
Verfügbarkeit
Statt Hochverfügbarkeit geht es zuerst einmal um die Verfügbarkeit. Und hier hier gibt es schon mehrere Fälle zu unterscheiden. für eine saubere Planung muss sich die Geschäftsführung hier festlegen oder Sie müssen für die verschiedenen Verfügbarkeitszeiten entsprechende Kosten gegenübersetzen:
| Szenario | Ausfallzeit | Kosten |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Die ganzen Zeiten müssen aber noch nach Rollen gestaffelt werden. Ein Mailbox Server ist natürlich eine kritische Ressource. Aber das Mailrouting (Hub/Transport/SMTP) oder der Zugriff (Frontend/CAS/ISA/POP3/IMAP4 etc.) kann auch über mehrere Server besser verfügbar gemacht werden. Und an all die Geschäftsführer, die eine Wiederherstellung in Minuten oder sogar wenigen Stunden fordern, seit gesagt, dass die dazu zumindest Ersatzhardware vor Ort vorhalten müssen, da kein Lieferant in weniger als 4h ein Ersatzteil vor Ort garantiert. Sie sehen, dass Verfügbarkeit mehr ist, als mal schnell einen Cluster zu installieren und die Hände in die Taschen zu stecken.
Warum Cluster oder sind 99,9% möglich ?
Exchange und der Inhalt und die Erreichbarkeit der Inhalte wird immer wichtiger. Erst wenn der Exchange Server einige Stunden nicht verfügbar ist, und die Anwender an die Tür trommeln, wird dies jedem Administrator so recht deutlich. Daher ist eines der Ziele die Erhöhung der Erreichbarkeit.
Wenn Sie eine Hochverfügbarkeit fordern, dann geht es um die Betrachtung aller Aspekte. Es reicht nicht, einen Exchange Cluster zu installieren, aber Netzwerk, Domain Controller, Namensauflösung, IP Adressvergabe, Internetanbindung und so weiter zu vergessen.
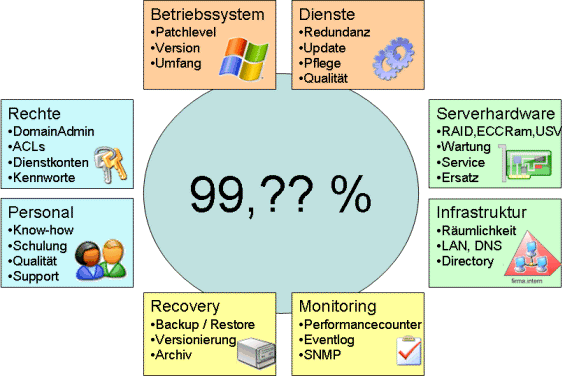
Die 99,9% sollten sich nicht auf einen SERVER beziehen, sondern auf die Funktionen.
Hier einige Aspekte beim Betrieb und wie diese gesichert werden könnten:
| Szenario | Verhinderung |
|---|---|
Ausfall einer Festplatte |
Hardware RAID mit Hot Standby |
Probleme der Stromversorgung |
USV und Überspannungsschutz |
Netzwerkprobleme |
Doppelte Anbindung an mehrere Switches. Adapter Teaming |
Serverprobleme |
Qualitätshardware mit Defekterkennung. Ausblenden des Moduls und Neustart. |
Datenbank korrupt |
KEINE LöSUNG !!!! |
Internet Mail |
mehrere Connector Server, Firewall, doppelte Anbindung, Backup-Wählverbindungen |
Netzwerkinfrastruktur |
mehrere eigene DCs, GCs, DNS-Server, WINS-Server, DHCP-Server |
Alle diese Faktoren können ohne Cluster ebenso in der Verfügbarkeit preiswerter erhöht werden. Es gibt nur sehr wenige Gründe "FÜR einen Cluster. z.B.
- Automatischer Failover beim Ausfall eines kompletten Serverknoten
- geringere Downtime bei Updates und Service Packs
Die geringere Downtime erklärt sich, dass ein Rolling Update möglich ist und eine Kernfunktion des Clusters ist der Failover beim Ausfall eines Knotens in relativ kurzer Zeit. Insofern müssen Sie sich überlegen, ob Sie nicht einfach mit einem "gut gepflegten" System letztlich preiswerter eine bessere Verfügbarkeit erhalten.
Cluster Server ohne Monitoring ist eigentlich ein unding, da der Cluster nicht alles retten kann, sondern eine Komponente in der Kette hoch verfügbar macht. Aber für die Gesamtfunktion sind alle Bestandteile wichtig. Wenn Sie kein Geld für Monitoring ausgeben können, dann dürfen Sie erst recht kein Geld für Cluster übrig haben.
Durchschnittliche Verfügbarkeit und erlaubte Ausfallzeit im Jahr
Schauen Sie mal auf diese Tabelle, wie viele Stunden und Tage ein System ausfallen darf, um bestimmte Verfügbarkeiten zu erreichen:
| Verfügbarkeit | 24-Stunden Tag | 8- Stunden Tag |
|---|---|---|
90% |
876 Stunden (36,5 Tage) |
291,2 Stunden (12,13 Tage) |
95% |
438 Stunden (18,25 Tage) |
145,6 Stunden (6,07 Tage) |
99% |
87,6 Stunden (3,65 Tage) |
29,12 Stunden (1,21 Tage) |
99,9% |
8,76 Stunden |
2,91 Stunden |
99,99% |
52,56 Minuten |
17,47 Minuten |
99,999% |
5,256 Minuten |
1,747 Minuten |
99,9999% |
31,536 Sekunden |
10,483 Sekunden |
Schon das erreichen von 99,9% ist ein stattliches Ziel, da Sie ihren Server im Jahr mindestens einige Male aufgrund von erforderlichen Patches, Updates aber auch geplanten Erweiterungen neu starten müssen. Cluster kann hierbei helfen, da ein Failover schneller ist, als ein Neustart. Aber eine kurze Unterbrechung bleibt bestehen. Auf der anderen Seite ist es bei einem Failover von 20 Sekunden bis 1 Minute schon sehr schwer, die 99,999 zu erreichen.
Auf der anderen Seite ist diese Tabelle aber auch sehr hilfreich, um bei Vorgesetzten und Inhabern deutlich zu machen, was vielleicht eine geforderte Verfügbarkeit real bedeutet und welch hoher Aufwand dafür entsteht.














