
PowerShell Workflows
Bei Workflows denken wird oftmals an SharePoint oder Provisioning-Systeme, die den Ablauf von Aktionen seriell steuern. Ich will da grade mal nicht den klassischen Urlaubsworkflow strapazieren. Workflows in PowerShell sind aber eine Option, bestimmte Dinge gerade parallel und nicht sequentiell ablaufen zu lassen. Die Funktion gibt es seit PowerShell 3.0. Auf PowerShell und parallele Verarbeitung habe ich noch andere Wege beschrieben, wie Dinge parallel laufen können.
Workflows funktionieren noch nicht mit PS6+
Beispiel PING
Lange habe ich mich um die Parallelisierung gedrückt. Für die meisten Aktionen ist das auch gar nicht erforderlich oder gewünscht und wenn, konnte ich Skripte ja problemlos mehrfach starten oder mit Start-Job in den Hintergrund schicken. Leider zu einem relativ hohen Preis (CPU, RAM, Umgebung). Meine Aufgabenstellung sah so aus, dass ich mehrere Computer sehr häufig per ICMP-Ping ansprechen wollte. Sagen wir mal ich möchte ein Subnetz scannen. Natürlich können das NMAP und Co auch aber ich möchte die Ergebnisse ja mit PowerShell auswerten. Ich könnte ja auch einen Traceroute parallel starten. Denn sowohl TRACERT als auch PING haben genau wie "Test-NetConnection" das Problem, dass Sie sehr lange auf einen Timeout warten, wenn die Gegenstelle nicht erreichbar ist. Test-NetConnection wartet dann 4 Sekunden und das ist nicht per Parameter einstellbar. Im LAN sind aber Antwortzeiten von wenigen Millisekunden üblich und wenn ein Server nach z.B. 100ms noch nicht geantwortet hat, dann ist er wohl nicht erreichbar.
Sequentiell kann ich ein Subnetz sehr einfach abscannen.
1..254 | foreach { test-netconnection 192.168.178.$($_)}
Aber selbst bei einem Netzwerk, in dem alle Endgeräte aktiv sind, prüft dieser Code jede IP-Adresse sequentiell mit 4 Pings im Abstand von 1 Sekunde und läuft daher 253*4*1Sek oder 100 Sekunden = 16 Minuten. Damit ist heute natürlich kein Blumentops zu gewinnen. Wenn dann noch eine IP-Adresse nicht antwortet, dann wartet Test-Connection noch deutlich länger. Sicher könnte man den ICMP-Ping auch selbst bauen oder den Timeout reduzieren aber darunter leidet dann die Aussagekraft.
- Test-Connection with Timeout
http://community.idera.com/powershell/powertips/b/tips/posts/test-connection-with-timeout
Es kann ja schon mal sein, dass ein ICMP-Paket "verloren" geht oder ein Client nicht schnell genug antwortet. Das Mittel der Wahl lautet also parallelisieren. Auf der Seite PowerShell und parallele Verarbeitung habe ich einige Optionen vorgestellt, die aber
Einfacher Workflow
Schön wäre es, wenn man im Code einfach die Befehle mit einer Klammer umgeben könnte, die diese dann parallel ausführt. Für Workflows müssen Sie aber die Befehle in eine Funktion auslagern, die mit dem Codeword "workflow" vorangestellt definiert wird. Ich möchte das an einem Beispiel einfach mal aufzeigen. der folgende Code gibt drei Ausgaben mit unterschiedlich langer Verzögerung aus.
function ser1 {
# sequentielle Ausgabe
"$(get-date -Format HH:mm:ss) Sequentiell Start"
start-sleep -seconds 1
write-output "$(get-date -Format HH:mm:ss) Sequentiell 1 Sekunde"
start-sleep -seconds 3
write-output "$(get-date -Format HH:mm:ss) Sequentiell 3 Sekunden"
start-sleep -seconds 5
write-output "$(get-date -Format HH:mm:ss) Sequentiell 5 Sekunden"
write-output "$(get-date -Format HH:mm:ss) Sequentiell End"
}
workflow wf1 {
# Parallel als Workflow
parallel {
write-output "$(get-date -Format HH:mm:ss) Workflow Start"
start-sleep -seconds 1
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 1 Sekunde"
start-sleep -seconds 3
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 3 Sekunden"
start-sleep -seconds 5
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 5 Sekunden"
write-output "$(get-date -Format HH:mm:ss) Workflow End"
}
}
write-output "$(get-date -Format HH:mm:ss) Main Start ser1"
ser1
write-output "$(get-date -Format HH:mm:ss) Main Start wf1"
wf1
write-output "$(get-date -Format HH:mm:ss) Main End"
Die Ausgabe muss etwas interpretiert werden. "Start Test1" kennzeichnet den Skriptstart und die Funktion "Test1" läuft sequentiell ab. Von Sekunde 28 bis 37 sind es 9 Sekunden, was genau der Dauer 1+3+5 entspricht.

"Start Test" kennzeichnet den Aufruf des Workflows und die drei Ausgaben kommen in der gleichen Sekunden. Sie können nicht sehen, dass die "Start-Sleep" ebenfalls parallel im Hintergrund laufen. Der längste Codeabschnitt dauert 5 Sekunden, so dass der Workflow in der Sekunde 42 erst zu Ende ist. Das ist aber verständlich, dass das komplette Pakete erst mit dem Ende des längsten Befehls terminiert. Allerdings ist gut zu sehen, dass die Ausgaben schon vorher zurück kommen.
Wenn ich aber einen Workflow als Funktion aufrufe und die Ausgaben in die Pipeline übergebe, dann können diese direkt weiter verarbeitet werden.
workflow wf1 {
# Parallel als Workflow
parallel {
write-output "$(get-date -Format HH:mm:ss) Workflow Start"
start-sleep -seconds 1
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 1 Sekunde"
start-sleep -seconds 3
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 3 Sekunden"
start-sleep -seconds 5
write-output "$(get-date -Format HH:mm:ss) Workflow Nach 5 Sekunden"
write-output "$(get-date -Format HH:mm:ss) Workflow End"
}
}
write-output "$(get-date -Format HH:mm:ss) Main Start wf1"
wf1 | out-default
write-output "$(get-date -Format HH:mm:ss) Main End"
In der Ausgabe sieht man, dass die Ausgaben alle parallel laufen. Im Bild kann man nicht erkennen, dass die Ausgabe auch sofort gekommen ist, d.h. nicht erst nach Abschluss des Workflow

Wenn die den Aufruf aber erst in eine Variable übergebe, dann startet der Code erst nach Abschluss des Workflow
write-output "$(get-date -Format HH:mm:ss) Main Start wf1" $a= wf1 write-output "$(get-date -Format HH:mm:ss) Main Ausgabe" $a write-output "$(get-date -Format HH:mm:ss) Main End"

Bis zur Generierung der Zeile "Main Ausgabe" vergehen ca. 6 Sekunden. Der aufrufende Code wartet dann aber bis zum Abschluss des kompletten Workflows.
Praktischer Einsatz
Ich komme nun wieder auf meinen "PING-Test" zurück, zu dem ich ein komplettes Subnetz einmal "durchpingen" möchte. Ein einfaches "Test-NetConnection" auf eine nicht erreichbare IP-Adresse braucht mit 21 Sekunden sehr lange.
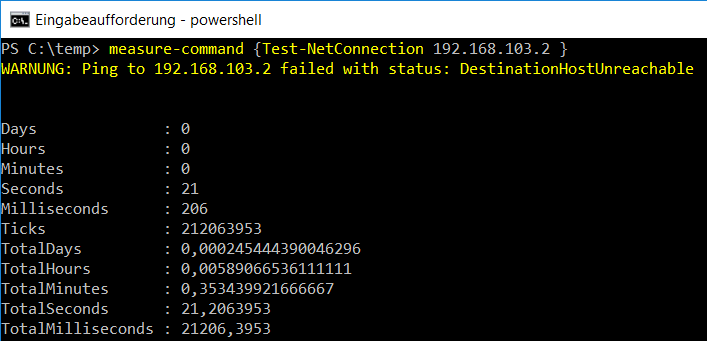
253 nicht erreichbare Hosts würden daraus dann 88 Minuten werden lassen. Daher Nun verpacke ich den Aufruf in einen Workflow und weil es numerische Werte sind, kann ich eine Vorschleife mit der Option "-parallel" nutzen.
workflow scan-subnet([string]$subnet) {
foreach -parallel ($ip in (1..5)) {
"Probing $($subnet).$($ip)"
Test-NetConnection `
-ComputerName "$($subnet).$($ip)" `
-ErrorAction SilentlyContinue
}
}
Write-Output "$(get-date -Format HH:mm:ss) Main Start Scan"
scan-subnet "192.168.103"
Write-Uutput "$(get-date -Format HH:mm:ss) Main End Scan"
Etwas unschön ist dabei immer noch, dass "Test-NetConnection" für einen PING keinen Timeout oder einen Wiederholungswerte als Parameter erlaubt und daher bei einem nicht erreichbaren System schon sehr lange "hängen" bleibt. Mit "Test-Connection" sieht es etwas besser aus.
workflow scan-subnet2 ([string]$subnet){
parallel {
foreach -parallel ($ip in (1..5)) {
"Testing $(get-date -Format HH:mm:ss) Start : $($subnet).$($ip)"
Test-Connection -Count 1 -ComputerName "$($subnet).$($ip)" -ErrorAction silentlycontinue
"Testing $(get-date -Format HH:mm:ss) End: $($subnet).$($ip)"
}
}
}
# Aufruf des Workflow
scan-subnet2 "192.168.103"
An der Ausgabe ist hier aber auch zu sehen, dass der Block in der For-Schleife in sich wieder sequentiell ausgeführt wird aber die Blöcke selbst parallel ablaufen.

Erst wenn alle parallelen Workflows beendet sind, kommt der Code wieder zurück. Ein "hängender" Workflow bremst den weiteren Ablauf. Allerdings scheint es hier noch ein anderes Problem zu geben. Ich hätte schon erwartet, da die erfolgreichen Antworten schneller kommen. Per Wireshark war dann aber zu sehen, dass die Abrufe zumindest auf meinem Windows 10 Client sequentiell erfolgen. Ich könnte mir vorstellen, dass die darunterliegende PING-Klasse nicht mit Workflows harmoniert und die Prozesse aufeinander warten. Man kann aber schon sehen, dass die Reihenfolge nicht dem Aufruf entspricht.
Insofern müssen Sie bei den aufgerufenen Befehlen schon kontrollieren, ob diese auch wirklich "parallel" ablaufen.
- Use PowerShell Workflow to Ping Computers in Parallel
https://blogs.technet.microsoft.com/heyscriptingguy/2012/11/20/use-powershell-workflow-to-ping-computers-in-parallel/ - Use PowerShell to Test Connectivity on Remote Servers
https://blogs.technet.microsoft.com/heyscriptingguy/2012/02/24/use-powershell-to-test-connectivity-on-remote-servers/ - Using Parallel Operations in PowerShell to Write a Port
Scanner
https://virtuallyjason.blogspot.com/2016/11/using-parallel-operations-in-powershell.html
Einschränkungen, z.B. Kein Write-Host
Nicht alle Befehle in einer PowerShell können in Verbindung mit "Workflows" genutzt werden. So ist z.B. Write-Host nicht immer gerade "geeignet" um Ausgaben zu generieren. Ich habe dazu eine eigene Seite Write-Host Debugging geschrieben. In Verbindung mit Workflows funktioniert das gar nicht. Sie bekommen direkt einen Fehler.
In C:\temp\wftest.ps1:14 Zeichen:4
+ write-host "Start"
+ ~~~~~~~~~~~~~~~~~~
Der Write-Host-Befehl kann nicht aufgerufen werden. Andere Befehle aus diesem Modul wurden als Workflowaktivitäten in
ein Paket gepackt, dieser Befehl wurde jedoch ausdrücklich ausgeschlossen. Der Grund ist vermutlich, dass der Befehl
eine interaktive Windows PowerShell-Sitzung erfordert oder dass er ein Verhalten aufweist, das für Workflows nicht
geeignet ist. Wenn Sie diesen Befehl dennoch ausführen möchten, platzieren Sie ihn innerhalb eines Inlineskripts
("InlineScript { Write-Host }"), wo er isoliert aufgerufen wird.
+ CategoryInfo : ParserError: (:) [], ParseException
+ FullyQualifiedErrorId : CommandActivityExcluded
Es gibt noch andere Dinge wie z.B. die Switch-Anweisung u..a
- PowerShell Workflows: Restrictions
https://blogs.technet.microsoft.com/heyscriptingguy/2013/01/02/powershell-workflows-restrictions/
Erweiterungen
Es gibt noch so viel Dinge, die ich mit Workflows untersuchen müsste, z.B. Auswirkungen auf die CPU-Belastung und Hauptspeicher. Funktionen wie "Start-Job" oder "-asJob starten ja quasi eine teure eigene Umgebung. Die Workflows hingegen laufen in der gleichen Umgebung und nutzen entsprechend auch die geladenen Module. Aber der Zugriff auf Variablen muss natürlich koordiniert werden. Mehrere parallele Jobs sollten nicht die gleichen Variablen verändern. Ich behelfe mir immer so, dass an den Job übergebene Variablen nicht geändert werden sollen und die Rückgabe für die Ergebnisse genutzt werden. Diese können dann vom aufrufenden Programm weiter verwendet werden.
Parallele Programmierung kann Dinge sehr beschleunigen aber zugleich Fehler mitbringen, die sehr schwer zu entdecken sind.
Weitere Links
- PowerShell und parallele Verarbeitung
- Getting Started with Windows PowerShell Workflow
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2012-R2-and-2012/jj134242(v=ws.11) - Learn PowerShell Workflow for Azure Automation
https://docs.microsoft.com/en-us/azure/automation/automation-powershell-workflow - PowerShell Workflows: The Basics
https://blogs.technet.microsoft.com/heyscriptingguy/2012/12/26/powershell-workflows-the-basics/ - PowerShell Workflows: Restrictions
https://blogs.technet.microsoft.com/heyscriptingguy/2013/01/02/powershell-workflows-restrictions/ - Windows PowerShell Workflow Concepts
https://docs.microsoft.com/de-de/system-center/sma/overview-powershell-workflows?view=sc-sma-1801 - Use PowerShell Workflow to Ping Computers in Parallel
https://blogs.technet.microsoft.com/heyscriptingguy/2012/11/20/use-powershell-workflow-to-ping-computers-in-parallel/ - About_Parallell
https://docs.microsoft.com/en-us/powershell/module/psworkflow/about/about_parallel?view=powershell-5.1 - About_InlineScript
https://docs.microsoft.com/en-us/powershell/module/psworkflow/about/about_inlinescript?view=powershell-5.1 - Workflow-Konzepte in Windows PowerShell
https://docs.microsoft.com/de-de/system-center/sma/overview-powershell-workflows?view=sc-sma-1801 - VMWare PowerCLI And PowerShell Workflows
http://www.lucd.info/2015/03/17/powercli-and-powershell-workflows/













