
MSXFAQ Monitoring
Wenn Sie eine Webseite wie die MSXFAQ betreiben, dann möchte man natürlich sicherstellen, dass auch die Erreichbarkeit gegeben ist und die Performance passt. Das wurde auch noch mal wichtig, als ich den Umzug IONOS -> HostEurope durchgeführt habe.
Manuelles Monitoring
Nach dem Umzug der MSXFAQ habe ich zwei WebServer bei zwei Providern gehabt, die beide per HTTPS erreichbar waren. Ich konnte von meinem Client also genau beide Systeme proben und kann daher interessante Aussagen machen.
Zuerst habe ich mir mal den Weg von meinem Client zu den Servern angeschaut:
| Gegenstelle | IONOS | HostEurope |
|---|---|---|
| Ping 19:00 |
C:\>ping www.carius.de Ping wird ausgeführt für www.carius.de [217.160.0.234] mit 32 Bytes Daten: Antwort von 217.160.0.234: Bytes=32 Zeit=13ms TTL=58 Antwort von 217.160.0.234: Bytes=32 Zeit=13ms TTL=58 Antwort von 217.160.0.234: Bytes=32 Zeit=13ms TTL=58 Antwort von 217.160.0.234: Bytes=32 Zeit=13ms TTL=58 |
C:\>ping www.msxfaq.de -4 Ping wird ausgeführt für www.msxfaq.de [178.77.117.98] mit 32 Bytes Daten: Antwort von 178.77.117.98: Bytes=32 Zeit=24ms TTL=58 Antwort von 178.77.117.98: Bytes=32 Zeit=23ms TTL=58 Antwort von 178.77.117.98: Bytes=32 Zeit=23ms TTL=58 Antwort von 178.77.117.98: Bytes=32 Zeit=23ms TTL=58 |
| Traceroute 19:00 |
C:\>tracert www.carius.de Routenverfolgung zu www.carius.de [217.160.0.234] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [192.168.178.1] 2 4 ms 5 ms 5 ms 62.155.242.220 3 15 ms 14 ms 14 ms f-ee1-i.F.DE.NET.DTAG.DE [62.154.14.54] 4 11 ms 11 ms 11 ms 62.157.249.74 5 14 ms 16 ms 16 ms ae-9.bb-b.bs.kae.de.oneandone.net [212.227.120.168] 6 14 ms 14 ms 14 ms port-channel-2.gw-distd-sh-1.bs.kae.de.oneandone.net [212.227.116.221] 7 13 ms * * 217-160-0-234.elastic-ssl.ui-r.com [217.160.0.234] 8 13 ms * 14 ms 217-160-0-234.elastic-ssl.ui-r.com [217.160.0.234] |
C:\>tracert www.msxfaq.de Routenverfolgung zu www.msxfaq.de [2a01:488:42:1000:b24d:7562:25:6783] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [2003:ea:a716:7000:cece:1eff:fe34:3d04] 2 8 ms 5 ms 5 ms 2003:0:8504:d000::1 3 * * * Zeitüberschreitung der Anforderung. 4 12 ms 12 ms 11 ms ae0.cr-polaris.fra1.bb.godaddy.com [2003:0:1304:8007::2] 5 24 ms 23 ms 18 ms ae0.cr-antares.fra10.bb.godaddy.com [2a01:488:bb03:100::3] 6 24 ms 24 ms 24 ms ae0.cr-vega.sxb1.bb.godaddy.com [2a01:488:bb03:101::3] 7 25 ms 22 ms 23 ms ae0-v100.sr-helios.sxb1.mass.systems [2a01:488:bb00:102::3] 8 24 ms 23 ms 24 ms xh1153.webpack.hosteurope.de [2a01:488:42::a5c:213d] 9 24 ms 23 ms 24 ms vwp17599.webpack.hosteurope.de [2a01:488:42:1000:b24d:7562:25:6783] Gut zu sehen, dass zwischen Polaris und Antares am Hop 5 eine Verzögerung auftritt |
| TraceRT 20:45 |
C:\>tracert www.carius.de Routenverfolgung zu www.carius.de [217.160.0.234] über maximal 30 Hops: 1 2 ms 1 ms 1 ms fritz.box [192.168.178.1] 2 6 ms 8 ms 5 ms 62.155.242.220 3 18 ms 13 ms 14 ms f-ee1-i.F.DE.NET.DTAG.DE [62.154.14.54] 4 12 ms 11 ms 11 ms 62.157.249.74 5 13 ms 13 ms 13 ms ae-9.bb-b.bs.kae.de.oneandone.net [212.227.120.168] 6 14 ms 13 ms 14 ms port-channel-2.gw-distd-sh-1.bs.kae.de.oneandone.net [212.227.116.221] 7 13 ms 13 ms * 217-160-0-234.elastic-ssl.ui-r.com [217.160.0.234] 8 13 ms * 14 ms 217-160-0-234.elastic-ssl.ui-r.com [217.160.0.234] |
Diese Verzögerung ist aber wenige Stunden später nicht mehr da. C:\>tracert www.msxfaq.de Routenverfolgung zu www.msxfaq.de [2a01:488:42:1000:b24d:7562:25:6783] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [2003:ea:a716:7000:cece:1eff:fe34:3d04] 2 6 ms 6 ms 5 ms 2003:0:8504:d000::1 3 * * * Zeitüberschreitung der Anforderung. 4 12 ms 11 ms 12 ms ae0.cr-polaris.fra1.bb.godaddy.com [2003:0:1304:8007::2] 5 12 ms 11 ms 11 ms ae0.cr-antares.fra10.bb.godaddy.com [2a01:488:bb03:100::3] 6 24 ms 23 ms 23 ms ae0.cr-vega.sxb1.bb.godaddy.com [2a01:488:bb03:101::3] 7 14 ms 14 ms 14 ms ae4.cr-nunki.sxb1.bb.godaddy.com [2a01:488:bb::b2] 8 14 ms 15 ms 14 ms ae0-v100.sr-sol.sxb1.mass.systems [2a01:488:bb00:101::3] 9 14 ms 14 ms 14 ms xh1153.webpack.hosteurope.de [2a01:488:42::a5c:213d] 10 15 ms 15 ms 14 ms vwp17599.webpack.hosteurope.de [2a01:488:42:1000:b24d:7562:25:6783] C:\>tracert -4 www.msxfaq.de Routenverfolgung zu www.msxfaq.de [178.77.117.98] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [192.168.178.1] 2 5 ms 5 ms 4 ms 62.155.242.220 3 14 ms 14 ms 13 ms 217.239.40.178 4 14 ms 14 ms 14 ms ae8.cr-nunki.sxb1.bb.godaddy.com [62.157.249.226] 5 15 ms 14 ms 14 ms ae0-v100.sr-sol.sxb1.dcnet-emea.godaddy.com [87.230.112.3] 6 * * * Zeitüberschreitung der Anforderung. 7 15 ms 14 ms 15 ms vwp17599.webpack.hosteurope.de [178.77.117.98] |
Zum Zeitpunkt des ersten Vergleichs der HTTP-Response-Time ist der einfache ICMP-Ping von IONOS mit 13ms schon schneller als HostEurope mit 23ms. Dennoch ist die HTTP-Zeit insgesamt mit 82ms im Mittel bei HostEurope besser. Man könnte versucht sein, die Serverzeit durch die Differenz zu bilden. Dann wäre mein neuer "WebServer Basic SSD" mit ca. 49ms ja fast doppelt so schnell als der vorherige IONOS-Server mit 110ms - 13ms = 97ms. Die Rechnung ist so aber nicht legitim, denn sie beruht auf einem einzelnen Ping und auch der Inhalte der msxfaq.de ist sicher größer als von carius.de. Erste mit einer kontinuierlichen Test-Serie könnte man hier ein besseres Bild bekommen.
Sie sehen aber auch, wie essentiell ein Monitoring von solchen Diensten ist. Es geht nicht nur um den Alarm beim Ausfall oder den Belegt von Aussetzern sondern auch um Basis-Werte zur Erkennung von
Um 20:45 habe ich mich auch dran erinnert, dass meine neue Webseite ja sowohl statische IPv4- als auch IPv6-Adressen hat. Da liegt ein Vergleich der Routen schon auf der Hand.
| IPv4 | IPv6 |
|---|---|
C:\>tracert -4 www.msxfaq.de Routenverfolgung zu www.msxfaq.de [178.77.117.98] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [192.168.178.1] 2 5 ms 5 ms 4 ms 62.155.242.220 3 14 ms 14 ms 13 ms 217.239.40.178 4 14 ms 14 ms 14 ms ae8.cr-nunki.sxb1.bb.godaddy.com [62.157.249.226] 5 15 ms 14 ms 14 ms ae0-v100.sr-sol.sxb1.dcnet-emea.godaddy.com [87.230.112.3] 6 * * * Zeitüberschreitung der Anforderung. 7 15 ms 14 ms 15 ms vwp17599.webpack.hosteurope.de [178.77.117.98] |
C:\>tracert www.msxfaq.de Routenverfolgung zu www.msxfaq.de [2a01:488:42:1000:b24d:7562:25:6783] über maximal 30 Hops: 1 1 ms 1 ms 1 ms fritz.box [2003:ea:a716:7000:cece:1eff:fe34:3d04] 2 6 ms 6 ms 5 ms 2003:0:8504:d000::1 3 * * * Zeitüberschreitung der Anforderung. 4 12 ms 11 ms 12 ms ae0.cr-polaris.fra1.bb.godaddy.com [2003:0:1304:8007::2] 5 12 ms 11 ms 11 ms ae0.cr-antares.fra10.bb.godaddy.com [2a01:488:bb03:100::3] 6 24 ms 23 ms 23 ms ae0.cr-vega.sxb1.bb.godaddy.com [2a01:488:bb03:101::3] 7 14 ms 14 ms 14 ms ae4.cr-nunki.sxb1.bb.godaddy.com [2a01:488:bb::b2] 8 14 ms 15 ms 14 ms ae0-v100.sr-sol.sxb1.mass.systems [2a01:488:bb00:101::3] 9 14 ms 14 ms 14 ms xh1153.webpack.hosteurope.de [2a01:488:42::a5c:213d] 10 15 ms 15 ms 14 ms vwp17599.webpack.hosteurope.de [2a01:488:42:1000:b24d:7562:25:6783] |
Ich hatte eigentlich erwartet, dass die WAN-Strecken heute schon alle IPv4 und IPV6-Routen und daher der Weg für die Pakete identisch wäre. Dem ist aber nicht so. Der IPv4-Weg ist 3 Hops kürzer aber von der Geschwindigkeit vergleichbar. Sie sehen hier aber auch, dass es wohl ein direktes Peering der Telekom mit dem Carrier "GoDaddy" gibt, der zugleich Gesellschafter von HostEurope ist.
- Host Europe Group
https://de.wikipedia.org/wiki/Host_Europe_Group
HTTP-Performance
Auch mein Überwachung mit PRTG funktionierte ohne Umkonfiguration nach einiger Zeit wieder. ich habe aber dennoch mein Monitoring um weitere Sensoren erweitert, dass ich nun auch die PING-Laufzeit und parallel noch HTTP und HTTPS-Zugriffe prüfe.

Interessant ist aber schon nach wenigen Stunden der direkte Vergleich. der Responsezeit eines HTTP-Requests. Die letzten 30 Tage vor dem Ausfall bei IONOS kam ich auf Mittelwerte bei ca. 110ms mit einigen Peak.

Für den Betrieb bei HostEurope habe ich noch nicht so lange Daten aber der Mittelwert ist hier eher bei 82ms.

Nun hören sich 30ms Unterschied nicht viel an aber es ist schon merklich. Interessant finde ich, dass heute nochmal etwas "passiert" sein muss, denn seit 20:00 ist die Antwortzeit noch mal schneller geworden.
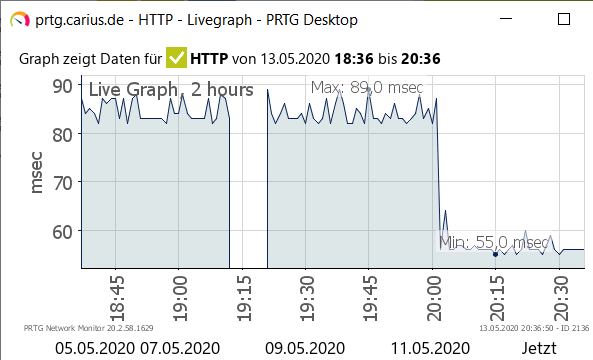
Da muss ich mal ein Auge drauf haben. Allerdings kann ich hier nicht sehen, wie weit die Entfernung von meinem DSL-Anschluss zum Webserver ist und welche Rolle ob das Netzwerk spielt. Da aber meine "carius.de"-Seite immer noch bei IONOS liegt, habe ich ja zwei Gegenstelle, die ich per HTTP: PING und Traceroute ansprechen kann.
Einen Tag später hatte ich dann auch mehr Daten im direkten Vergleich. Obwohl meine MSXFAQ nun nicht mehr auf dem IONOS Shared Server läuft und damit viel Last entfallen sein müsste, ist die carius.de-Seite immer noch deutlich langsamer:


Die Bilder sehen sehr ähnlich aus aber PRTG skaliert dynamisch die Daten. Sie müssen links die Skala in Millisekunden im Blick behalten. Links ist die neue MSXFAQ mit Antwortzeiten zwischen 50-60 Millisekunden. Rechts dann der IONOS Server mit Werten im Bereich 90-100 Millisekunden. Schade, das Provider solche Daten selbst vielleicht erheben aber nicht den Kunden zur Verfügung stellen oder zumindest dem Kunden einen Tipp geben, wenn Server langsam sind.
301 Redirect und Fehlalarm
Etwas einen Monat später habe ich noch mal die aktuelle Performance angeschaut und bin erschrocken.
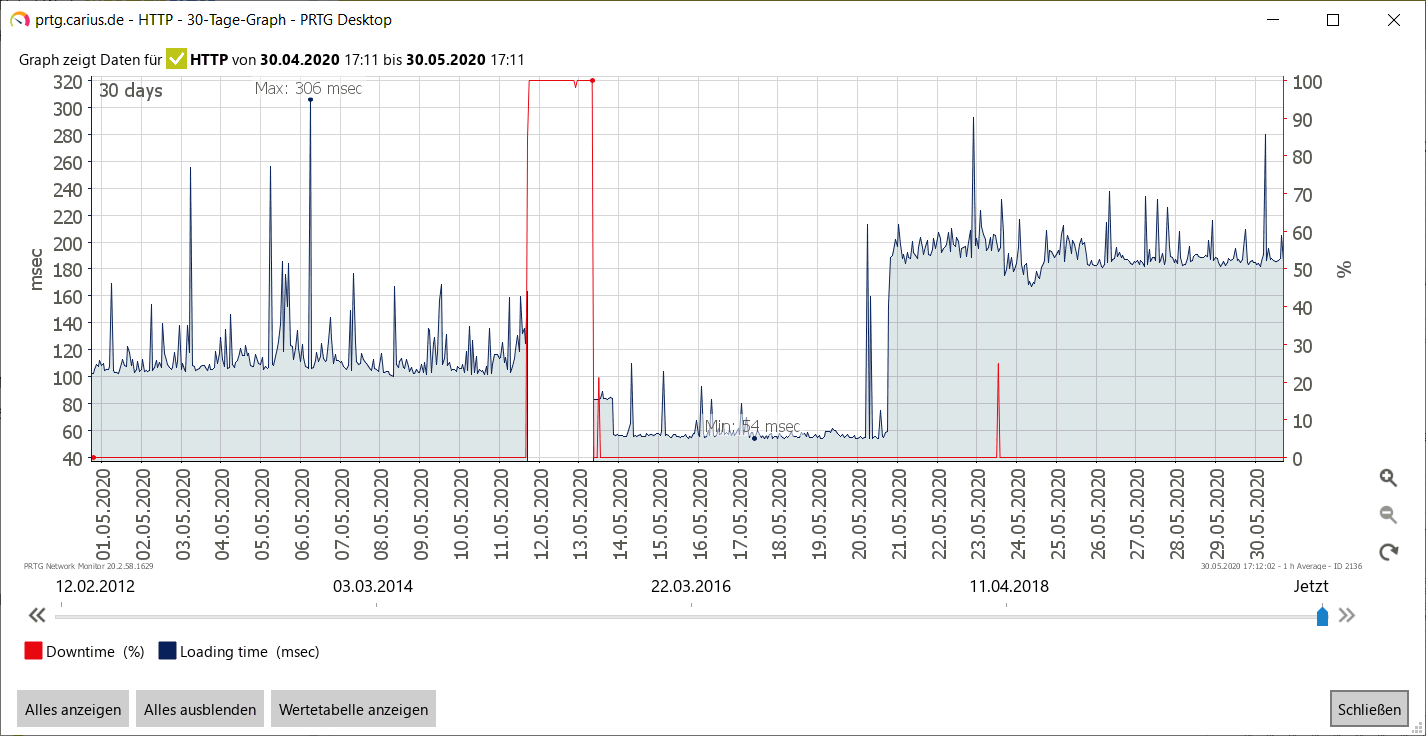

Links waren die 110ms bei IONOS zu sehen und dann die "nicht Erreichbarkeit" zwischen dem 11.5 nachmittags und 13.3 abends. Am 13.5 habe ich mich noch über die schnellere Performance gefreut, die am 14.5 bis 20.5 sogar noch deutlich schneller wurde. Aber 20.5 gegen 18:00 hat sich die Performance deutlich verschlechtert. Die PING-Zeiten zum Webserver sind dahingehend aber unverändert

Ich bin da natürlich alarmiert und habe am 31.5 daher bei HostEurope per Mail nachgefragt und sehr schnell auch eine Antwort samt den Grafiken zum 20.5.2020 bekommen, die ich im nächsten Abschnitt vorstelle, ehe ich danach auf die Ursache eingehe.
Host Europe Monitoring
Es steht jedem Hoster gut zu Gesicht, die eigenen Server zu überwachen. Solche Daten sind wichtig, um Missbrauch, Überlast u.a. zu erkennen und auf den Kunden zugehen zu können. Noch besser wäre es, wenn ich als Kunde auch Zugriff auf meine Daten hätte. Im Fehlerfall könnte das helfen. Bei HostEurope habe ich eine Mail an den Support mit meiner Problemstellung gesendet und am nächsten Werktag eine Antwort mit Screen-Captures zur fraglichen Zeit bekommen.
| Kriterium | Diagramm |
|---|---|
CPU-LastDas ist ja schon lächerlich wenig. Aber hätte mich auch gewundert, wenn statische Webseiten einen Apache stressen sollten. Andere Prozesse oder CRON-Jobs und Mailboxen laufen auf dem Server ja nicht wirklich. |
 |
HauptspeicherAuch hier bewege ich mich in absolut erwarteten Größenordnungen. |
 |
ProzesseBei den Prozess sind die Bilder erst einmal nicht so wichtig Vielmehr interessiert mich hier die Apache-Prozesse. Die waren zwischen 17:00- und 19:20 Uhr, also etwas nach der Hauptaktivität mit 18 max. in einer erwarteten Größe. |
 |
Aus Sicht des Servers ist hier kein Sprung oder eine Stufe zu sehen.
Wer misst, misst Mist
Die Quelle für den Spruch dürfte in der Elektrotechnik zu finden sein aber wenn der Server nicht auffällig ist und das Netzwerk beim PING auch keine Sprünge anzeigt und die Abfrage des Monitoring-Systems nur mit diesem Server einen Sprung anzeigt, dann muss es ja doch in der Applikation oder der Art der Abfrage zu suchen sein. Vielleicht hat sich ja auch PRTG Abfrage verändert oder mein LAN oder Proxy-Server. Ein ICMP-Ping sagt ja nicht allein alles aus. Ich überwache von meinem Standpunkt aus natürlich noch andere Webserver, z.B. carius.de bei IONOS, netatwork.de etc. Diese Monitore haben aber keinen Sprung zur fraglichen Zeit angezeigt und auch keine generelle Verschlechterung.
Ich habe die Abrufe per PowerShell gestartet und dort auch die Verzögerungen gesehen:
PS C:\> (measure-command {Invoke-WebRequest http://www.msxfaq.de/favicon.ico}).totalmilliseconds
172,301
Mit Wireshark war dann aber auch zu sehen, was letztlich die Ursache ist. Der Client startet eine HTTP-Anfrage an die Favicon. Die ersten drei Pakete sind der TCP-Handshake um dann im Paket 4 den GET zu senden, der in Paket 5 quittiert und Paket6 beantwortet wird. Da ist aber kein Bild in der Antwort, sondern ein 301 Redirect.

Und damit ist natürlich auch offensichtlich, was hier passiert. Invoke-Webrequest als auch PRTG folgenden auch noch dem Redirect und verbinden sich per HTTPS mit der Gegenseite. Sie bauen also einen neuen TCP-Kanal auf Port 443 auf, starten einen TLS-Handshake um dann die Datei verschlüssel zu übertragen. Damit ist natürlich klar das diese Flut an Paketen nicht in 50m übertragen werden kann. In PRTG kann ich das "verfolgen" leider nicht abschalten. Bei PowerShell hingegen ist es möglich und schon sind wir wieder weit unter den 100ms.
PS C:\> (measure-command {Invoke-WebRequest http://www.msxfaq.de/favicon.ico -MaximumRedirection 0}).totalmilliseconds
Invoke-WebRequest:
301 Moved Permanently
Moved Permanently
The document has moved here.
84,6732
Damit war ich dann wieder beruhigt.
PRTG HTTP Cloud Sensor
Paessler stellt mit dem Produkt PRTG auch einen "Cloud HTTP Sensors" bereit, d.h. meine lokale PRTG-Installation kann sich ein paar Proxy-Server in der Cloud bedienen, um die Erreichbarkeit der Webseite aus unterschiedlichen geografischen Orten zu überprüfen. Die Orte sind natürlich durch die Standorte von Paessler vorgegeben und der Sensor testet die Webseite auch nur einmal alle 10 Minuten. In meinem Fall sind es 4 Standorte, die alle 10 Minuten einmal 25kByte herunter laden, also 600 KB/Stunde oder 14MByte/Tag.

Wobei auch hier die Messwerte durchaus Abweichungen haben, die nicht stimmen können. Die Minimum-Server (USA=10ms, Tokyo=27ms) sind nicht zu schaffen. Aber sie sehen so schon gut, wann die Seite aus einem Teil der Welt nicht erreichbar wäre und dass die Laufzeiten mit der Entfernung zu Deutschland natürlich zunehmen.
Weiterentwicklung
Ich bin noch nicht sicher, wann ich dazu komme. Die Überwachung eines Webservers mit PRTG ist schon sehr einfach möglich, da es die entsprechenden Sensoren auch schon alle gibt, d.h. ICMP, HTTP. HTTPS und sogar CloudHTTP. Die Daten der einzelnen Sensoren könnte ich auch recht einfach mit einem Sensor Factory Sensor zusammenfassen. Aber vielleicht baue ich mir doch noch mal einen kleinen PowerShell-Sensor, der PING, NSLookup, TraceRoute und HTTP-Request ohne Redirect in einem Rutsch zusammenfasst und in einem Diagramm die verschiedenen Werte aufeinander stapelt.
Dann fehlt nur noch die Funktion, weitere Daten des Server, z.B. CPU-Last etc. oder die Antwort des PHP-Aufrufs "sys_getloadavg();" in eine HTTP-Antwort zu verpacken. Eine Trivial-Version per SSH aufgerufen liefert aber ein "bool(false)
<?php $load = sys_getloadavg(); var_dump($load); ?>
Das geht dann wohl nicht.
- sys_getloadavg
https://www.php.net/manual/de/function.sys-getloadavg.php
Die Optionen direkt aus PHP die Befehle "free" und "uptime" zu starten, scheitern schon direkt in der SSH-Shel mit einem "/proc must be mounted". Das ist auch dokumentiert:
...jedoch ist es aus Sicherheitsgründen leider nicht möglich,
Prozessinformationen aus dem /proc Pseudodateisystem zu lesen
Quelle:
https://www.hosteurope.de/faq/webserver-dedicated/ssh-zugang-webserver/ssh-zugang-info/
Aber auch Apache hat einen eigenen Statushandler mod_status. Ich weiß aber nicht, ob dieser bei HostEurope aktiv ist. Da ich die Apache.conf nicht anpassen oder einsehen kann, habe ich einfach mal eine Konfiguration in der Datei ".htaccess" versucht.
<IfModule mod_status.c> <Location /server-status> SetHandler server-status #Order deny,allow # Deny from all # Allow from 203.0.113.2 203.0.113.3 </Location> ExtendedStatus On </IfModule>
Eine Abfrage hat dennoch einen 404 geliefert. Per SSH habe ich aber auf dem WebServer im Pfad /etc/apache2/mods-enabled/status.conf folgendes gefunden
<IfModule mod_status.c>
# Allow server status reports generated by mod_status,
# with the URL of http://servername/server-status
# Uncomment and change the "192.0.2.0/24" to allow access from other hosts.
<Location /server-status>
SetHandler server-status
Require local
#Require ip 192.0.2.0/24
</Location>
# Keep track of extended status information for each request
ExtendedStatus On
# Determine if mod_status displays the first 63 characters of a request or
# the last 63, assuming the request itself is greater than 63 chars.
# Default: Off
#SeeRequestTail On
<IfModule mod_proxy.c>
# Show Proxy LoadBalancer status in mod_status
ProxyStatus On
</IfModule>
</IfModule>
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
Anscheinend ist das Modul enthalten aber nur von "Localhost" aufrufbar. Das ist dann doch wieder ein Weg per PHP den Status vielleicht zu erreichen. Leider hat aber ein "CURL localhost/serverstatus" einen "connection refused" ergeben und ein "curl https:/www.msxfaq.de/server-status" auch wieder nur den üblichen 404 geliefert.
Auch ein Versuch, die Konfiguration über eine HTAccess zu überschreiben, hat nicht funktioniert. Dann brauch ich auch nicht weiter nach der "Machine-readable" URL zu schauen
http://your.server.name/server-status?auto
Schade bis hier erst einmal.
- Apache Module mod_status
https://httpd.apache.org/docs/2.4/mod/mod_status.html - PRTG Manual: HTTP Apache ModStatus PerfStats Sensor
https://www.paessler.com/manuals/prtg/http_apache_modstatus_perfstats_sensor - How to enable the Apache server statistics on a Plesk server
https://support.plesk.com/hc/en-us/articles/213922425-How-to-enable-the-Apache-server-statistics-on-a-Plesk-server - Nginx status monitor sensor
https://kb.paessler.com/en/topic/60186-nginx-status-monitor-sensor - Ways to Check Apache Server Status and Uptime in Linux
https://www.tecmint.com/check-apache-httpd-status-and-uptime-in-linux/ - How to Monitor Apache Web Server Load and Page Statistics
https://www.tecmint.com/monitor-apache-web-server-load-and-page-statistics/
Noch gibt es noch einen erweiterten "Webserver Sensor".
Weitere Links
- MSXFAQ Offline 27.4.2020 + 11/12.05.
- Syncback upload
- 13. April 2006: msexchangefaq.de hacked
-
IONOS Shared Hosting
https://www.ionos.de/hosting/webhosting -
HTTP Strict Transport Security
https://de.wikipedia.org/wiki/HTTP_Strict_Transport_Security - Gefahren durch Webshells: NSA nennt
beliebte Einfallstore für Server-Angriffe
https://www.heise.de/security/meldung/Gefahren-durch-Webshells-NSA-nennt-beliebte-Einfallstore-fuer-Server-Angriffe-4709470.html - How many visitors can 20 concurrent
connections handle?
https://webmasters.stackexchange.com/questions/103957/how-many-visitors-can-20-concurrent-connections-handle - Limits on Hosting by different providers
https://hostmayo.com/blog/limits-on-hosting-by-different-providers/
Andere Provider listen diesen Wert sichtbarer auf. - Wo liegt welche Domain
https://securitytrails.com/domain/msxfaq.de/













