
DAG-Replication
Jeder Administrator einer Exchange Server DAG weiß, dass die Server untereinander zur Replikation der Datenbanken natürlich Daten über die Netzwerke schaufeln müssen. Aber die wenigsten Überwachen dieses Belastung obwohl diese Zahl ein guter Indikator für Probleme und Auslastung sein kann. Diese Seite beschreibt die Performance-Counter und wie Sie die Werte nutzen.
Was wird wie repliziert ?
Ehe wir aber in die "Zahlen" gehen, hier noch mal die Informationen, welche Datenmengen denn überhaupt auflaufen
- Datenreplikation per TCP
oder Log Shipping
Exchange 2010 Server in einer DAG replizieren von dem Server mit der aktiven Datenbank die Informationen über einen TCP Kanal zu den passiven Servern. Nur wenn dieser Kanal bestimmte Performancewerte unterschreitet, stellen Sie auf das alte Verfahren "Kopieren der Transaktionsprotokolle" über SMB um. Beide Verfahren benötigen die meiste Bandbreite im laufenden Betrieb - CI Replikation
Damit der passive Knoten, auf dem die Datenbank ja nicht gemountet ist, auch einen aktuellen Content Index hat, wird auch diese Datenbank mit repliziert - Seeding
Nicht vergessen werden darf die initiale Replikation einer Datenbank beim der Einrichtung. Dies kann aber auch "offline" erfolgen, d.h. wenn ein passiver Server weiter entfernt ist, dann kann die Datenbank auf dem aktiven Server kopiert (per Backup/VSS) und dann im Ziel bereit gestellt werden.
Das ist insbesondere interessant, wenn ein Server samt Daten oder das Datacenter ausgefallen ist und viele Datenbanken neu aufzubauen sind.
Die vier Datenbereiche werden seit Exchange 2010 SP1 als TCP-Connection repliziert, bei der der Quellserver die Daten direkt zum Store des Zielsystems als PageÄnderungen der Datenbank sendet. Das ist deutlich schneller als Logfiles zu schreiben und nach Abschluss von 1 MB dieses wieder zu lesen, zu kopieren und im Ziel wieder zu schreiben und zu lesen. So schreibt nur der Quellserver und der Zielserver aber Logfiles müssen nicht mehr gelesen werden und die passive Kopie ist viel aktueller-
Wenn die Verbindung aber zu "wackelig" ist, dann schaltet Exchange wieder auf den Blockmode zurück. Denn allzu viele TCP-Pakete dürfen nicht verloren gehen und die Queue kann nicht endlos groß werden. Dies zeigt sich auch in unterschiedlichen Transactionlogs.
Welches Netzwerk war das noch mal ?
Ein gut aufgebauter Cluster ist zumindest über zwei Subnetze miteinander verbunden. Einmal das Netzwerk über das auch die Anfragen der Clients ankommen aber es gibt immer noch ein zweites oder mehr Netzwerke, für die interne Kommunikation. Zumindest für den "Heartbeat" sollten sie immer ein eigenes Netzwerk vorsehen, so dass selbst eine Überlastsituation auf dem Client-LAN (z.B. Netzwerkflooding) die Cluster weiter ungestört miteinander kommunizieren können. Das gilt natürlich auch und gerade beim Einsatz über WAN-Verbindungen. Nun werden die wenigsten Firmen hier eigene WAN-Links für einen DAG-Heartbeat bereit stellen. Aber dann sollte man auf jeden Fall die Netzwerke in VLANs auftrennen und mit QoS eine garantierte Mindestbandbreite für den Cluster bereit stellen.
Exchange versucht die Replikation per Default nicht über das Client-LAN durchzuführen, sondern nutzt bevorzugt das Replikationsnetzwerk. Dies ist aber einstellbar, welches Netzwerk Exchange nutzt.
# Wenn Sie ein Replication LAN haben, sollten die diese aktivieren Set-DatabaseAvailabilityGroupNetwork ` -Identity "\ReplicationLAN" ` -ReplicationEnabled:$True # Auf dem Client-LAN will man nicht unbedingt den Replikationstraffic Set-DatabaseAvailabilityGroupNetwork ` -Identity "\ClientLAN" ` -ReplicationEnabled:$false # und schon gar nicht auf dem Netzwerk zum iSCSI Storage oder Backup. Set-DatabaseAvailabilityGroupNetwork ` -Identity "\iSCSILan" ` -ReplicationEnabled:$false ` -IgnoreNetwork:$true
Sie sollten aber abwägen, ob das Client-Netzwerk nicht auch zur Replikation genutzt werden darf. Stellen Sie sich vor, dass ReplikationsLAN ist unterbrochen und niemand bemerkt es. Dann ist es schon besser, wenn Exchange auf einen anderen Link schwenkt.
- Planning für High
Availability and Site Resilience
- Network requirements
http://technet.microsoft.com/en-us/library/dd638104.aspx#NR - Set-DatabaseAvailabilityGroupNetwork
Exchange 2013: http://technet.microsoft.com/de-de/library/dd298008(v=exchg.150).aspx
Exchange 2010: http://technet.microsoft.com/de-de/library/dd298008(v=exchg.141).aspx - Exchange 2010: Collapsing
DAG Networks
http://blogs.technet.com/b/timmcmic/archive/2011/09/26/exchange-2010-collapsing-dag-networks.aspx - Configuring DAG Networks in
Exchange 2010
http://blog.gothamtg.com/2012/09/26/configuring-dag-networks/ - Exchange 2010 databases
replicating over wrong network
http://sparesomeexchange.com/exchange-2010-databases-replicating-over-wrong-network/
Performance Counter
Das Hauptthema dieser Seite ist aber die DAG-Replikation und die Bandbreite. vielleicht haben Sie bereits eine DAG laufen und überlegen einen weiteres DAG-Mitglied zu installieren, welches aber nun etwas weiter entfernt steht. Da wäre es doch sehr interessant die aktuelle Replikationslast zu sehen. Das ist zumindest eine ergänzende Information zum Exchange Sizer, der solche Werte auch anhand der Benutzerprofile ermittelt.
Aber auch wenn Sie nichts Derartiges planen, sind die Counter durchaus interessant. Zwei Counterbereiche sind hier sehr interessant:
- MSExchange Replica Seeder
Diese Gruppe enthält die Daten für den Neuaufbau einer Datenbank auf der anderen Seite. Das ist in der Regel eine Spitzenlast, die nur nach einem Datenverlust auf einem Server auftritt. Sie ist für das Monitoring interessant aber sie können genauso gut die Größe der Datenbank ermitteln. Die Zahlen helfen aber vielleicht beim Hochrechnen, wie lange es noch dauern könnte.
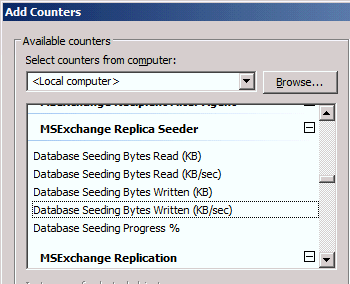
Die Counter gibt es pro Instanz, die gerade "geseeded" wird. - MSExchange Replication
Dieser Bereich ist deutlich interessanter, da er die aktuellen aktiven Replikationen enthält. Und die hat eigentlich immer was zu tun.
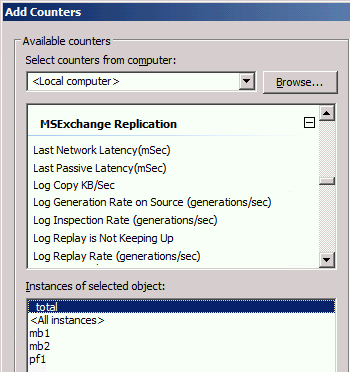
Hier erscheinen auf dem Server alle Datenbanken, die auf dem Server vorliegen. Die Counter für die Regelreplikation können pro Datenbank und als Summe ausgelesen werden. für die Abschätzung der Bandbreite reicht natürlich die Summe. Ein Aufschlüsseln pro Datenbank ist aber ein guter Indikator für "ungleich" verteilte Datenbanken.
Interessant ist hier die Ansicht auf einem Server mit mehreren Datenbanken. Hier gefiltert auf zwei Datenbanken, von denen eine Aktiv und eine Passiv ist.
Neben der Menge an Countern ist auch gut zu sehen, dass nur der passive Server hier Werte verzeichnet. Auf der aktiven Version sind die Daten fast alle 0.
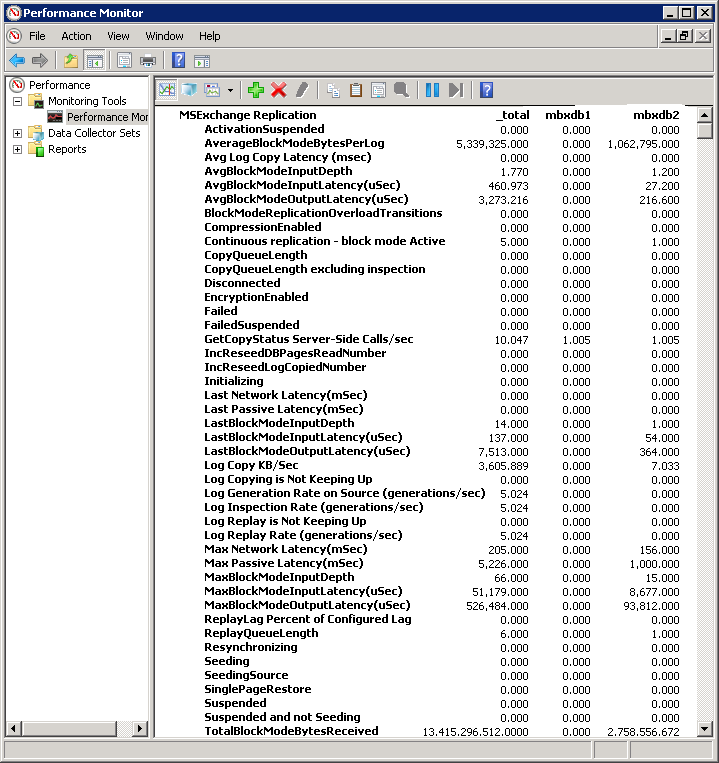
Interessant sind hierbei sicher der Counter "Log Copy KB/Sek" und als Überwachung die Latenzzeiten. Einige Counter wie z.B. initializing, Seeding, Failed, Suspended können nur den Wert 1 oder 0 annehmen.
Bedeutung der Counter bei "MSExchange Replication"
| Counter | Bedeutung |
|---|---|
Last Network Latency(mSec) |
The last measured network latency (in Milliseconds) |
Last Passive Latency(mSec) |
The last measured latency (in milliseconds) of this copy, relative to the active copy. This value is valid only when running in continuous replication - block mode. |
Log Copy KB/Sek |
Number of KB of log copied per second. |
Continuous replication - block mode Active |
BlockMode is set to 1 when running in continuous replication - block mode. BlockMode is set to 0 when running in continuous replication - file mode. |
Log Generation Rate on Source (generations/Sec) |
The log copier's view of new logs generated on the source per second. |
Max Network Latency(msec) |
The maximum measured network latency (in milliseconds). |
Max Passive Network Latency(msec) |
The maximum measured latency (in milliseconds) of this copy relative to the active copy. This value is only valid when running in continuous replication - block mode. |
Auslesen
Performance Counter können mit nahezu jeder ordentlichen Windows Monitoring-Lösung ausgelesen und visualisiert werden. Ich habe mir dennoch eine PowerShell gebaut, die von PRTG genutzt werden kann, um die Daten z.B. alle 5 Minuten zu erfassen aber alle Datenbank in einem Diagramm erfasst. Standardmäßig erfasst PRTG Daten immer pro Sensor und der eingebaute Performance Counter kann so nicht alle Server einer DAG in einem Bild zusammenfassen.
Eine PowerShell erlaubt aber schnell das Auslesen der Werte und dann sind es nur noch ein paar Codezeilen um eine nette Tabelle zu erhalten oder Daten für PRTG aufzubereiten:
(get-counter "\MSExchange Replication(*)\log copy kb/sec").countersamples | ft -AutoSize Path InstanceName CookedValue ---- ------------ ----------- \\w2k8r2e2010\msexchange replication(mb2)\log copy kb/sec mb2 0 \\w2k8r2e2010\msexchange replication(pf1)\log copy kb/sec pf1 0 \\w2k8r2e2010\msexchange replication(mb1)\log copy kb/sec mb1 0 \\w2k8r2e2010\msexchange replication(_total)\log copy kb/sec _total 0
Bei einer größeren Umgebung kann man das mit PRTG und einem passenden PowerShell-Skript auswerten.
Das Skript ist aktuell
kein öffentlicher Download. Schreiben Sie mir
einfach eine Mail von ihrem Firmenaccount, wenn
Sie es haben möchten.
Informationen, warum diese Skripte nicht öffentlich sind, finden Sie auf
nicht public.
Hier am Beispiel eines Exchange DAG-Servers mit 4 Knoten und ca. 45 Datenbanken. Ich habe hier aber nur die vier "_Total"-Werte angezeigt.
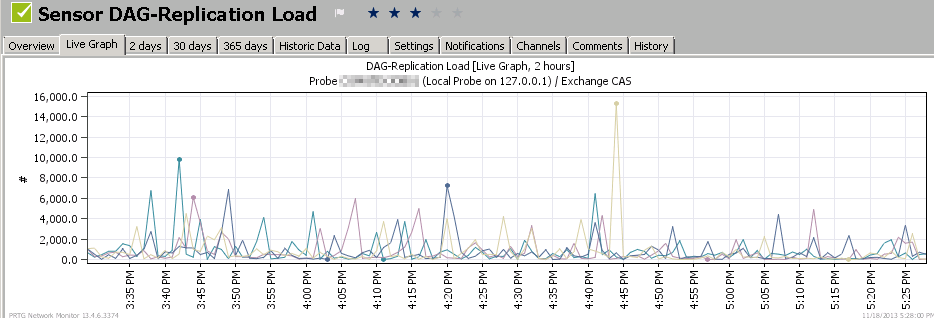
Die Einheit links zeigt Kilobyte wobei der "Punkt" das Dezimalzeichen ist. Meist sind alle vier Server also unterhalb 2MByte/Server/Sek, replizieren also ca. 8 Megabyte/Sek. Aber es gibt auch Peaks bis zu 10MByte/Sek oder sogar fast 16MByte/Sek. Die Messungen im Abstand von einer Minute sind immer nur Momentaufnahmen. Es kann also noch viel mehr und höhere Ausschläge geben. Sie sollten die Messungen also längere Zeit ausführen.
Sie können natürlich einen Alarm generieren lassen, wenn das Datenvolumen überhöht oder auch unterschritten ist. für Alarme sind aber andere Counter oder Eventlogs interessanter über die Exchange selbst einen Fehler anzeigt. Die Daten sind interessant für eine Überwachung oder Erfassung der Bandbreite z.B. wenn Server weiter entfernt stehen. Hierzu sind auch die folgenden Counter interessanter.

Neben der Durchschnittswerte (avg) pro Datenbank über die Laufzeit des Servers sind hier natürlich die "Max"-Werte interessant. Gerade wenn Sie Exchange Server etwas "entfernt" voneinander aufstellen. Leider kann man den "Max"-Wert nur durch einen Schwenk der Datenbank "zurückstellen".














