
Exchange im Cluster
Lesen Sie unbedingt auch Hochverfügbarkeit und Clustergrundlagen. Sie finden dort sehr viele Grundlagen zum Clustereinsatz im unternehmen. Sie finden hier keine Beschreibung mehr für Exchange 5.5 Cluster, da ich nicht davon ausgehe, dass diese noch installiert werden. Die Funktion von Exchange 5.5 ist sehr unterschiedlich zu Exchange 2000/2003.
Lesen Sie unbedingt "vorher" Hochverfügbarkeit und Clustergrundlagen, und dort insbesondere den Hinweis, welche Dienste nicht auf Cluster installiert werden können.
Exchange 2003 mit Windows 2003 unterstützt bis zu 8
Clusterkonten mit 7 aktiven virtuellen Servern a 20 Datenbanken.
![]() http://msexchangeteam.com//archive/2005/09/09/410522.aspx
http://msexchangeteam.com//archive/2005/09/09/410522.aspx
Servicepack und Cluster.
Sie können das Servicepack problemlos auf dem passiven Knoten installieren.
Nur installieren Sie das Service Pack immer von einer lokalen Festplatte
oder einem Netzwerklaufwerk und NICHT von einer Shared Disk, das das Setup
den Clusterdienst am Ende durchstartet und damit selbst nicht mehr auf seine
Quelle kommt.
Formbased Authentication ist nur mit Frontend Servern
möglich
834637 The "Enable Forms Based Authentication" check box is unavailable in
Exchange Server 2003
Exchange 2010
Mit Exchange 2010 wurde die Thematik Cluster noch mal kräftig umgekrempelt. CCR, LCR und SCR ist nicht mehr und statt dessen gibt es nur noch die Database Availability Group für die Postfachspeicher und LoadBalancer bzw. NLB für die CAS/HT-Rollen.
Exchange 2007
Mit der Verfügbarkeit von Exchange 2007 gibt es eine neue Möglichkeit, Exchange hochverfügbar zu betreiben. Details hierzu finden Sie auf
Exchange 2000/2003 im Cluster
Exchange 5.5. konnte nur auf einen Cluster mit zwei Knoten im Aktiv/Passiv Mode betrieben werden. Dies bedeutet, dass ein Knoten Exchange betrieben hat, während der andere Knoten nur darauf gewartet hat, dass der erste ausfällt.
Exchange 2000 bietet nun Aktiv/Aktiv an, d.h. beide oder alle vier Knoten sind aktive Server. bei einem 4-Knoten Cluster sehen Sie im Netzwerk auch mindestens 8 Server !!. Die vier einzelnen Knoten als Windows 2000 Server und zusätzlich vier Exchange 2000 Server. Aber sie sehen nicht, auf welchen Knoten welcher virtuelle Exchange Server gestartet ist. Im schlimmsten Fall übernimmt der einzige verbliebene Server alle vier virtuelle Server.
Jeder virtuelle Exchange hat dabei seine eigene Festplatte oder mehrere Festplatten, denn aus der Information zur Exchange Datenbank wissen wir, dass Datenbank und Transaktionsprotokolle getrennt sein sollten. Nun ist auch klar, warum Exchange bis zu vier Speichergruppen unterstützt. für den Betrieb von Exchange im Cluster benötigen zu je Knoten eine Lizenz Exchange 5.5. Enterprise oder Exchange 2000 Enterprise.
Sie dürfen das Exchange Setup erst aufrufen, nachdem der Server schon Mitglied des Clusters ist. Nur dann erkennt das Setup, dass es sich um eine Clusterinstallation handelt. Bei der Installation werden alle Programme auf die lokale Festplatte des Clusters installiert. Die Installation darf NICHT auf den gemeinsamen Festplatte erfolgen.
Erst nach der Installation auf allen Knoten sollte dann die Ressource "Exchange System Aufsicht" eingerichtet werden. Der Assistent richtet dann alle anderen Ressourcen für Sie ein.
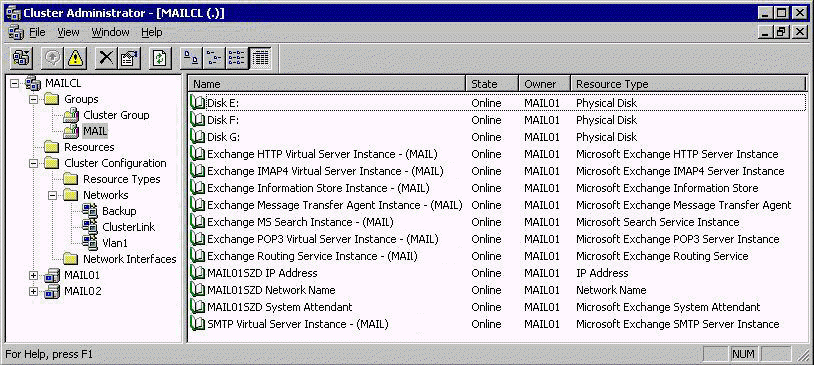
Das Bild zeigt einen einfachen 2-Knoten Cluster mit zwei Gruppen. Die erste Gruppe enthält nur den Clusternamen, das Quorum und die dazugehörige IP-Adresse. Die angezeigte zweite Gruppe ist der eigentliche Exchange Server. Es ist sinnvoll dies zu trennen, da damit der Cluster auch funktioniert, wenn z.B. die Exchange Gruppe "offline" ist.
Der primitive Cluster
Zum Einstieg planen wir einen sehr kleinen Cluster. Dieser soll nur die Prinzipien erklären und sollte in der Form nicht installiert werden.
Zwei identische Knoten werden mit einer Netzwerkkarte an das Hauslan angeschlossen und über eine zweite Karte als Heartbeat verbunden. Der Cluster könnte zwar auch ohne diese zweite Verbindung arbeiten, aber dann müsste beim Ausfall des Netzwerks jeder Cluster erst über das Quorum klären, welcher denn nun DOWN ist und welcher nicht. Ein separates Heartbeat Netz ist daher eine Mindestvoraussetzung für einen Cluster. Hierzu reicht aber auch eine 10MBit-Karte mit einem Kreuzkabel, so dass Kosten kein Grund auf einen Verzicht sind.
Weiterhin haben beide Cluster einen SCSI-Controller, der an einen gemeinsamen Speicherbereicht angeschlossen ist. Es gibt unterschiedliche Lösungen, wer nun das "RAID-1" bildet. Sehr einfache Lösungen nutzen den RAID-Controller im Host selbst, um das RAID zu bauen. Etwas bessere Lösungen haben einen eigenen RAID-Controller im Speichersubsystem, der den einzelnen Controllern eine Festplatte simuliert. Die Verbindung kann dabei auf drei Wege erfolgen:
- Shared SCSI-Bus
Es ist möglich, die Festplatten und beide Controller auf einen BUS anzuschließen und zu betreiben. Das Problem hierbei ist aber die Terminierung dieses Busses und die begrenzte Länge der Kabel. Besonders wenn ein Server dann abgeschaltet wird, muss durch geeignete Terminatoren sichergestellt werden, dass der Bus IMMER richtig terminiert ist - Y-SCSI-Bus
Eine Besonderheit ist daher ein Y-Kabel mit entsprechender Elektronik, so dass von jedem Knoten zum Speicherpool ein eigener SCSI-Bus führt. Sehr häufig ist dabei ein aktiver SCSI-Controller (z.B. Mylex DAC960FL) im Subsystem, der den Anschluss von zwei Servern erlaubt. - Fibre Channel
Die elegante, schnelle und beste aber noch relativ teure Anbindung ist die Nutzung von Fibrechannel über Glasfaser oder Kupfer. - iSCSI
Vermutlich wird es zukünftig auch Speicheranbindungen über normale Netzwerkkomponenten (Stichwort iSCSI) geben.
Sie sollten schon zur eigenen Sicherheit nur Komponenten einsetzen, die auf der Windows Cluster HCL aufgeführt sind. Auch bei BIOS-Update ist mit Vorsicht vorzugehen, da einige Controller für den Einsatz im Cluster ein anderes Bios verwenden oder in der Konfiguration der Betrieb an einem Shared BUS explizit zu aktivieren ist.

Da nur eine gemeinsame Festplatte zur Verfügung steht, kann auch nur eine Clustergruppe eingerichtet werden. Dies macht der Assistent zur Clusterinstallation für Sie. In dieser Clustergruppe wird die Systemaufsicht angelegt. Der Assistent erfragt dann gleich die Pfade für die Datenbanken und Protokolldatei. Diese können Später mit dem Exchange System Manager wieder verschoben werden.
In diesem Beispiel ist die gemeinsame Platte aber zumindest in zwei Partitionen getrennt, damit das Laufwerk für die Quorum Disk nicht durch Exchange voll geschrieben werden kann. Best practice ist natürlich, dass die Festplatte für das Quorum eine eigenständige Festplatte ist.
Diese Mustercluster hat einige Defizite, die einer Realisierung widersprechen:
- Keine Trennung von Datenbank und Transaktionsprotokollen
Die Performance ist geringer aber wenn diese logische Festplatte inkonsistent ist, dann sind Datenbank und Transaktionsprotokolle betroffen. Ein "RollForward" nach einem Restore ist nicht möglich. - keine Trennung von Quorum und Anwendungsdiensten
Wenn warum auch immer das Quorum wechseln muss, muss auch Exchange mit umschwenken, da alle Resourcen in einer Gruppe sind. Zumindest haben wir das Quorum in dieser Minimalkonfiguration logisch getrennt, damit ein Vollaufen der Datenbank nicht gleich den ganzen Cluster - Gleicher Name und IP
Name und IP-Adresse des Clusters ist zugleich auch der Name und IP-Adresse von Exchange.
Spätestens jetzt ist klar, dass dieser Cluster nur zum Üben gedacht ist.
Der kleine Cluster
Aber was ist dann der kleinste "richtiger" Cluster ?. Entsprechend der Vorgaben bedeutet eine sinnvoll unsere Grenze, dass
- Ein Cluster aus zwei Clustergruppen besteht.
Eine für die Clusterverwaltung selbst und die zweite Gruppe für Exchange - Die Datenbanken und Protokolldateien getrennt sind
- Der Shared Storage nicht an einem Bus hängt.
Demnach stellt sich das Bild wie folgt dar: Beide Knoten haben wieder eine Verbindung zum Hauslan und ihren Clusterlink. Das Speichersubsystem ist über getrennte SCSI-Kanäle angeschlossen und drei logische Festplatten werden dem Cluster präsentiert.
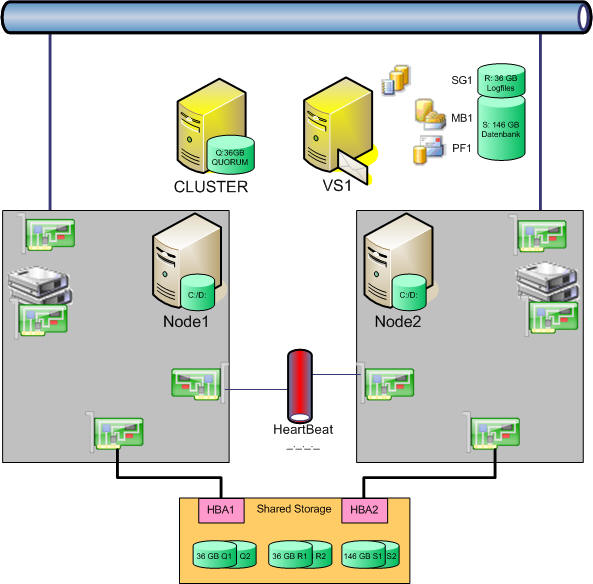
Eine RAID1-Disk für das Cluster Quorum und zwei RAID1-Disks für die Exchange Datenbank und Transaktionsprotokolle. Denkbar ist natürlich auch ein RAID5, allerdings sollte sie immer beachten, dass ein RAID5 in der Regel langsamer ist, sie mehr Platteneinschübe brauchen und zwei größere Festplatten nicht unbedingt viel teurer sind als drei kleine Festplatten. Speziell wenn Sie sich damit dann Einschübe für spätere Erweiterungen verbauen.
Der mittlere Cluster
Wenn ihnen der kleine Cluster nicht reicht, dann wird es Zeit etwas mehr zu machen. Die Steigerung bei dem Beispiel besteht darin, dass:
- Adapter-Teaming auf dem Netzwerk
Um den Ausfall einer Netzwerkkarte oder eines Einschubs im Switch zu verhindern oder die Bandbreite zu erhöhenn werden zwei Netzwerkkarten als Team verschaltet. - Weitere Speichergruppe und weitere Datenbanken sind hinzu gekommen.
- Die Anbindung wurde auf Fibrechannel mit zwei Switches und doppelter Anbindung der Server erweitert
Wenn Sie schon für Hochverfügbarkeit planen, dann sollte es möglichst wenig "Single Point of Failure" geben. Kabel und Karten sind immer gefährdet so dass redundante Wege eine gute Sache sind.
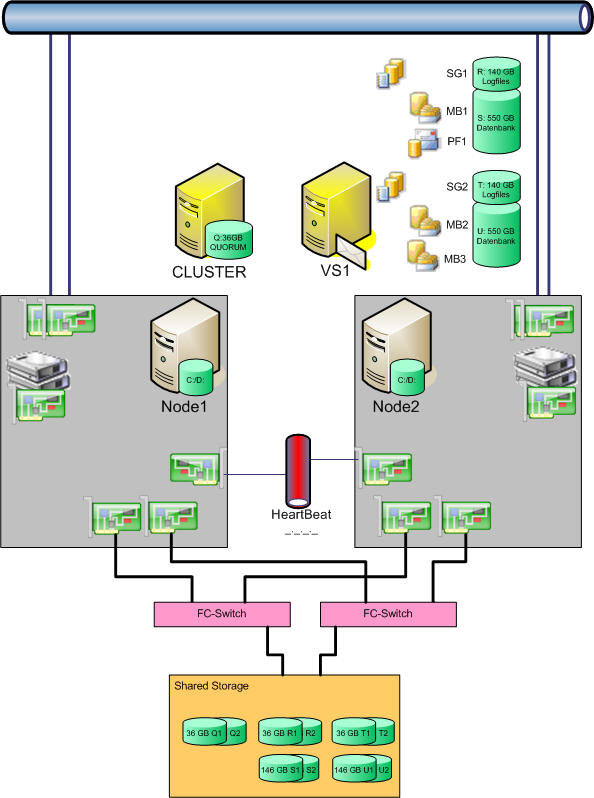
Beachten Sie beim Teaming, dass die meisten Netzwerk kein Loadbalancing Teaming über mehrere Switches unterstützen, sondern nur ein Failover Team. Trotzdem ist dies weiterhin ein Aktiv/Passiv Cluster, weil es nur eine Clustergruppe gibt, in der allerdings zwei Speichergruppen mit mehreren Datenbanken liegen. So haben wir eine gesteigerte Performance und die unabhängigkeit im Bezug auf Backup etc. (Siehe auch Exchange Sizing - Speichergruppen und Datenbanken).
Einen Aktiv Aktiv Cluster wäre mit dieser Konstellation auch möglich. Allerdings besteht bei einem A/A-Cluster immer das Problem, dass nach einiger Zeit der Speicher doch fragmentiert wird und ein Failover damit nicht mehr sicher gegeben ist. Es gibt immer wieder mal Empfehlungen von Microsoft, dass A/A funktioniert, wenn nicht mehr als 1000 bis 1500 Verbindungen pro Knoten betrieben werden.
Nur zur Erinnerung: Dieser Cluster benötigt mindestens 4 IP-Adressen im Hauslan (Node1, Node2, CLuster und VS1) und die Adressen für den Clusterlink.
Enterprise Cluster
Um, die Hardware besser Auszunutzen kann man aber aus 4 Clusterknoten einen Cluster formen, bei dem drei Knoten aktiv sind und einer passiv bleibt. So funktioniert ein Failover beim Ausfall eines Knotens zuverlässig. Der mittlere Cluster hatte schon sehr viel Dinge hochverfügbar angelegt. Aber bislang ist der Shared Storage immer die Achillesferse der Cluster geblieben. Diese Konfiguration erweitert den Cluster nun um folgende Komponenten:
- 4-Node A/A/A/P
Drei aktive Knoten und ein passiver Knoten nutzen die Hardware zu 75% aus. - redundante müssenspeicher
Es gibt SAN-Speicher, die sich selbst replizieren, Dazu gehören z.B.: Systeme wie eine EMC Symmetrix, die alle Daten an zwei Orten synchron halten und damit auch den Totalausfall eines Systems verkraften. Die nächste Steigerung wäre dann ein geografisch verteilter Cluster, bei dem die Knoten in verschiedenen Orten stehen - BCVs
Datensicherung und Restore ist wichtig und notwendig. Wenn aber doch einmal eine Festplatte logisch korrupt ist, dass sind für den Desasterfall schnelle Lösungen gefragt.
Damit wird das Bild natürlich etwas umfangreicher und damit sind die Möglichkeiten von Exchange immer noch nicht ausgeschöpft. Exchange 2000/2003 kann ja bis zu 20 Datenbanken betreiben. In diesem Muster sind es "nur" fünf Postfachspeicher und einen Speicher für öffentliche Ordner.
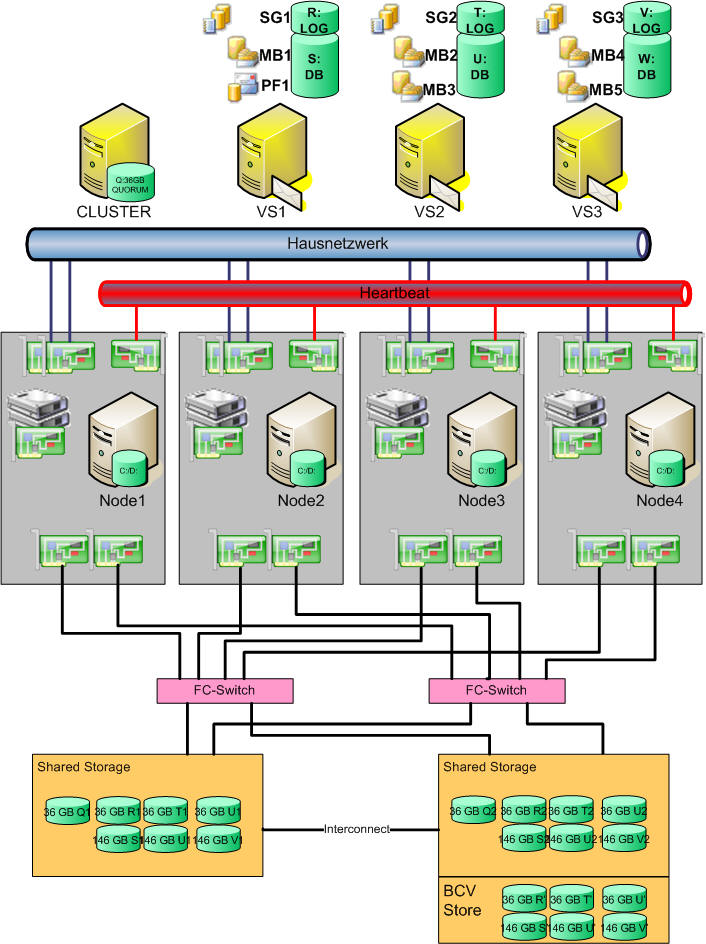
Die doppelten Speichereinheiten stehen natürlich am besten in verschiedenen Räumen, Etagen, Gebäudeabschnitten, Brandabschnitten. Über die beiden FibreChannel Switches und doppelte Anbindungen ist jede Komponente doppelt abgesichert. Wenn Sie aber mal genau zählen, dann werden Sie feststellen dass Sie...
- ... 7 LWL-Doppeladern zwischen beiden Gebäuden frei haben müssen.
- ... 8 IP-Adressen im Hauslan benötigen (4x physikalische Nodes, 4 virtuelle Server)
- ... 14+6 logische Festplatten benötigen, die ihrerseits natürlich am besten durch RAIDs abgesichert sind.
- ... 4 Windows 2003 Enterprise Server und
... 4 Exchange 2003 Enterprise Server Lizenzen benötigen. - ... zwingend eine Software benötigen, die aus den vielen virtuellen Pfaden zu den Festplatten logisch einen machen (z.B. EMC Powerpath, IBM SDD, HP SecurePath)
- Und wie Sie das alles auf Bänder sichern ist noch eine Geschichte für sich
Aber das ist genau das, was Sie sich unter Windows Datacenter vorstellen können. Und seit Exchange 2003 und Windows 2003 können Sie mit dem ganz normalen Enterprise Version sogar einen 8-Knoten-Cluster aufbauen.
Cluster Migration
Ein Exchange Server im Cluster sieht wie ein "normaler" Exchange Server aus. Wenn Sie die Daten ihres bestehenden Server auf einen Cluster bringen wollen, dann sollten Sie die Postfächer verschieben und die Ordner replizieren. Bitte versuchen Sie nicht, einen einzelnen Server mit Exchange nachträglich zum Cluster umzubauen. Das geht höchstwahrscheinlich schief. Sie können dies versuchen, indem sie ihren aktuellen Datenbestand sichern, den Server neu als Cluster installieren und dann ein Restore in den Cluster machen. Aber meist ist der vorhandene Server sowieso älter und nicht Cluster zertifiziert, so dass diese Option recht selten sein sollte.
Wenn Sie sich die Ausführung von oben noch mal durch den Kopf gehen lassen, dann sollten Sie erkennen, dass sie besser den Cluster neu kaufen und installieren und ihren bisherigen Exchange Server einer anderen Verwendung, z.B. als OWA-Server in der DMZ oder als Server für Connectoren zuführen.
Weitere Hinweise
Und dann gibt es noch die üblichen Hinweise, die aber 100% ernst gemeint sind:
- Es gibt eine Hardware Compatibility List für Windows Cluster.
Kaufen Sie kein System, welches nicht für Cluster zertifiziert ist. - Planen Sie kein System nur mit einem Assistenten oder einer Webseite
Holen Sie sich einen Fachmann ins Haus, der ihre Planung überprüft und ihnen wertvolle Hinweise gibt. - Vergewissern Sie sich, dass auch das Umfeld stimmt.
Ein Cluster in einem Baustellenkontainer oder ohne uSV ist nicht sinnvoll. - Uptime = Servicelevel
Suchen Sie einen Hersteller der schnell Ersatz liefern kann, der Erfahrung mit Cluster hat, der zertifiziert ist. - ...
Was sie bis jetzt vergessen haben, welchen sie beim ersten Ausfall argumentieren müssen. Wenn sie unsicher sind, dann brechen Sie ab. Sie können nur verlieren. Entweder sie verlieren ihren Kunden oder ihren Arbeitsplatz. Sie versprechen mit einem Cluster uPTIME und mangelnde Verfügbarkeit ist sehr leicht zu belegen.
Wir betreuen Windows 2000 Dateiserver mit 900 Gigabyte und über 30 Festplatten ebenso wie Exchange Server für 4000 Postfächer mit permanenten Lasten von 10 Nachrichten pro Sekunde und mehreren Gigabyte Transaktionsprotokolle pro Stunde. Sowohl Windows als auch Exchange sind skalierbar, robust und für ernsthafte Anwendungen ausgelegt. aber nicht auf einem PC vom Discounter mit einem Hardwaredesign aus der Bastelkiste.
Cluster und Servicepack
Die Installation eines Servicepack auf dem Cluster ist im Prinzip einfach. Sie verlagern die Ressourcen derart, dass ein Knoten keine Dienste mehr hat und installieren dort das Servicepack. Danach müssen Sie im Cluster Administrator diesen Knoten noch "hochrüsten". Beim Verlagern der Ressourcen auf diesen Knoten werden dann eventuell die Daten auch aktualisiert. Ein Fallback auf Knoten ohne Servicepack ist meist nicht möglich. Also müssen Sie nun auch noch die anderen Knoten nacheinander reihum aktualisieren.
Ob Exchange einen Knoten als "Hier ist Exchange installiert" erkennt, macht er an einem Registrierungsschlüssel (MSExchange_NodeState und MSExchange_CurrentBuild) fest, welche durch die Installation gesetzt werden.
Suchen Sie besser den Grund, warum, das Setup den Wert nicht gesetzt hat und setzen Sie den Wert nicht manuell. Ein "Setup /Reinstall" und Servicepacks ist die bessere Wahl.
Die Bedeutung der beiden Schlüssel:
- "MSExchange_NodeState=1"
Kennzeichnet, dass auf diesem Knoten die Exchange Programmdateien installiert sind - MSExchange_CurrentBuild
Enthält die aktuelle BUILD-Version. Ist diese niedriger als der Eintrag in der Systemaufsicht, dann haben Sie das Menü "Upgrade virtual Server".
Die aktuellen Versionen könne Sie durch die beiden Kommandozeilen erhalten
Anzeige der Exchange Version auf den Knoten:
cluster.exe /node "NODENAME" /priv
MSExchange_CurrentBuild:
NODE1: 500563969
NODE2: 473563136
Anzeige der Version der Systemaufsicht
cluster.exe /res "Name der Systemaufsicht" /priv
System Attendant ResourceBuild:
473563136
Natürlich sind manuelle Änderungen ohne Zusammenarbeit mit Microsoft hier nicht ratsam.
Kleiner Clusterwächter
Wenn Sie nun ihre Cluster installiert haben, dann kann es sein, dass Sie einen Fail-Over eigentlich gar nicht bemerken, besonders wenn dieser außerhalb der Geschäftszeiten statt findet. Hier können Sie sich mit einem einfachen Batch behelfen. Jede Clustergruppe hat eine gemeinsam genutzte Festplatte. Auf dieser gemeinsamen Festplatte legen Sie einen kleinen Batch "Clusterwatch.cmd" mit folgendem Inhalt an:
echo off
echo %DATE% % TIME% Clustergruppe wurde gestartet >>clusterinfo.txt
echo Info | blat.exe - -server mailserver -to ziel@firma.de -f sender@firma.de -s
Clusterschwenk
PAUSE
Dieser kleiner Batch wird nun in der Clustergruppe als Ressource (Generic Application) mit eingebunden.
Befehlszeile : S:\Clusterwatch\clusterwatch.cmd
Aktuelles Verzeichnis: S:\Clusterwatch\
Was nun passiert ist schnell erklärt:
- Failover oder Neustart
Immer wenn die Clustergruppe und damit auch diese Ressource startet, wird der Batch ausgeführt - Funktion
Dieser schreibt den Start in eine Textdatei und sendet eine Mail mittels Blat an den Mailserver (Dies sollte natürlich nicht der Cluster selbst sein). - Die Aufgabe der "Pause"
Durch den "PAUSE"-Befehl am Ende wird der Batch nie beendet, was aber erforderlich ist, da ansonsten der Cluster diese Ressource als "Failed" erkennt (die CMD.EXE wäre ja beendet, wenn die PAUSE dies nicht verhindern würde)
Wenn nun der Cluster aufgrund eines Fehlers schwenkt, wird zwar nicht mehr das "Offline"-Nehmen der Clustergruppe gemeldet, aber das erneute Online-Schalten auf einem anderen Knoten sehr wohl. Das ersetzt zwar kein Monitoring, wie dies z.B. mit MOM2005 möglich ist, aber zumindest ein kleiner Hinweis auf umschaltvorgänge auf dem Cluster Server.
Wenn Sie übrigens MOM2005 für die Überwachung einsetzen, dann sollten Sie folgende Aussage beachten.
The agent is deployed to the nodes and the Management Pack is deployed to the Virtual Servers.
Dies bedeutet, dass Sie den MOM-Agenten selbst auf jeden Knoten installieren müssen aber das Management nur auf die virtuellen Server anwenden, d.h. in der Computergruppe "Exchange Backend Server" die virtuellen Server addieren und optional die physikalischen Knoten ausschließen.
- 260527 Generating Notifications für an MSCS Resource Problem
Ein Microsoft-KB-Artikel, der genau die gleiche Idee zeigt aber nur ein NET SEND macht, was unter 2003 und XP per Default nicht mehr geht (Nachrichtendienst ist beendet) - MSH Cluster Watcher script
http://mow001.blogspot.com/2005/12/msh-cluster-watcher-script.html
Cluster Checkliste
Der wichtigste Check für eine bestehende ClusterUmgebung ist natürlich ExBPA. Aber einige Eckpunkte sollten Sie im Cluster noch manuell überprüfen, z.B.:
- Eventlog Replikation
Per Default replizieren Cluster ihre Eventlogs auf alle Knoten. Das ist hilfreich, wenn ein Knoten ausfällt und das Eventlog dort damit nicht mehr erreichbar ist. Sie können dann auf dem aktiv gewordenen Knoten auch die Events des anderen Knoten nachschauen. Wenn Sie aber eh MOM oder eine andere Eventlogüberwachung nutzen, dann können Sie diese Replikation mit folgendem Befehl abschalten:
Cluster.exe /prop EnableEventLogReplication = 0
- Monitoring
Ein Cluster kann viele "Probleme" selbst lösen und wenn es erst durch einen Failover geht. Viele Anwender "merken" das nicht mal, aber sie als Administrator sollten dies immer schnell erfahren. Es kann ja der Anfang eines Desasters sein. Also lassen Sie automatisch Eventlogs überprüfen. - PreferredOwner
Jeder Clusterressource sollte einen bevorzugten Besitzer haben, auf dem Sie läuft. Zwar ist dies nicht wirklich essentiell aber für Sie als Administrator ist es speziell bei einem Mehrknotencluster schon wichtig zu wissen, welcher Knoten gerade "passiv" ist. Und es fällt dann schnell auf, wenn ein Clusterschwenk passiert ist.
Ein Preferred Owner ist um so wichtiger je mehr Knoten ihr Cluster hat. Wenn Sie z.B. einen A1/A2/A3/P1/P2/P3 Cluster haben, und ein aktiver Knoten fällt aus, dann sollten dessen Ressourcen natürlich auf einen passiven Knoten schwenken. So sollte der "Referred Owner" einer Ressourcegroup also z.B. A1/P1/P2/P3 enthalten und nicht A2 oder A3.
Das ganze macht natürlich nur Sinn, wenn Sie "genug" passive Knoten haben. - Failover/Retry/AutoFallBack
Eine Clustergruppe besteht immer aus mehreren Ressourcen. z.B.: hat ein Fileserver jede Menge "Shared". Nun kann es passieren, dass ein Mitarbeiter einfach das Verzeichnis eines Share löscht, ohne die Clusterressource zu löschen. Der Cluster erkennt einen "Ausfall" und schwenkt die komplette Gruppe. Im schlimmsten Fall 5 Mal (Default). Eventuell ist es sinnvoller, bei solchen Ressourcen die Option "Affekt Group" zu deaktivieren oder zumindest die Wiederholversuche zu reduzieren. Auch die Trennung in mehrere Ressourcegroups (mit entsprechenden eigenen Physical Disk Ressourcen) ist daher zu überlegen - ClusterLan
Immer noch finden sich Cluster, die kein eigenes privates Subnetz für ihre Kommunikation haben oder auf dem geplanten privaten Netz weiterhin der MSClient gebunden und aktiv ist. Ein guter Cluster hat mindestens ein eigenes privates LAN für die Kommunikation, welches auch in der Netzwerk Priorität ganz oben steht. Auch Problemen mit der "Auto Negotiation" geht man am besten aus dem Weg, wenn die Daten auf dem Server und dem Switch fest eingestellt werden. - Monitoring
Wie ich schon an vielen anderen Stellen geschrieben habe ist ein Cluster ohne Überwachung eher ein Risiko denn eine Verbesserung für ihr Netzwerk. Ein Cluster hilft nicht bei defekten Festplatten, fehlerhaften Programmen und Datenbeständen oder so trivialen Probleme wie eine voll gelaufene Festplatte. Daher ist eine Überwachung ein Muss.
Eine gute Beschreibung hierzu finden Sie auch auf der TechNet unter ms-help://MS.TechNet.2006FEB.1033/exchange/tnoffline/prodtechnol/exchange/exchange2003/proddocs/library/e2k3clst.htm
Cluster Debugging
Eigentlich ist der Status eines Clusters im Clustermanager sehr einfach einzusehen. Wenn aber doch mal ein Failover stattfindet oder andere Probleme genauer zu untersuchen sind, dann ist das Eventlog die erste Anlaufstelle. Beachten Sie dass die Eventlogs zwischen den Clusterknoten repliziert werden, dies aber abschaltbar ist.:
| EventID | Beschreibung |
|---|---|
1203 |
Start eine Clustergruppe "Offline" zu nehmen. Dies ist meist der Start eines Failovers und erscheint auf dem Cluster, der dann die Gruppe aktiv betreibt |
1204 |
Gruppe wurde erfolgreich offline geschaltet |
1200 |
Start eine Clustergruppe "Online" zu nehmen. Dies Meldung erscheint dann auf dem Knoten, der nun diese Gruppe aktiv betreiben soll. |
1201 |
Gruppe erfolgreich online geschaltet und zeigt das Ende eines Failovers an. Darauf kann man sehr gut filtern, um die umschaltungen zu finden |
1069 |
Allgemeiner Fehler. Diese Meldung hilft bei der Eingrenzung, welche Ressource für den Failover verantwortlich war |
All diese Meldungen helfen aber nicht, wenn der Clusterdienst selbst ein Problem hat. Daher kann manb zusätzlich auch noch ein Debugging einschalten (Siehe Q168801 How to turn on cluster logging in Microsoft Cluster Server). Dabei wird etwas ungewöhnlich über System-Umgebungsvariablen dem Clusterdienst gesagt, wohin und in welcher Detailtiefe er Debug-Ausgaben schreiben soll
- ClusterLog=C:\cluster.log
Diese Variable aktiviert das Log in die angegebene Datei - CLUSTERLOGSIZE
Das Logfile wird dabei maximal 8 Megabyte groß. Wenn es diese Größe erreicht, dann wirft der Clusterdienst die ersten 4 MB weg. Über diese Variable können Sie die Größe abweichend einstellen (Wert in Megabyte) - ClusterLogOverwrite
Hiermit können Sie steuern, ob der Cluster beim Start des Diensts die Logdatei überschreibt. - ClusterLogLevel= 0-3
Dieser Parameter beeinflusst die Detailausgabe, wenn Sie den Clusterdienst mit der Option "/debug" starten.
In der Datei sollten dann ausreichend Informationen landen, um den Fehler genauer einzukreisen. Wem das immer noch nicht hilft, kann den Clusterdienst auch mit der Option "/debug" starten, so dass in dann geöffneten Fenster weitere Meldungen angezeigt werden.
- How to create the cluster.log in Windows Server 2008
Failover Clustering
http://blogs.msdn.com/b/clustering/archive/2008/09/24/8962934.aspx
Weitere Links
- Clustergrundlagen
- Frontend/Backend Konstellation
- Cluster Continuous Replication
-
Exchange 2007 High Availability
http://technet.Microsoft.com/en-us/library/bb124721.aspx - White Paper: High Availability in Exchange Server 2007
http://technet.Microsoft.com/en-us/library/2ab0f608-5c19-43cb-bf7a-7240a2e5ef88.aspx - Exchange 2007 Desaster Sicherung und Wiederherstellung
http://www.microsoft.com/technet/technetmag/issues/2007/07/Exchange/default.aspx?loc=de - http://www.microsoft.com/windows2000/techinfo/planning/server/clustersteps.asp
- EX55 Clustering http://www.microsoft.com/exchange/en/55/help/documents/clustering/xclcl001.htm?id=913
- http://www.microsoft.com/germany/ms/technetdatenbank/overview.asp?siteid=600241
- NLB: www.microsoft.com/windows2000/techinfo/howitworks/cluster/nlb.asp
- “Partitioned” Cluster Networks
http://blogs.technet.com/b/askcore/archive/2011/08/08/partitioned-cluster-networks.aspx - 142865 Microsoft Support Policy on Hardware Not on Windows HCL Datacenter Server Product
- Q168801 How to turn on cluster logging in Microsoft Cluster Server
- 178311 XADM: Error Running ISINTEG on a Cluster Server
- 248635 XADM: Recommended Installation Ordner für Windows NT, Exchange Server, Cluster Service, and Service Packs
- 224967 How to Create File Shares on a Cluster
- 251123 Maximum Number of Storage Groups in Exchange 2000 für Database Capacity Planning
- 258750 Recommended Private 'Heartbeat' Configuration on a Cluster Server
- 259197 XGEN: Status of Exchange 2000 Server Components on Cluster Server Was ist Active/Passiv und was Active/active und was "not supportet"
- 259267 Microsoft Cluster Service Installation Resources
- 265173 The Datacenter Program and Windows 2000
- 271651 XADM: How to Add a Node to an Exchange 2000 Cluster
- 277908 XWEB: How to Enable the Change Password Option in Exchange 2000 OWA Clustering
- 280743 Windows Clustering and Geographically Separate Sites
- 281290 XADM: How to upgrade an Exchange Server 5.5 Cluster to an Exchange 2000 Cluster
- 281662 Windows 2000, Windows Server 2003, and Windows Server 2008 cluster nodes as domain controllers
- 284838 How to Create a Server Cluster File Share with Cluster.exe
- 285137 XADM: "C0072030" Error Message Occurs When You Create a System Attendant Resource on a Cluster Server
- 295925 XADM: How to Install Exchange 2000 SP1 on a Cluster Server
- 303949 HOW TO: Restore an Information Store Database in a Clustered Exchange Environment
- 304415 Support für Multiple Clusters Attached to the Same SAN Device
- 309395 The Microsoft Support Policy für Server Clusters and the HCL
- 323016 XADM: Setup with DisasterRecovery Does Not Work on a Clustered Exchange 2000 Server
- 324318 HOW TO: Migrate from Exchange Server 5.5 to Exchange 2000 by using the In-Place upgrade Method
- Q810860 XGEN: Architecture of the Exchange Resource Dynamic Link Library (Exres.dll)
- 810986 XADM: Microsoft Support Policy für Exchange Server Installed on Cluster Nodes. Cluster und DC verboten nicht, aber nicht supported.
- Q821833 Exchange Cluster Resource Dependencies in Exchange Server 2003
- 837852 Windows Clustering is not supported on front-end servers in Exchange Server 2003
- 834637 The "Enable Forms Based Authentication" check box is unavailable in Exchange Server 2003
- 895847 Multi-site data replication support für Exchange 2003 and Exchange 2000
- 899382 You may receive an error message when you try to run the Exchange Management Pack Configuration Wizard in a Microsoft Exchange Server 2003 clustered environment
- Microsoft Cluster Technical Library
http://www.microsoft.com/windows2000/library/technologies/cluster/default.asp - Exchange Server 2003 Clustering Quality Assurance Checklist
http://www.microsoft.com/downloads/details.aspx?FamilyId=0E9B809D-2A7A-4ADF-9FDE-897210A461DB&displaylang=en - Windows 2000 Datacenter Informationsseite
http://www.microsoft.com/windows2000/guide/datacenter/overview/default.asp - E2K Clustering
http://msdn.Microsoft.com/library/en-us/dnmes2k/html/clustering.asp - http://www.microsoft.com/windows2000/guide/server/features/clustering.asp
-
http://www.microsoft.com/exchange/techinfo/deployment/2000/XchSP2CL.doc
Exchange 2000 Service Pack 2 Clustering Guide (Updated !!!) - http://technet.Microsoft.com/en-us/library/2ab0f608-5c19-43cb-bf7a-7240a2e5ef88.aspx
-
www.microsoft.com/hcl
Hardware Compatibility List - Exchange 2000 Operations Guide http://www.microsoft.com/technet/prodtechnol/exchange/maintain/operate/opsguide/e2kopall.exe
- Exchange 2000 SP1 Cluster White Paper http://www.microsoft.com/exchange/techinfo/deployment/2000/ClustersSP1.doc
- Deploying Microsoft Exchange 2000 Server Clusters Whitepaper (PDF)
http://download.Microsoft.com/download/exchplatinumbeta/e2kclust/1.0/WIN98MeXP/EN-US/e2kcluster_pdf.exe - Cluster geografisch verteilen http://www.microsoft.com/windows.netserver/techinfo/overview/clustergeo.mspx
- Technical Overview of Clustering Services http://www.microsoft.com/windows.netserver/techinfo/overview/clustering.mspx
- What’s New in Clustering Technologies http://www.microsoft.com/windows.netserver/evaluation/overview/technologies/clustering.mspx
- Clustering Technologies
http://www.microsoft.com/windows2000/technologies/clustering/default.asp - Technet: Technische Übersicht über die Cluster-Technologien http://www.microsoft.com/germany/technet/datenbank/articles/600103.mspx
-
www.microsoft.com/backstage
Informationen wie Microsoft ihre Webseite betreibt. Viele Webserver als Frontendsysteme, redundant mit Windows Load Balancing Services (Convoi) und dahinter SQL-Server als Cluster um die Inhalte zu liefern. Weitere SQL-Cluster für Zugriffsprotokolle. - WebCast zu Cluster
http://download.Microsoft.com/download/0/5/f/05fd8f6e-35c8-425f-ba9d-6941b4b60850/wc090903-offline.exe (15 MB)
http://download.Microsoft.com/download/7/6/3/76321006-30f1-46ed-bd33-20f530b3763f/WC090903.exe (PPT)
http://support.Microsoft.com/servicedesks/webcasts/en/transcripts/wct090903.asp Transcript - Blogcast: Virtual Server 2005 R2 Host Clustering How To
 http://blogs.technet.com/jhoward/archive/2005/12/02/415459.aspx
http://blogs.technet.com/jhoward/archive/2005/12/02/415459.aspx
Insgesamt 5 Teile mit Videos - Cluster in VM
http://www.microsoft.com/austria/technet/articles/hostclustering.mspx - MVP Seite zu Cluster
http://www.nwnetworks.com/cluster.html -
www.windowsclusters.org
Informationsseite zu Cluster. - HP best practices für Microsoft Exchange Server 2000 and 2003 cluster
deployments
http://h71028.www7.hp.com/enterprise/cache/70586-0-0-225-121.aspx?jumpid=reg_R1002_USEN
Direkter Link zum PDF http://h71028.www7.hp.com/ActiveAnswers/downloads/73843.pdf - Implementing a Two Node Cluster with Windows 2003 Enterprise
http://www.msexchange.org/tutorials/Implementing-Two-Node-Cluster-Windows-2003-Enterprise.html - Just say NO to A/A
http://www.msexchange.org/tutorials/NO-Active-Active-Cluster.html - Cluster Core Resources fail to come online on some Exchange 2010 Database
Availability Group (DAG) nodes.
http://blogs.technet.com/timmcmic/archive/2010/05/12/cluster-core-resources-fail-to-come-online-on-some-exchange-2010-database-availability-group-dag-nodes.aspx














