
In den Händen der Werbenetzwerk - Tracking im Internet
Auf dieser Seite sammle ich meine Gedanken zu dem Verhalten unterschiedlicher Webseiten und was Sie als "Surfer" darüber wissen sollten. Landläufig sind das "Tracker", mit denen Firmen versuchen, ihr Surfverhalten zu analysieren und sie genauer zu bestimmen. Es gibt verschiedene Wege dies zu tun, z.B. durch JavaScript, 3rd Party Tracker, o.ä. Speziell aktive Werbevideos und wiederholte Hintergrundanfragen kosten nicht nur ihre Aufmerksamkeit und ein paar CPU-Zyklen sondern auch Batterielaufzeit und Datenvolumen und unterscheiden auch nicht zwischen der Datenflat am heimischen DSL und einer teuren Mobilfunk-Verbindung. Es geht mit also nicht nur darum, Sie beim Thema Datenschutz zu sensibilisieren, denn auch wenn Sie nichts zu verbergen haben, so sollte man dennoch nicht ein komplett offenes Buch sein. Es können auch durchaus Kosten anfallen.
Und dann gibt es noch das Thema der "Filterblase". Wenn jemand ihnen immer wieder nur die gleichen Informationen als Werbung oder Empfehlungen einblendet, dann übersehen Sie ganz viele andere Möglichkeiten.
Aus dem Grund gibt es auf der MSXFAQ keine Werbung oder dauern wechselnde Werbebilder. beiden Einblendungen links zu Net at Work und oben rechts zu Aktionen ändern sich eher alle Monat mal und Google Analytics sammelt für mich ein paar Daten zu den Besuchern (OS, Auflösung, besuchte Seiten). Werbenetzwerke gibt es auf der MSXFAQ nicht.
Es geht immer ums Geld
Letztlich ist das Internet schon lange nicht mehr das wissenschaftlicher und Forschungsnetzwerk, als welches in den Anfängen gestartet ist. Sicher nutzen immer noch Universitäten, Studenten und Forscher die Plattform zur effektiven Kommunikation und Datenübertragung aber viel größere Datenmengen werden heute für Medien (Fernsehen, Videos, Radio, Pornografie) und auch Software-Downloads und Updates verwendet. Sie als Anwender bezahlen für ihren "Internetzugang" und die Anbieter für das Hosting an Provider und Carrier. Die Anbieter müssen sich daher anders finanzieren.
- Abonnement/Paywall
Am saubersten ist eigentlich ein "Bezahldienst", wie dies einige Verlage aber auch Anbieter wie Netflix, Spotify, outlook.com, DropBox anbieten. Sie melden sich an, d.h. identifizieren sich und haben einen Vertrag mit dem Anbieter, der ihnen gegen Bezahlung eine Leistung zusichert. Allerdings gibt es auch da reduzierte und werbefinanzierte Mischangebote. Selbst zahlende Abonnementen von z.B. "Heise+" müssen mit Werbung leben

Quelle: https://www.heise.de/plus/info-faq/ (Stand Dez 2019) - Werbung und Daten
Da es sehr schwer ist, zahlende Anbieter zu gewinnen und dann auch noch das Inkasso vielleicht weltweit zu betreiben, erscheint der Weg über Werbung doch viel einfacher. Keine Einstiegshürden können Anbieter mit der Werbung Geld verdienen, solange es nur etwas redaktionellen Inhalt gibt. Der wird aber aus meiner Sicht immer schwieriger zu finden. Es gibt immer mehr Seiten die aus viel mehr Werbung bestehen und Inhalte absichtlich über mehrere Seiten verteilt werden, um immer neue Werbeklicks zu ermitteln. Zudem können Surfer noch besser personalisiert werden, wenn ihr "Weg durch das Angebot" vieler kleiner Seiten nachverfolgt werden kann.
Wenn die verschiedenen Webseiten dann Informationen der gleichen dritten "Werbe-Liefer-Webseite" einbinden, dann erlaubt dies ein übergreifendes Tracking. - Kostenfreier Shop-Zugriff
Einige Webseiten kommen mit wenig Werbung aus, weil Sie am Ende doch ihre Adresse hinterlassen und bezahlen. Das sind die klassischen Bestell-Webseiten wie Amazon, Reichelt etc. deren Webseite "fast" werbefrei ist, um Kunden nicht abzuschrecken. Hinweise auf passende Produkte, was auch Werbung ist, wird natürlich genutzt. Spätestens mit der Bestellung weiß der Betreiber aber sowieso, wer sie sind, so wie wohnen und wie sie bezahlen. Ich gehe mal davon aus, dass der Betreiber aber auch diese Daten weiter nutzt. Er kennt ja Zeitpunkt und ihr IP-Adresse, was Werbetracker gerne zukaufen. - Kostenfrei und Werbefrei
Natürlich gibt es noch die rein private Webseiten, die aus Idealismus betrieben werden. Sei es als "persönliche Seite" um Informationen zu liefern, Selbstdarstellung zu betreiben, sich zu Bewerben etc. Seiten von Firmen und Universitäten fallen in der Regel auch darunter, weil hie Werbung für andere Produkte die Besucher eher abschrecken würde.
Natürlich ist auch jede Art von Kombination möglich. Je weniger sie bezahlen, desto eher ist ein Tracking wahrscheinlich, was meist durch eine Kombination von Hilfsmitteln erfolgt. Auf dieser Seite beschreibe ich unter anderem:
- Cookies und 3rd Party Cookies
- JavaScript
- Modern App Datenbanken
- Source-IP-Adresse und Nachbarn
Aus meiner Sicht ist es heute für einen normalen Anwender unmöglich, sich einem Tracking zu entziehen.
The Internet is on fire | Mikko
Hypponen | TEDxBrussels
https://www.youtube.com/watch?v=QKe-aO44R7k
Sehr schöner Vortrag von 2014. bei Min 12: Google investiert
2 Mrd/Quartal in die Infrastruktur und verdient damit 12 Mrd
US$/Jahr
Privat-Mode
Vorneweg gleich ein Wort zu dem besonderen "Privat"-Mode, den mittlerweile alle Browser mit leicht unterschiedlicher Bezeichnung haben. Oft wird dieser Betrieb auch als "Inkognito-Mode" bezeichnet, was aber aus meiner Sicht irreführend ist


Denn es wird übersehen, dass die Funktion den Browser anweist beim Beenden der Sitzung alle Spuren zu entfernen. Ein anderer Benutzer am gleichen Computer kann dann nicht mehr nachvollziehen, wo sie sich herum getrieben haben. Diese Einstellung schützt nur bedingt gegen Tracking-Maßnahmen von Anbietern. Da natürlich z.B. Cookies etc. gelöscht werden, ist es für einen Webseitenbetreiber schon kniffliger den PC oder Anwender wieder zu erkennen. Aber es ist ihm dennoch möglich, da zumindest am privaten Anschluss die ganze Familie hinter dem gleichen Router steht und extern die gleiche IP-Adresse verwendet.
Tracking auf Smartphone
Immer mehr Menschen verbringen viel mehr Zeit mit ihrem Smartphone und konsumieren dort über Browser aber insbesondere auch Apps die verschiedenen Informationen, Bestellen Produkte, Lesen Nachrichten nutzen Twitter, Facebook etc. sind für die Werbeindustrie dabei natürlich sehr interessant. Die meisten Smartphones sind nämlich oft gut zu erkennen, da sie eine Seriennummer, eine SIM-Karte, eine Rufnummer oder eine by Default statische TrackingID haben. In den Einstellungen können Sie die Nutzung beschränken:

Es ist natürlich "schade", wenn ich dann nur "weniger relevante" Werbung bekommen kann. Es wird aber verschwiegen, dass ihr Weg durchs die werbebestückten Seiten des Internet anhand der ID nachvollzogen werden kann und bei der ersten Anmeldung auf nur einer Seite mit dem Werbenetzwerk die Verknüpfung zur Person passiert.
Bei Apple war diese ID lange seit fest aber konnte in einem ersten Schritt manuell geändert werden, später kann man sie manuell schon mal ändern, den Zugriff angeblich unterbinden oder Apple will mit IOS14 eine Warnung einblenden. Leider wissen die wenigsten Anwender um diese Funktion und das Apple nicht "sicher als Default" einstellt, kann nur mit einem wirtschaftlichen Interesse erklärt werden
- SKAdNetwork
https://developer.apple.com/documentation/storekit/skadnetwork - Werbung und Datenschutz
https://support.apple.com/de-de/HT205223 - What Half of iPhone Users Don’t Know
About Their Privacy: New Poll
https://foundation.mozilla.org/de/blog/what-half-of-iphone-users-dont-know-about-their-privacy-new-poll/
Ich bin sicher, dass auch auf den verschiedenen Android-Derivaten die wenigsten Personen über solche IDs und deren Einstellungen bescheid wissen. Auf der anderen Seite helfen diese IDs aber nicht weiter, wenn Smartphone früher oder später eine IPv6-Adresse bekommen, die einige Zeit stabil ist. Solange die Hintergrund-Apps mit ihren Servern kommunizieren, kennen diese Betreiber sehr wohl die Identität und was hindert diese damit Geld zu verdienen. Zudem einige selbst Werbenetzwerke betreiben und damit Geld verdienen und man es mit dem Datenschutz auch nicht so genau nimmt:
- Oracle: Datenpanne mit Milliarden
Einträgen enthüllt riesiges Tracking-Netz
https://www.heise.de/amp/news/Oracle-Datenpanne-mit-Milliarden-Eintraegen-enthuellt-riesiges-Tracking-Netz-4790339.html - Oracle - Strategic Acquisitions - Oracle
Buys BlueKai
https://www.oracle.com/corporate/acquisitions/bluekai/ - WhoTracksme: Bluekai
https://whotracks.me/trackers/bluekai.html
Interessant ist, wie die Werb-Industrie gegen weitere Schutzmaßnahen seitens der Hersteller bemüht und davor nicht mal vor dem Missbrauch der DSGVO zurückschreckt:
- Tracking-Warnung in iOS 14: Europäische
Werbeverbände pochen auf Änderungen
https://www.heise.de/news/Tracking-Warnung-in-iOS-14-Europaeische-Werbeverbaende-pochen-auf-Aenderungen-4835785.html
Apples Tracking-Einwilligungsdialog sei nicht DSGVO-konform, schrecke Nutzer ab und sorge für wettbewerbsrechtliche Bedenken, so die Werber.
"Apples Dialog, der Nutzer über mögliches Tracking informiert und dafür um Erlaubnis bittet, erfülle nicht die Vorgaben der Datenschutzgrundverordnung (DSGVO) zur Einholung einer Einwilligung für personalisierte Werbung, schreiben die Werber."
Cookies: Gut weniger gut
Cookies sind im Grund erst mal nicht böse, wenn Sie mit Bedacht eingesetzt werden. Die Verbindung zwischen deinem Webbrowser und einem Server ist im Grunde immer "Stateless", d.h. anders als bei einem Terminalzugang per TELNET oder SSH, bei dem die TCP-Verbindung bestehen bleibt, nutzen Browser mehrere Verbindungen und bei einem Netzwerkwechsel kommt eine neue Verbindung zustande.
- Identifizierung
Es wäre sehr nervig sich dann immer neu anmelden zu müssen. Daher verwenden eigentlich alle Webseiten mit Anmeldung entsprechende Cookies, die ihre Identität beweisen und einige relativ kurze Zeit gültig sind - Authentifizierung
Durch die Gültigkeitsdauer kann eine Webseite bestimmen, ab wann ein Anwender wegen Inaktivität sich neu anmelden muss. - Bestellungen und Warenkorb
Solche Cookies kommen auch zum Einsatz, um in Shop-Systemen den Warenkorb über mehrere Fenster hinweg zu erhalten. Sie halten den "Status" der Sitzung.
All diese Cookies sind im originären Interesse des Anbieters aber auch des Anwenders und sollten nicht blockiert werden. Ansonsten funktioniert nicht mehr viel. Cookies zeichnen sich aber dadurch aus, dass Sie in der Regel auch nur an die Seite gesendet werden, von der sie gesetzt wurde. Es sollte also nie möglich sein, dass z.B. eine Werbeseite auf ihrem PC einen Cookie von Amazon, Google, PayPal oder einer anderen Seite abfragen kann. Das war ganz am Anfang des Internets noch gar nicht immer sichergestellt. Heute aber kein Problem mehr.
Früher wurden sie gar nicht bezüglich Cookies informiert. Dann wurde eine unaufdringliche Cookie-Info eingeblendet aber mittlerweile sind die Cookie-Rückfragen schon seitenfüllend und eher abschreckend und helfen keinem wirklich weiter. Einige setzen "freundliche" Defaults", während andere Seiten gleich 2-3 Klick brauchen, wenn man nur die "funktionalen" Cookies zulassen will

Den Vogel schießt aus meiner Sicht ausgerechnet eine Computerzeitschrift (heise.de) ab, bei sie erst begrüßt werden und nach einem Mausklick die Konfiguration sehen. Sie sehen hier aber beim "akzeptieren" nicht, was sie damit erlauben. Ich kann nur hoffen, dass die Defaults zum Tragen kommen, die beim Druck auf Konfigurieren angezeigt werden.

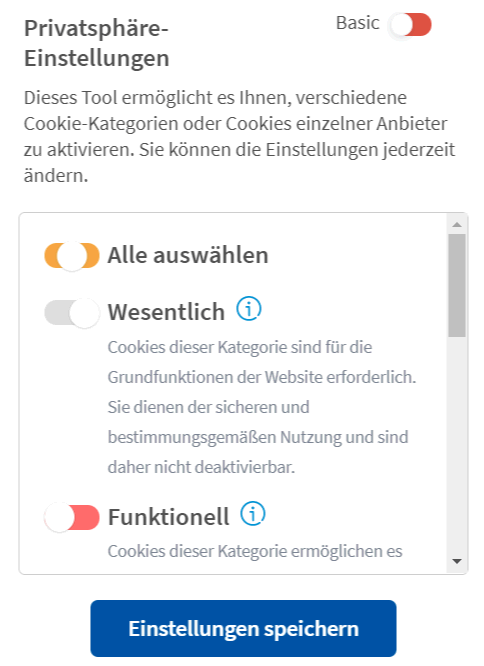
Es sind nur die "Wesentlichen" Cookies aktiviert, die Heise glaubt zu brauchen. Gehen Sie aber in die Advanced-Einstellungen, dann kann einen die Anzahl (Siehe Scrollbalken rechts) der Cookies schon abschrecken.
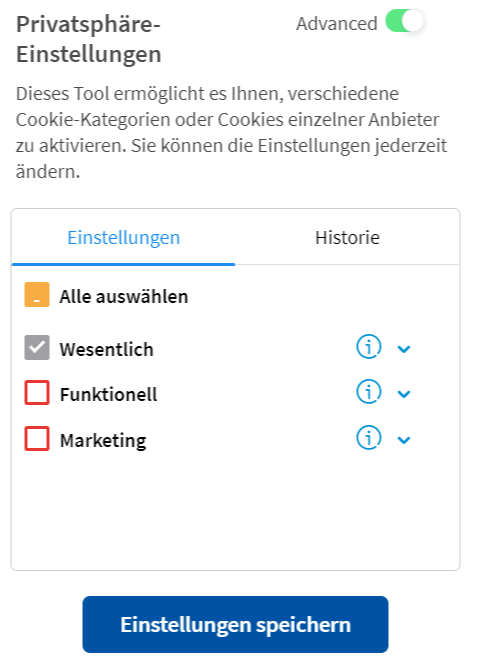
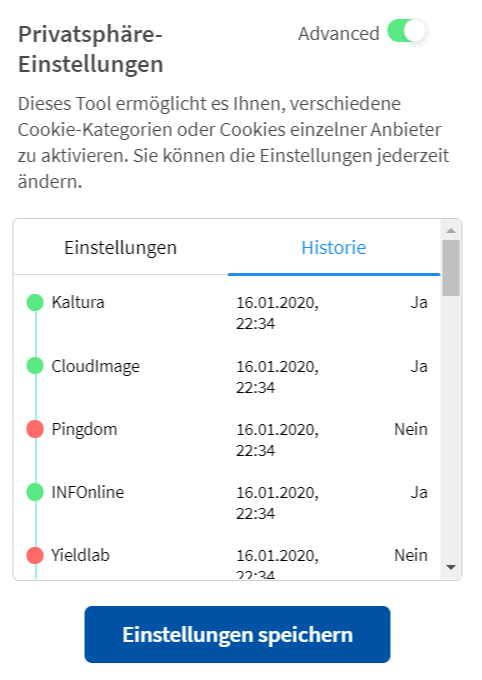
Klicken Sie sich ruhig mal durch. Schon bei "Wesentlich", also nicht deaktivierbare Cookies sind sehr viele Drittanbieter dabei.

Bei den funktionellen Cookies waren es am 16.1.2020 weitere 11 Webseiten und bei Werbung weitere 13 Adressen. Bedenken Sie einfach, dass bei jedem Aufruf von heise.de ihr Client über den HTML-Code auch Dateien von diesen Zulieferern bezieht und diese Cookies zur Wiedererkennung auf ihrem PC hinterlassen könnten.
Es gibt noch viele weitere negative Beispiele und es geht mir auch nicht um Heise-Bashing.
Aber auch andere Seiten sind durchaus "umfassend". "Verizon Media", unter denen auch Yahoo, AOL, und andere Seiten logieren, lassen ihnen gar keine Wahl. Die "Grundlegenden Partner" aber auch "Google" mit einer Unmenge an Partnern könne nicht abgewählt werden.


Angeblich würde Google das sogar vorschreiben, dass Sie als Besucher diese Tracker in ihren eigenen Datenschutzeinstellungen einzeln abschalten.
Der Cookie-Wahnsinn + Live-Gespräch
mit MdEP Tiemo Wölken zum EU-Datenschutz
https://www.youtube.com/watch?v=pVnOJ3dEk0Q
Sie können eine Webseite sehr schnell z.B.: über https://webbkoll.dataskydd.net/ prüfen lassen
- Ihr Datenschutz-Dashboard
https://www.verizonmedia.com/policies/ie/de/verizonmedia/privacy/dashboard/index.html - Cookies auf der MSXFAQ
-
Cookie-Fallen: Wir pfeifen auf Ihre
Privatsphäre
https://www.gutjahr.biz/2020/12/wir-pfeifen-auf-ihre-privatsphaere/
3rd Party Cookies
Damit kommen wir das erste Mal zu dem Thema "3rd Party Cookies". Wenn Sie z.B. www.msxfaq.de ansurfen, dann lädt ihr Browser nicht nur die HTML-Seite, Bilder und CSS-Datieen von meiner Webseite sondern bekommt auch per JavaScript die Info eine Datei von "google-analytics.com" nachzuladen. Das können Sie gut im Header sehen:

Wenn ihr Browser nun Daten von diese Adresse lädt, kann dieser Service natürlich auch einen Cookie für seine Dienste setzen und pflegen. In den Browser Debugging Tools (F12) können Sie dies auch sehen. Hier die drei Bereiche, die auf der MSXFAQ einen Cookie setzen:
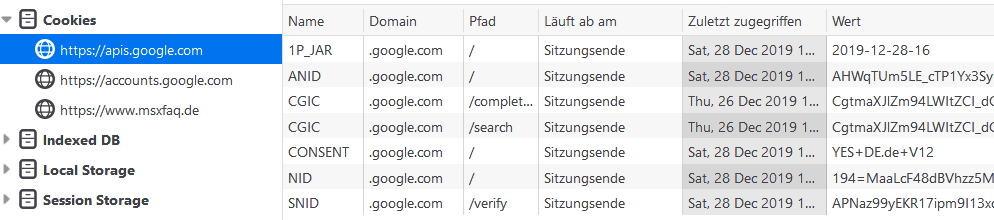
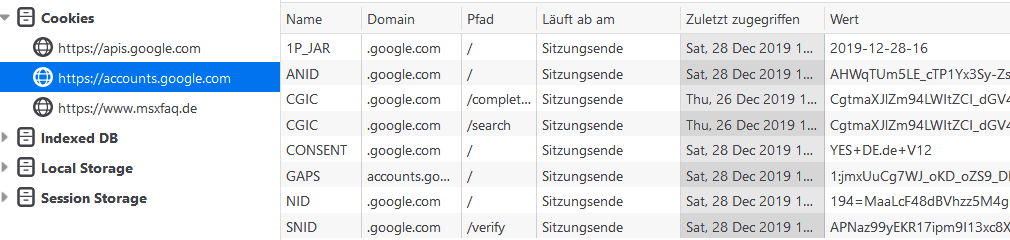

Achten Sie auf "Läuft ab am: Sitzungsende". Diese Cookies bleiben also nicht über lange Zeit erhalten
Andere Webseiten setzen da sehr viel längere Identitäten

20 Jahre ist schon sehr lange, zumal ich mich bei Amazon durchaus ja per Anmeldung identifiziere.
- Google Analytics Cookie Usage on Websites
https://developers.google.com/analytics/devguides/collection/analyticsjs/cookie-usage
Das wäre so auch noch gar nicht schlimm, denn technisch kann es schon Gründe geben, Dateien z.B. von einem Content Delivery-Netzwerk nachzuladen und auch JavaScript muss nicht jeder Webmaster selbst vorhalten, wenn diese an einer zentralen Stelle liegen. So sind sie dann immer schön aktuell. Auf der anderen Seite verrät der Browser dieser dritten Partei natürlich, woher sie kommen und wer sie sind.
Wenn Sie nun mehrere Webseiten besuchen, die alle die Dienste von "Google Analytics" nutzen, dann kann Google die verschiedenen Besuche auf den unterschiedlichen Seiten wieder "zusammenführen" und letztlich ihren Weg durch das Internet zumindest teilweise nachverfolgen.. Ihr Browser sendet den Cookie immer wieder an die gleiche Adresse aber liefert einen unterschiedlichen "Referer" mit. Als Nutzer von Google Analytics sehe ich allerdings nur die Zugriffe auf meiner Webseite und nicht, was Sie woanders noch gemacht habe.
Anders wird sich der gleiche Trick bei Werbetrackern aus, die mit den Webseiten-Betreibern in einem Vertragsverhältnis stehen. Da ist es schon interessant, welche Seiten Sie als Anwender besucht haben und welche Inhalte sich für die Qualifizierung eignen. Sie können diese Verhalten sehr einfach ausprobieren. Starten sie einen Browser im "privaten"- oder "Inkognito"-Mode". Er sollte dann nichts gespeichert haben und "ungenutzt" für jede Webseite aussehen. Wenn Sie dann eine Webseite ansurfen und etwas warten, dann können Sie recht schnell sehen, wie viele und welche Cookies gesetzt wurde.

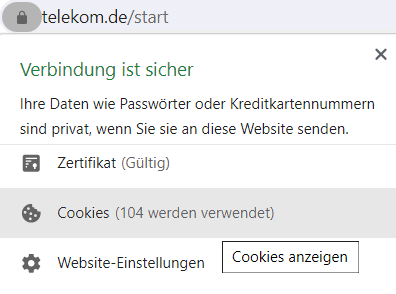
Wenn Sie auf die Cookies klicken, dann zeigt Chrome mir hier die Domains mit Cookies an.

Interessanter ist hier die Seite der blockierten Cookies.

Ich habe dann mal ein paar Seiten bezüglich der Cookies analysiert, wen nicht keine 3rd Party Cookies unterdrücke und bei Consent-Rückfragen keine Werbenetzwerke ablehne.
| URL | Cookies der Domain/Subdomain | 3rd Party Cookies |
|---|---|---|
6 |
25 (Google) |
|
37 |
2 |
|
33 |
0 |
|
3 |
4 |
Allerdings ist das nur eine "Momentaufnahme" (29. Dez 2019) und zeigt nur den Aufruf der ersten Seite. Je mehr Seiten sie auf einer Webseite aufrufen, desto mehr Einträge könnten dazu kommen. Die Liste können Sie selbst auch ganz einfach erweitern.
Diese "3rd Party-Cookies werden immer mehr Browser blockieren, da Sie sich als "Hüter der Sicherheit" sehen. Firefox, Opera, Brave sind natürlich früher als Microsoft Edge und insbesondere Chrome ist hier noch nicht so weit. Blocken können es alle aber die Einstellung dazu ist eben nicht immer aktiv.
Im "Inkognito-Mode" blockiert Chrome per Default alle Cookies von Drittanbietern, die im normalen Mode "natürlich" gesetzt werden. Klar ist auch der Heise-Verlag ein Wirtschaftsunternehmen, der seinen Werbefirmen das beste "Zielgruppenmarketing" anbieten will. Aber wenn Sie die Seite ohne Schutz ansurfen, dann werden ganz schnell mal all dieses Cookies gesetzt

Hier landen aber nicht nur die Cookies auf ihre lokalen Speicher sondern ihr Browser hat eine Verbindung zu all diesen Domains aufgebaut, um überhaupt erst diese Cookies zu erhalten. Datenmenge, Zeitverzögerung und Datenschutz sind hier durchaus zu interfragen.
Datenmengen
Aber auch im Hinblick auf die Datenmenge sind Cookies zwar zu vernachlässigen, wenn der Inhalt kurz ist. Sie werden aber mit jedem Request an die Domain immer wieder mitgeschickt und bei vielen Zielen ist immer auch ein TLS-Handshake erforderlich, so dass dies insbesondere bei Verbindungen mit schwacher Bandbreite oder höherer Latenzzeit die Performance beeinflusst. Dazu zählen aber auch zusätzliche Bilder u.a.
Mit den Entwicklertools (F12) in Browser können Sie sogar die Summe aller Requests anzeigen. Beachten Sie den Rollbalken rechts. Das hier ist nur ein kleiner Ausschnitt (ca. 15%) aller Requests beim Aufruf einer einzelnen Seite

Die Homepage lädt 224 Seiten und benötigt ca. 3,41 Sekunden während die Seite selbst in 567ms gerendert ist.
Wohlgemerkt: Das ist der "Inkognito-Mode" bei dem nur keine Cookies gesetzt werden aber die Abrufe bei all den Werbenetzwerken erfolgen dennoch. Die Tracker kennen damit zumindest ihre IP-Adresse, die sich doch ziemlich gut auf ihren Anschluss eingrenzen lässt. Wenn nun noch Links zu anderen Seiten "personalisiert" sind und jemand in ihrem Haus woanders "nicht inkognito" surft, dann ist auch der Inkognito-Mode nicht mehr wert.
Inkognito verhindert nur, dass der Browser auf dem PC Spuren hinterlässt und jemand anderes so ihre Surf-Geschichte nachverfolgen oder eine Sitzung wieder aufnehmen kann.
Dennoch ist die Unterbindung von 3rd Party Cookies aus meiner Sicht ein wichtiger Teilaspekt einer gewissen Schutzstufe. Damit wird ihr Browser angewiesen, Cookies nur von Seiten der Domäne oder Unterdomänen zuzulassen. Wenn also eine Webseite auch Informationen von anderen Domänen einbindet, dann kann der Browser die Cookies dieser anderen Seiten ignorieren und sendet auch keine Cookies mehr hin. So entziehen Sie diesen anderen Seiten schon etwas die Daten, um ihren Client über mehrere Webseiten hinweg nachzutracken.
Allerdings wissen auch die Betreiber darum und fangen nun damit an, die Werbung über Unterdomänen auszuspielen. Technisch ist es kein Problem einen DNS-Eintrag wie "werbung.msxfaq.de" auf einen Server eines Werbeanbieters zeigen zu lassen, damit ein Browser diese "Neben-Adresse" auch mit Cookies bespielt. Allerdings hilft das nicht beim Seitenübergreifenden Tracken und die Verwaltung der Zertifikate wird aufwändiger.
Hier sind die Einstellungen je Browser (Stand Dez 2019)
| Browser | 3rd Party Cookie | Einstellung |
|---|---|---|
Edge |
Erlaubt |
Beim Edge finden Sie die Konfiguration unter "Einstellungen - Datenschutz und Sicherheit"
Microsoft Edge to Include
Internet Explorer Mode, Privacy, and
Productivity Modes
|
Chrome |
erlaubt |
Chrome erlaubt 3rd Party Cookies. Sie können das Verhalten aber global als auch pro Domain abschalten. Google tut sich damit aber natürlich schwerer als die anderen Hersteller, da auch Google quasi von Werbung lebt und auch Google Analytics, YouTube etc. solche Cookies nutzen. Ich glaube nicht, dass Google in Chrome dann eine "Allowlist" für seine Dienste einfügt. Sie können als Anwender natürlich die Funktion selbst entsprechende konfigurieren:
Über die folgende besondere URL können Sie sehen, welche Daten Chrom pro Domain speichert chrome://settings/siteData Im Debugge habe ich folgende Meldung gefunden, die ich aber nicht weiter beschreibe
|
Firefox |
Unterbunden seit Version 67 |
Seit Version 67 hat Firefox per Default einige Schutzfunktionen aktiv.
Ich habe meinen Browser auf "Streng" gestellt. Wenn Seiten dann nicht funktionieren, dann kann ich ja immer noch bewusst auf einen anderen Browser im "Private Mode" wechseln.
|
Safari |
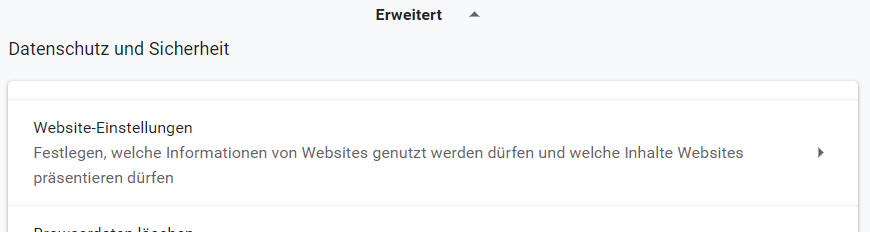
Unterbunden seit Version 11 (Sep 2017) |
Seit 2019 werden sogar die "First Party Cookies" 7 Tage beschränkt und weitere Einschränkungen sind wohl angekündigt. Auf meinem IPhone sieht es so aus:
|

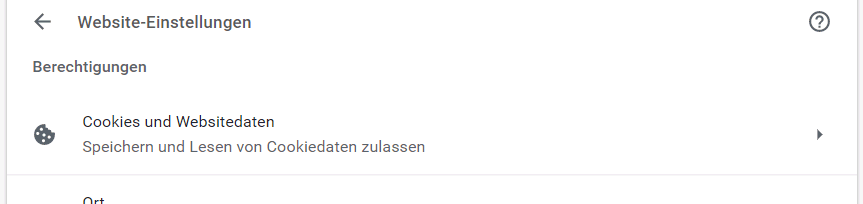
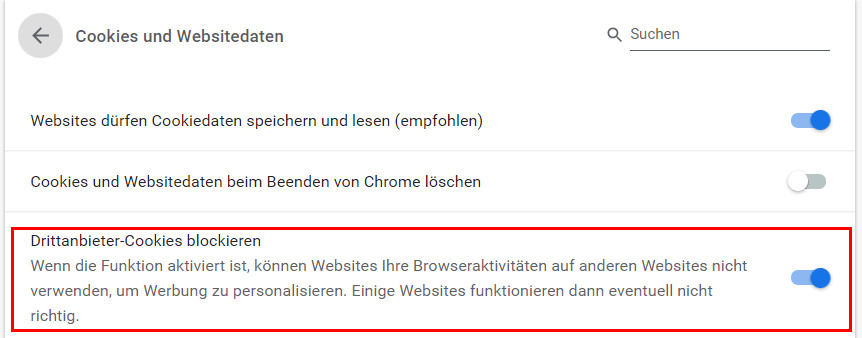

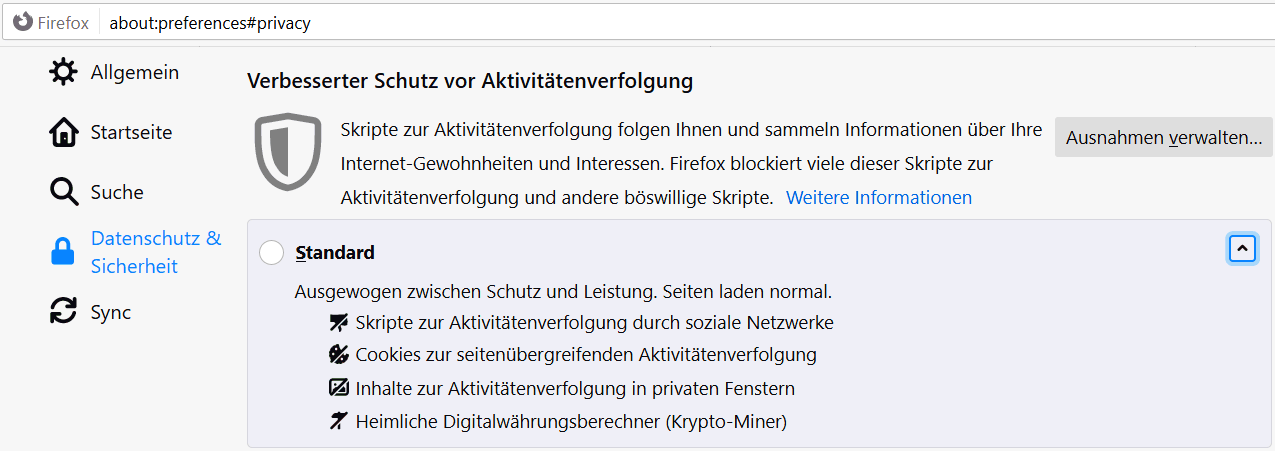
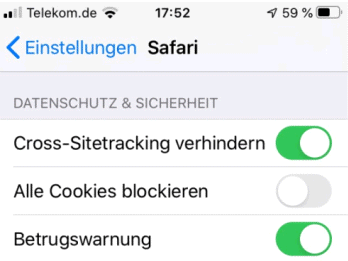
- How Different Browsers Handle First-Party and Third-Party
Cookies
https://clearcode.cc/blog/browsers-first-third-party-cookies/ - DECONSTRUCTING: Intelligent Tracking Prevention (ITP) and
the Future of Online Tracking
https://www.media-sense.com/2019/04/25/deconstructing-intelligent-tracking-prevention-itp-and-the-future-of-online-tracking/ - Block third-party cookies in Chrome, Firefox, Opera, Edge,
and Internet Explorer
https://www.digitalcitizen.life/how-disable-third-party-cookies-all-major-browsers - Browser Wars“: Wie Google, Apple und Mozilla die Zukunft des Cookies
verhandeln
https://omr.com/de/browser-wars-google-third-party-cookies-tracking/ - SameSite cookies explained
https://web.dev/samesite-cookies-explained/
Fremde URLs
Es sind aber nicht nur Cookies. Webseiten können sich auch an anderen Quellen bedienen um z.B. Skripte, Schriftarten oder Bilder nachzuladen. Dabei geht es weniger um Einsparen von eigenem Transfervolumen, da die meisten Webhoster schon großzügige Volumen anbieten. Interessanter für einen Seitenbetreiber ist hier eher, dass man so immer eine aktuelle Version verwendet und speziell bei eingebundenen Skripten sich nicht selbst um Updates kümmern muss. Das bedeutet aber auch, dass eben diese Dienste auch einen Zugriff des Clients sehen.
Wen Sie also über mehrere Seiten im Internet surfen, die alle z.B. die gleichen Fonts von Google oder jquery-Skripte eingebunden haben, dann kann dieser Anbieter Sie anhand der Quell-IP-Adresse ihres Internet-Anschlusses auch wieder besser verfolgen und das erlangte Wissen mit anderen Daten verknüpfen. Ein sehr nettes Tool um diese Dinge zu erkennen und zu steuern ist UMATRIX. Sie sehen für einen Webseite sehr schnell, woher sie noch andere Informationen bezieht und können diese selektiv erlauben oder verbieten. Hier ein paar Beispiele (nicht repräsentativ)
| Webseite | UMATRIX |
|---|---|
|
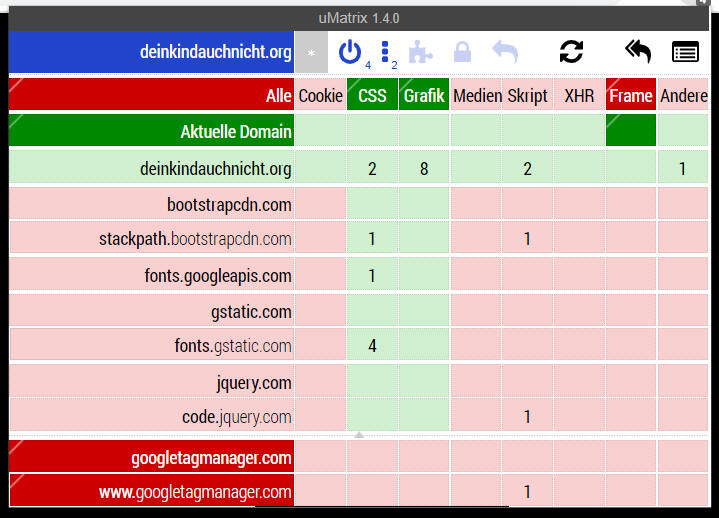
deinkindauchnicht.org Eigentlich eine ganz wichtige Seite für Eltern und Kinder zur Sensibilisierung. Leider zeigt gerade diese Seite dann gar nicht mehr an. den Webmaster habe ich schon mal informiert. |
|
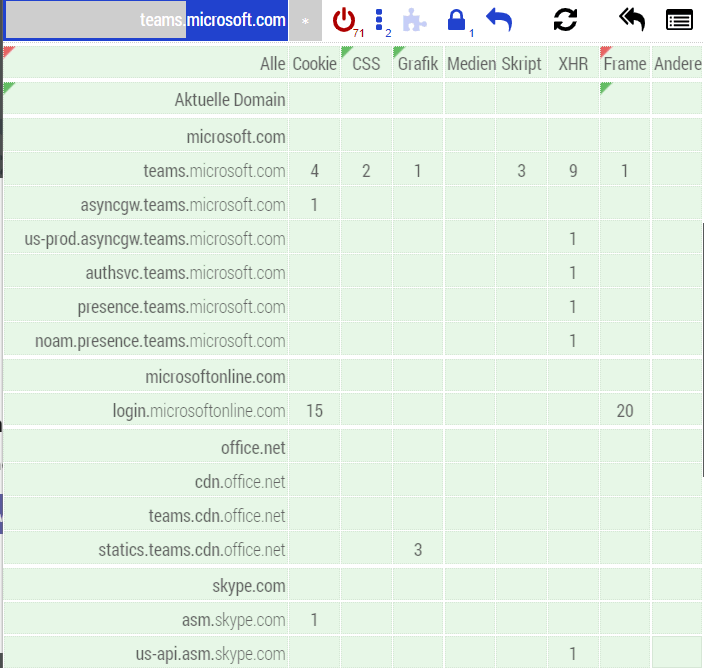
Microsoft Teams |
|
|
MSN.COM - Was sich die Betreiber hier gedacht haben ist schon sehr befremdlich. Ich liste gar nicht alle "Fremdquellen" auf aber der Scrollbalken am Rechten zeigt gut, dass es sehr viele sind und auch die Hostnamen sind suspekt. vielleicht bekommt nun jeder Besucher einen eigenen DNS-Namen, die alle auf gleichen Webserver samt Wildcard-Zertifikat zeigen, nur dass man dann per SNI-Header den Client wiedererkennen kann? Ich habe mal eine URl geschnappt https://c-4tvylwolbz88x24jvvrplzx2evulaybzax2etnyx2ejvuzluzbx2evyn.g01.msn.com und tatsächlich ist ein Wildcard dahinter
|
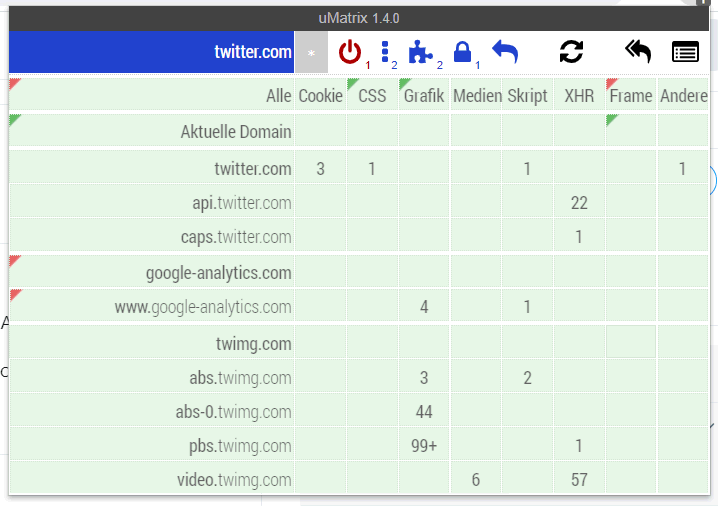
|
Twitter ist dagegen fast schon ein Musterknabe. Ich frage mich natürlich, warum es noch einer gesonderten Domain twimg.com bedarf. Das hätte ja auch noch eine Subdomain sein können. Aber Twitter muss ja auch nicht viel Werbenetzwerke nutzen, wenn Sie die Werbung selbst in den Tweets einbetten und Benutzer sich eh anmelden. |
|
|
Bild.de -Hier werden wieder sehr viele andere Domains eingebunden und aktiv der Zugriff verwehrt, wenn UMATRIX und andere Blocker Zugriffe unterbinden. Also bleibe ich weg und vermisse wohl auch nichts. Das gleiche Bild finden sie auch bei viele anderen Zeitungen und Zeitschriften. Es wäre echt mal an der Zeit, wenn die Zeitungen auf Gegenseitigkeit ein Payment einführen würden. Ich habe z.B. eine Tagesszeitung abonniert, die ich aus Papier und Online lesen kann. Es wäre durchaus interessant, wenn ich mit den Anmeldedaten z.B. ein paar wenige Artikel pro Woche auch bei anderen Zeitungen lesen könnte. |
|



UMATRIX ist nett in der Anwendung und auch einfach einzusetzen aber normale Anwender werden nach kurzer Zeit die Funktion wieder abschalten, das es sehr viele Seiten gibt, die mit der normalen "sicheren" Sperre einfach gar nicht mehr gehen oder nur sehr eingeschränkt funktionieren. Häufig erwischt es z.B. Seiten der Bahn, Lufthansa etc., die bei der Eingabe von Orten per JavaScript und Anfragen an einen Datenbankserver nicht mehr funktionieren.
Die Tücken von JavaScript
Cookies werden durch den Browser alleine anhand einer Information in der HTTP-Antwort gesetzt, aktualisiert und gelöscht. Aber fast keine Seite kommt heute ohne JavaScript aus. Die Skripte hören aber nicht einfach auf zu laufen, Wenn Sie mit den Debugging Tools, Fiddler oder auch mit UMATRIX ihrem Browser mal auf die Finger schauen, dann sehen Sie schon Unarten bestimmter Webseiten.
Wenn Sie z.B. auf msn.de einfach nur stehen, dann wird im Hintergrund jede zweite Sekunden eine Datei nachgeladen und ein Cookie gesetzt.

Im Wasserfall-Diagramm ist das auch zu sehen:

Man muss das nicht gleich als "Böse" abtun aber hier versucht MSN zu erkunden, ob sie immer noch auf die Seite schauen oder die Seite offen ist. Da die MSN-Seite aber sehr oft auch die "Startseite" eines Browsers ist, die vielleicht lange unbeobachtet offen ist, kann MSN damit den Client und seine IP-Adresse sehr lange beobachten. Dann fehlt nur noch die Anmeldung an MSN mit ihrer LiveID um das Puzzle komplett zu machen.
Lokale Speicher
Browser zeigen heute nicht mehr nur heruntergeladene Webseiten an, sondern sind komplette Laufzeitumgebungen für Applikationen, die meist per JavaScript auf dem Client viel Arbeit übernehmen. So gibt es von Microsoft quasi auch "Browser-Version" von Word, Excel, PowerPoint, die in vielen Bereichen den nativen Applikationen schon das Wasser reichen können. Viele andere Dienste arbeiten ähnlich, dass eine Applikation im Browser nur noch Daten von "hinten" abruft und aufbereitet. Der nächste Schritt ist dann die lokale Speicherung von Daten, um wiederholte Downloads zu reduzieren. Der Anbieter spart Bandbreite und der Anwender hat eine "schnellere" Reaktion der Anwendung. Die Anwendung selbst als JavaScript kann schon durch den Cache des Browsers schneller geladen werden.
Die Ablage von Informationen habe ich das erste Mal bewusst gesehen, als Exchange 2013 eine "Offline-Version" von Outlook Wen App angeboten hat.
- Offlineverwendung von Outlook Web App
https://support.office.com/de-de/article/offlineverwendung-von-outlook-web-app-3214839c-0604-4162-8a97-6856b4c27b36 - Outlook Webzugriff
- Mit Outlook im Web (OWA) offline auf E-Mails zugreifen
https://www.windowspro.de/roland-eich/outlook-web-owa-offline-e-mails-zugreifen
Mittlerweile gibt es ganze Applikationen die quasi im Browser laufen. Microsoft Teams ist das beste Beispiel dafür. Die Daten sind natürlich nur "im Browser" aber sie sind eben da. Was sollte einen Tracker nun hindern, ebenfalls solche Daten als "Applikation" in einem lokalen Cache vorzuhalten und einer späteren erneuten Verbindung diesen Status zur Identifikation nutzen?. Mit Chrome können Sie sehr schnell sehen, wer neben Cookies auch "lokale Speicher" nutzt.
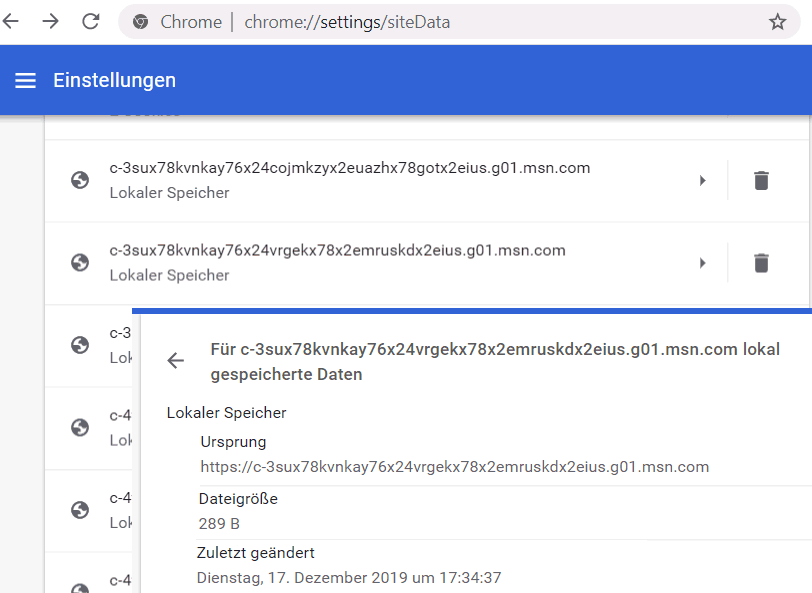
Für Tracker sind das natürlich auch neue Möglichkeiten. Quas über die Hintertür einer WebApp (JavaScript), die einen Status im lokalen "Applikationsspeicher" ablegt, kann der Tracker den Client auch ohne Cookies verfolgen.
Der Browser-Schutz ist löchrig
Die Thematik ist nicht neu und natürlich ist sie mir nicht alleine aufgefallen. Es gibt daher verschiedene Ansätze und Browser, die hier zumindest etwas dagegen unternehmen. Es können "Werbeblocker"-AddOns sein, denn noch ist ihr Client ja der aktive Teil, der Daten abruft und damit sich verrät. Bekannte Vertreter sind z.B.
- Adblock
https://adblockplus.org/de/ - AdAware
https://www.adaware.com/de
Es gibt weitere Anbieter aber es gibt auch Trittbrettfahrer, die ähnlich klingende AddOns kostenfrei verteilen und als Browser-Plug-in noch ganz andere Sachen machen. Allerdings geben Sie die Werbeseiten nicht einfach geschlagen und prüfen, ob ein Client den auch die Werbung nachlädt oder sie nutzen JavaScript, um den eigentlichen Inhalt und die Werbung nachzuladen und so eine partielle Unterdrückung zu vermeiden. Entweder sieht der Anwender dann nichts oder eine große Warnung samt Anleitung, wie man den Blocker für diese Seite bitte wieder ausschaltet. Als mündiger Anwender müssen Sie dann überlegen, ob ihnen der Inhalt der Seite dies dann wert ist.
Andere Tools fokussieren gar nicht alleine auf die Unterdrückung von Werbung sondern steuern feiner, welche Komponenten ein Browser überhaupt nutzt.
- UMatrix-Addon
https://addons.mozilla.org/de/firefox/addon/umatrix/
https://chrome.google.com/webstore/detail/umatrix/ogfcmafjalglgifnmanfmnieipoejdcf
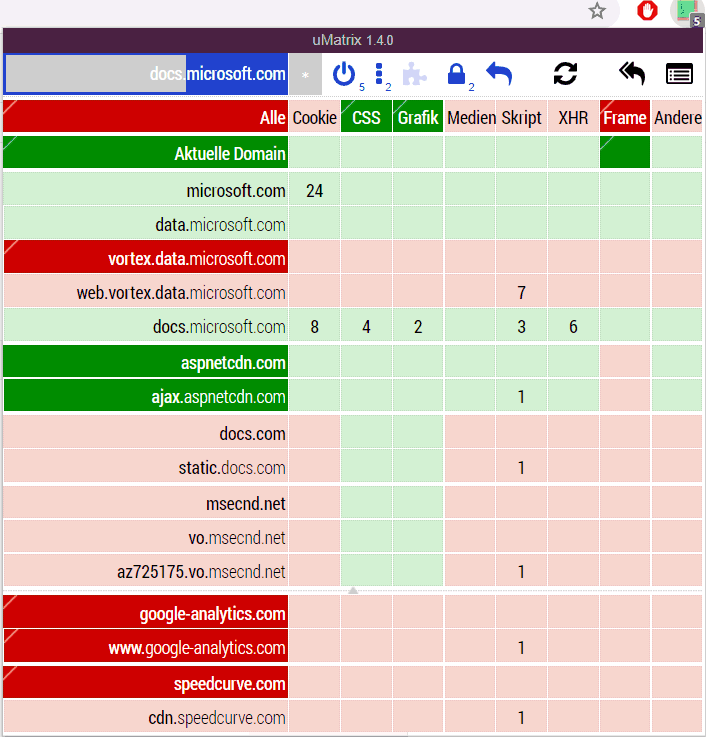
UMatrix finde ich sehr gelungen, da man auf einen Blick zu einer Webseite sehen kann, welche Daten von anderen Domänen nachgeladen werden. zudem kann ich mit einem Klick dann diese Daten erlauben, verbieten oder die Defaults aktiv lassen, wobei die Default (hier hellrot) schon sehr viel wegblocken. Allerdings werden Sie sehr schnell merken, dass viele Webseiten erst einmal nicht mehr wie erwartet funktionieren, wenn Sie Schriften, Skripte etc. von anderen Domänen nachladen. Es dauert also einige Zeit, bis Sie ihre eigenen "Vertrauenswürdigen" Quellen addiert haben. UMatrix kann hier am Beispiel von docs.microsoft.com ja nicht ahnen, dass die Domain "aspnetdn" das Content Delivery Network für JavaScript ist und die Domain "Docs.com" tatsächlich auch zu Microsoft gehört-
Es gibt aber auch komplette Browser, die sich dem Datenschutz oder einem anderen Modell verschieben haben und mehr oder minder eingebaut zumindest Basisfunktionen habe. Mein erster Wunsch wäre ja schon mal das verhindern von "3rd Party Cookies" als Default und vielleicht sogar die Rückfrage beim Download von Inhalten von anderen Domains. Wenn in der Adressleiste "msxfaq.de" steht, dann sollte ich gefragt werden, ob Daten von Googleanalytics oder Werbetracker-Netzwerken geladen werden. Wobei auch hier die Anbieter dann wieder "Subdomains" nutzen.
- Firefox
https://www.mozilla.org/de/firefox/features/adblocker/

- Edge
Microsoft liefert mit Edge sie Januar 2020 einen besseren Trackingschutz
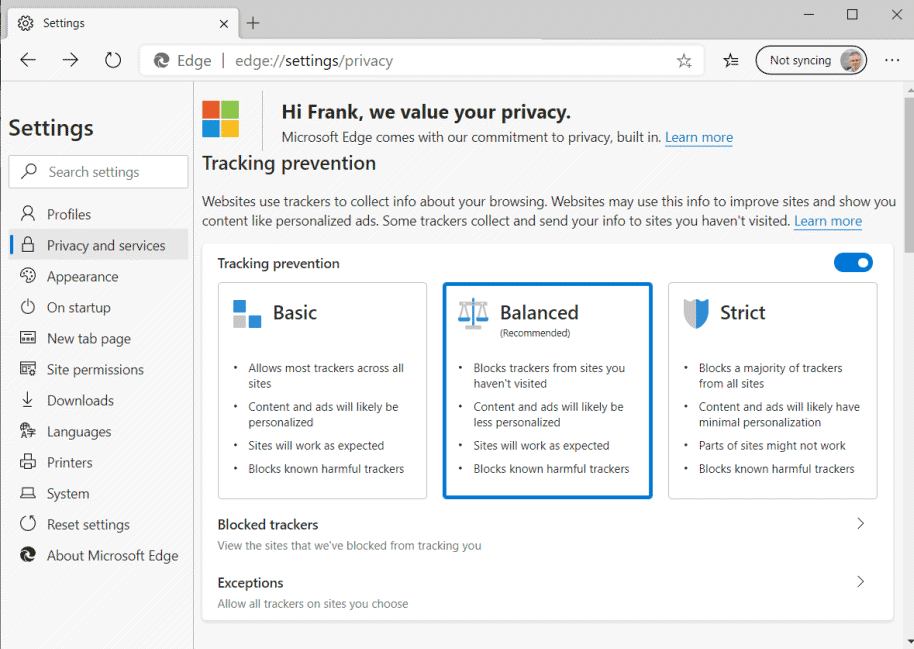
Auch Spuren können sehr schnell gelöscht werden und über "Blocked Trackers" sehen Sie, wie viele Tracker (auch von Microsoft selbst) geblockt wurden
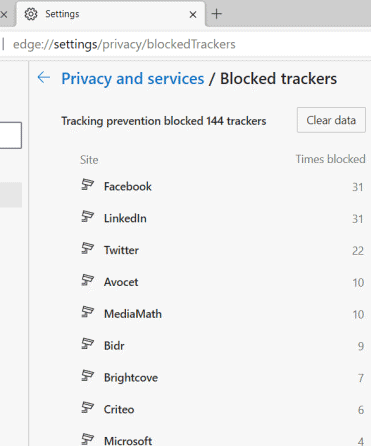
Ein Anfang ist gemacht - Tor Browser
Wer mit Tor surft, hat vermutlich ein sehr hohes Sicherheitsbewusstsein, da der Browser nicht nur versucht solche Tracking-Skripte und Cookies sehr aggressiv zu blocken sondern über das Tor-Netzwerk auch seine Quelle verschleiert. - Brave-Browser
Ein anderer Browser, der zwar auf die Chromium-Engine setzt aber "aufdringliche" Werbung verhindert und Einnahmen von der angezeigten Werbung" an die besuchten Seiten weiter gibt.

Ich bin neugierig, wie das Verfahren funktioniert. Aber ein einmaliger Aufruf und etwas Surfen auf "heise.de" hat zumindest einen mächtigen Eindruck in der Statistik hinterlassen:

Ich werde das mal weiter beachten - Waterfox
https://www.waterfox.net/
Angeblich auch ein Firefox-Derivat, der aber keine Telemetrie u.a. melden soll.
Welchen Ansatz sie nun gehen, bleibt aber wieder ihnen überlassen.
Die "Nachbarn"
Bislang habe ich mich auf meinen Client bezogen. Das ist aber auch nicht weit genug gedacht, denn mehrere Programme auf ihrem PC aber auch alle anderen Nutzen in ihrem LAN erscheinen extern mit der gleichen öffentlichen IP-Adresse. Auch wenn Sie auf ihrem PC also alle Vorkehrungen gegen Tracker getroffen haben, kann ihr Fernseher, das Smartphone, die App ihrer Kinder mit Werbebanner natürlich Spuren hinterlassen. Über den Weg kann also ihr Surf-Verhalten doch wieder auf den Haushalt zurück geführt werden. Wenn Sie sich dagegen schützen wollen, dann bleiben ihnen nur härtere Filter für alle Teilnehmer in ihrem LAN oder der Wechsel auf andere IP-Adressen.
- DNS-Hole (z.B.
https://de.wikipedia.org/wiki/Pi-hole)
Wer keine Lust hat, auf jedem Client mit Filtern und Sperren zu arbeiten, kann allen Clients einen alternativen DNS-Server, z.B. PiHole, übergeben. Alle DNS-Anfragen gehen dann an diesen Service, der entsprechende Antworten gibt und die URLs von Trackern blockiert. Ganz sicher ist das aber nicht, denn wer sollte einen Tracker hindern in einem JavaScript direkt eine IP-Adresse anzusprechen. Das geht dann zwar nicht per HTTPS aber dem Tracker geht es ja nur drum die Daten zu erhalten. - Firewall
Ein weiterer Weg ist natürlich eine mehr oder minder ausgereifte Firewall, die nicht nur die DNS-Anfragen umleitet sondern auch die IP-Verbindungen unterbindet. Im Privatbereich gibt es hier mit PFSense schon eine interessante Lösung.
https://www.computing-competence.de/2018/06/11/mit-pfsense-werbung-und-potentielle-angriffe-blockieren-ala-pihole/
Der andere Ansatz ziel auf die Verschleierung der eigenen IP-Adresse. Da kommen eigentlich zwei Ansätze zum tragen.
- VPN oder Freifunk
Sie können mit ihrem PC oder einen Router ein VPN zu einer Gegenstelle aufbauen, die keinen Rückschluss auf Sie als Surfer zulässt. Ich habe dazu einfach einen Freifunk-Router aufgebaut, den auch Nachbarn und vor allem Gäste gerne mit nutzen können. Für einen Tracker wird es da schon schwer, weil meine dann sichtbar IP-Adresse nicht mehr auf mich als Haushalt zugeordnet ist. Ganz sicher ist das aber nicht, da auch andere Programme, die meine Identität preisgeben, auch die Adresse nutzen.
Bei einem VPN allerdings kann der VPN-Betreiber natürlich die identifizieren und ihre Ziele erkennen. - Tor-Browser
Viel sicherer, aber halt auch deutlich langsamer, ist die Nutzung des Tor-Browsers, bei dem meine Daten über mehrere Stationen unterwegs sind. Der Anbieter kann sie nicht über die IP-Adresse zurück verfolgen und wenn der Browser Cookies etc. blockt, dann bleiben Sie anonym. Wenn Sie aber in einem Fenster eine "böse Seite" aufrufen, die Werbetracker1 nutze und sie im gleichen Browser auch eine "gute Seite" aufrufen, die ihre Identität kennt aber den gleichen Werbetracker nutzt, dann war es das vielleicht schon wieder.
Selbst mit Zusatzprodukten und Blockern bleibt es knifflig wirklich nicht nachvollziehbar zu sein.
IPv6 - der neue Tracker
Seit August 2020 habe ich eine FTTH-Anbindung der deutschen Glasfaser und damit keine "öffentliche IPv4-Adresse" mehr. Die IPV4-Adressen sind eh knapp und immer mehr Provider unterstützen aktiv die Kunden über IPv6 zu surfen. Das geht recht gut und ist auf jeden Fall sinnvoll.
Allerdings wird dabei übersehen, dass der Client auch per IPv6-Adresse trackbar ist und aufgrund der immensen Adressanzahl kann jeder Kunde sogar ganz viele Adressen erhalten. Ich bekomme bei DG z.B. 256 Subnetze a 2 Mrd IP-Adressen. Mein Router hat eine öffentliche IP-Adresse, die er anscheinend dauerhaft behält. Aufgrund der Mengen ist es aber auch nicht mehr erforderlich und quasi nicht erwünscht ein "NAT" zu machen. Haben sich früher viele Clients hinter meiner einen öffentlichen IPv4-Adresse versteckt, geht nun jeder Client mit einer öffentlichen IPv6-Adresse raus.
Da hilft es auch nicht viel, wenn ein Client mehrere IPv6-Adressen hat und speziell temporäre Adressen auch wechseln kann Das Subnetz bleibt in allen Fällen gleich und damit ist der Anschlussinhaber. Diese Zuordnung bleibt sogar sehr lange bestehen. Eine öffentliche IPv4-Adresse eines DSL-Routers ändert sich nach der Zwangstrennung bzw. alle 24 Stunden Bei IPv6 muss der Provider darauf keine Rücksicht mehr nehmen.
Als "Werber" würde ich sehr schnell bestimmte Informationen nur noch per IPv6 erreichbar machen und so einen schönen Datenbestand aufbauen.
Tracking per App
Auf einem PC lassen sich ja sehr einfach andere Browser verwenden und viele AddOns und Drittprogramme versprechend Abhilfe und Lösungen, auch wenn diese alle mehr versprechen, als sie halten können. Was ist da dann mit all den Apps auf Smartphones und Tablets, die sich auch noch in ihrem Haus bewegen? Hier ist das Rennen sogar noch herausfordernder, denn ein Smartphone hat heute immer auch eine SIM-Karte und GPS-Empfänger. Beide Module sind auch immer an und per WLAN kommt noch eine dritte Ortung dazu. Wenn nu eine App auf ihrem Gerät den Standort nach Haus meldet, kennt der Anbieter ihren Standort und die IP-Adresse. Die meisten Apps haben einen Passus ,der das Weiterverkaufen dieser Daten an Werbenetzwerke erlaubt.
Eine Wetter App kann natürlich den Standort per GPS erfassen aber für die Wettervorhersage würde auch die GSM-Funkzelle reichen. Auch andere Apps versuchen sich immer die Berechtigung zur Standortabfrage geben zu lassen. Selbst im Grunde nützliche Programme wie FING, fragen aus meiner Sicht nur dafür den Standort ab. Wenn man "Weiter ohne Erlaubnis" klickt, dann funktioniert alles wie gehabt.
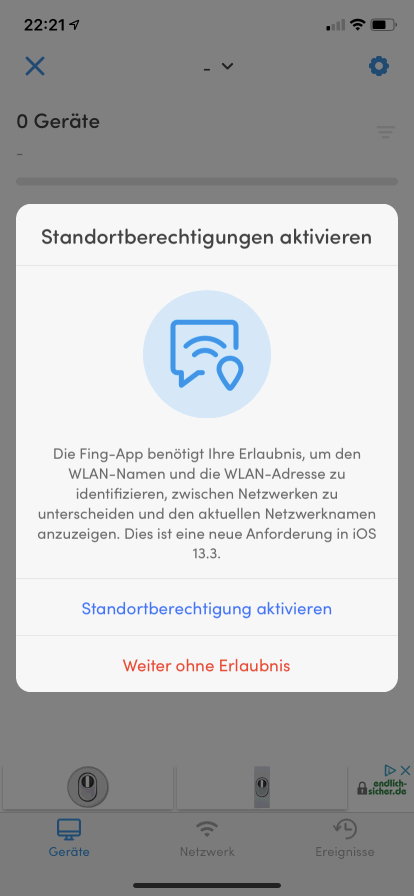
Aber auch "TrackingIDs" kommen in Browser zum Einsatz. Bei IOS können Sie des Abschalten aber zumindest bei meinem mit IOS 13.3 im Dez 2019 installierten IPhone 11 war die Einstellung nicht eingeschränkt.
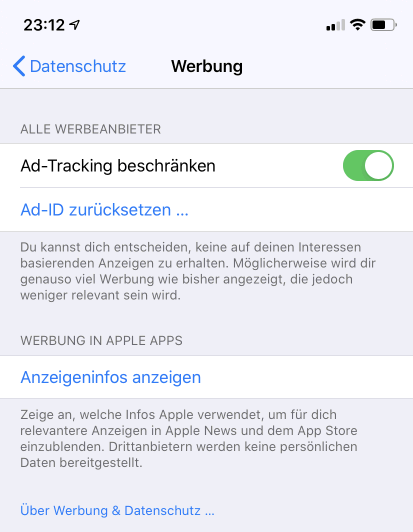
ich habe hier den Schieber natürlich aktiviert. Damit werde ich zwar nicht weniger getrackt aber wenn das Smartphone immer wieder neue Ad-IDs erzeugt, wird die Verknüpfung der Daten kniffliger. Zumindest solange nicht eine App ihre eigene ID erstellt und mit übermittelt. Die Einstellung gilt ja nur für Safari.
- iOS 13: Datenschutzfunktion macht standortbasierten
Werbeanbietern zu schaffen
https://www.heise.de/mac-and-i/meldung/iOS-13-Datenschutzfunktion-macht-standortbasierten-Werbeanbietern-zu-schaffen-4634962.html - AccuWeather: iPhone-App übermittelt Standortdaten an
Werbeanbieter
https://www.heise.de/mac-and-i/meldung/AccuWeather-iPhone-App-uebermittelt-Standortdaten-an-Werbeanbieter-3809784.html - Trojanische Apps sind überall!
http://spam.tamagothi.de/2012/02/15/trojanische-apps-sind-ueberall/
Auch Aps "sammeln". - Zugriff auf Zwischenablagen sind ein Problem -Aber
wohl nicht für Apple oder TikTok
https://uk.pcmag.com/mobile-operating-system-2/125007/malicious-ios-apps-can-quietly-steal-data-from-the-clipboard - TikTok schnappt sich von iPhone-Nutzern regelmäßig die
Zwischenablage
https://www.heise.de/news/TikTok-schnappt-sich-von-iPhone-Nutzern-regelmaessig-die-Zwischenablage-4796222.html - iOS 14: Auch LinkedIn und Reddit überwachen die
Zwischenablage
https://www.heise.de/news/iOS-14-Auch-LinkedIn-und-Reddit-ueberwachen-die-Zwischenablage-4836108.html
Tracking per Mail
Bei all dem Tracking per Browser sollte es sie nicht wundern, dass die gleichen Firmen natürlich auch bei Mails den Empfänger analysieren. dazu dienen in der Mail eingebettete Bilder, die Sie nachladen müssen um den Inhalt sinnvoll lesen zu können oder gleich personalisierte Links und Bilder. Hier ein ziemlich dumm gemachtes Beispiel.
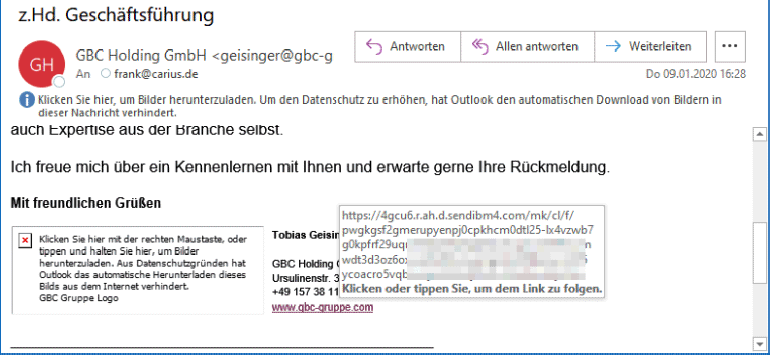
Mein Outlook lädt natürlich nicht das Bild nach. Aus dem Sourcecode ist aber zu erkennen, woher es geladen würde:
<img alt=3D"GBC Gruppe Logo" height=3D"90" = src=3D"http://4gcu6.img.ah.d.sendibm4.com/im/2609766/7f68e56dfe6a52ac84ae= xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx= xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx= xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx= 2dKUiRYLeJ8qRxF0Z6PVQ36KPHnpzWGw" style=3D"color: rgb(34, 34, 34); = font-family: Arial, Verdana, sans-serif; font-size: 12px;" width=3D"258" = sib_img_id=3D"0"/>
Die Quelle des Bildes verweist auf den Server eines Mailversanddienstleisters, über den solche Aussendungen getrackt werden. Wenn Sie das Bild nachladen oder den Link klicken, dann kann der Versender individuell für jede Mail sehen, wann diese gelesen wurde. Er bekommt kostenfrei auch noch ihre zu dem Zeitpunkt gültige IP-Adresse und noch ein paar weitere Informationen von ihrem Browser. Das gilt übrigens auch, wenn Sie die Mail weiterleiten oder später noch mal öffnen. Das können alles interessante Daten für einen Versender sein.
Wenn Sie dann über die Links in einer Mail auf die Webseite gehen, dann sind sich schon sehr sehr gut vorqualifizierter Besucher, denn über den individuellen Link hat der Webseitenbetreiber schon ihre Mailadresse. Diese Verknüpfung wird er sicher nicht so schnell vergessen wollen und legt diese ziemlich sicher auch in einem Cookie ab, damit Sie später auch wiedererkannt werden.
Insofern lade ich quasi nie Bilder in Mails nach und auch Links tippe ich ab oder schaue mir zumindest genau an, wohin diese in Realität gehen.
Versender versuchen des natürlich zu erschweren, in dem essentielle Informationen in der Mail nur über das Bild zu erhalten sind oder die Formatierung ohne Bilder das Lesen sehr erschwert. Auch die Links können über Link-Verkürzer natürlich weiter unkenntlich gemacht werden.
Tracken per Link und Linkverkürzer
Personalisiert Links kommen nicht nur in Mails vor. Auch an anderer stelle werden Links gesetzt, die aber gar nicht direkt beim Ziel landen. Beim Klick auf einen normalen Link im Browser würde der Browser direkt dort hin springen. Das Ziel könnte über den Refer-Header erkennen, woher sie kommen. Die abgehende Seite könnte nicht erkennen, dass Sie den Link angeklickt haben. Dieses Wissen ist für Seiten aber wichtig, da Sie damit ja ihr "Interesse" besser ausforschen können. Daher können Sie sicher sein, dass die viele Links in der Hinsicht "vergiftet" sind und entweder per JavaScript bereichert werden oder auf eine andere Seite verweisen. Hier einmal am Beispiel eines Bitly-Links in einem Twitter-Tweet:
Der Schreiber der Nachricht hat den Linkverkürzer "bit.ly" genutzt, um vermutlich Platz beim Tweet zu sparen.
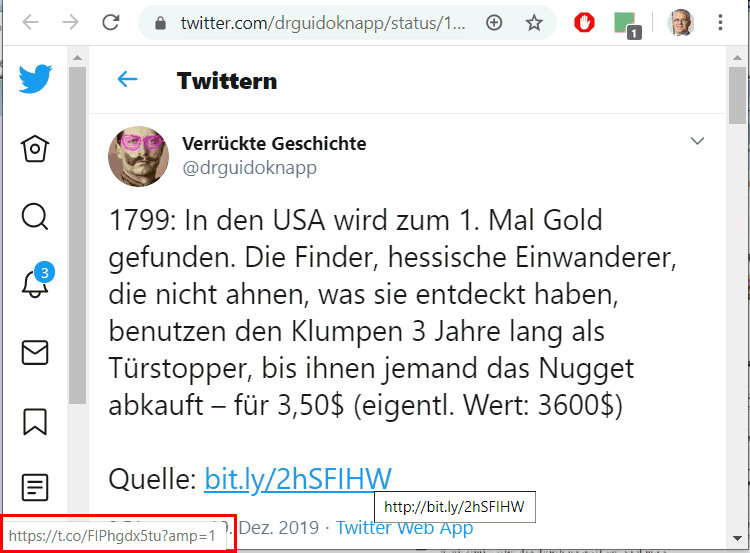
Aber nebenbei kann er über bit.ly natürlich nachvollziehen, wie viele Personen dem Link gefolgt sind. Ansonsten hätte nur die echte Zielseite das per Refer sehen können. Durch den Umweg über Bit.ly kann der Dienst natürlich sehen, dass der Surfer von Twitter kommt und zum Ziel will und kann direkt auch noch Cookies setzen. Diesmal sind es aber nicht mal "3rd Party Cookies" und das tut Bit.ly natürlich auch. Wenn Sie direkt auf Bitly gehen, dann können Sie das auch lesen.
Beim Klick auf den Link in Twitter sehen Sie diese Meldung aber nicht. Ein Blick in einen HTTP-Trace offenbart aber mehr Details

Zuerst sehen Sie, dass ich gar nicht bit.ly sondern eine URL bei t.co ansurfe. Ich habe oben im Bild das auch rot markiert, dass der Browser (Hier Chrome) sehr wohl anzeigt, dass der physikalische Link woanders hin weist. Twitter nutze aber den Title-Tag um dieses Verhalten zu verschleiern

So bekommt Twitter also mit, dass Sie den Link im Tweet angeklickt haben. t.co leitet sie dann aber nicht mal mit einem "301 moved permanently" oder "302 moved temporarily" um, sondern antwortet mit einem 200 OK und nutzt das META-Tag Refresh und setzt natürlich mal schnell einen Cookie.

Auf die Funktion, dass der Browser nun die URL prüft, gehe ich im folgenden Abschnitt ein. Der nächte jetzt relevante Aufruf ist die bit.ly-URL und die Antwort
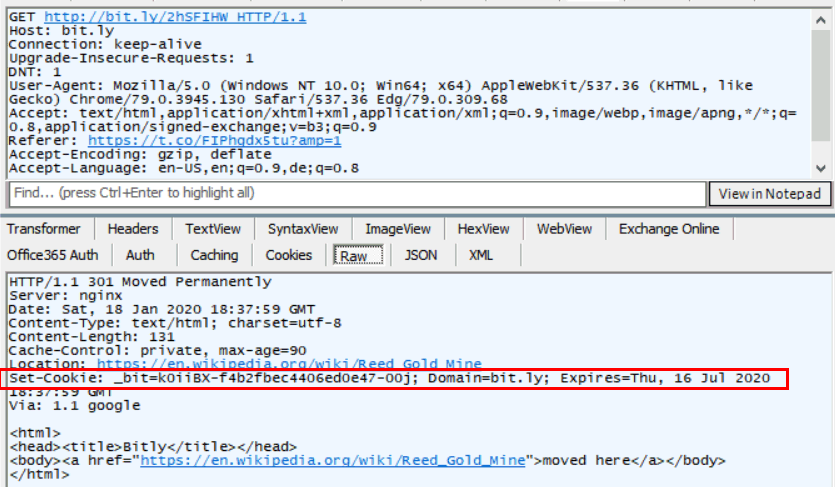
Bitly sendet ein "301 Moved Permanently" mit dem Location-Header und zur Sicherheit auch noch mal eine kleine HTML-Seite. Soweit alles erwartet aber ich sehe keinen Grund, warum für diese Funktion bei mir ein Cookie mit einer Gültigkeit von 6 Monaten gesetzt werden muss. Das ist kein 3rd Party Cookie so dass die meisten Browsereinstellungen den nicht verhindern und Sie damit bei jeder weiteren Nutzung von bit.ly-Links eindeutig zugeordnet werden können. Nur wenn Sie wirklich 6 Monaten lange ununterbrochen eine bit.ly-URL von diesem Browser ansurfen, geht die Spur verloren.
Auch die von Bit.ly gelieferte Ziel.URL wird von Browser geprüft und dann kommt der eigentliche Zugriff auf die Wikipedia-URL
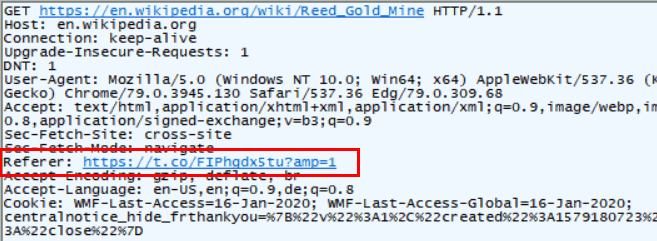
Da Twitter die Umleitung über einen "200 OK" mit einem META-Refresh statt einem 301/302 umsetzt, kommt bei Wikipedia als Referer nur der Kurzlink an. Die Zielseite kann also nicht auf den Tweet zurück schließen, obwohl das genau für diverse Seiten zur Reichweitenermittlung interessant wäre.
Ich werte den REFERER bei der MSXFAQ bislang nur aus, wenn ich Missbrauch vermute, z.B. weil Bilder in anderen Seiten eingebunden werden. Durch das Vorgehen von Twitter kann ich aber nicht sehen, in welchen Tweets die MSXFAQ erwähnt werde. Da versagt Twitter also.
Solche "Umleitungslinks" verwenden quasi alle größeren Seiten und insbesondere Suchmaschinen können so ermitteln, welches Ergebnis Sie in einer Suche angeklickt haben. Google verbirgt das Verhalten aber durch JavaScript-Tricks. Wenn Sie nach MSXFAQ suchen und mit der Maus nur über den Link fahren, dann sehen Sie in der Adressleiste im Browser die gleiche URL. Wenn Sie dann aber auf den Link drücken und die Maus gedrückt halten, dann tauscht JavaScript den angezeigten Link durch den "Echten" Link aus.
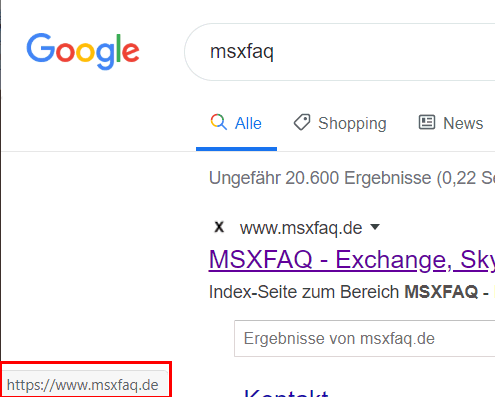
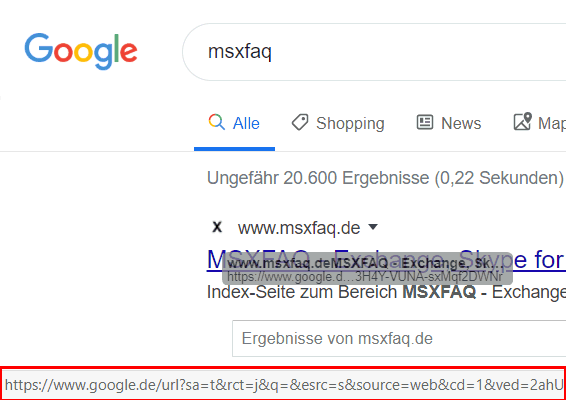
Ein Blick in den HTML-Code verrät es

Ein "onmousedown"-Event triggert die Funktion "rtw" mit entsprechenden Parametern an, um die URL beim "Klick" umzuschreiben. Einen technischen Grund dafür gibt es nicht, hier eine Ehrenrunde zu fahren. Aus meiner Sicht ist die Verschleierung der dann tatsächlich angesurften URL der einzige Grund.
Das Umschreiben von URL bei "Mausklick" ist natürlich auch eine beliebte Option für Malware, um Scanner zu überlisten, die URLs in einer Webseite durchsuchen und auf Malware prüfen. Eigentlich fehlt mir hier dann im Browser eine Funktion, die "href"-Felder eines Links nachträglich zu ändern.
Welt und Uni-Göttingen
Aber auch seriöse Zeitschriften müssen mit Werbung Geld verdienen und hier eine auffällige Werbung, die ich nicht auf einer großen Tageszeitung erwartet hätte. Das hat doch eher MSN-Niveau.
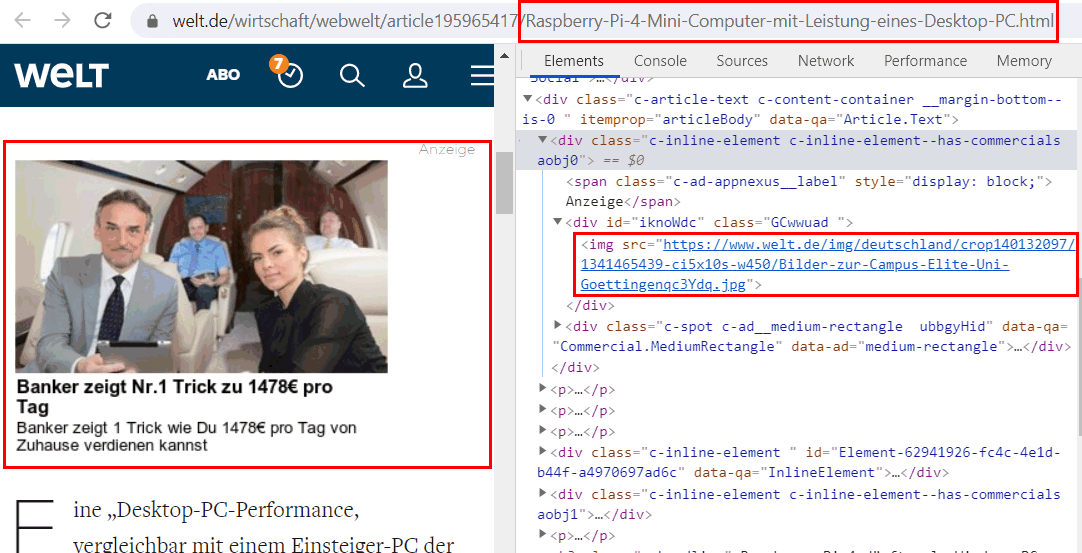
Interessant ist hierbei, dass zumindest laut HTML-Code das Bild selbst keinen Hyperlink hat. Es ist aber dennoch anklickbar. Ich tippe auf ein globales "OnClick"-JavaScript, aber habe es nicht weiter untersucht. In Fiddler sehe ich dann aber einen Request, der erklärt werden müsste. Auf den ersten Blick sieht es aus wie ein Bild, welches geladen werden soll. Die Endung ist JPG aber schon der Pfad unterscheidet sich gegenüber dem IMG-Link im Quelltext. Allerdings frage ich mich wirklich, was die Welt und die Werbung mit der "Elite Uni Göttingen" (https://www.uni-goettingen.de/) am Hut hat.

Wenn Sie dann aber glauben dass nun ein Bild geladen wird, dann täuschen Sie sich. Menschen würden die Endung "JPG" mit einem Bild verknüpfen aber Computer beachten den "Content-Type" in der Antwort, der hier eine HTML-Datei samt weiteren Skripten ausliefert. Es ist zumindest ungewöhnlich sich so weit vom üblichen Verfahren weg zu bewegen.
Es geht dann über mehrere Zwischenstationen, bei denen der Surfer überall seine Spuren hinterlässt, Cookies gesetzt werden und ich sicher dem nicht zugestimmt habe:
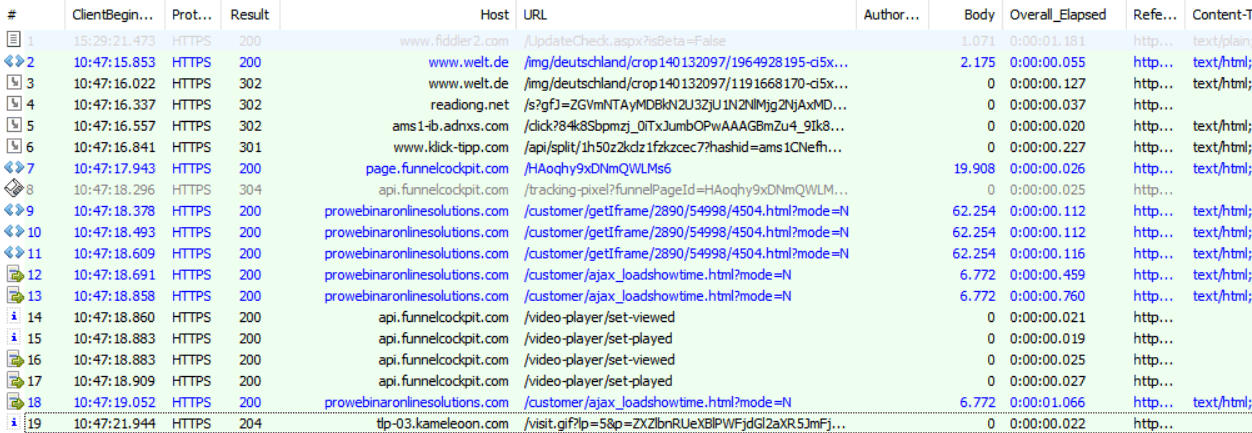
Die Zieladresse ist dann natürlich wieder eine Seminarseite, bei der man sich anmelden kann, um zu hören, wie der Trick funktioniert. Natürlich gegen Geld, denn anscheinend kann der Autor selbst seine Tipps ja nicht umsetzen. Vorträge halten scheint ja lohnender zu sein.
Tracking durch "Safe Browsing"
Bei der Analyse des bit.ly-Links haben Sie auch zwei Zugriffe gesehen, die auf eine Schutzfunktion des Browsers hinweisen.

Sowohl vor dem Aufruf der Bit.ly-URL als auch der Wikipedia-URL hat hier der Edge-Browser bei Microsoft nachgefragt, ob die URLs denn "sicher" sind.
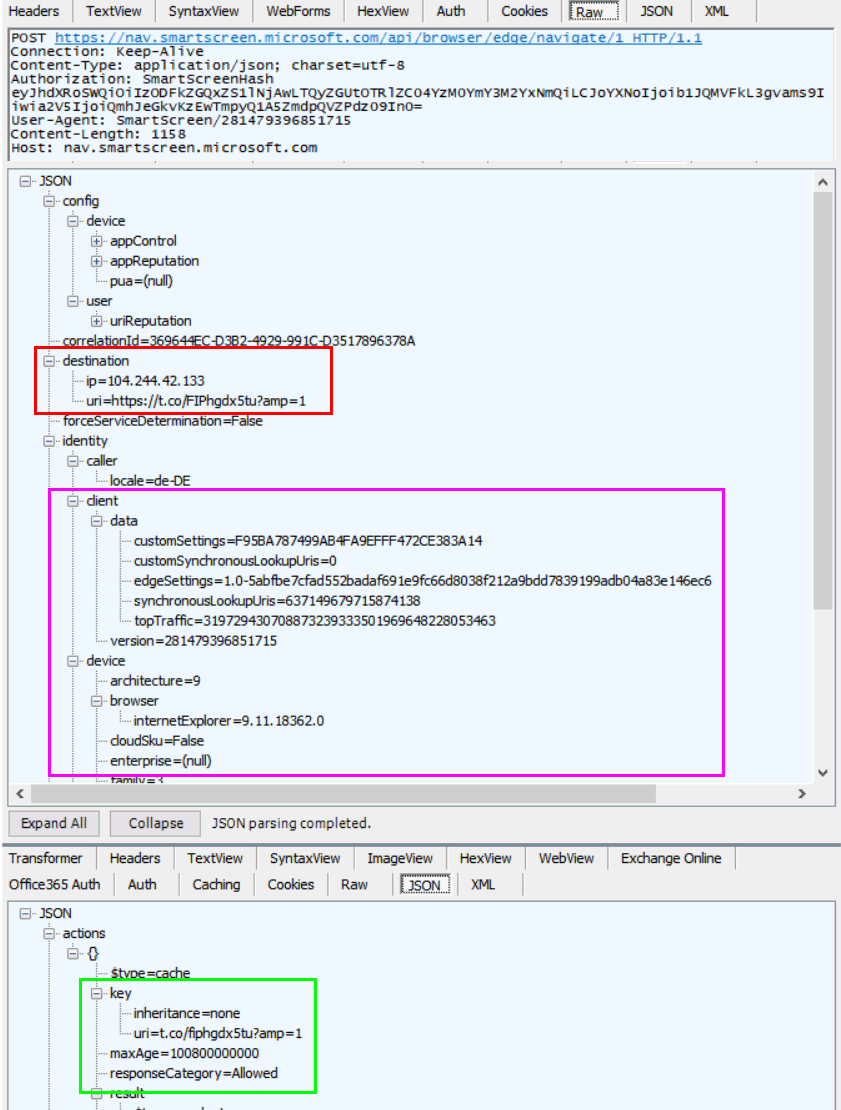
Aus Sicht des Anwenders und der Allgemeinheit ist so eine Funktion natürlich wünschenswert, um böse Webseiten bei unbedarften Anwendern direkt zu blocken oder eine Warnung einzublenden. Auf der anderen Seite muss ja jemand für diese Funktion bezahlen.
- Betrieb der Plattform
Wenn alle Browser der Welt jede angesurfte URL bei Microsoft prüfen, dann kommen da schon einige Daten zusammen. Der Betrieb dieser Plattform kostet natürlich Geld - Pflege der Daten
Der Filter ist nur so gut, wie die "Liste der bösen URLs gepflegt wird. So eine Reputationsdatenbank ist durchaus eine Herausforderung und bedarf auch kontinuierlichen Anpassungen
Microsoft verdient Geld mit den Windows-Lizenzen und der darauf laufende Edge-Server ist Bestandteil des Betriebssystems. Ob das aber zur Finanzierung reicht, kann ich nicht sagen. Interessant kann der so gewonnene Datenschatz natürlich schon für eine weitere Verwertung sind.
Sie können aber sicher sein, dass auch andere Browser und die Antiviren-Produkte und Browser AddOns die gleichen Techniken nutzen. Die Frage ist immer, an wen die Daten weiter gegeben werden, ob Sie widersprechen können und wie freizügig der Anbieter diese Optionen kommuniziert.
- Microsoft SmartScreen
https://en.wikipedia.org/wiki/Microsoft_SmartScreen - SmartScreen: FAQ
https://support.microsoft.com/en-us/help/17443/microsoft-edge-smartscreen-faq - Google Safe Browsing
https://en.wikipedia.org/wiki/Google_Safe_Browsing
Tracking durch Virenscanner
Die "Bewegungsdaten" von Benutzern sind aber sogar so viel Wert, dass selbst erforderliche Programme solche Daten erfassen und melden, die sich erst einmal nicht auf dem Radar haben. Es ist auf jeden Fall keine gute Idee auf einem PC ohne Virenscanner zu arbeiten. Frühe war der Markt recht klar, dass man ein passendes Produkt gekauft und eingesetzt hat.
Mit Windows Defender liefert Microsoft für Windows einen Virenscanner kostenfrei mit. Für Dritthersteller hat das aber nun die Herausforderung, einen Lücke im Markt zu finden, indem Sie ihre Produkte um Zusatzfunktionen (z.B. Firewall-Funktionen, Management) bereichern. Diese Funktionen sind manchmal natürlich auch die Lücke für Angriffe.
Private Anwender suchen natürlich erst einmal nach kostenfreie Lösungen. Jeder AV-Hersteller bietet auch solche "beschränkte" Funktionen an, die meist dann nur ein Realtime-Scanner sind und mit Werbung für ein Upgrade auffallen.
Der durch den Anwender installierte Scanner integriert sich aber tief ins System und kann deutlich mehr. Sie sollten nicht davon ausgehen, dass die Hersteller nicht anderweitig noch Einnahmen mit ihren Daten generieren. Der AV-Scanner überprüft mit ihrem Einverständnis natürlich auch die von ihnen angesurften Webseiten samt Inhalt. Diese "Linksammlung" ist durchaus für Werbefirmen interessant.
- Mitsubishi-Hack: Sicherheitslücke in
Anti-Viren-Software als Einfallstor
https://www.heise.de/newsticker/meldung/Mitsubishi-Hack-Sicherheitsluecke-in-Anti-Viren-Software-als-Einfallstor-4646386.html
Angreifer haben wohl eine damals bekannte Lücke des Virenscanners ausgenutzt. - Leaked Documents Expose the Secretive
Market for Your Web Browsing Data
https://www.vice.com/en_us/article/qjdkq7/avast-antivirus-sells-user-browsing-data-investigation - Avast Antivirus verkauft massenhaft
Browser-Daten seiner Nutzer
https://www.heise.de/newsticker/meldung/Avast-Antivirus-verkauft-massenhaft-Browser-Daten-seiner-Nutzer-4646926.html - Wie Avast die Daten seiner Kunden
verkaufte
https://www.heise.de/ct/artikel/Wie-Avast-die-Daten-seiner-Kunden-verkaufte-4657290.html
Tracking per Login
Kurz vor Schluss möchte ich noch auf eine weitere Options zur Verknüpfung von bislang unbekannten Anwendern und deren Spuren im Netzwerk zu einer verifizierten Identität aufmerksam machen. Die meisten Anwender haben ein oder mehrere Konten bei verschiedenen Diensten und melden sich dort an. Diese Anbieter wie Microsoft, Google, Facebook, Twitter, LinkedIn u.a. verifizieren die Anwender natürlich. DAs passiert z.B. über eine Mail an ihr Postfach oder eine SMS an ihre Rufnummer. Beide Wege werden auch gerne zur Wiederherstellung bei einem vergessenen Kennwort oder als zweiter Faktor genutzt.
Auch andere Seiten wüssten gern wer sie sind und bieten individualisierte Dienste an. Anstatt dort nun noch eine Konto anzulegen, bieten immer mehr Webseiten eine Anmeldung mit diesen bekannten Diensten an. Die Webseiten vertrauen quasi den großen Authentifizierungsdiensten und nebenbei gibt es sogar noch ein Sigle-SignOn kostenfrei dazu.
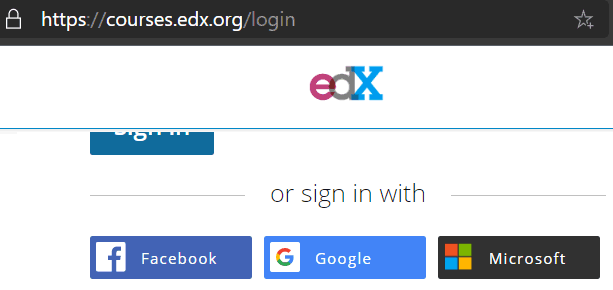

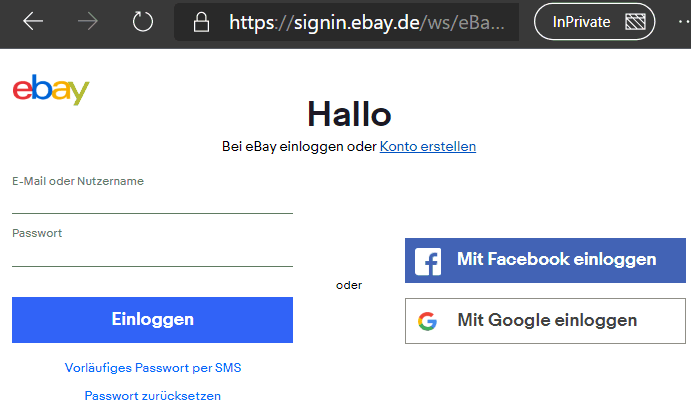
Damit senke ich als Anbieter natürlich die Eintrittshürde. Sie müssen sich nicht schon wieder einen Benutzernamen und Kennwort ausdenken, Geheimfragen zur Rücksetzung und Telefonnummern zur Verifikation hinterlegen sondern können gleich loslegen. Der Anbieter "vertraut" dazu den Authentifizierungsdaten des Anbieters, aus denen er oft nicht nur die notwendigen sondern auch für den Dienst gar nicht erforderlichen zusätzlichen Informationen anfordert.
Viel interessanter ist dieses Wissen aber für die Anbieter (Google, Facebook, Twitter, Instagram etc.), die jedes Mal die Anmeldung bestätigen und damit ein eine lückenlose Nutzungshistorie von ihnen bekommen. Google und Go weiß also nicht nur, welchen Dienst sie nutzen, sondern auch wann und von wo und mit welchen Client.
Rein technisch ist es diesen Diensten sogar möglich, ihre Identität zu kapern. Ich bin sogar sicher, dass dies schon gemacht wird. Wenn also sie als Verdächtiger in einem Ermittlungsverfahren ihre Zugangsdaten zu Google bereitstellen oder Google und Co per Durchsuchungsbeschluss gezwungen werden, die Daten auszuhändigen, dann haben Sie zugleich auch den Zugriff auf alle damit verbundenen Dienste.
- FAZ: Missbrauch programmiert
https://www.faz.net/aktuell/technik-motor/digital/login-mit-facebook-kann-gefaehrlich-werden-12860066.html
Werbenetzwerker und Strafverfolgung
Einen anderen Aspekt habe ich hier aber noch nicht beleuchtet. Gegen wir mal davon aus, dass Nutzer des Internets durch die verschiedenen Werbenetzwerke nach nachverfolgt werden, dann haben die Werbenetzwerke natürlich eine ziemlich gute Einschätzung, wer der jeweilige Surfer ist. Sie kennen nicht nur die Zeit und die IP-Adresse (Ausnahme Tor-Browser) sondern mehr oder weniger auch das Umfeld, in dem er sich bewegt. Ich warte ja darauf, dass ich einem Werbenetzwerk eine IP-Adresse und einen Zeitpunkte gebe, uns sie mir dann die Daten dazu verkaufen. Nichts anderes machen ja Creditreform, Schufa und andere Dienstleister auch.
Ich wüsste nicht mal, wen ich da fragen sollte, aber ich kann mir schon denken, dass Ermittlungsbehörden auch diese Informationen anzapfen. Sie haben zwar auch die Möglichkeit über Provider an die IP-Adressen und Verbindungsdaten zu kommen aber ob die Provider auch alle DNS-Anfragen, TCP-Verbindungen etc. protokollieren, kann ich nicht sagen. Aber es ist anzunehmen.
Geheimdienstliche Massenüberwachung vs. Menschenrechte
https://media.ccc.de/v/36c3-11141-geheimdienstliche_massenuberwachung_vs_menschenrechte
- CCC | CCC analysiert Münchner
Staatstrojaner FinSpy
https://www.ccc.de/de/updates/2019/finspy - Daten-Speicherung.de – minimum data,
maximum privacy
https://www.daten-speicherung.de/index.php/ueberwachungsgesetze/
Nicht nur die Werbung sammelt Daten
Einschätzung
Der Wettbewerber zwischen Werbeindustrie, Tracker, Geheimdienste, etc. auf der einen Seite und für Datenschutz sensiblen Anwendern und Firmen auf der anderen Seite wird auch zukünftig weiter gehen. Der Großteil der Anwender wird aber weder das technische Verständnis noch die Möglichkeiten haben, sich gegen ihre Datenerfassung und Spionage zu wehren. Schade eigentlich, dass es im Internet hier eher wie im "wilden Westen", einer nicht regulierten Umgebung, zugeht. Ich bin nicht mal sicher, ob der Gesetzgeber überhaupt ein Interesse hat, denn die Daten der Werbefirmen lassen sich auch gut für geheimdienstlicher Aufgaben oder Ermittlungsbelange verwenden. Da das Internet "global" ist. können geografische Gesetze eh kaum was helfen. Nach Ländern segmentierte "Internets" sind auch kein erstrebenswertes Ziel, auch wenn diverse Staaten damit schon experimentieren.
Es könnte aber die Wirtschaft selbst regeln, indem sich Werbung und Nutzen einpendeln und exzessives Verhalten einiger Anbieter negativ auffällt und dann geblockt wird. Es hängt aber auch von einem aktiven Feedback der Leser die entsprechenden Redakteure und Webseiten ab, die solche negativen Auswüchse kritisieren und zu einem Umdenken führen. Aber auch die Besucher sollten auf Dauer verstehen, dass nichts kostenfrei ist oder wie ein Spruch sagt: "There is no free lunch" (https://de.wikipedia.org/wiki/TANSTAAFL). Also müssen Sie abwägen, wo sie sich wie bewegen.
Dass Werbung aber ihren Bandbreite, ihre Energie, ihre CPU-Last und letztlich ihr Zeit kostet, wird sich nicht ändern. Werbung ist ja auch ein legitimes Mittel zur Finanzierung und findet sich auch in Kauf-Zeitschriften, Öffentlich-rechtlichem Rundfunk etc. Wenn eine Seite Werbung einstellt, ist das auch tolerierbar, aber aus meiner Sicht eben nicht über die Einbindung von anderen URLs, von denen es dann natürlich auch keinerlei Cookie-Hinweise gibt.
Weitere Links
- IPv6 statt Cookie-Tracking
- Berechtigtes Interesse
- Cookies auf der MSXFAQ
- Datenschutzerklärung
- OpenDNS - besser nicht
- DSGVO Fail - So kann man sich doch nicht über das Gesetz stellen, oder?
-
Das sind 650.000 Kategorien, in die uns die
Online-Werbeindustrie einsortiert
https://netzpolitik.org/2023/microsofts-datenmarktplatz-xandr-das-sind-650-000-kategorien-in-die-uns-die-online-werbeindustrie-einsortiert -
TANSTAAFL - "there ain’t no such thing as a free lunch "
https://de.wikipedia.org/wiki/TANSTAAFL - Firefox, Edge und Brave: Drei Browser im Kampf gegen
Werbetracker ($)
https://www.heise.de/tests/Firefox-Edge-und-Brave-Drei-Browser-im-Kampf-gegen-Werbetracker-4613798.html - uMatrix - Browser Firewall
Firefox: https://addons.mozilla.org/de/firefox/addon/umatrix/
Chrome https://chrome.google.com/webstore/detail/umatrix/ogfcmafjalglgifnmanfmnieipoejdcf - SameSite cookies explained
https://web.dev/samesite-cookies-explained/ - The New York Time: One Nation. Tracked. Twelve Million
Phones, One Dataset, Zero Privacy
https://www.nytimes.com/interactive/2019/12/19/opinion/location-tracking-cell-phone.html - Norwegische Verbraucherschützer: DSGVO-Beschwerde gegen
Grindr
https://www.heise.de/newsticker/meldung/Norwegische-Verbraucherschuetzer-DSGVO-Beschwerde-gegen-Grindr-4637211.html - Online-Werbung: Ein Karussell aus Geld und Daten
https://www.heise.de/newsticker/meldung/Online-Werbung-Ein-Karussell-aus-Geld-und-Daten-3677305.html - Listening Back Browser Add-On Translates Cookies Into Sound
The Sound of Surveillance
https://media.ccc.de/v/36c3-10855-listening_back_browser_add-on_tranlates_cookies_into_sound - Privacy concerns with social networking services
https://en.wikipedia.org/wiki/Privacy_concerns_with_social_networking_services - Wie viele Cookies werden in Browsern gespeichert?
https://twitter.com/robinhartmann/status/1210994506016927744?s=11 - Daten-Speicherung.de – minimum data, maximum privacy
https://www.daten-speicherung.de/index.php/ueberwachungsgesetze/
Nicht nur die Werbung sammelt Daten - Google und Facebook tracken auch auf Sex-Websites
https://www.heise.de/newsticker/meldung/Google-und-Facebook-tracken-auch-auf-Sex-Websites-4474354.html - Film: The Circle (2017)
https://de.wikipedia.org/wiki/The_Circle_(2017)
The Internet is on fire | Mikko
Hypponen | TEDxBrussels
https://www.youtube.com/watch?v=QKe-aO44R7k
Sehr schöner Vortrag von 2014. bei Min 12: Google investiert
2 Mrd/Quartal in die Infrastruktur und verdient damit 12 Mrd
US$/Jahr













