
Git für Administratoren und Consultants
Auf der Seite GIT und GitHub habe ich einen Überblick zu der Thematik zu geben.
Hier möchte ich aber einmal den praktischen Aspekt aufzeigen, warum jeder, der nur im entferntesten Skripte oder Code schreibt und über eine Versionierung nachdenkt, sich mit GIT beschäftigen sollte.
Nicht nur für Code!
Ehe sie nun gleich wegklicken, weil Sie eh keinen Code schreiben, dann möchte ich sie bitte kurz weiter zu lesen. Wo ist denn der Unterschied zwischen einem Sourcecode, der nach dem Einchecken automatisch übersetzt und in einem Testfeld verifiziert wird und einer Dokumentation, die von Menschen "gelesen" wird. Eine Versionierung von Dokumenten kennen wir schon aus SharePoint und OneDrive.
Es ist natürlich keine gute Idee, DOCX-Dateien in einem GIT oder DevOps abzulegen, da es ein ZIP-Archiv und damit Binär ist und Git keine sinnvolle Differenzen ermitteln kann. Aber vielleicht scheiben Sie Wiki-Inhalte, Markdown, HTML oder auch nur einfache Text-Dateien. Ich überlege auch meine MSXFAQ z.B. in GIT zu versionieren.
Am Beispiel von Code ist der Vorteil einer Versionierung und Zusammenarbeit mittels GIT, DevOps und anderen Programmen natürlich am einfachsten zu demonstrieren.
So sollte es nicht sein!
Wenn wir Consultants und Administratoren mal ehrlich sind, dann fangen kleine Lösungen auch klein an, indem wir ein paar PowerShell Commandlets aneinander hängen um ein Ergebnis zu erhalten. Sehr schnell merken wir, dass es doch etwas mehr wird und dann wird eben mit Notepad, NotePad++ oder vielleicht sogar Visual Studio Code ein kleines PS1-Skript geschrieben. Und wir es der Teufel will, gibt es immer mal dies und das anzupassen und zu erweitern und ehe wir uns versehen, haben wir was falsch gemacht und wollen ein UNDO.
Also fangen wir damit an, die Dateien mit Versionsnummern zu versehen und ehe man es sich versieht, ist das Verzeichnis voll von Dateien.

Damit man über "AutoComplete" nicht immer eine alte Version überspringen muss, verschieben wir diese vielleicht noch in eine Unterverzeichnis. Diese Arbeitsweise ist schon lange überholt und kollidiert spätestens, wenn mehrere Personen an den gleichen Skripten weiter arbeiten.
Das eigene GIT
Sie haben sicher schon von GIT, GitHub, GitLabs und anderen Dingen gehört aber sich vielleicht nicht dran getraut oder den Sinn für Sie als Administrator nicht verstanden. Dann machen Sie doch einfach folgendes:
| Aktion | Status |
|---|---|
Download GITLanden Sie GIT for Windows herunter. Die Installationsquellen finden Sie direkt auf GitHub https://GitHub.com/git-for-windows/git/releases/ https://GitHub.com/git-for-windows/git/releases/download/v2.21.0.windows.1/Git-2.21.0-64-bit.exe |
|
Installieren Sie GITUnter Windows starten Sie einfach den herunter geladenen EXE. Das Setup fragt einige Dinge nach
|
|
Installation Visual Studio CodeFür die weiteren Beispiele nutze ich Visual Studio Code. Der freie Code-Editor für Windows, Linux und Mac ist sehr leistungsfähig und hat beim Programmieren meine anderen Favoriten abgelöst. Er ist auch deutlich flotter als die ISE. Download
Die Installation beschreibe ich nun nicht gesondert. Hinweis: Ich nutze hier nun explizit Visual Studio Code. VS Code nutzt im Hintergrund aber auch nur die GIT-Tools. Sie können alle Aktionen auch komplett per Kommandozeile ausführen und damit auch automatisieren. |
|
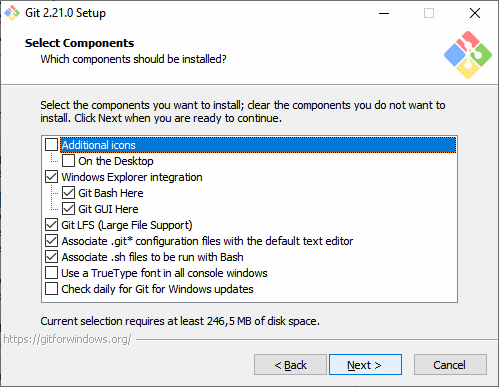




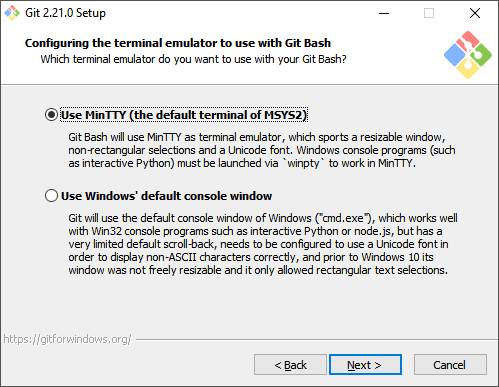

Verzeichnis statt Datei
Wenn Sie bisher in einzelnen PowerShell-Dateien gedacht haben, dann stellen Sie dies umgehend auf "Verzeichnisse" um. Jedes Projekt, jedes Skript, jedes Modul sollte ein eigenes Verzeichnis haben. Dort landet ja vielleicht nicht nur ein PS1-File sondern vielleicht noch eine Konfiguration oder auch eine Dokumentation, Notizen und vieles mehr. Also legen wir ein Verzeichnis an. Öffnen Sie einfach eine PowerShell und geben Sie ein.
md skript1 cd skript1 git init code .
Diese vier Befehle legen ein Verzeichnis an, initialisieren ein eigenes GIT Repository und starten Visual Studio Code aber es gibt ja noch keine Datei:

Wer nun neugierig mit dem Explorer in das Verzeichnis schaut und versteckte Ordner anzeigen lässt, sieht aber schon einen Verzeichnisbaum, der sie aber erst mal nicht weiter zu interessieren hat.

Lassen Sie ihn einfach mal in Frieden.
Die erste Datei
Nun fangen wir wieder wie gewohnt an. Wir legen eine neue Datei an, schreiben etwas hinein uns speichern diese. Ich habe dazu auf das Symbol für eine neue Datei geklickt, einen Dateinamen angegeben und dann rechts etwas getippt:

Sie sehen aber auch ein "U" hinter der Datei. Diese Datei wird noch nicht von der Versionskontrolle verfolgt und entsprechend sehen Sie rechts zweimal eine "1". Das oberste Symbol zeigt die noch nicht gespeicherte Datei an und das dritte Symbol die neue Datei in der Versionsverwaltung GIT. Wenn ich mit "CTRL-S" nun die Datei speichere, dann verschwindet die obere 1. Noch arbeite ich einfach mit einer Datei in einem Verzeichnis wie bisher auch.
Das erste Staging und Commit
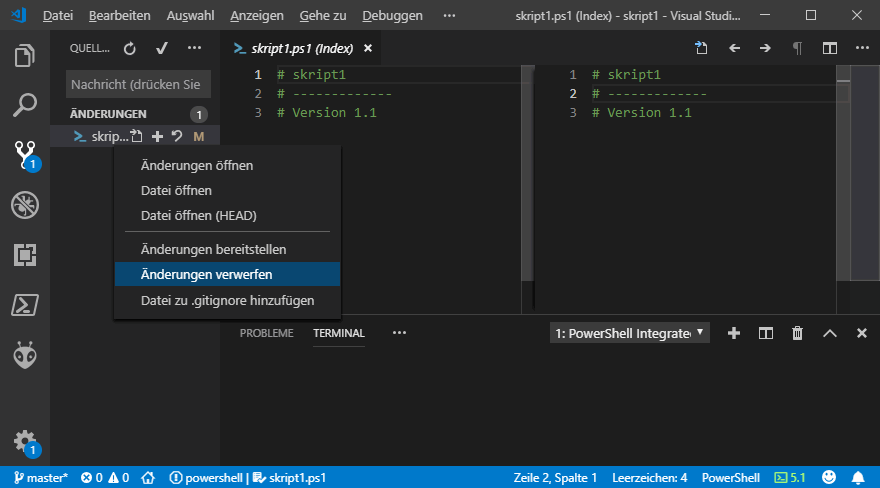
Ich möchte aber sicherstellen, dass diese Datei in der Version "sicher" ist und auch spätere Änderungen nachvollzogen und rückgängig gemacht werden können. Also werde ich diese Datei nun Aufnehmen und meine Änderungen bereitstellen. Dazu klicke ich links auf die Versionsverwaltung und über das Kontext-Menü stelle ich die Datei bereit.
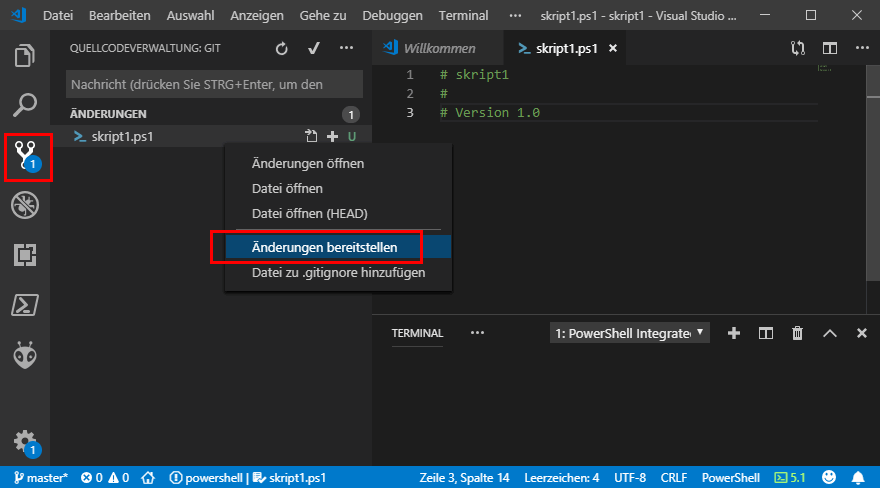
Damit ist die Datei noch nicht als Version "gesichert". Es könnte ja sein, dass Sie in dem Verzeichnis viele Dateien haben und mehrere Dateien geändert wurden. Dann können Sie so auswählen, welche Dateien als "Gruppe" zusammengefasst eine neue Version darstellen sollen. Ein Beispiel ist eine PS1-Datei und die dazugehörige Konfigurationsdatei. Hier belassen wir es aber mal bei einer Datei.
Das Bild hat sich nun etwas geändert. Die Datei habe ich quasi in meinen Korb zur Auslieferung gegeben

Damit die Datei nun wirklich "eingecheckt" wird, drücke ich oben auf den Haken und gebe einen Kommentar ab. Dokumentation ist bei der Entwicklung von Code aber auch jeder anderen Arbeit wichtig.
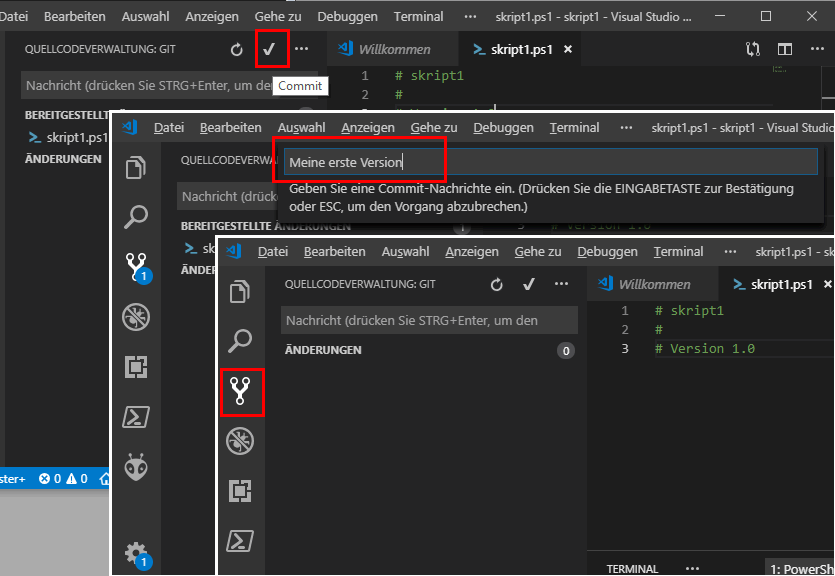
Am Ende sehe ich erst mal nichts. meine Datei ist wie bisher da. Ein Blick in das Dateisystem zeigt auch nur die aktuelle Datei:
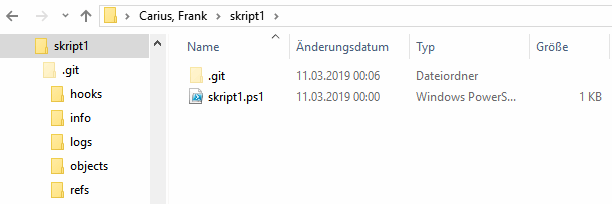
Das ist aber gut, denn eigentlich interessiert mich immer nur die aktuelle Datei in meiner Welt
Änderungen und neue Version
Aber weil wir uns hier um die Versionsverwaltung Gedanken machen, editiere ich natürlich nun die Datei und addiere und entferne etwas. Danach speichere ich die Datei wieder weg. Auf meiner Festplatte ist nun die Datei überschrieben und in Visual Studio Code sehe ich eine ausstehende Änderung in der Versionsverwaltung.

Diesmal mache ich mit das Leben einfach und drücke direkt oben auf den "Commit" Haken.

Visual Studio Code erkennt die Änderungen und fragt mich, ob ich diese alle bereitstellen und bestätigen möchte. Ich sage hier ein Ja und gebe wieder einen Kommentar ein. Auf meiner Festplatte ist immer die aktuelle Version und die vorherigen Versionen hat GIT auf meinem PC irgendwie schon verwaltet.
Änderung und Vergleich
Die Version 1.0 und 1.1 lassen wir mal unberührt. Ich habe den Code natürlich weiter bearbeitet und gespeichert. Wenn ich nun auf die Änderungen wieder in der Versionskontrolle anzeige, dann sehe ich sofort, was ich geändert habe.
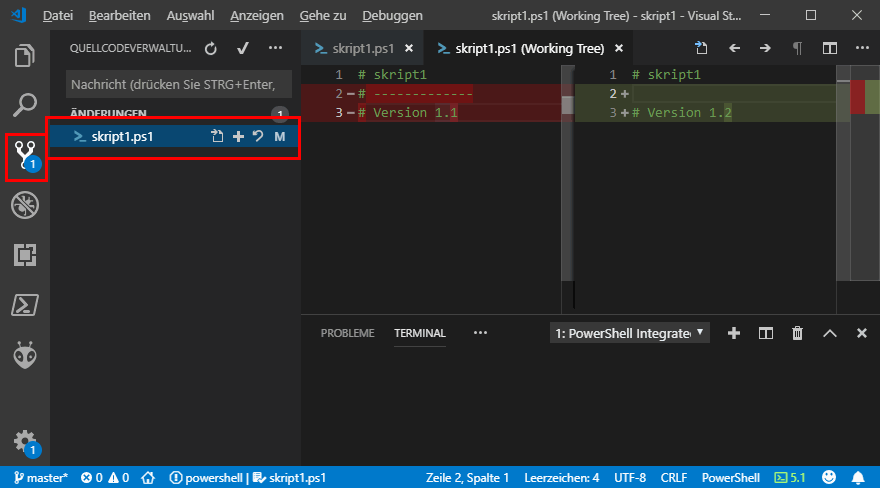
Ich habe hier die "------" Zeichen wieder entfernt und die Version um eine Stelle erhöht. Hier kann ich über die Datei dann auch ganz schnell die Änderungen wieder verwerfen.
Arbeitsweise
Wenn sie sich das so anschauen, dann macht ein Entwickler neben dem Schreiben von Code hinsichtlich der Versionsverwaltung was immer das gleiche Schema:
| Schritte | Bild |
|---|---|
|
|

Natürlich werden einige Schleifen immer und immer wieder durchlaufen und speziell bei größeren Projekten gibt es für jeden Bereich einen "Maintainer", der die Hoheit hat und die Merge-Aktionen durchführt.
Nicht verschwiegen werden darf aber auch, dass es innerhalb einer Repository auch "Branches" geben kann und dass ein Programmierer idealerweise nicht auf dem produktiven Repository arbeitet, sondern sich einen Fork anlegt, quasi eine Kopie und dort seine Änderungen durchführt. Er kann dann den Besitzer des originalen Repository einen "Pull Request" vorschlagen. Der Besitzer kann dann die Änderungen aus dem Fork mit dem eigenen Repository vergleichen und Änderungen übernehmen. Das System kann als durchaus komplexer werden.
Versionierung simulieren
Ales, was ich in Visual Studio Code grade mal so über Mausaktionen gemacht habe, passiert im Hintergrund über Kommandozeilen des Programms GIT. Wenn Sie häufiger mit GIT arbeiten, dann werden sie sehr bald die verschiedenen Aktionen per Kommandozeile ausführen. Dies gilt um so mehr, wenn sie mehrere Repositories verwalten oder Dinge automatisieren wollen.
Auf der Webseite https://learngitbranching.js.org/ gibt es eine grafische Umsetzung, anhand der Sie die Aktionen durchspielen können. Ich habe mir mal folgendes Storyboard überlegt. Sie können diese im Browser auf https://learngitbranching.js.org/ einfach nachvollziehen.
| Storybaord | Aussehen |
|---|---|
|
Verzeichnis anlegen und ein GIT INIT darauf machen. Diese Vorarbeiten sind im Browser nicht möglich. Wir müssen also damit anfangen, dass das GIT schon initialisiert ist und die ersten Dateien vorhanden sind. Das ist der Master-Branch |
|
|
Änderungen einchecken. Dazu machen wir: git commit Schon habe ich eine weitere Version. Lösen Sie sich in am Besten von klassischen Versionsnummern im Stiel von 1.0, 1.1 etc. Die gib es nicht wirklich. |
|
|
Nun nehme ich mal an, dass ich eine besondere Version für einen Kunden oder eine neue Funktion entwickeln will, von der ich noch nicht weiß, ob sie später so bestehen bleiben soll. Oder ich möchte größere Änderungen machen. Dann wäre es töricht diese Änderungen am Hauptast zu machen. Also lege ich mir einen Zweig für das neue Feature an. git branch Feature1 git checkout Feature1 zuerst sieht man erst wenig, da der neue Branch ja noch identisch zum Master ist. Über den Checkout habe ich aber meine lokale Kopie nun auf den Branch gesetzt, wie an dem kleinen "Stern" zu sehen ist. |
|
|
Nun kann ich weitere Änderungen vornehmen und mit mit verschiedenen Commits einbuchen. Der Branch läuft weiter. git commit git commit In der Zwischenzeit könnte ein anderer Entwickler natürlich am "Master" auch weiter schreiben und die Änderungen dort einchecken. Selbst ich könnte einfach vom Branch "Feature1" mal schnell zum Master wechseln mit: git checkout master git commit Mit einem "git checkout branchname" kann ich zwischen den verschiedenen Zweigen hin und herwechseln. Wenn in dem Verzeichnis aber noch geänderte Dateien liegen, die nicht per Commit irgendwo gespeichert sind, dann verhindert GIT einen Checkout, um Datenverlust zu verhindern. |
|
|
Ein Branch wird man nicht auf Dauer parallel laufen lassen, Er ist in der Regel für einen zeitlich überschaubaren Zeitraum um neue Funktionen ohne Risiko für den Master zu entwickeln und am Ende dann in den Master zu überführen oder zu verwerfen. Das Löschen eines Branch geht sehr einfach mit: git branch -d Feature1 Genau genommen wird hier natürlich keine Datei oder ältere Version gelöscht. Es verschwindet einfach nur der Zeiger auf die Version C4 und der Branch wird quasi unsichtbar. |
|
|
Möchte man die Neuerungen aus dem Branch komplett oder als einzelne Dateien in den Master übernehmen, muss man die Dateien per Merge integrieren. Sie verbinden sich dazu mit dem Master und holen sich das Feature oder auch einen bestimmten Stand: git heckout master git merge FeatureA git merge c4 Damit werden die Änderungen aus dem Branch in den Master übernommen. GIT versucht bei Textdateien hier Konflikte entsprechend aufzulösen. Es bietet sich also an, nicht einen großen langen Spagetti-Code in einer PS1-Datei zu schreiben, sondern modular zu arbeiten. Sie sollten in einer Datei zumindest mit Funktionen arbeiten und auch mehrere Dateien sind von Vorteil, wenn unterschiedliche Personen am gleichen Code arbeiten. Sie reduzieren dabei das Konfliktpotential und ersparen sich das manuelle Aufräumen. Einzelne Dateien eines Branch kann man ich auch "rauspicken". Ich muss nur den Hash mit angeben "git cherry-pic hash" |
|
|
|

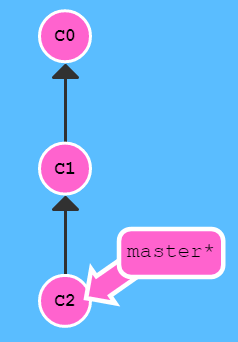



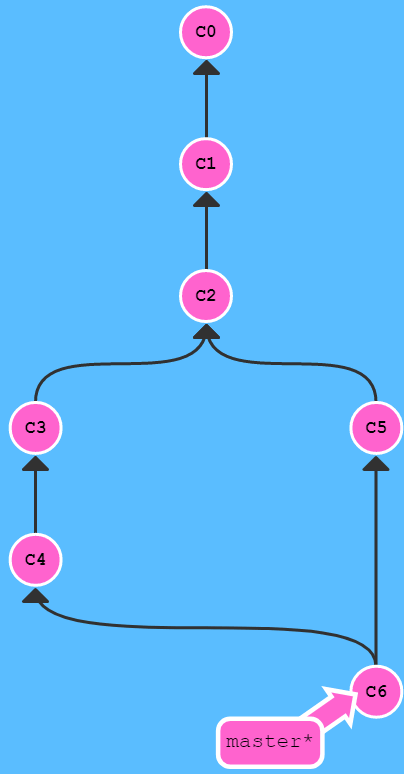
Lassen Sie sich durch die Branches nicht verwirren. Sie sehen von all den Versionen im Dateisystem immer nur die, auf die sie ihren aktuellen Pointer gesetzt haben. Wenn Sie den Blickpunkt wechseln, dann tauscht GIT die Dateien entsprechend aus. Ein Editor muss dass erkennen und darf die Datei dann nicht überschreiben sondern muss die geänderten Dateien neu laden. Sie sollten beim Wechsel der Sicht aber ihren aktuellen und vielleicht geänderten Stand auch schnell mal per Commit sichern.
.All diese Änderungen beziehen sich nun auf ihr eigenes lokales GIT, was für die ersten Schritte vollkommen ausreichend ist. Wenn Sie heute schon Code alleine entwickeln, werden Sie GIT nicht mehr missen wollen. In einen Teams werden Sie aber das ein oder andere Repository mit anderen Entwicklern teilen. Damit kommt die Synchronisation zwischen Systemen ins Spiel. Dazu gibt es aber sehr umfangreiche Anleitungen.
- GIT und GitHub
- The entire Pro Git book
https://git-scm.com/book/de/v2
Auch als PDF, epub, mobi-Download
.gitignore
Viele meiner Powershell-Skripte erzeugen temporäre Dateien, Hashtabellen, Debug-Ausgaben, Kennwortspeicher etc., die eigentlich nichts in der Sourcecode-Verwaltung verloren haben und vielleicht sogar Kundendaten enthalten. Auch Module anderer Entwickler, die man gerne mal einbindet, sollte man nicht im eigenen Code "mitschleppe" sondern besser von der originalen Quellen bei Bedarf aktualisieren.
Über eine Konfiguration in der Datei ".gitignore" können Sie bestimmen, welche Dateien ausgenommen werden sollen. Die Datei können Sie einfach mit einem Text-Editor bearbeiten oder Visual Studio Code enthält ein Kontext-Menü.

- gitignore - Specifies intentionally
untracked files to ignore
https://git-scm.com/docs/gitignore - Gitignore in VSCode
https://dev.to/eclecticcoding/gitignore-in-vscode-17da
Mehrere GITs
Alle Dateien in einem GIT Repository gehören zum gleichen "Projekt" und sind damit auch Bestandteil der gleichen Commits. Wenn ich mir nun meine Skript-Sammlung anschaue, dann gibt es da ja eine ganz große Menge an Skripten. Da kommt dann schon die Frage auf, wie man das sinnvoll organisiert.
- Ein Repository für alle Skripte
Dann hat man mit einem Pull von allen Skripten immer die aktuelle Version. Wenn mehrere Personen an unterschiedlichen Skripten arbeiten, gibt es dennoch selten Kollisionen. Allerdings bedeutet das auch, dass sie keine Berechtigungen aufteilen können. Das Repository ist der Berechtigungs-Container. Auch die Verwaltung von "Branches" bezieht sich immer auf das komplette Repository. Wenn ein Consultant ein Skript für einen Kunden in einem eigenen Branch weiter entwickeln will, ist der Branch für alle Skripte aktiv. Das ist nicht schlimm aber Sie sollten dann den Branch schon sinnvoll benennen, dass er nur einen Teil betrifft. Wenn es immer mehr Skripte werden, dann wird die Datenmenge natürlich auch immer größer und jede Kopie ist ja erst einmal eine "volle Kopie". - Jedes Skript ein Repository
Daher können Sie überlegen, einfach für jedes Skript ein eigenes Repository zu starten. Dann ist jedes Skript autark und Kollegen können selektiv Bereiche per Pull abholen. Wer allerdings 100 Skripte in 100 Repositories ablegt, macht es neuen Mitarbeitern auch nicht immer einfach, diese dann alle zu überschauen.
Einen goldenen Weg gibt es hier nicht. Ich habe mir angewöhnt, wie in Microsoft Teams und auf Dateiservern die Aufteilung vom Einzelfall und der erwarteten Nutzung abhängig zu machen. So könnten Sie ja eigenständige Repositories für Themenbereiche aufteilen. So sind meine Ende zu Ende Monitoring-Skripte ein eigenes Repository aber die einzelnen Skripts selbst sind kein Repository
Auch mit Hinblick auf die Sichtbarkeit müssen Sie eine Entscheidung treffen. Wer Code auch auf GitHub öffentlichen bereitstellen will, kann eben auch nur das komplette Repository veröffentlichen. Skripte, die ein "besonderes Know-how" enthalten, sollten sie daher getrennt verwalten.
GIT-Repositories können sich aber nicht überlappen, d.h. sie sollten nicht ihr "Benutzerverzeichnis" mittels Funktionen von GIT auf einen eigenen GIT-Server replizieren und dann in einem Unterverzeichnis ein eigenes Repository anlegen.
Achtung: Ein Repository enthält auf die früheren Kopien. Es reicht also nicht, so eine Datei zu löschen, da man über "vorherige Versionen" diese wieder sichtbar machen kann. Da ist es dann besser ein neues leeres Repository zu starten und nur die gewünschten Dateien zu übertragen.
Git für andere Dokumente
Auch wenn GIT primäre für die Verwaltung von Sourcecode genutzt wird, so ist es der Versionsverwaltung eigentlich egal, welche Dateien dort enthalten sind. Auch zu Quellcode gehören binäre Dateien wie z.B. Bilder, Audiodaten u.a. Mit GIT lassen sich alle Arten von Dateien synchronisieren und übertragen. Allerdings sind die Fähigkeiten hinsichtlich des Vergleichs (DIFF) oder Zusammenführen (MERGE) bei unbekannten Dateien deutlich eingeschränkt. GIT kann sehr wohl Sourcecode in seine Bestandteile, z.B. Funktionsblöcke, aufteilen und dann sogar Dateien zusammenführen, in denen mehrere Personen gleichzeitig aber an unterschiedlichen Stellen gearbeitet haben.
Auch wenn GitHub mittlerweile zu Microsoft gehört und Office Dokumente (DOCX, XLSX, PPTX u.a.) mittlerweile ja auch ZIP-Archive mit XML-Inhalten sind, so habe ich noch nicht gesehen, dass GIT z.B. auch das Mergen von Office Dokumenten, z.B. auf Basis von Absätzen in Word, Folien in PowerPoint oder Zellen in Excel unterstützt. Ich erwarte dies auch nicht, denn für Office hat Microsoft mit OneDrive, SharePoint und den Office Online Diensten eine Plattform, die normale Anwender einfacher verstehen. GIT-Nutzer sollten es also vermeiden, die gleichen Dateien losgelöst voneinander zu bearbeiten weil der Merge dann eher ein "letzter Schreiber gewinnt" darstellt. Das hindert uns aber nicht, solche Dokumente mit GIT zu verwalten.
Da GIT und Dateien komplett automatisierbar sind und Änderungen verfolgen, eignet sich der Speicher auch für die Ablage von Konfigurationseinstellungen. Wenn Sie z.B. die Konfiguration eines Routers, Switches, Session Border Controller o.ä. als TXT-Datei automatisch exportieren können, kann ein Git-Repository ihnen die Verwaltung der Versionen abnehmen.
Interessant sind hier z.B. "Markdown"-Dokumente, da Git-Server (z. b. GitHub) nicht nur den Zugang per Client sondern auch per Webbrowser genutzt werden kann. Anfangs haben Entwickler über den Weg mal schnell einen Code anschauen können, ohne gleich das Repository zu klonen. Markdown-Dateien können von GitHub aber als HTML-Datei an einen Browser ausgeliefert werden. So können Dokumentationen quasi zusammen mit dem Sourcecode erstellt und verwaltet werden.
Mit Markdown und passenden "Generatoren" können Sie aus er Code-Dokumentation sogar Webseiten, PDF-Dokumente und E-Books erstellen
- MarkDown Dokumente und GitHub
- Markdown
https://de.wikipedia.org/wiki/Markdown - Verwenden von Markdown für das Schreiben
von Dokumentationsartikeln
https://docs.microsoft.com/de-de/contribute/how-to-write-use-markdown
Git als Backup
Git ist ein zentraler Speicher, den sie in der Cloud kaufen oder auch selbst betreiben können und nichts mit SMB, NFS, FTP o.ä. zu tun hat. Es ist "Internet tauglich" und kann so eingerichtet werden, dass es von überall auch erreichbar ist. Zudem überträgt es Änderungen von Dateien. Allerdings funktionieren "Delta"-Versionen für Binärdateien nicht gut. Sehr große Dateien werden eher komplett übertragen und auch komplett gespeichert. Git ist optimiert für Source Code, Test-Dateien etc.
Dennoch könnten Sie natürlich auch ihre Dokumentverzeichnisse auf ihrem PC ebenfalls als Repository definieren und mit Git nicht nur versionieren sondern auch in ein entferntes Repository als Backup hochladen. Das macht man natürlich nicht mit dem "öffentlichen GIT" sondern brau sich einen eigenen Git-Server. Das kann ein lokaler Server oder ein gehosteter Server oder Service sein.
Mit der Versionierung verlieren dann natürlich auch Crypto-Trojaner u.a. Malware ihren Schrecken, da Sie ja wieder auf eine vorherige Version zurück können und sogar die Änderungen nachvollziehen können. Beachten Sie aber, dass auch lokal per Default alle Versionen gespeichert werden. Hier sollten Sie dann auch gelegentlich alte Versionen entfernen.
Ich nutze Git nicht als "Backup" von normalen Dateien. Meine Backup-Strategie ist mehrstufig und sichert die wichtigen Daten kontinuierlich per OneDrive in ein 1TB OneDrive, zudem gibt es Snaptshots des Komplettsystems auf USB-Disks (ca. 1x pro Monat) und weiterhin gibt es den Windows Dateiverlauf auf ein SMB-Laufwerk auf einen OpenMediaVault-Server.
- Using Git as
a backup tool
https://stdout.koraktor.de/using-git-as-a-backup-tool-b98760e04162 - Git unter
openmediavault installieren
http://kabasumo.de/wordpress/blog/2015/04/19/git-unter-openmediavault-installieren/ - https://GitHub.com/git/git/blob/master/Documentation/technical/pack-heuristics.txt
- How to shrink down a git(hub) repository
https://www.saschawillems.de/blog/2017/09/10/how-to-shrink-down-a-GitHub-repository/
GitOps
Git ist aber nicht nur eine Versionsverwaltung, sondern kann noch mehr. Ob das nun der öffentliche GitHub oder ein eigener lokal installierter GitLab-Server ist, macht erst einmal keinen Unterschied. Stellen Sie sich einfach mal vor, sie schreiben Code oder Konfigurationseinstellungen, die beim Commit automatisch weitere Prozesse anstoßen. Sie könnte ein neuer SourceCode durch das Backend geprüft, kompiliert, als Installer paketiert und vielleiht auf eine neu aufgesetzte VM deployed werden um die Funktion zu testen. Für Entwickler kann das viel Arbeit und Zeit sparen.
Aber denken Sie als Administrator einfach mal weiter. Wie wäre es, wenn sie eine Systembeschreibung, Stichwort "Desired State Configuration" über Git verwalten und ihre Server sich Updates über diesen Weg beziehen und diese automatische anwenden? Sie könnten PowerShell-Skripte einmal auf einem Git-Server ablegen und alle Server beziehen sich das Update. Zum Download brauchen sie nicht einmal einen Git-Client, denn die wollen ja keine Kopie des Repository auf ihrem Computer sondern nur eine Auswahl der Dateien. Die können Sie auch einfach per Invoke-Webrequest herunterladen.
Dabei profitieren sie von allen Möglichkeiten von Git mit Versionierung, Branches, Forks, Vier-Augen-Prinzip mit Pull-Requests und integrierter Dokumentation. Sicher ist aller Anfang etwas schwerer als mal eben eine PS1-Datei in Visual Studio Code zu erstellen oder zu überarbeiten und laufen zu lassen. Aber der Aufwand kann es wert sein. Denken Sie mal drüber nach. Und dann ist Git auch wieder etwas für Administratoren und Consultants.
- Was ist GitOps?
https://about.gitlab.com/de-de/topics/gitops/ - What is GitOps, How GitOps works and Why
it's so useful
https://www.youtube.com/watch?v=f5EpcWp0THw
Brauch ich GIT?
Wenn Sie sich bis hier her durchgelesen haben, dann kann ich mir die Zusammenfassung ja sparen. Die Arbeit mit einem Versionsverwaltungssystem für Dateien ist keineswegs nur für Vollzeit-Entwickler Pflicht sondern auch für Administratoren und Consultants interessant, um selbst kleine Skripte sauber zu verwalten. Auf GIT und GitHub habe ich noch mehr Informationen, wie sie auch ihren eigenen GIT-Server bereitstellen. Aber je mehr Code sie schreiben, desto wichtiger ist selbst für eine Einzelperson auf ihrem eigenen PC eine Versionsverwaltung.
Weitere Links
- GIT und GitHub
- Using Version Control in VS Code
https://code.visualstudio.com/Docs/editor/versioncontrol - GitHub is now free for teams
https://GitHub.blog/2020-04-14-GitHub-is-now-free-for-teams/ - HPI Open: Let’s Git - Versionsverwaltung und OpenSource
https://open.hpi.de/courses/git2020 - Git cheatsheet for beginners
https://dev.to/duomly/git-cheatsheet-for-beginners-5apl -
Getting started with Git and GitHub: the complete beginner’s
guide
https://towardsdatascience.com/getting-started-with-git-and-GitHub-6fcd0f2d4ac6 - Visual Studio Code (7): Git als Quellcodeverwaltung einsetzen
https://www.microsoft.com/de-de/techwiese/know-how/visual-studio-code-07-git-als-quellcodeverwaltung-einsetzen.aspx - Open source releases from Microsoft
https://opensource.microsoft.com - Microsoft and Open Source: An unofficial timeline
https://boxofcables.dev/microsoft-and-open-source-an-unofficial-timeline/ - Buch Pro Git
https://git-scm.com/book/de/v1 - How To Run Your Own Git Server
https://www.linux.com/training-tutorials/how-run-your-own-git-server/ - Git-Tutorial: Die ersten Schritte mit dem
Versionskontrollsystem
https://www.ionos.de/digitalguide/websites/web-entwicklung/git-tutorial/













