
PowerShell Pipeline
Eine große Stärke von PowerShell ist die Möglichkeit, Skripte zu verketten. Ausgaben von einem Skript oder Commandlet können an das nächste Commandlet übergeben werden. Das gab es natürlich auch schon bei MS-DOS und schon immer bei UNIX. Allerdings werden hier zwischen den Prozessen dann nur "Strings" übergeben.
Bei MS-Dos war es sogar so, dass erst ein Skript komplett durchgelaufen war, ehe die Daten aus der Pipeline dann dem zweiten Skript übergeben wurde. MS-Dos war nun mal kein "Multi Tasking System" mit mehreren Threads. PowerShell hingegen kann auf der Windows Basis auch problemlos mehrere Skripte ausführen und damit die Verarbeitung von Daten aus der Pipeline direkt fortsetzen. Allerdings ist die Pipeline damit nicht schneller, wie ich auf PS Parallel beschrieben habe.
Der große Unterschied zwischen PowerShell und anderen Diensten ist aber das Format der Pipeline. Mit PowerShell können komplette Objekte übergeben werden und nicht nur "Texte". Daher ist die PowerShell Pipeline ein sehr interessantes Thema auch für die Eigenentwicklung von Funktionen.
In dem Zuge möchte ich auf
einen englischen Artikel verweisen, den ich
später gefunden habe und der sehr lesenswert ist:
Tips on Implementing Pipeline Support
http://learn-powershell.net/2013/05/07/tips-on-implementing-pipeline-support/
Ausgaben
PowerShell-Skripts können Ausgeben auf den Bildschirm, in Dateien oder die Pipeline übergeben. Bei der Übergabe an die Pipeline werden dabei nicht nur einfache "Strings" ausgegebene, sondern auch komplexe PowerShell-Objekte sind möglich und können damit einfach weiter verarbeitet werden. Versuchen Sie es einfach schnell mal mit einer Liste der Prozesse aus, die ganz unterschiedlich formatiert werden können:
# Einfache Ausgabe als Liste Get-Process # Sortierung absteigend nach der CPU Get-Process | sort cpu -Descending # Übergabe an ein grafisches Fenster ohne weitere Updates Get-Process | Out-GridView # Ausgabe in CSV-Datei Get-Process | Export-Csv process.csv
Für die Weiterverarbeitung gibt es schon in der PowerShell ganz viele Commandlets. Es ist also auf jeden Fall sinnvoll, auch eigene Skripte um die Funktion zu ergänzen, Ausgaben nicht plump auf die Konsole oder direkt in eine Datei zu schreiben, sondern als Pipeline zu übergeben. Ich beschränke mich im folgenden nur auf die "Standard-Pipeline", denn es gibt durchaus weitere Pipelines. Die DOS-Oldies kennen vermutlich noch "STDIN", "STDIN", "STDOUT" und "STDERR". Bei PowerShell gibt es eigene Pipelines für Output, Error, Warning, Verbose, Debug". Ich beschränke mich hier erst einmal auf "OUTPUT" mit folgendem Kurztest, mit dem ich einen String ausgebe (PowerShell 7.1)
| Ausgabecode | Pipeline |
|---|---|
Ausgabe mit Write-Host landet nicht in der Pipelinewrite-host "test" | Out-GridView test |
Nein |
Ausgabe als String landet in der Pipeline"test" | Out-GridView |
Ja |
Ausgabe mit Write-Output String landet in der PipelineWrite-Output "test" | out-gridview |
Ja |
Ausgabe mit Out-Host landet nicht in der Pipeline"test" | Out-Host |Out-GridView |
Nein |
Als Entwickler von Powershell-Skripts ist das sehr nützlich. Ich kann in meinen Skripten mit "Write-Host" weiterhin auch farbige Ausgaben auf die Konsole schreiben, die nicht in der Pipeline landen und vom nachfolgenden Skript oder Programm nicht verarbeitet oder ignoriert werden müssen.
Vorsicht allerdings bei Programme, die nicht die "Pipeline" sondern die "Konsole" abfragen. Wenn z.B. PRTG einen PRTG - Custom Sensor als PowerShellSkript aufruft, dann bekommt er von "Powershell.exe" nicht nur die Pipeline sondern die komplette Ausgabe zurück.
- Write-Host Debugging
- About_Pipelines
https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_pipelines?view=powershell-7.1 - Weekend Scripter: Welcome to the PowerShell Information Stream
https://devblogs.microsoft.com/scripting/weekend-scripter-welcome-to-the-powershell-information-stream/ - Microsoft PowerShell Support for
Pipeline
https://www.jenkins.io/blog/2017/07/26/powershell-pipeline/
Eingaben über $INPUT
Siehe dazu die gesonderte Seite PowerShell Pipeline $input
Eingaben über Begin, Process, End
Powershell kennt über die Bezeichner Begin, Process, End auch die Möglichkeit, das Skript aufzuteilen. So kann man als Entwickler z.B. globale Variablen und Objekte instanziieren und effektiv nutzen. In Verbindung mit der Pipeline hingegen eröffnet dies neue Wege, da nun die Prozesse überlappt ablaufen.
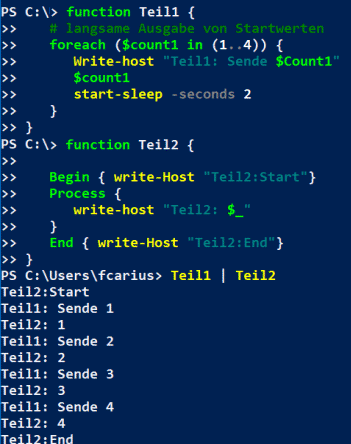
function Teil1 {
# langsame Ausgabe von Startwerten
foreach ($count1 in (1..4)) {
Write-host "Teil1: Sende $Count1"
$count1
start-sleep -seconds 2
}
}
function Teil2 {
Begin { write-Host "Teil2:Start"}
Process {
write-host "Teil2: $_"
}
End { write-Host "Teil2:End"}
}
Teil1 | Teil2
In der Powershell ist gut zu sehen, dass nun beide Funktionen miteinander verzahnt laufen und der Teil2 sogar noch vor dem Teil 1 eine Ausgabe erzeugt.
Hier nutzt ich die Variable "$INPUT" weiterhin, obwohl sie nun nicht mehr die komplette Pipeline sondern nur das eine Element enthält. Alternativ können Sie natürlich auch "$_" verwenden.
- Windows PowerShell: The
Advanced Function Lifecycle
https://technet.microsoft.com/de-de/magazine/hh413265.aspx - Tips on Implementing
Pipeline Support
http://learn-powershell.net/2013/05/07/tips-on-implementing-pipeline-support/
Wenn Sie mit Begin, Process, End arbeiten, darf außer eines Param-Blocks kein Code außerhalb stehen. sonst wird dieser ausgeführt und ein Fehler bezüglich "Begin" generiert.
Der Scope von Variablen in dem Begin, Process und End-Block ist Skriptlokal, d.h. eine Variable, die Sie als Vorarbeit im BEGIN-Block definieren und füllen, können Sie im Process-Block problemlos weiter verwenden.
Pipeline und Objekte
Wie ich anfangs geschrieben habe, ist die Verwendung der Pipeline natürlich nicht nur auf Zahlen und Strings beschränkt. Das Objekt in der Pipeline kann auch ein volles PowerShell-Objekt sein. Hier ein anderes Beispiel mit "$_" und einem Objekt
begin {
Write-Host 'Testskript: ============== started ============== '
}
process {
Write-Host "Testskript: ------ Pipelinedata --------"
$pipedata = $_
$fields = ($_ | gm -MemberType NoteProperty)
foreach($item in $fields) {
Write-Host "Name:" $item.name " Daten: " $pipedata.($item.name)
}
}
end {
Write-Host "Testskript: ============== ended ============== "
}
Ab PowerShell 3 können Sie statt "$_" auch "PSItem" schreiben.
Interessanter ist bei der Konstruktion die Arbeitsweise. Wer damit mehrere Prozesse miteinander verkettet, wird erkennen, dass alle Prozesse parallel ablaufen, d.h. es ist eine permanente Abarbeitung möglich.
Hier noch ein Beispiel in getrennten Skripten. Kopieren sie die beiden Skripte in ein Verzeichnis.
script1.ps1.txt
script2.ps1.txt
Starten Sie diese dann mit folgendem Aufruf:
script1.ps1 | script2.ps1
Und sie werden sehen, dass Skript 1 startet aber dann auch gleich Skript 2 und jede Ausgabe, die Skript 1 produziert von von Skript 2 gleich weiter verarbeitet wird.
Wenn Sie in solch einer Konstruktion noch eigene Funktionen addieren wollen, dann sind diese sinnvoll nur innerhalb des "begin"-Blocks zu definieren. Wenn die sie Lücke weg lassen, dann setzt die PowerShell das Skript automatisch als "END"-Block.
Pipeline und $_
Ich habe mir angewöhnt, das Pipelineobjekt in eine Variable namens $pipeline
zu kopieren und dann damit zu arbeiten. Zu oft habe ich innerhalb des "process"-Blocks
wieder mit FOR-Schleifen gearbeitet und mir so die Variable
überschrieben.
- $input gotchas
http://dmitrysotnikov.wordpress.com/2008/11/26/input-gotchas/ - PowerShell, $input vs. process
http://msgoodies.blogspot.com/2007/07/PowerShell-input-vs-process.html - Using Script Functions in the PowerShell Pipeline (
Take Two )
http://huddledmasses.org/using-script-functions-in-the-PowerShell-pipeline-take-two/
Es ist meines Wissens nicht möglich, die Pipeline bidirektional zu nutzen, d.h. ein direkter "Rückweg" zum aufrufenden Prozess ist verbaut. Denkbar wäre aber z.B. der Umweg über eine Datei (Prozess2 schreibt) und Prozess1 prüft.
Pipeline Parameter
Es gibt noch einen weiteren interessanten Weg mit der Pipeline zu arbeiten. Bei der Definition von Parametern können Sie auch diese als Pipeline-Parameter definieren.
function Teil1 {
# langsame Ausgabe von Startwerten
foreach ($count1 in (1..4)) {
Write-host "Teil1: Sende $Count1"
$count1
start-sleep -seconds 2
}
}
function Teil2 {
param (
[Parameter(ValueFromPipeline=$true)]
$variable1
)
Begin { write-Host "Teil2:Start"}
Process {
foreach ($count2 in $variable1){
write-host "Teil2: $count2"
}
}
End { write-Host "Teil2:End"}
}
Teil1 | Teil2
Durch die Angabe von "ValueFromPipeline" wird die Variable durch die Pipeline gefüllt. Es muss auch nicht immer die erste Variable sein. Die Varaiblen können durch den Property-Name bestimmt werden, wenn Sie die aktivieren. Die beiden folgenden Schlüsselworte sind hier relevant:
- ValueFromPipeline
ParameterAttribute.ValueFromPipeline Property
https://msdn.microsoft.com/en-us/library/system.management.automation.parameterattribute.valuefrompipeline(v=vs.85).aspx -
ValueFromPipelinebyPropertyname
https://msdn.microsoft.com/en-us/library/system.management.automation.parameterattribute.valuefrompipelinebypropertyname(v=vs.85).aspx -
Tips on Implementing
Pipeline Support
http://learn-powershell.net/2013/05/07/tips-on-implementing-pipeline-support/ -
Windows PowerShell: Erstellen
Sie bessere Funktionen
https://technet.microsoft.com/de-de/magazine/hh360993.aspx -
Tips on Implementing
Pipeline Support
https://learn-powershell.net/2013/05/07/tips-on-implementing-pipeline-support/
Sehr schöne Beschreibung in Verbindung mit CMDLETBinding
PowerShell und "zwei Pipelines"
Es kann eigentlich nur eine aktive Pipeline geben. Und so stoßen Sie bei Exchange 2010 z.B. bei folgendem Befehl auf einen Fehler:
get-mailbox `
| $Userlist `
| %{ set-mailbox -Identity $_.identity -SimpleDisplayName $_.displayname}
ERROR: Pipeline not executed because a pipeline is already executing. Pipelines cannot be executed concurrently.
Trennen Sie aber die Zeilen dann funktioniert es:
$Userlist = get-mailbox
$Userlist | %{ set-mailbox -Identity $_.identity -SimpleDisplayName $_.displayname}
Eine andere Lösung ist der Verzicht auf die Pipeline mit einer For-Schleife:
foreach ($mb in get-mailbox) {
set-mailbox -Identity $mb.identity -SimpleDisplayName $mb.displayname}
}
Ein einfaches get-mailbox | set-mailbox hingegen funktioniert. Das liegt an der Kombination der Pipeline mit einem FOR-Operator, der dann in der Befehlsgruppe wieder ein eigenständiges Commandlet startet. Dieses versucht nun auch auf die gleiche Pipeline zuzugreifen bzw. diese zu erstellen und das geht nicht. Das ist aber nur ein "Sonderfall" beim Einsatz mit RBAC.
- Exchange Management Shell Error: Pipelines Cannot be
Executed Concurrently
http://www.mikepfeiffer.net/2010/02/exchange-management-shell-error-pipelines-cannot-be-executed-concurrently/
PowerShell und Output Pipeline
Genauso kann es natürlich interessant sein, Ausgaben in eine Pipeline zu schreiben. Wie wäre es, wenn ein Skript z.B.: die Mitglieder einer Verteilerliste extrahiert und nicht stumpf in eine Datei schreibt, sondern Sie in eine PIPE übergibt, so dass Sie selbst mit Export-CSV oder Export-CliXML oder andere Tools darauf zugreifen können ? Auch das geht per PowerShell.
Achtung
Ich habe schon Effekte gesehen, wenn die
übergebenen Werte keine neuen Objekte oder
einfache Variablen waren.
Beispiel: Sie instanziieren eine Ausgabevariable
mit "new-object PSObject" und füllen die
gleiche Variable immer mit neuen Werten und
geben diese aus, dann bekommt der nächte Prozess
eventuell überschriebene Werte.
Man muss einfach nur ein PowerShell Objekt erstellen, mit Properties und Werten versehen und "ausgeben.
Write-Host "Testskript: ------ Pipelinedata --------" $pso = New-Object PSObject $pso | Add-Member NoteProperty "ColumnA" "Data1" $pso | Add-Member NoteProperty "ColumnB" "Data2" $pso | Add-Member NoteProperty "ColumnC" "Data3" Write-Output $pso
Wen die Schreibweise mit der PIPE nach Add-Member nicht gefällt, kann die Werte auch anders zuweisen:
$pso = New-Object PSObject Add-Member -InputObject $pso -MemberType NoteProperty -Name Feld1 -Value Wert1 Add-Member -InputObject $pso -MemberType NoteProperty -Name Feld2 -Value Wert2 # Oder Kürzer Add-Member -InputObject $pso noteproperty feld1 wert2 Add-Member -InputObject $pso noteproperty feld2 wert2 # Bestehende Felder können einfach dann zugewiesen werden $pso.feld1 = "wert1neu" #und ausgegeben werden write-host $pso.feld1
Siehe auch http://technet.microsoft.com/en-us/magazine/cc510337.aspx
Es geht sogar noch einfacher durch einen kleinen Kniff. Man gibt einfach einen Leerstring an "select" aus und wählt die Felder. PowerShell erstellt so ein leeres Objekt mit den Feldern. Das Beispiel erstellt nicht nur ein Objekt sonder addiert es auch an eine Tabelle. So können also sehr einfach viele Ausgaben schnell aufgestellt und später ausgegeben werden.
$ergebnistabelle = @() $ergebnis = "" | select Feld1,Feld2,Feld3 $ergebnis.Feld1 = "Inhalt1" $ergebnis.Feld2 = "Inhalt2" $ergebnis.Feld2 = "Inhalt3" $ergebnistabelle += $ergebnis
Übrigens können Sie die Ausgabe auch an CScript übergeben, welches dann über "wscript.stdin.readall" darauf zugreifen kann. Allerdings sollten Sie nicht zu viel erwarten. Mehr als die Bildschirmausgabe des vorherigen PowerShell Skripts kommt in VBScript nicht an. Also ist dieser Weg nicht wirklich sinnvoll zu nutzen.
Pipeline und Rekursion
Was passiert, wenn ein PowerShell-Skript mit Funktionen arbeitet und diese rekursiv aufgerufen werden?. Ich habe mir dazu folgendes Testscript gebaut:
function sub {
param ($deep)
write-host "Subvor $deep"
$deep
if ($deep -lt 3) {
sub ($deep +1)
}
write-host "Subnach $deep"
}
sub 1
Ich definiere eine Unterfunktion, die eine Zahl als Parameter erwartet und rekursiv hochzählt, bis die maximal gewünschte Tiefe erreicht ist. Neben der Bildschirmausgabe wird auch der Wert in die Pipeline ausgegeben. Der Aufruf zeigt dann folgendes verhalten:

Ohne Nachverarbeitung werden Bildschirmausgabe als auch Pipeline auf der Konsole ausgegeben. Die Pipeline kann aber einfach in eine Textdatei ausgegeben werden. Damit ist bewiesen, dass eine Ausgabe in die Pipeline auch bei Rekursion nicht unterbrochen wird.
Pipeline mit "Format-Table"
Die Verkettung von Skripten per PowerShell ist ja nett aber manchmal ist eine "Foreach"-Schleife mit drin, die eine Pipeline erschwert. In dem folgenden Beispiel möchte ich 10mal einen Performance Counter erfassen. Die Erfassung selbst sammelt 6 Messungen im Abstand von einer Sekunde und ermittelt dann Min;Max,Avg
1..10 `
| %{ Get-Counter `
-Counter "\TCPv4\erneut übertragene segmente/s" `
-SampleInterval 1 `
-MaxSamples 5 `
| %{$_.countersamples[0].cookedvalue} `
| Measure-Object -Average -Maximum -Minimum -Sum `
}
Führt man den Code so aus, dann funktioniert er wie erwartet und auf dem Bildschirm kommen die Daten raus:

Was hier aber nicht sichtbar wird, ist eine Trennung zwischen den einzelnen Datensätzen. Soll die Ausgabe mit "Format-Table" anders erfolgen, dann wird das sichtbar:
1..10 `
| %{ Get-Counter `
-Counter "\TCPv4\erneut übertragene segmente/s" `
-SampleInterval 1 `
-MaxSamples 5 `
| %{$_.countersamples[0].cookedvalue} `
| Measure-Object -Average -Maximum -Minimum -Sum `
| ft -autosize
}

Jede Messung ist zwar ein eigenes Objekt aber die nachfolgende Pipeline wird immer wieder neu gestartet. Format-Table zeigt jeden Datensatz einzeln an. Die Weiterverarbeitung muss also "weiter hinten" erfolgen. Sie müssen hinter der "}"-Klammer der For-Schleife ansetzen.
1..10 `
| %{ Get-Counter `
-Counter "\TCPv4\erneut übertragene segmente/s" `
-SampleInterval 1 `
-MaxSamples 5 `
| %{$_.countersamples[0].cookedvalue} `
| Measure-Object -Average -Maximum -Minimum -Sum
}`
| ft -autosize export-csv retransmit.csv -notypeinformation
Das ist schon besser nur "sehen" Sie von der Ausgabe erst etwas, wenn alle Durchläufe abgeschlossen ist. Format-Table sammelt nämlich erst einmal alle Einträge um dann die Ausgabe entsprechend aufzubereiten. Wenn Sie die Ergebnisse aber in eine CSV-Datei schreiben lassen, dann können sie sehr wohl sehen, wie die CSV-Datei nach und nach fortgeschrieben wird. Insofern ist gerate "Format-Table" ein sehr schlechtes "Ende" einer Pipeline. Nur wenn die Übergabe an Format-Table kein Objekt mit mehreren Feldern sondern einfach nur ein String ist, dann gibt auch Format-Table die Ergebnisse sofort aus.
Pipeline mit Dateien
Ich schreibe in vielen Skripten verschiedene Protokolldateien, teils direkt oder über ein "Start-Transcript". Wer viele Logs schreibt, sollte sich aber auch um das Aufräumen kümmern, d.h. alte Dateien nach Ablauf einer Zeit wieder entfernen. Niemand will tausende von Logfiles vorhalten und die Festplatte füllen. Ein einfacher "Einzeiler könnte wie folgt aussehen:
get-item -path "C:\Tasks\scriptname\logs\dynquota*.log" | where {$_.lastwritetime -lt ((get-date).adddays(-30))} | remove-item
Das funktioniert in der Regel ganz gut aber manchmal eben auch nicht die Fehlermeldung ist dabei:
Get-Item : Could not find item C:\Tasks\skriptname\logs\skriptname.2016-03-15-20-00-05-493.log.
At C:\Tasks\skriptname\skriptname.ps1:56 char:9
+ get-item <<<< -path "C:\Tasks\skriptname\logs\skriptname*.log" | where {$_.lastwritetime -lt ((get-date).adddays(-30))} | remove-item
+ CategoryInfo : ObjectNotFound: (C:\Tasks\skriptname...0-00-05-493.log:String) [Get-Item], IOException
+ FullyQualifiedErrorId : ItemNotFound,Microsoft.PowerShell.Commands.GetItemCommand
Auf den ersten Blick könnte man meinen, dass jemand anderes die Datei schon gelöscht hat. Das Skript wird aber nur einmal gestartet. Ich vermute mal, dass hier die "Parallelisierung" oder eine Verwirrung bei Filehandles die Ursache ist. Schließlich löscht das "Remove-Item" eine Datei, während vorne noch das "Get-Item" die Liste aufbaut. Hier hilft es dann die beiden Prozesse zu entzerren
$purgefilelist = get-item -path "C:\Tasks\scriptname\logs\dynquota*.log" | where {$_.lastwritetime -lt ((get-date).adddays(-30))}
$purgefilelist| remove-item
Damit habe ich zumindest die Probleme deutlich reduzieren können.
Where-Methode statt Where-Objekt
Manchmal sind es die kleinen Änderungen, die über die Geschwindigkeit eines Skripts entscheiden. Das Filtern von Daten mittels Pipeline und "Where-Objekt" ist zwar einfach zu lesen aber deutlich langsamer als die "Where-Methode" eines Objekts. Sie können es mit folgendem Beispiel recht einfach nachvollziehen, bei dem ich mir alle Informationen zu Dateien meiner Festplatte hole und dann filtere:
$filelist= Get-ChildItem C:\ -Recurse
$filelist.count
677439
(measure-command {$filelist | ? {$_.name -like "pdf"}}).totalseconds
22,1507168
(measure-command {$filelist.Where({$_.name -like "pdf"})}).totalseconds
5,6654204
(measure-command {$filelist.foreach({$_.name -like "pdf"})}).totalseconds
4,7433125
Die Suche nach "pdf" im Namen von 677439 Dateien dauert über die Pipeline über 5 Mal solange. Allerdings sollten Sie bei einer Weiterverarbeitung berücksichtigen, dass die Rückgabe sich unterscheiden kann. Wenn es kein Ergebnis gibt, dann liefert "Where" ein $null während Object.Where() ein leeres Array liefert.
- Speeding Access to Office 365 PowerShell
Data Using Where Instead of Where-Object
https://office365itpros.com/2020/09/07/speed-powershell-code-where-method/ - ForEach and Where magic methods
https://www.powershellmagazine.com/2014/10/22/foreach-and-where-magic-methods/
CMDLETBinding und Pipeline
Wenn Sie am Anfang das Schlüsselwort "[CMDLETBinding()] in einem PowerShell-Script verwenden, dann funktionieren auch die Parameter "-verbose" und "-debug" ganz von alleine und alle in den Script verwendeten Commandlets übernehmen ebenfalls diese Einstellungen. Das ist sehr bequem um mit Write-Verbose und Write-Debug im eigenen Skript entsprechende Zusatzinformationen für die Fehlersuche auszugeben.
Allerdings hat das auch Einfluss auf die Nutzung der Pipeline. Eine einfache Einbindung per $INPUT oder $_ ist dann nicht mehr möglich. Sie sehen folgenden Fehler:
"The input object cannot be bound to any parameters for the command either because the command does not take pipeline input or the input and its properties do not match any of the parameters that take pipeline input."
Der Trick dabei ist, eine Variable in der PARAM-Sektion entsprechend zu definieren, dass Sie mit Werten aus der Pipeline gefüllt werden kann.
param ( [Parameter(ValueFromPipeline= $True)] $Werte
Sie müssen auch auf jeden Fall eine "PARAM"-Sektion anlegen, damit Sie so Werte von der Pipeline dann erhalten. Ansonsten gibt es folgenden Fehler:
Unexpected attribute 'CMDLetBinding'
-
Use the Pipeline to Create Robust PowerShell Functions
https://blogs.technet.microsoft.com/heyscriptingguy/2011/05/10/use-the-%20pipeline-to-create-robust-powershell-functions/
STDOUT-Bug
Etwas nervig war in der Anfangszeit der Powershell ein Bug in der Behandlung von Ausgaben nach STDOUT. In der Powershell1 und 2 konnte die Powershell einfach eine Ausgabe an STDOUT senden und damit in die Pipeline zur weiteren Verarbeitung übergeben. Aber auch die Ausgabe von "Write-host" will man vielleicht in eine Datei umleiten, wenn ein Skript "unbewacht" läuft. Natürlich gibt es in der Powershell auch die Befehle "Start-Transcript" und "Stop-Transcript"
- Start-Transcript
https://technet.microsoft.com/de-de/library/hh849687.aspx - Stop-Transcript
https://technet.microsoft.com/de-de/library/hh849688.aspx
Und selbst beim Aufruf der Powershell z.B. aus einer CMD-Datei kann mit " > datei.txt" eine Umleitung erfolgen. Das passiert gerne, wenn andere Job-Scheduler wie z.B. Control-M (http://www.bmcsoftware.de/it-solutions/control-m.html) die Jobs starten und die Ausgaben für die Protokollierung abgreifen.
Die Fehlermeldung in der Powershell war dann ziemlich nichtssagend und eher erschreckend
Write-Host : The OS handle’s position is not what FileStream expected. Do not use a handle simultaneously in one FileStream and in Win32 code or another FileStream. This may cause data loss.
Ursächlich ist aber wohl die Tatsache, dass Powershell nicht direkt auf STDOUT schreibt, sondern ein Helper-Objekt verwendet, welches zwischen der Powershell und STDOUT vermittelt. Wenn nun ein anderes Programm ebenfalls nach STDOUT schreibt, dann verweist der Powershell Helper auf die falsche Position. STDOUT ist ja schon weiter gerückt.
Es gibt wohl einen Fix, der auch bei meinen Skripten temporär geholfen hat aber mit einer neueren Powershell nicht mehr funktionieren muss oder sogar stören kann:
#Fix für STDOUT Bug in PS.10 und 2.0 $bindingFlags = [Reflection.BindingFlags] "Instance,NonPublic,GetField" $objectRef = $host.GetType().GetField( "externalHostRef", $bindingFlags ).GetValue( $host ) $bindingFlags = [Reflection.BindingFlags] "Instance,NonPublic,GetProperty" $consoleHost = $objectRef.GetType().GetProperty( "Value", $bindingFlags ).GetValue( $objectRef, @() ) [void] $consoleHost.GetType().GetProperty( "IsStandardOutputRedirected", $bindingFlags ).GetValue( $consoleHost, @() ) $bindingFlags = [Reflection.BindingFlags] "Instance,NonPublic,GetField" $field = $consoleHost.GetType().GetField( "standardOutputWriter", $bindingFlags ) $field.SetValue( $consoleHost, [Console]::Out ) $field2 = $consoleHost.GetType().GetField( "standardErrorWriter", $bindingFlags ) $field2.SetValue( $consoleHost, [Console]::Out )
Ab der Powershell 3.0 soll das Problem durch einen Fix richtig gelöst worden sein. Aber zumindest Exchange 2010 nutzt ja noch die Powershell 2.0.
- Workaround: The OS handle's position is
not what FileStream expected
http://www.leeholmes.com/blog/2008/07/30/workaround-the-os-handles-position-is-not-what-filestream-expected/ - Powershell 2.0 redirection file handle
exception
http://stackoverflow.com/questions/8978052/powershell-2-0-redirection-file-handle-exception - How to redirect output of console
program to a file in PowerShell
http://chuchuva.com/pavel/2010/03/how-to-redirect-output-of-console-program-to-a-file-in-powershell/
Foreach-Object
Auch beim Einsatz der For-Schleife gibt es Unterschiede. Sie können ja die Liste von Elementen an einen ForEach-Commandlet über die Pipeline übergeben oder im ForEach-Statement einsammeln.
PS C:\> Get-Item *.* | Foreach-Object { $_}
PS C:\> Foreach-Object ($item in (get-item *.*)) {$item}
Beide Befehle funktionieren gleich und liefert die gleiche Ausgabe auf der Konsole. Interessant wird es, wenn Sie die Ausgabe in einer Pipeline z.B.: mit "Where-Object" oder "Group-Object" weiter verarbeiten wollen.
PS C:\> Get-Item *.* | Foreach-Object { $_} | group path
Count Name Group
----- ---- -----
108 {C:\Users\, C:\Windows, C:\temp, C:\…
PS C:\> ForEach ($item in (get-item *.*)) {$item} | group path
ParserError:
Line |
1 | foreach ($item in (get-item *.*)) {$item} | group path
| ~
| An empty pipe element is not allowed.
Nur wenn ich vorne in die For-Schleife die Elemente über eine Pipeline einkippe, werden die verarbeiteten Ergebnisse hinten wieder in eine Pipeline weiter gereicht. Ohne Pipeline muss ich dann die Ergebnisse erst einer Variablen zuweisen und diese dann weiter verarbeiten.
PS C:\> $result = ForEach ($item in (get-item *.*)) {$item}
PS C:\> $result | group path
Übrigens: Auch wenn "ForEach" ein Alias auf "ForEach-Object" ist, ist es doch nicht ganz das gleich.
# Das Funktioniert
$result = ForEach ($item in (get-item *.*)) {$item}
# Das funktioniert nicht
$result = ForEach-Object ($item in (get-item *.*)) {$item}
ParserError:
Line |
1 | $result = ForEach-Object ($item in (get-item *.*)) {$item}
| ~~
| Unexpected token 'in' in expression or statement.
Falle mit $_
Die PowerShell Pipeline ist ja sehr leistungsfähig aber manchmal gräbt man sich selbst eine Falle. Aufgefallen ist mir das bei einer Verarbeitung von Exchange Empfängern in einem Skript. Das Beispiel ist nur ein Ausschnitt.
Zuerst hole ich mir die Liste der Empfänger, die dann aber direkt per Pipeline in eine "Foreach"-Schleife sende. In der Schleife greife ich dann über "$_.EMailAddresses" auf die Mailadressen des jeweiligen Objekts zu. Da mich nur die SMTP-Adressen der Liste interessieren, habe ich diese einfach mit "Where-Object" in der zweien For-Schleife gefiltert.
Get-Recipient -resultsize unlimited -ignoreDefaultScope | ForEach-Object {
foreach ($proxyaddress in ($_.EMailAddresses | Where-Object {$_.PrefixString -eq "SMTP"})) {
Write-Host " Processing SMTP ProxyAddress $($proxyaddress.SmtpAddress.tolower())"
}
}
Schön ist anders aber das Problem ist, dass ich nun eigentlich die Laufvariable "$_" mit dem "Where-Objekt" anscheinend so verändert habe, dass immer nur die erste Mailadresse aus der Collection genutzt wurde. Ich konnte das lösen, in dem ich die innere Verwendung aufgelöst habe
Get-Recipient -resultsize unlimited -ignoreDefaultScope | ForEach-Object {
foreach ($proxyaddress in $_.EMailAddresses) {
if ($proxyaddress.PrefixString -eq "SMTP") {
Write-Host " Processing SMTP ProxyAddress $($proxyaddress.SmtpAddress.tolower())"
}
}
}
Alternativ hätte ich auch die äußere Schleife ohne $_ schreiben können:
$recipients = Get-Recipient -resultsize unlimited -ignoreDefaultScope
ForEach-Object ($recipient in $recipients) {
foreach ($proxyaddress in ($recipient.EMailAddresses | Where-Object {$_.PrefixString -eq "SMTP"})) {
Write-Host " Processing SMTP ProxyAddress $($proxyaddress.SmtpAddress.tolower())"
}
}
Oder ich verzichte im Zweifel bei größeren Codeteilen einfach konsequent auf "$_" und nutze immer benannte Laufvariablen.
Vorsicht Variablenscope
Der folgende Fehler meinerseits hat mich einige Zeit gebraucht, um die Ursache letztlich zu finden. Ich hatte ein PowerShell-Script, welches am Anfang über HTTP-Anfragen eine Information ermittelt und in einer Variablen gespeichert hat. Mit einer Der Fehler ist dann aufgetreten, wenn für einen Durchlauf diese HTTP-Abfrage nicht funktioniert hat und es danach noch einen weiteren Lauf gab. Dann hat das Skript falsch gearbeitet. Ich habe hier ein Beispiel gebaut, welches den Fehler aufzeigt:
param (
[parameter(Position=0,mandatory=$true,ValueFromPipeline=$true)]
[string[]]$domain
)
begin {
write-host "Start Domain:$($domain)"
}
process {
write-host " Process Domain:$($domain)" -nonewline
try {
$result = Invoke-webrequest "https://$($domain)"
Write-host " OK" -ForegroundColor green -NoNewline
$size = $result.RawContentLength
}
catch {
Write-host " Error" -ForegroundColor red -NoNewline
}
write-host " Size $($size)"
}
end{
}
Der geübte Entwickler wird den Fehler in dem einfachen Code schnell sehen aber wenn der Code in in dem "Process"-Block etwas länger ist, und etwas Abstand zwischen der Zuweisung von "$size" und der späteren Weiterverwendung ist, dann ist das nicht mehr so einfach. Führen Sie den Code einfach mal aus mit:
"www.msxfaq.local",""www.msxfaq.de","www.msxfaq.local" | test-pipeline.ps1
In meinem Fall ist die dritte Zeile natürlich falsch

Die "Size" sollte hier natürlich auch leer sein und nicht von der vorherigen Schleife übrig bleiben.
Wenn Sie in dem "Process-Block" eine quasi lokale Variable setzen, dann bleibt der Inhalt auch in der nächsten Schleife erhalten. Der Scope der Variable ist das Skript und nicht der "process"-Block. Am besten definieren und initialisieren Sie alle im Process-Block verwendeten Variablen am Anfang.
Weitere Links
- PowerShell Pipeline $input
- PS Parallel
- Piping and the Pipeline in
Windows PowerShell
http://technet.microsoft.com/en-us/library/ee176927.aspx - Microcode: PowerShell
Scripting Tricks: Select-Object
(Note Properties) vs Add-Member
(Script Properties)
http://blogs.msdn.com/b/mediaandmicrocode/archive/2008/11/26/microcode-PowerShell-scripting-tricks-select-object-note-properties-vs-add-member-script-properties.aspx - Effective PowerShell Item 11: understanding ByPropertyName Pipeline Bound
Parameters
http://rkeithhill.wordpress.com/2008/04/06/effective-PowerShell-item-11-understanding-bypropertyname-pipeline-bound-parameters/ - Effective PowerShell Item 12: understanding ByValue Pipeline Bound Parameters
http://rkeithhill.wordpress.com/2008/05/09/effective-PowerShell-item-12-understanding-byvalue-pipeline-bound-parameters/ - Windows PowerShell: The
Advanced Function Lifecycle
https://technet.microsoft.com/en-en/magazine/hh413265.aspx - Tips on Implementing
Pipeline Support
http://learn-PowerShell.net/2013/05/07/tips-on-implementing-pipeline-support/ - Microsoft PowerShell Support
for Pipeline
https://www.jenkins.io/blog/2017/07/26/powershell-pipeline/














