
Exchange 2007 - CCR Failover
Diese Seite beschreibt meine eigenen Erfahrungen und Eindrücke einer Exchange 2007 Funktion, die ich aber mangels Source-Code nicht 100% sicherstellen kann. Es kann also sein, dass hier einige Fehler enthalten sind. Feedback ist gerne willkommen. Kontakt
White Paper: Continuous Replication Deep Dive (released
erst Jun 2008)
http://technet.Microsoft.com/en-us/library/cc535020(EXCHG.80).aspx
Erschreckenderweise scheinen immer mehr Firmen einen Exchange 2007 CCR zu installieren, ohne sich genauer mit der Thematik beschäftigt zu haben. Ich mache das an Supportcalls und Fragen in Newsgroups fest, die erst dann kommen, wenn das Kind sprichwörtlich schon in den Brunnen gefallen ist.
Unterstützung durch
Net at
Work:
Diese Seite versucht die Hintergründe eines CCR zu beschreiben. Sie ist
keine How-To Anleitung, sondern soll ihnen die Komplexität verdeutlichen.
Wir helfen ihnen gerne bei der Planung, Umsetzung und Pflege ihres CCR
Clusters.
CCR Ziele und Warnungen
In aller Kürze möchte ich der noch einmal ein paar Fakten dazu aufführen:
- Ein ungeplanter CCR Failover verliert Daten
Auch wenn der Transport Dumpster dies reduziert bleibt ein kleiner Rest - Ein geplanter Shutdown des Betriebssystem ist kein geplanter Clusterschwenk !
ACHTUNG: Nutzen Sie immer die Exchange Commandlets um
einen Cluster zu schwenken
Damit sind sie sicher, dass der passive Knoten auch die Funktion übernommen
hat, ehe Sie den vormals aktiven Knoten herunter fahren
Fahren Sie nie den aktiven Knoten mit einem "Shutdown"
herunter
Ansonsten beenden sich zwar noch die Exchange Dienste "sauber" aber der
Serverdienst wird dann auch sehr schnell beendet. Der passive Knoten hat
nicht mehr die Zeit alle beim Beenden der Speichergruppen geschriebenen
Transaktionsprotokolle zu kopieren und fährt nicht mehr hoch.
- CCR ist günstiger als SCR aber keine "einfache" Lösung
Auch wenn ein CCR keine Hardware der Cluster-HCL und auch kein SAN braucht, so gilt auch hier weiterhin, dass zu jedem CCR auch mindestens zwei weitere ungeclusterte Server gehören. - Keine Public Folder auf CCR
Der Betrieb von öffentlichen Ordnern auf einem CCR ist nicht anzuraten, da beim Failover, bei dem Logfiles auf dem passiven Knoten fehlen, diese Datenbank nicht mehr "online" geht und eine Replikation mit anderen Servern der gleichen Organisation (noch) nicht möglich ist. - Ignorieren Sie nie das "Seeding"
CCR erlaubt sehr einfach die Verteilung von Servern auf zwei Standorte. Vergessen Sie aber nie dabei, dass bei einem einzigen ungeplanten Failover die Datenbank neu kopiert wird. Und hier muss der Administrator dann auch noch manuell den Prozess anstoßen. Gigabytes über WAN transferieren ist auf jeden Fall mehr als die Transaktionsprotokolle des Tages, zumal die Anwender auch noch auf der falschen Seite sitzen. - Falsche LAN/WAN Struktur
Es hilft nichts, wenn Sie zwei CCR-Knoten in zwei RZs platzieren um den Ausfall eines RZs zu überbrücken, wenn die Clients nicht auch doppelt angeschlossen sind. - CCR ist nichts ohne Monitoring und Schulung
Wenn Sie einen Cluster installieren und keine Überwachung der Dienste bereit stellen können, dann sparen Sie das Geld. Sie werden nicht die erhoffte Verfügbarkeit erreichen. Das gilt auch für die Schulung der Administratoren. Wer einen Cluster betreut sollte als Zertifikat einen MCSA für Windows und den Test für Cluster bestanden haben. - Transport Dumpster
Dies ist eine schöne Einrichtung aber für viele Firmen dürfte der Buffer viel zu gering sein. Hier müssen Sie die passenden Einstellungen tätigen.
Wenn Sie nun immer noch glauben, dass CCR für Sie die richtige Lösung ist, dann schauen Sie sich die folgenden Ausführungen an. Sie sollten das alles schon vorher gewusst haben und dies nur als "Auffrischung" verstehen. Zudem ist dies natürlich nur eine Teilmenge dessen, was ein Administrator mit Cluster wissen sollte.
CCR Planung
Wenn Sie CCR nur als Paarung von zwei Servern zur besseren Verfügbarkeit von Exchange 2007 ansehen, dann haben Sie ihre Hausaufgaben noch nicht gemacht. Die Exchange Verfügbarkeit misst sich beim Client. Ich habe ihnen hier mal eine mögliche Konfiguration aufgezeichnet.

Wichtig ist, dass für ein echtes automatisches Failover wirklich alle Komponenten doppelt und unabhängig voneinander vorhanden sind. Dazu zählen nicht nur die beiden Clusterknoten, sondern auch die Domain Controller, DNS, WINS, NTP und andere Infrastrukturdienste. Auch die Hub/Transport und Client Access-Rollen müssen zum einen auf nicht geclusterten Servern und dann auch doppelt vorgehalten werden. Wird ein echter "Shared Nothing"-Cluster installiert, muss der File Share Witness so platziert werden, dass er keine gemeinsamen Komponenten mit den Clusterknoten nutzt. Er muss auch den Ausfall eines kompletten Datacenters so überleben, dass der verbliebene Knoten eine Verbindung herstellen kann. Häufig vergessen werden die Clients. Auch diese müssen mit beiden Knoten derart angebunden werden, dass der Ausfall eines Datacenters keine Folgen für die Kommunikation mit dem anderen Datacenter hat.
Damit sie überprüfen können, ob Sie alle Ausführungen "verstanden" haben, sehen Sie hier eine CCR Planung , die mindestens 4 Fehler enthält:

Die Fehler sind im einzelnen:
- Kein HT/CAS im Datacenter2
Fällte das Datacenter 1 komplett aus, dann können keine Mails mehr zugestellt werden. - Kein AutoFailover da FSW nicht abgetrennt
Der File Share Witness ist nicht in einem autarken Segment. Viele Anleitungen beschreiben, dass man den doch einfach auf einem Hub/Transport oder CAS-Server mitlaufen lassen sollte. Sollte nun aber das Datacenter 1 komplett offline sein, dann kann der Node in Datacenter 2 zumindest nicht automatisch hochfahren. - Keine Client-Datacenter 2 Netzkopplung
Häufiger Fehler ist, dass die PCs der Anwender über Switches an ein Datacenter angeschlossen werden. Auch wenn das redundant erfolgt, haben die wenigsten Firmen auch eine unabhängige Anbindung des Client-LANs über das WAN an die Infrastruktur im Datacenter 2. Die Clients erreichen die Server in Datacenter 2 nur "durch" das Datacenter 1 hindurch. Bei einem Ausfall können Outlook und Exchange nicht miteinander kommunizieren. - Geroutetes WAN
WAN Verbindungen werden fast immer über "Router" gelenkt. Damit haben die Netzwerksegmente im Datacenter 1 und Datacenter 2 unterschiedliche IP-Adressen. Dies ist mit einem Microsoft Cluster aktuell noch nicht möglich.
Spitzfindige Leser können mir nun gerne schreiben, dass ich hier noch die redundante Datensicherung, die Internetanbindung etc. vergessen habe. Hochverfügbarkeit mit Exchange ist ein weites Feld und auch wenn die Exchange 2007 Online Hilfe die Installation sehr einfach beschreibt und die Installation sogar per grafischem Assistenten wirklich Jedem gelingen sollte, ist CRR mehr als nur das Ausführen verschiedener Setups.
CCR Failover
Im folgenden beschreibe ich drei von vielen möglichen Ausfällen, um die Funktionsweise des CCR und der Failover-Funktion zu beschreiben.
Auf dem Exchange Team Blog finden Sie Flussdiagramme,
wann CCR welche Aktion durchführt.
http://msexchangeteam.com/files/12/attachments/entry447215.aspx
Geplanter Failover
Diese Situation ist hoffentlich die häufigste umschaltung von einem Knoten auf einen anderen Knoten. Dies trifft z.B. bei der Installation von Hotfixes und SicherheitsUpdates zu. Der passive Knoten wird "gefixt" und danach durch einen geplanten Failover "aktiv" gesetzt. Dann kann der vormals aktive und nun passive Knoten aktualisiert werden. Eventuell schwenken Sie dann wieder die Dienste auf den ersten Knoten zurück.

Durch den geplanten Schwenk werden die Transaktionsprotokolle nach dem Shutdown des aktiven Knotens auf den passiven Knoten kopiert und dann erst gestartet. Dies funktioniert, weil zwar Exchange noch down ist, aber die Dateifreigaben weiterhin erhalten bleiben. Der Transport Dumpster kommt nicht zum Einsatz
Replikationsausfall
Ein anderer häufiger Fall ist eine Unterbrechung der Replikation. Wenn Sie z.B.: den passiven Knoten nach einem Update herunterfahren, dann werden die Protokolldateien erst einmal nicht weiter repliziert.

Startet der Server dann wieder, dann werden auch hier wieder zuerst die Transaktionsprotokolle kopiert. Übrigens berücksichtigt Exchange diesen Fall auch bei der Datensicherung. Wenn Sie in dieser Phase ein Streamingbackup des aktiven Knotens machen, dann werden nur die Transaktionsprotokolle entfernt, die schon auf dem passiven Knoten sind. Lassen Sie den passiven Knoten also nicht allzu lange "offline" und überwachen Sie die Partition mit den Transaktionsprotokollen.
Ungeplanter Failover
Fällt ein aktiver Clusterknoten ungeplant aus, dann bedeutet dies für den passiven Knoten, dass er zumindest nicht mehr das aktuelle Transaktionsprotokoll mehr hat. Ist der passive Knoten nicht schnell, dann können sogar mehrere Transaktionsprotokolle á 1 Megabyte fehlen.

Mails während der Ausfallzeit bleiben auf dem Transport Server in der Warteschlange liegen. Der passive Knoten versucht dann seine Kopie der Datenbank zu starten. Allerdings fehlen natürlich die letzten Nachrichten. Nun kommt der Transport Dumpster zum Einsatz. Exchange fordert die letzten Nachrichten einfach noch einmal an.
Elemente, die aber in letzter Zeit direkt verändert, angelegt oder gelöscht wurden, z.B.: Termine, Kontakte, Aufgaben etc. Und nicht über den Hub/Transport übertragen wurden, sind jedoch nicht mehr vorhanden.
Wird nun der ausgefallene Server wieder aktiviert, dann "versucht" Exchange diesen wieder in die Replikation einzubinden. In den meisten Fällen funktioniert dies sogar, so dass kein komplettes "Seeding" der Datenbank erforderlich wird. Dies würde ja eine Kopieraktion von mehreren Gigabyte zum zweiten Knoten (auch über WAN) bedeuten.
CCR Recovery
Daher hat Microsoft bei Exchange 2007 CCR ziemlich viel Grips investiert, um die Erfordernis einer kompletten Datenbankkopie zu reduzieren. Dies ist eigentlich nur erforderlich, wenn die Datenbank auf dem passiven Knoten nicht mehr vorhanden (Neuinstallation, Festplattenverlust) ist.
Exchange arbeitet transaktionsorientiert. Eine Änderung wird dazu zuerst im Hauptspeicher durchgeführt und dann in das Transaktionsprotokoll gesichert geschrieben. Die entsprechende Änderung in der Datenbank hingegen erfolgt nicht unbedingt zeitnah. Hier kann Exchange Zugriffe optimieren. Entsprechend groß ist die Wahrscheinlichkeit, dass ihre Änderung noch bis zum Exchange Speicher und vielleicht auch noch in das Transaktionsprotokoll gekommen ist, aber nicht mehr in der Datenbank gelandet ist. Beim CCR hilft das aber nicht, da das letzte Transaktionsprotokoll nicht kopiert wurde. Mit etwas Glück ist die Datenbank auf einem Stand, bei dem sie auch später als passiver Knoten weiter geführt werden kann.

Viel kniffliger ist das Problem, wenn eine Änderung auch noch den Weg bis in die Datenbank geschafft hat, aber das Transaktionsprotokoll noch nicht auf den passiven Knoten übertragen wurde. Findet nun ein ungeplanter Failover statt, dann fehlen diese Informationen auf dem neuen aktiven Knoten aber die Datenbank auf dem vormals aktiven Knoten ist schon verändert. Kommt nun der alte Knoten wieder online, so versucht dieser eine Rückreplikation. Dazu prüft Exchange die Datenbank und schaut, ob eine Replikation von dem aktiven Server zurück überhaupt möglich ist. Das ist in dem Fall nicht mehr möglich. Aber schauen wir uns die Replikation im zeitlichen Verlauf an.

| Schritt | Beschreibung |
|---|---|
|
|
Die Installation des aktiven Knotens auf NODE1 erzeugt eine Datenbank. Die Installation des passiven Knotens NODE2 führt dazu, dass die Datenbank beim ersten mal natürlich auf den passiven Knoten kopiert (Seeding) wird. |
|
|
In der Folge beginnt dann die normale Arbeit und Replikation. Der Node1 ist der aktive Server und generiert für die Änderungen entsprechende Transaktionsprotokolle (1,2,3,4,5,..). Diese werden auf den NODE2 repliziert und dort auch in die Datenbank geschrieben. |
|
|
Die Datenbank des aktiven Knotens folgt den Transaktionsprotokollen mit etwas Verzögerung. In diesem Beispiel wird die Datenbank erst weitergeschrieben, als schon das vierte Transaktionsprotokoll bearbeitet wird. Die "Versionsnummer" der Datenbank soll anzeigen, bis zu welchem Transaktionsprotokoll die Daten bereits gepflegt sind. Es kann also durchaus sein, dass der passive Knoten schon weiter ist als der aktive Knoten. |
|
|
Wird der passive Knoten nun herunter gefahren, dann stoppt natürlich die Replikation. den aktiven Knoten stört dies aber nicht. Ist der passive Knoten wieder online, dann beeilt er sich natürlich, die Transaktionsprotokolldateien der Vergangenheit nachzuziehen. Wir gehen nun davon aus, dass das Transaktionsprotokoll "7" noch den Weg auf den passiven Knoten geschafft hat |
|
|
Hier passiert ein ungeplanter Ausfall. Die Transaktionsprotokolle 8 und 9 sind nicht mehr repliziert worden. Die Datenbank des ausgefallenen Servers ist bis zum Transaktionsprotokoll 4 gekommen. Dennoch muss der passive Knoten nun aktiv werden und startet seine Datenbankkopie. Die Änderungen aus Transaktionsprotokoll 8 und 9 sind verloren bzw. werden teilweise durch den Transport Dumpster nachgeliefert. |
|
|
Der neue aktive Knoten "NODE2" protokolliert nun seinerseits alle Aktivitäten der Benutzer in den Protokolldateien 8b, 9b und folgende. |
|
|
Der ausgefallene Server wurde repariert. Dabei blieben die Festplatteninhalte (vor allem die Datenbank)erhalten. Die Datenbank ist bei einer Version 4 stehen geblieben. Nun beginnt der Server seine Prüfung und stellt fest, dass er seine Datenbank durch die eigenen Transaktionsprotokolle und die Kopien von 8b,9b ff wieder synchron bringen kann. Es findet also kein "Seeding" statt. |
Dass der ausgefallene Cluster kein Seeding benötigt hat im wesentlichen den Grund, dass die Datenbankversion einen Stand vor dem Failover hat. Hätte die Datenbank schon das Transaktionsprotokoll 8 eingespielt, welches nie auf dem passiven Knoten gelandet ist, dann wären beide Datenbanken auseinander gelaufen. Der NODE hätte dann nicht mehr anhand der Transaktionsprotokolle von NODE2 einen konsistenten Stand erreichen können. Stellen Sie sich zwei Autos vor, von denen eines falsch abbiegt und nicht mehr zurück fahren kann.
CCR Details (LLR, AutoDatabaseMountDial und ForceDatabaseMountAfter
Wie sie jetzt wissen ist der umgang mit den Transaktionsprotokollen ein wichtiger Punkt beim Betrieb eines CCR-Clusters. Bei einem ungeplanten Failover gehen auf jeden Fall Transaktionsprotokolle verloren. Dies kann durch mehrere Einstellungen gesteuert werden.
Exchange 2007 reduziert selbst das Verlustrisiko, indem Transaktionsprotokolle immer mal wieder abgeschlossen werden, auch wenn in der Zeit nichts passiert ist. Das Transaktionsprotokoll enthält dann leere Bereiche aber dies erlaubt dem passiven Knoten auch die Teilmenge schon zu replizieren und zu übertragen. Drei Stufen sind hierbei konfigurierbar
| Konfiguration | Logintervall | AutoMount |
|---|---|---|
Standard Server |
96 (900Sek) |
<=0 |
CCR mit Good Availability |
384 (225 Sek) |
<=2 |
CCR mit Best Availability (Default) |
675 (128Sek) |
<=5 |
Das bedeutet aber auch, dass bei "Best Availability" pro Tag mindestens 675 Megabyte Transaktionsprotokolle entstehen die auch auf den passiven Knoten repliziert werden, auch wenn keine Daten umgeschlagen werden.
Die gleiche Einstellung steuert auch beim Failover, bis wann Exchange die Datenbank automatisch mounted. In der Einstellung "Lossless" wartet der passive Knoten immer bis alle Transaktionsprotokolle kopiert wurden. Damit ist sichergestellt, dass keinerlei Daten verloren gehen. Dies hilft beim CCR aber nur dann wenn der Exchange Dienst auf dem aktiven Knoten ausgefallen ist, aber die Transaktionsprotokolle weiterhin per SMB kopiert werden können.
Standardeinstellung ist aber "Best Availability", d.h. bis zu 5 Transaktionsprotokolle (also 5 MB Daten) können vergessen werden. Damit bei dieser Einstellung aber der Verlust nicht ganz so groß ist, wird hier dann alle 2 Minuten ein neues Transaktionsprotokoll gestartet, so dass auf einem Server mit wenig Last eine Änderung nach wenigen Minuten vom passiven Knoten bezogen werden kann.
Diese Einstellung erfolgt über den Parameter "AutoDatabaseMountDial"
Set-MailboxServer <CMSName> -AutoDatabaseMountDial:<Value>
Gültiger Wert ist: Lossless, GoodAvailability, BestAvailability
Ein zweiter Parameter steuert, wie lange der Cluster wartet bis die Datenbank automatisch gemountet wird. Der passive Knoten versucht immer och vom früheren aktiven Knoten die Transaktionsprotokolle zu beziehen aber dieser Parameter begrenzt dies in der Zeit.
Set-MailboxServer <CMSName> -ForceDatabaseMountAfter:<Value>
Gültige Werte: Datum/Zeit (2h ist dann "2:00:00") oder "unlimited"
Nach dieser Zeit wird also die Datenbank "immer" gemountet, auch wenn mehr Protokolldateien fehlen sollten.
Best Practice
Die Standardeinstellungen von Exchange 2007 sind "BestAvailability" und "unlimited",
d.h. der Ausfall bis zu fünf kompletten (und einem angefangenen)
Transaktionsprotokoll wird toleriert aber wenn
mehr Daten fehlen, dann müssen Sie als Administrator Hand anlegen und den
passiven Knoten selbst aktiv schalten oder die fehlenden
Transaktionsprotokolle von den Festplatten des ausgefallenen Knotens
extrahieren.
Diese Einstellungen sind aus meiner Sicht sinnvoll. Überwachen Sie am besten
wie weit der passive Knoten hinter ihrem aktiven Knoten hinterherläuft
Übrigens installiert CCR die Clustergruppe derart, dass nur ein Failover pro Stunde erlaubt ist. Bei Exchange 2003 waren die Werte noch 10 Failovers in 6 Stunden. Dies kommt auch meiner Empfehlung nahe, da ich auch schon immer predige, dass ein Cluster vielleicht ein oder zweimal umfallen darf, aber spätestens dann das System verharren soll, so dass ein Administrator auch eine Fehlersuche durchführen kann. Es ist nicht nur störend, wenn ein Exchange Cluster dauernd schwenkt und einem dadurch die Hände gebunden sind. für eine TestUmgebung ist diese Einstellung natürlich erst einmal störend, denn hier werden Sie sicher häufiger einen "Failover" benötigen.
CCR Reseeding, wann passiert es ?
Die Funktion des ReSeedings ist in folgenden Fällen erforderlich
- Erstinstallation und Recovery-Installation
Bei der ersten Installation wird natürlich die leere Datenbank das erste mal kopiert. Wird ein ausgefallener Knoten über "setup /RecoverCMS" wieder hergestellt, dann entspricht die auch einer Neuinstallation - Datenbank fehlt
Wenn der passive Knoten die Datenbank nicht mehr findet (Datei weg) aber der Pfad als solches noch da ist, dann startet der Cluster selbständig ein neues Reseeding. - Divergenz
Stellt der Replication Service fest, dass die Datenbank auf dem passiven Knoten nicht mit der aktiven Seite übereinstimmt (Generation), dann kann die Fortschreibung mit den replizierten Logs nicht stattfinden. Dies kann auch passieren, Wenn ein Admin z.B.: mit "ESEUTIL /R" eine Datenbank "repariert" hat. In diesem Fall muss der Administrator selbst ein "Reseeding" durchführen (Update-StorageGroupCopy)
Da ein Seeding einer vollen Datenbank faktisch eine Kopie der kompletten Datenbank bedeutet, ist dieser Fall besonders "teuer", wenn eine WAN-Verbindung dazwischen liegt. Ein ReSeeding können Sie z.B. nachstellen, indem Sie den Microsoft Exchange Replication Service auf dem passiven Knoten stoppen, dann die EDB und LOG-Dateien löschen und dann den Service wieder starten.
Technisch ist das ReSeeding einfach ein "StreamingBackup" des aktiven Knoten. Der passive Knoten kopiert die Datenbank, indem er sie über die StreamingAPI vom aktiven Knoten kopiert, wie dies auch beim Streamingbackup erfolgt, nur dass es ein "COPY" ist, d.h. die Transaktionsprotokolle natürlich danach nicht gelöscht werden.
Achtung Remote Streaming Copy und SP1
Aus "Sicherheitsgründen" erlaubt die API seit SP1 kein Kopieren mehr über
das LAN und stört damit auch das Reseeding. Also müssen Sie auf den CCR
diesen Default wieder ändern
Exchange 2007 - using Backup to Back up and Restore Exchange Data
http://technet.Microsoft.com/en-us/library/aa998870.aspx
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\MSExchangeIS\ParametersSystem
Name: Enable Remote Streaming Backup
Type: DWORD
Value: 0 = default behavior (remote backup disabled); 1 = remote backup
enabled
CCR Dienste
Wenn Sie sich im Cluster Administrator die Exchange Gruppe anschauen, dann erkennen Sie, dass ein CCR in der Clusterverwaltung nur folgende Dienste anzeigt:
- IP-Adresse
- Netzwerkname
- Microsoft Exchange System Attendant
- Microsoft Exchange Store
- Speichergruppe 1..n
Die vom Exchange 2000/2003 bekannten Dienste wie SMTP, MTA, HTTP etc. sind alle nicht mehr als Clusterressource vorhanden. Wenn Sie aber die Exchange Dienste selbst anschauen, dann finden Sie sehr viele weitere Dienste, die nicht als Clusterressource aufgelistet sind:
- Microsoft Exchange Message Submission
Ohne diesen Dienst bleiben Mails einfach im Postausgang liegen, weil diese nicht zur Hub/Transport-Rolle übertragen werden. - Microsoft Exchange Replication
Ohne diesen Dienst findet überhaupt keine Transaktionsprotokollübertragung statt ! - Microsoft Exchange Transport Log Search
- Microsoft Exchange Search Index
- ...
- Forefront Virenschutzdienste
Sie können auch gerne mal den Test machen und einen dieser anderen Dienste stoppen. Der Cluster wird dies nicht bemerken und auch nicht schwenken. Das ist prinzipiell sogar wünschenswerte, dass sekundäre Dienste nicht gleich einen Failover bewirken. Aber es entbindet Sie natürlich nicht von der Überwachung.
Ich hätte mir z.B. gewünscht, dass diese sekundären Dienste durchaus im Cluster eingerichtet sind. Es reicht ja ein "Do not affect group", damit bei einem Ausfall dieser Dienste der Cluster nicht schwenkt, aber die Gruppe ein gelbes Ausrufezeichen bekommt.
CCR FAQ
- Ungeplanter Failover bedeutet immer einen gewissen Datenverlust von 0/2/5 Transaktionsprotokollen (á 1 MB), wenn der passive Knoten repliziert
- Ist passiver Knoten mehr als 0/2/5 vollständige Transaktionsprotokolle nachhinkend (Latenzzeit im WAN), dann erfolgt beim Failover kein Automount
- Wird ein Automount über "ForceDatabaseMountAfter" erzwungen, dann ist ein größerer Datenverlust zu erwarten. !!
- Rückreplikation macht nicht immer ein neues Seeding, da der Store die Zieldatenbank prüft. Eventuell kann er damit noch arbeiten.
- StreamingBackup auf aktiven Knoten
löscht nur Transaktionsprotokolle, die der passive Knoten schon hat
löscht auch die Transaktionsprotokolle auf dem passiven Knoten - Streaming Backup auf dem passiven Knoten
Diese Sicherung ist nicht möglich - VSS Backup auf passiven Knoten
löscht Transaktionsprotokolle auf passiven und aktiven Knoten - VSS Backup auf aktiven Knoten
ist keine Exchange Sicherung - Kontrollierter Failover mit "LossLess" ratsam
Bitte nie den aktiven Knoten einfach runter fahren. Immer erst die Ressourcen schwenken - Die Datenbank des aktiven Knotens läuft immer 1 oder mehr Transaktionsprotokolle hinterher
- Der passive Knoten sollte nur wenige Transaktionsprotokolle
nachlaufen
Ansonsten kann kein automatisches Failover stattfinden kann und die Gefahr eines Reseeding beim Verlust mehrerer Logs besteht. -> Überwachen Sie dies:
CCR Überwachung
Die meisten Administratoren haben vermutlich noch nie wirklich die Performance Counter angeschaut, denn auf dem passiven Knoten gibt es sehr viele Counter, die sehr gut den Status des CCR-Knotens anzeigen. Man erkennt sehr gut die verschiedenen Stationen, die eine Protokolldatei durchläuft, bis Sie im Ziel (dem passiven Knoten) letztlich eingebunden ist.

Besonders sind hier natürlich die Counter interessant, die eigentlich nur den Status 0 oder 1 haben:
- "Suspended", "Failed" und "Initializing (nicht auf dem Bild
sichtbar)"
Diese sollten immer "0" sein, ansonsten müssen Sie den Fehler suchen und beheben. - "Copy Queue Exceeds Mount Threshold"
Ist dieser Wert auf 1, dann ist die Kopiergeschwindigkeit der betroffenen Speichergruppe "zu langsam". Im Falle eines Fehlers des aktiven Knotens wird der passive Knoten diese Datenbank nicht alleine Online stellen können.
Details, wo es gerade klemmt kann man anhand der anderen Werte erhalten. Der Exchange Replication Service auf dem passiven Knoten ist dafür zuständig, die Protokolldateien auf dem aktiven Knoten zu sehen, zu kopieren, zu prüfen und letztlich in die Datenbank einzubauen. Daher findet man dieses Counter auch nur auf dem passiven Knoten.
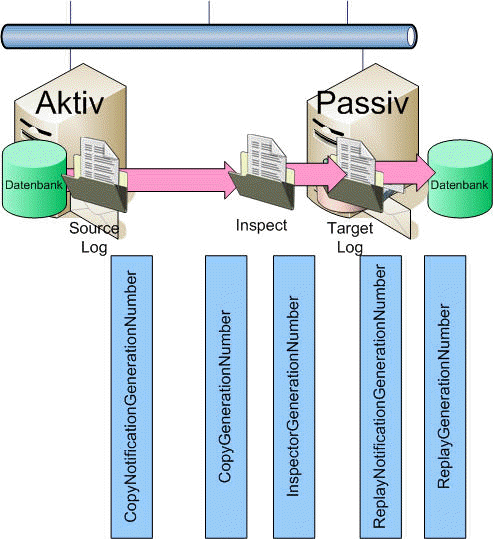
- CopyNotificationGenerationNumber
Die höchste Nummer an Logs, die der Replicationservice in der Quelle (Share) gesehen und in die Liste der zu kopierenden Dateien übernommen hat. - CopyGenerationNumber
Dies ist die Nummer der letzten bereits kopierten Protokolldatei - InspectorGenerationNumber
Dieser Counter zeigt die zuletzt inspizierte Protokolldatei an. - ReplayNotificationGenerationNumber
Dies ist die Nummer der Protokolldatei, die dem Replikationserivce zum einspielen bereits bekannt ist - ReplayGenerationNumber
Bis zu dieser Protokolldatei sind die Logs schon in die passive Datenbank eingespielt
Hier ein Bild zu der Position der verschiedenen Counter.
Sie wissen nun, dass es auch eine Liste der Dateien gibt, die vom Replication Service noch zu bearbeiten sind. Als Prüfpunkt kann man also auch einfach kontrollieren, ob diese Listen ausreichend Kurz sind. Meist sind die Werte nahe 0.
- CopyQueueLength
Der ReplicationService hat Logs zum Kopieren gefunden aber noch nicht kopiert. Ist dieser Counter längere Zeit groß oder steigt an, dann kann es daran liegen, dass die Netzwerkbandbreite zu gering für die aktuelle Datenmenge ist. - ReplayQueueLengh
Anzahl der Logs, die schon kopiert und inspiziert aber noch noch in das Ziel eingebunden wurden. Hohe Werte hier zeigen eher auf einen Engpass der Zielfestplatte hin, dass die Logs nicht ausreichend schnell in die passive Datenbank eingebaut werden können.
Ein Teil der Werte könnte man sich natürlich einfach durch die Substraktion der beiden Counter vor und hinter der Warteschlange ermitteln.
Weitere Links
- Cluster Continuous Replication
-
Exchange Tools vs. Cluster Tools: What's the Deal?
http://blogs.technet.com/b/exchange/archive/2007/10/22/447317.aspx -
http://msexchangeteam.com/files/447215/download.aspx
Flussdiagramme, wann CCR welche Aktion durchführt. - Exchange 2007 Hilfe: High Availability > Cluster Continuous Replication > Installing Cluster Continuous Replication > How to Tune Failover and Mount Settings für Cluster Continuous Replication
- http://blogs.technet.com/scottschnoll
- Exchange 2007 Monitoring Continuous Replication
http://technet.Microsoft.com/en-us/library/bb629521(EXCHG.80).aspx - UCM310: High Availability And Clustering In Exchange Server 2007
http://download.Microsoft.com/download/0/b/e/0be6834f-4fd5-40db-94b6-e56d204a4b2d/UCM003.pdf - Cluster Continuous Replication in Exchange 2007
Part 1: http://msexchangeteam.com/videos/9/drandha/entry428628.aspx
Part 2: http://msexchangeteam.com/videos/9/drandha/entry428629.aspx
Part 3: http://msexchangeteam.com/videos/9/drandha/entry428630.aspx
Part 4: http://msexchangeteam.com/videos/9/drandha/entry428631.aspx
Part 5: http://msexchangeteam.com/videos/9/drandha/entry428632.aspx
Part 6: http://msexchangeteam.com/videos/9/drandha/entry428633.aspx
Part 7: http://msexchangeteam.com/videos/9/drandha/entry428634.aspx - How to upgrade a Clustered Mailbox Server in a CCR
Environment to Exchange 2007 SP1
http://technet.Microsoft.com/en-us/library/bb676320.aspx -
 : upgrading Exchange 2007 CCR to Exchange 2007 SP1
: upgrading Exchange 2007 CCR to Exchange 2007 SP1
http://msexchangeteam.com/videos/9/drandha/entry447645.aspx














