
MO502273 Cloud Ausfall
Am 23. Januar 2023 waren sehr viele Microsoft 365 Dienste für einige Zeit nicht erreichbar. Anscheinend hat jemand an den Netzwerk-Routen gespielt, so dass die Server an sich noch funktioniert haben dürften, aber die Verbindung zu den Diensten unterbrochen wurde. Microsoft hatte die Störung dann doch recht schnell per Twitter (https://twitter.com/MSFT365Status/status/1618149579341369345) gemeldet und anhand der Folgemeldungen ist auch der zeitliche Verlauf gut zu erkennen:
| Zeit | Meldung |
|---|---|
08:31 |
We're investigating issues impacting
multiple Microsoft 365 services. More info can
be found in the admin center under MO502273. https://twitter.com/MSFT365Status/status/1618149579341369345 |
09:15 |
We've identified a potential networking
issue and are reviewing telemetry to determine
the next troubleshooting steps. You can find
additional information on our status page at
https://msft.it/6011eAYPc or on SHD under
MO502273. https://twitter.com/MSFT365Status/status/1618160643873411072 |
10:06 |
We’ve isolated the problem to networking
configuration issues, and we're analyzing the
best mitigation strategy to address these
without causing additional impact. Refer to the
admin center MO502273 or
https://msft.it/6018eAldp for more
information. https://twitter.com/MSFT365Status/status/1618173470596124673 |
10:26 |
We've rolled back a network change that we
believe is causing impact. We're monitoring the
service as the rollback takes effect. https://twitter.com/MSFT365Status/status/1618178407316987905 |
Eine ausführlichere Störungsmeldung wurde unter MO502273 im Admincenter veröffentlicht und immer wieder aktualisiert.
- Users may have been unable to access multiple Microsoft 365
services
https://admin.Microsoft.com/Adminportal/Home?#/servicehealth/history/:/alerts/MO502273
Wenn Sie im Portal angemeldet sind, können Sie dort auch einen " post-incident report" herunterladen. Ein Auszug davon
Starting Wednesday January 25, 2023, at 7:08 AM UTC, customers may have
experienced issues with networking connectivity, manifesting as network latency
and/or timeouts when attempting to connect to Azure and Microsoft 365 services.
As part of a planned change to update the IP address on a WAN router, a command
given to the router caused it to send messages to all other routers within the
WAN, that resulted in all of them recomputing their adjacency and forwarding
tables. During this re-computation process, the routers were unable to correctly
forward packets. Further, this issue impacted connectivity between clients on
the internet to Azure, connectivity between services in datacenters, and
ExpressRoute connections.
We identified the recent change to WAN infrastructure as the underlying cause of
the issue; however, the system had already begun automatic recovery. Our
telemetry indicated the service was mostly recovered by 9:05 AM UTC, and
continued to saturate across all regions and services, with most of the
networking equipment automatically recovering at 9:35 AM UTC.
Quelle: Microsoft Post Incident Report
https://admin.Microsoft.com/admin/api/servicehealth/postincidentreport?url=https://graph.Microsoft.com/v1.0/admin/serviceAnnouncement/issues(%27MO502273%27)/incidentreport
Ich kann nur jedem Administrator einmal empfehlen, den Post Incident Report zu lesen. Er macht zumindest den Eindruck, dass Microsoft mit offenen Karten spielt und Fehler benennt. Ich bin sicher, dass nicht alle On-Premises-ITler vergleichbar arbeiten. Leider ist der Report meines Wissens nur für Administratoren mit Zugang zum Microsoft Admin Portal direkt zu erreichen und auch dann müssen sie bei der Menge der Probleme die eine Meldung schon gezielt suchen. Daher habe ich eine PDF-Version hier bereit gestellt:
Microsoft Post Incident Report zu MO502273
mo502273-postincidentreport.pdf
Der Report ist aber nicht nur hinsichtlich der Zeitachse der Fehler, der Auswirkungen, Gegenmaßnahmen und Widerherstellung interessant. Microsoft gibt auch Einblicke in ihre Überwachung der Dienste. So erfasst Microsoft die Belastung der Server im Vergleich zur Vorwoche.
Interessant finde ich nicht nur die Verlaufskurven sondern auch die absoluten Werte der Y-Achse
| Bild | Beschreibung |
|---|---|
|
|
SharePoint Online/OneDriveIst ist der fast schlagartige Einbruch gegen 07:15 GMT direkt zu sehen. Beachten Sie, dass die 0-Linie nicht sichtbar ist und es "nur" ein Einbruch auf ca. 40% ist, wenn nur 1400k statt 2400k Requests/Sek im Vergleich zur vorherigen Woche anliegen. |
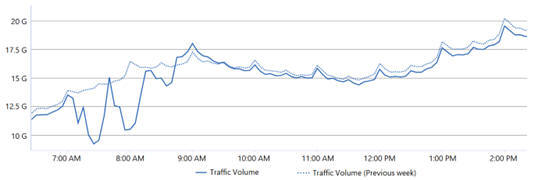 Quelle: Microsoft MO502273 Report |
Exchange Online NetzwerkvolumenEine zweite Grafik zeigt die WAN-Ausnutzung der Exchange Online Dienste im Vergleich zur Vorwoche. Hier ist besonders gut zu sehe, dass das Volumen in den Tälern bei ca. 10 G/Sek im Vergleich zu 14-17G/Sek ist Also 30-40% weniger Zugriffe, weil die Clients nicht zu den Servern gekommen sind. leider ist nicht angegeben, ob dies wirklich der externe Traffic ist oder auch interne CAFE-Proxy-Verbindungen enthalten sind. denn auch bis zu 20Gigabyte/Sek = 200 GBit erscheint mir etwas wenig. Es ist aber gut zu sehen, wie nah aber im Normalbetrieb die Werte beisammen sind. Ein Monitoring kann hier sehr gut bei größeren Abweichungen alarm schlagen, wenn wir mal die üblichen Feiertag ignorieren. |
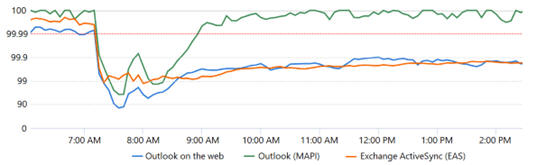 Quelle: Microsoft MO502273 Report |
Exchange Online Client ErfolgsrateDie Probleme dauerten länger, da der Netzwerkausfall auch das interne LAN/WAN betroffen hat und Bitlocker und ein "Shared Cache" durch Neustart von Servern "degraded" waren. Wie genau Microsoft diese Werte misst, ist leider nicht beschrieben. Vielleicht sind es Telemetriedaten von Outlook die konnten aufgrund der Störung auch nicht zu Microsoft gemeldet werden. Vielleicht betreibt Microsoft eine "Probe-Systeme" verteilt bei anderen Providern oder Sie bewerten hier die CAFE-Kommunikation zwischen Frontend und Backend. |
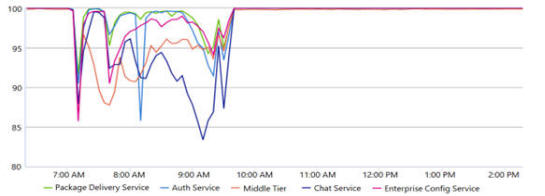 Quelle: Microsoft MO502273 Report |
Microsoft TeamsWährend OneDrive und Outlook mit ihrem Cache die Störung abgemildert haben, sind Audio/Video-Konferenzen natürlich direkt betroffen. Das Bild zeigt aber die Verfügbarkeit der internen Dienste, die mit 85% mit immer noch gefühlt zu "hoch" sind. Mag ja sein, dass die Netzwerkstörung auch die interne Kommunikation der Server untereinander betroffen hat. Aber das ist keine Aussage was beim Anwender angekommen ist. Leider ist dies nur eine Prozentanzeige. Absolute Werte zur genutzten Bandbreite wie bei Exchange hätten mich wirklich interessiert. |
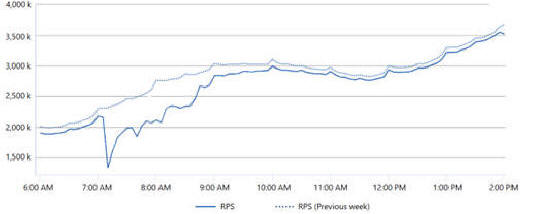
Aus diesen Werten ist gut zu sehen, wie wichtig ein internes Monitoring ist, welches nicht nur die Erreichbarkeit der Dienste sondern auch Kennzahlen ermittelt. Ansonsten kann ihr "IsAlive"-Test zwar die 100% Verfügbarkeit ihres Servers und und "keine Überlastung" melden aber es kommt dennoch kein Client an den Server. Das erkennen sie indirekt dann an zu wenig Last auf dem System.
Sichtbar in Rimscout
Ich predige schon viele Jahre, dass ein richtiges Monitoring sich nicht darauf beschränken darf, von einem Überwachungssystem im RZ die Server im RZ zu prüfen. Viel wichtiger ist aber, was letztlich beim Anwender ankommt und da ist der Server nu das letzte Stück einer ganzen Kette, ausgehend vom Desktop mit Software über die LAN/WLAN-Verbindung, Router, Firewall oder DSL-NAT, Internetprovider, Peering und Microsoft Global Network. Analog gilt dies auch für selbst betriebene On-Premises-Systeme.
Für meine Arbeit bei Kunden im Rahmen von Netzwerk Assessment oder auch als Dauerüberwachung hat Net at Work das Produkt "Rimscout" (https://www.rimscout.com) entwickelt und natürlich habe wir hier nicht nur den Ausfall gesehen, sondern deutlich mehr Auswirkungen als "nur" die Reduzierung auf 85%, die Microsoft in ihrem Bericht zugegeben hat.
Hier ist sehr gut zu sehe, dass z.B. Outlook, Teams UDP und TCP komplett "offline" war.
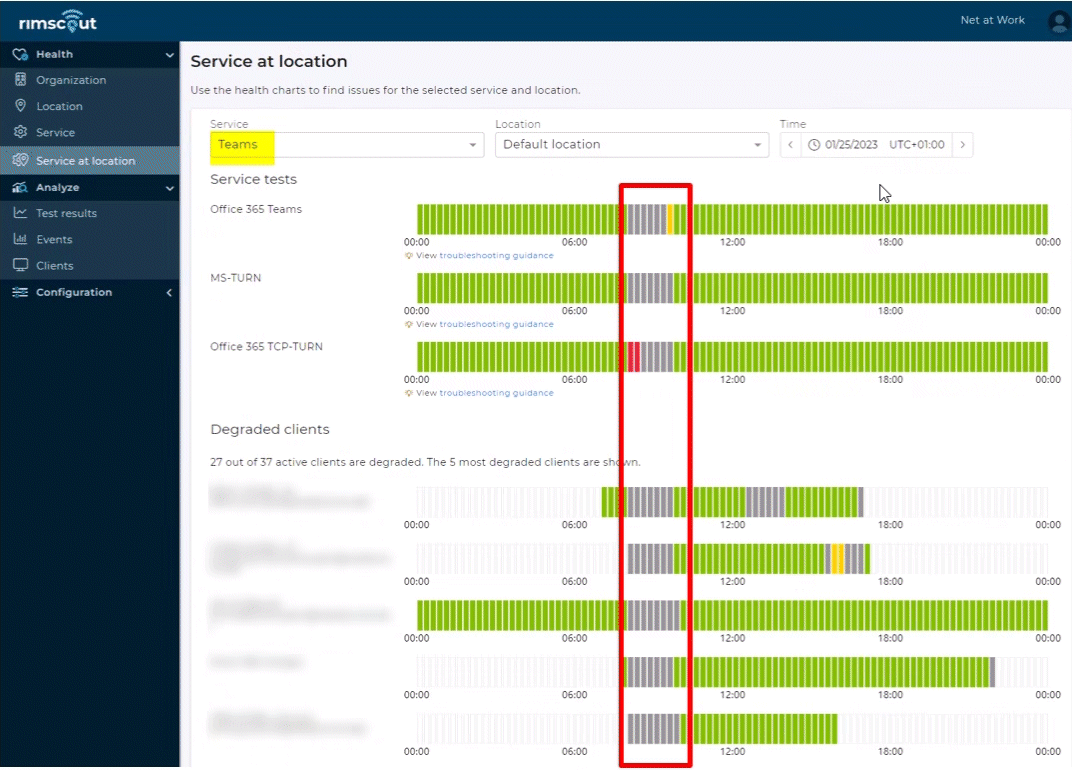
Das Bild zeigt im unteren Bereich die 5 am meisten betroffenen Clients. Wobei hier insgesamt 27 von 37 Client als "Degraded" geführt werden. Die gleiche Auswertung zeigt sehr ähnliche Daten über andere Standorte und sogar andere Kunden, so dass sehr schnell klar war: Hier ist nicht eine Internetleitung eines Kunden defekt, sondern das ist schon eine umfangreiche Störung aller Office 365 Dienste. Da Rimscout (https://www.rimscout.com) auch andere Dienste überwacht, z.B. Webseiten wie Google, Twitter u.a. und diese nicht betroffen waren, mussten unsere Kunden nicht lange "suchen". Die Anzeige ist absichtlich "einfach", denn Rimscout (https://www.rimscout.com) bewertet anhand unserer gesammelten Erfahrungswerte die gemessenen Daten.
Natürlich ist auch ein "Drilldown" bis auf den einzelnen Test und Client möglich. Auch das liefert manchmal interessant Einblicke, wie das Beispiel der Latenzzeit der Teams Transport Relay-Systeme zeigt:
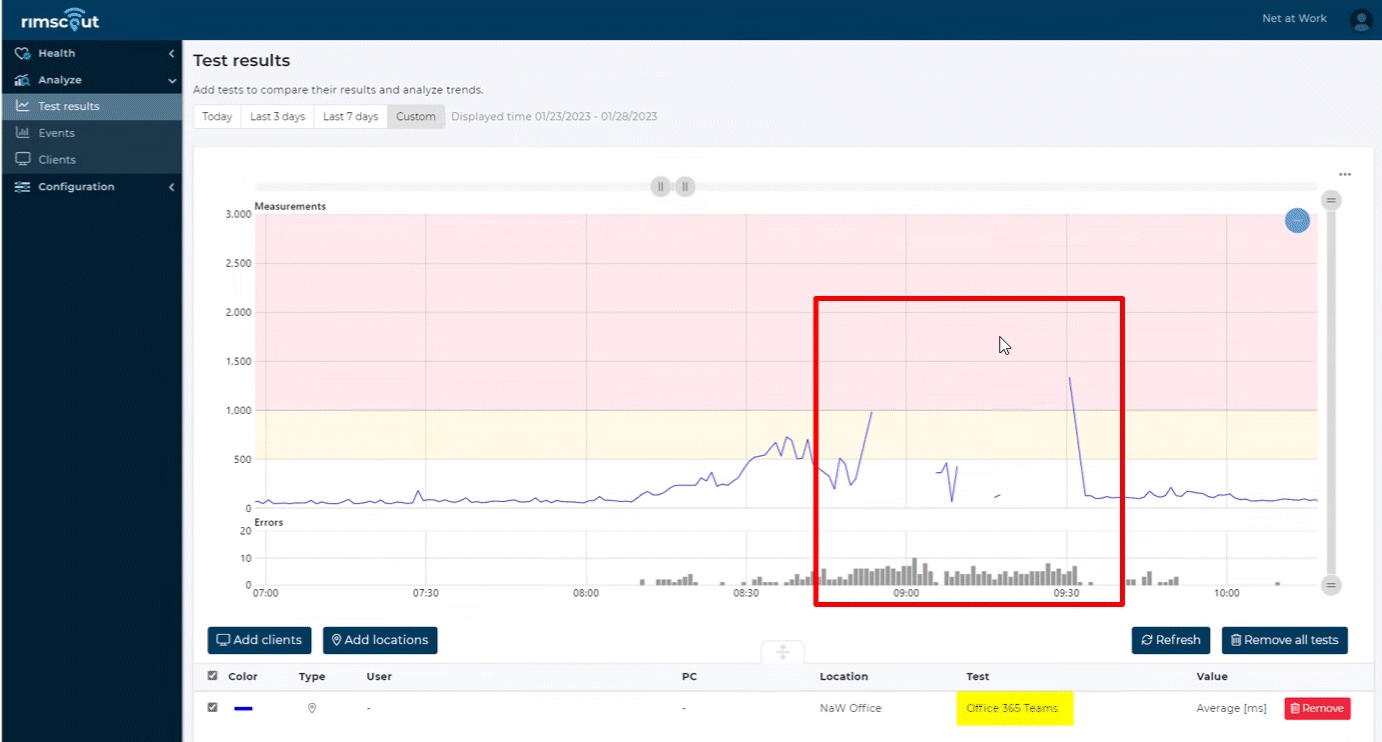
Der richtig Ausfall dieses Clients startet gegen 08:50 und dauert bis ca. 09:32. Interessant ist nicht nur, dass es zwischendurch mal wieder funktioniert hat. Ich schaue eher den Zeitraum von 08:10 bis 08:40 an. Rimscout (https://www.rimscout.com) erkennt hier schon eine Verschlechterung der Qualität und auch die Fehlerrate nimmt zu. Der Ausfall hat sich quasi "angekündigt". So ein Verhalten habe ich schon bei anderen WAN-Ausfällen bei Kunden gesehen, wenn eine interne Störung beim Provider durch ein internes Rerouting abgemildert wird. Die Dienste sind zwar noch zu erreichen aber die Latenzzeit wird schlechter bis dann auch die Ersatzstrecken überlastet werden und der Ausfall nicht mehr zu verbergen ist.
Einschätzung
Ausfälle können immer passieren und sowohl Menschen als auch Software sind nicht fehlerfrei. Um so wichtiger ist es, die Ursache schnell zu erkennen um Gegenmaßnahmen einleiten zu können. Zusätzlich sollten Aktionen und Veränderungen protokolliert werden, damit sie einen qualifizierten "Post Incident Report" für ihre Kunden erstellen können. Cloud-Anbieter müssen so etwas tun und es sagt viel über die im Unternehmen gelebte Fehlerkultur aus, wenn die Berichte auch noch öffentlich sind, so dass andere Firmen und Personen davon etwas lernen können.
Das Monitoring von Microsoft gibt auch On-Premises-Administratoren wichtige Ansatzpunkte, wie sie ihren eigenen Betrieb noch besser gestalten können. Es reicht aber nicht sich in seinem Datacenter zu verschanzen und den Weg zum Client und den Client selbst nicht mit zu erfassen. Microsoft hat mit den Telemetriedaten von Windows und Office sicher einen Ansatz, wenn diese denn auch den Weg zum Server finden. Das war hier wohl etwas schwerer. Vielleicht ist das auch ein Grund, warum Microsoft auch über Twitter informiert da auch das Admin Portal in der Zeit nicht erreichbar war.
Für mich hat dieser Ausfall aber auch wieder gezeigt, dass ein Monitoring auf dem Client mit dem Schwerpunkt auf die vom Client genutzten Dienste (Erreichbarkeit, Latenzzeit) auch heute zu jedem Unternehmen dazu gehört.
Wenn Sie mehr Informationen einer
Überwachung der Dienst durch Clients benötigen, dann schauen
Sie sich gerne meiner kommerzielle Lösung Rimscout an.
Weitere Informationen finden Sie dazu auf
https://www.rimscout.com
Weitere Links
- Microsoft Cloud Ausfälle
- PRTG mit Office 365
- Microsoft 365 Status
https://twitter.com/MSFT365status - Erste Störungsmeldung
https://twitter.com/MSFT365Status/status/1618149579341369345?lang=en - Großstörung bei Microsoft-Diensten (Outlook, OneDrive, Teams
etc. (25. Jan. 2023)
https://www.borncity.com/blog/2023/01/25/grostrung-bei-Microsoft-diensten-outlook-onedrive-teams-etc/ - Störung bei Microsoft: Viele Dienste von weltweiter Störung betroffen
(Update)
https://www.netzwelt.de/ist-down/213041-stoerung-Microsoft-viele-dienste-weltweiter-stoerung-betroffen.html - Analyse: Microsoft liefert erste Details zum Ausfall von Teams, Office und
Co.
https://www.heise.de/news/Analyse-Microsoft-liefert-erste-Details-zum-Ausfall-von-Teams-Office-und-Co-7473885.html - Microsoft Outage on 25th Jan 2023 MO502273
https://www.exoprise.com/2023/01/25/Microsoft-outage-25-jan-2023-mo502273/














