
JetStress 2013/2016
Eigentlich sollte dies nur eine Seite über den Einsatz von JetStress im allgemeinen werden. Da ich in diesem Fall aber einen etwas größeren Server analysiert habe, sind auch einige Probleme von Jetstress aufgefallen die mir vorher so gar nicht bewusst waren. Insofern ist die Seite etwas umfangreicher und tiefgründiger geworden. Viel Spaß beim Lesen.
Brauche ich JetStress?
JetStress ist schon viele Jahre das Werkzeug der Wahl, um ein zukünftiges Exchange System bezüglich der Disk-Performance zu verifizieren. Sie starten JetStress als Admin, wenn Sie auf dem Server nach Windows Server die Updates und Virenscanner aber noch kein Exchange installiert haben. Es macht keinen Sinn, JetStress auf einem schon installierten Exchange Server zu nutzen.
Wenn sie aber glauben, dass Sie auf JetStress verzichten könnten, weil es ja so aufwändig sei und die ganzen Zahlen doch niemand interpretieren kann, dann rufe ich ein lautes "VETO". Ich würde heute keinen Exchange Server mehr in Betrieb nehmen, auf dem JetStress oder ein geeignetes anderes Tool gelaufen ist, um folgende Fakten zu prüfen.
- Performance (Durchsatz, IOPS, Latenz)
Der Schwerpunkt des Tests ist natürlich die Messung der Leistung. Interessanter als die nackten "Megabyte/Sek" bei einem COPY ist die Performance in Bezug auf IOPS und Latenzzeit, die alle miteinander verbunden sind, Quasi wie Roundtrip, Jitter und Packetloss beim Ethernet. Hier gibt es physikalische Grenzen, die z.B. ohne Cache nicht unterschritten werden können. Exchange erwartet weniger als 10ms Latenz bei beliebigen Schreibzugriffen auf Log-Disks (20ms bei Datenbank Write). Wenn Sie wissen, dass eine normale Festplatte von 7-8ms Latenz (Positionierung + halbe Plattenumdrehung) mitbringt. dann ist dieser Wert nur mit Write-Cache zu erreichen. Die Leistung muss aber kontinuierlich anliegen, was gerade auf SAN-Umgebungen oder mit Virtualisierung eine Herausforderung sein kann. - Zuverlässigkeit
Jedes Bit kann kippen. heute gibt es kein "Wahr" oder "falsch" mehr und die Aufzeichnungsverfahren tragen es schon im Namen, dass die Information "vermutet" wird (PRML - https://de.wikipedia.org/wiki/Partial_Response/Maximum_Likelihood). Aber auch Übertragungswege (Kabel) und Treiber können ihnen böse Streiche spielen. JetStress kann nicht nur die Disk sehr voll schreiben, sondern sichert jeden Block auch noch mal über Prüfsummen (CRC) ab, die beim abschließenden Lesen überprüft werden. - Verhalten im Fehlerfall
Wenn alle Test erfolgreich waren, dann können Sie gern auch mal eine Festplatte "beschädigen". In einen RAID-Verbund müssen Sie einfach mal eine Disk ziehen und nach einigen Schreibzugriffen wieder stecken. Der Controller macht ein Rebuild. Reicht die dann verbleibende Leistung noch für den betrieb aus ?.
Ja, sie sollten sich die Zeit für JetStress nehme, wenn sieh ihren zukünftigen Exchange prüfen wollen
JetStress ist also nicht nur für "Große Firmen" sondern auch für den Small Business Bereich. Ich habe JetStress sogar schon auf Systemen genutzt, die am Ende gar nicht mit Exchange betrieben wurden.
Exchange 2016 Überlegungen
Seit Exchange 2010 gibt es von Microsoft und Herstellern keine "Beispiele" mehr für unterschiedlich große Server, sondern einfach nur eine "Preferred Architecture" und die empfiehlt quasi einen Server mit 2 Höheneinheiten, 20.24 Cores, bis zu 96 GB Ram und 12 oder mehr große Festplatten. Damit kann eine kleine Firma einen Single Server aufbauen und wenn mehr Postfächer oder Hochverfügbarkeit ein Thema wird, werden einfach weitere Server daneben verstellt und in einer DAG verbunden. Ab vier Kopien einer Datenbank können Sie überlegen auf ein Backup zu verzichten. SAN o.ä. kommt gar nicht mehr vor Da muss die Frage erlaubt sein, warum Microsoft den Weg geht.
Die Antwort dürfte hier wieder Office 365 liefern und dass Microsoft vermutlich genau solche "Bricks" in der Cloud verbaut und einfach weitere Server einschiebt, wenn mehr Kapazität benötigt wird. Das ganze geht natürlich nur, wenn neben der CPU und RAM eben auch die IOPS-Raten des Massenspeichers mit Exchange harmonieren. In dem Vortrag BRK3206 der Ignite 2015 wurden die Eckpunkte für den Storage aufgelistet:
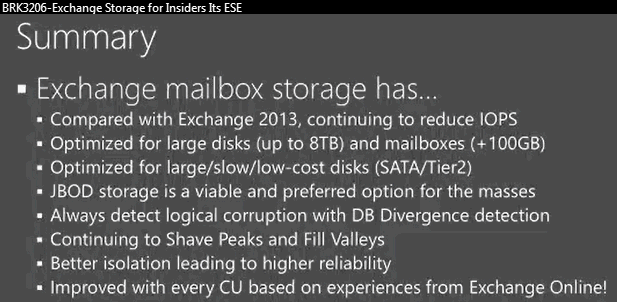
Ein RAID1 wird nur noch für das Betriebssystem und die Programme genutzt während die Datenbanken ganz einfach auf JBOD-Disks liegen, de Windows direkt "sieht". So kann Windows auch Fehler selbst erkenne und mit ReFS sogar einfach die ausgefallenen Daten wieder kopieren. Die Zeiten, dass ein RAID-Verbund durch den Rebuild deutlich verlangsamt ist, sind damit nebenbei auch vorbei.
- The Exchange Preferred Architecture
Exchange 2016 https://blogs.technet.Microsoft.com/exchange/2015/10/12/the-exchange-2016-preferred-architecture/
Exchange 2013 http://blogs.technet.com/b/exchange/archive/2014/04/21/the-preferred-architecture.aspx - Exchange 2013/2016 JBOD Storage
Validation Considerations
https://blogs.technet.Microsoft.com/mspfe/2016/03/15/exchange-20132016-jbod-storage-validation-considerations/ - Exchange Server Role Requirements
Calculator v8.3
https://gallery.technet.Microsoft.com/office/Exchange-2013-Server-Role-f8a61780 - Configure AutoReseed for a database
availability group
https://technet.Microsoft.com/en-us/library/jj619303(v=exchg.150).aspx - Enabling BitLocker on Exchange Servers
https://blogs.technet.Microsoft.com/exchange/2015/10/20/enabling-bitlocker-on-exchange-servers/
Einrichtung
JetStress ist gerade mal ein 1,7 MB Download, den Sie unter der folgenden URL erhalten.
Microsoft Exchange Server Jetstress 2013 Tool
https://www.microsoft.com/en-us/download/details.aspx?id=36849
Starten Sie einfach auf dem zukünftigen Server das Setup und lassen Sie es seine Arbeit tun. Das ist aber noch nicht alles. Das Programm benötigt einige Dateien, die sich auf einem Exchange Server oder den Installationsquellen finden.
C:\Program Files\Microsoft\Exchange Server\V15\Bin\ C:\Program Files\Microsoft\Exchange Server\V15\Bin\perf\AMD64\. ESE.DLL ESEPERF.DLL ESEPERF.INI ESEPERF.HXX ESEPERF.XML
Diese Dateien müssen Sie mit in das Programmverzeichnis von JetStress kopieren.
Jetstress Konfiguration
Danach starten Sie einfach die JetStressWIN.Exe, bei der Sie ein Assistent durch mehrere Dialoge führt. Da Tests oft mehrfach mit unterschiedlicher Hardware wiederholt werden, sollten Sie einen sinnvollen Namen für die Speicherung der Konfiguration vorsehen.
Danach wählen Sie ein Test-Szenario. Sie können zuerst einmal einen generellen Durchsatztest des Storage-Systems durchführen. dabei werden die später für Datenbanken hinterlegten Speicherbereiche möglichst schnell und intensiv beschrieben und gelesen. Alternativ können Sie auch über die weitere Einstellung von "Exchange Mailbox Profilen" eine die geplante Belegung konfigurieren und validieren, wie sich das Speichersystem darunter verhält.
Im folgenden Fenster geht es dann um die Definition der Datenbankanzahl und die Konfiguration der Pfade. Leider übernimmt JetStress hier z.B. nicht die Pfade der Datenbank auch als Defaults für die Logdateien. Es artet also bei vielen JBOD-Disks schon etwas in Tipparbeit aus. Wohl dem, der hier mit MountPoints arbeitet und später bei Umstellungen bei den Disks nicht immer wieder die Konfiguration anpassen muss.
Dann müssen sie nur noch auswählen, ob JetStress die Datenbank neu anlegen soll oder ob es schon vorhandene Datenbanken gibt, die es wieder verwenden soll.
Jetstresss Phasen
Beim Einsatz von JetStress gibt es drei Phasen
- Anlegen der Datenbanken
Ein Thread legt erst mal eine Datenbank mit den gewünschten Parametern an. Das kann durchaus etwas dauern - Kopieren der Datenbanken
Dann wird diese Datenbank als Master auf die verschiedenen Ziele dupliziert. - Belasten der Datenbanken
Zuletzt kommt der eigentliche Test auf den Datenbanken
Schauen wir uns die Schritte genauer an.
Datenbanken vorbereiten
Beim allerersten Start wird es natürlich noch keine Datenbanken geben. Zuerst legt JetStress eine Testdatenbank in der geforderten Größe an. Das kann schon etwas dauern, da JetStress quasi "Datenbank-Inserts" macht. Hier mal eine Musterausgabe von einem Kundenserver im Juni 2016, bei dem das Anlegen einer 300 GB Datenbank fast zwei Stunden gedauert hat.
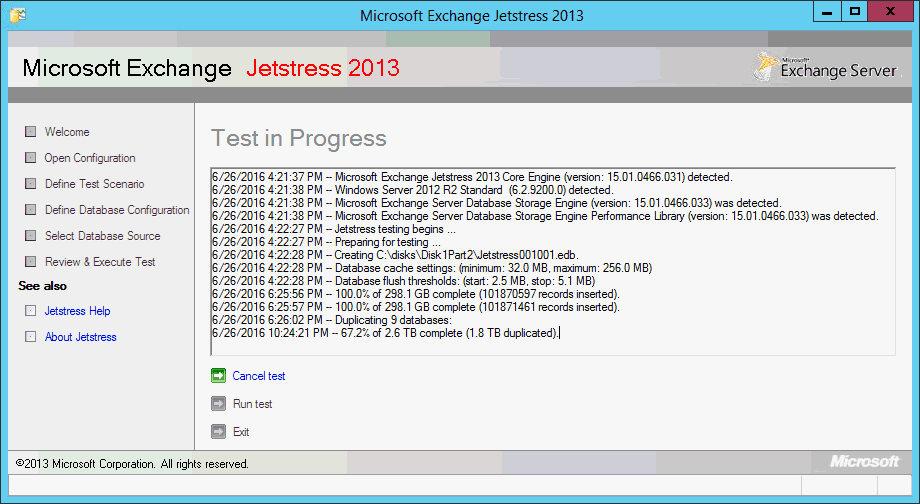
Phase 1: Datenbank vorbereiten
Wenn JetStress noch nie gelaufen ist, dann legt JetStress die Datenbank an. er generiert diese wirklich mit der ESE.DLL, in die immer weiter Seiten eingelagert werden. ein Journalfile stellt quasi per "Umlaufprotokollierung" die Transaktion sicher. Sie können also zuschauen, wie die Datenbank wächst. Damit hat jede Datenbankseite auch ihre CRC-Prüfsumme, die später wieder geprüft wird. Jetstress legt erst einmal genau eine Datenbank an.
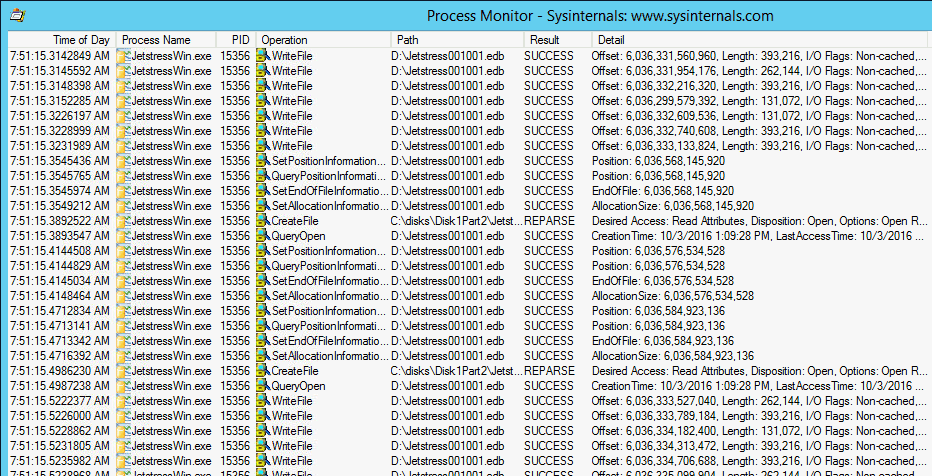
Allerdings werden Sie schon hier feststellen, dass JetStress sehr oft hinter seinen Möglichkeiten bezüglich Performance bleibt. Natürlich ist ein "Database Insert" nicht direkt mit einem "Streamcopy" zu vergleichen. Aber ein Blick mit Sysinternals Procmon zeigt schon, dass Jetstress mit unterschiedlichen Blockgrößen arbeitet und nach einigen Schreibzugriffen immer mal wieder unterbricht und das dauert durchaus länger.
Es hilft alles nichts: zumindest die erste Datenbank müssen Sie so anlegen lassen, wenn Sie nicht irgendwo eine passende Datenbank im TB-Bereich einfach herumliegen haben sollten. Planen Sie für diesen Schritt also durchaus einige Stunden oder gar Tage ein. So kann eine 6 TB Datei auch schon mal 4 Tage benötigen trotz sehr schneller JBOD-Disks an einem RAID-Controller mit Cache. Es kann also durchaus einige Stunden dauern, eine größere Datenbank anzulegen. Je nach Storage-System erreichen Sie zwischen 100-500 GB/h. Wer also eine 4 TB Datenbank als Zielsystem plant, kann den Start ruhig am Abend machen um am nächsten Morgen zu prüfen, ob dieser Schritt abgeschlossen wurde.
Phase 2: Kopieren der Datenbanken
Nachdem die erste Datenbank angelegt wurde, kopiert Jetstress diese Datenbank dann auf alle anderen Disks parallel, .d.h. anstatt auf allen Disks die Datenbanken mühsam anzulegen, wird ein COPY durchgeführt bei dem JetStress die im ersten Schritt angelegte Datenbank wieder einliest und quasi aus alle anderen Disks parallel schreibt. Das hat mehrere Auswirkungen:
- Geschwindigkeit der Quelle
Es ist wichtig, dass die erste Datenbank auf einer schnellen Festplatte liegt, die zumindest gleich schnell wie die Zielfestplatte ist - Vergleichbare Zielfestplatten
Vermeiden Sie, dass Sie als Ziel unterschiedlich schnelle Subsysteme nutzen, da das langsamste Ziel den Takt vorgibt. Wer also einen Exchange Server mit schnellen Disks für Postfächer und langsameren Disks für Archiv-Postfächer aufbaut, sollte die beiden Diskbereiche getrennt messen. - Verteilung der Ziele
Wer mehrere Datenbanken auf der gleichen Disk betreibt, bremst das System deutlich aus, da Jetstress das nicht sehen kann und dann mehrere IOs auf die gleiche Disk ausführt. Je nach Aufteilung in Partitionen muss der Kopf mehr positionieren oder die Datenbanken werden eng verzahnt geschrieben, was beim lesen von großen Datenmengen wieder stört.
Hierbei war gut zu sehen, dass das System von einer Disk gelesen und auf die anderen 9 Festplatten geschrieben hat.
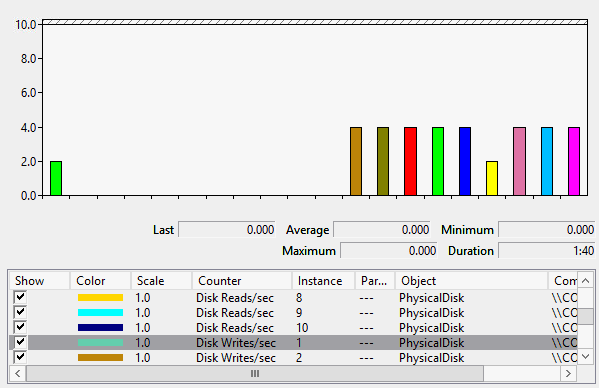
Es ist etwas verwirrend, dass hier nur ca. 4 "Disk Write/Sek" anliegen, also ca. 40 IOPS als Summer aller Disks. Ein ähnliches Bild ist im Taskmanager unter Windows 2012R2 noch besser zu sehen:
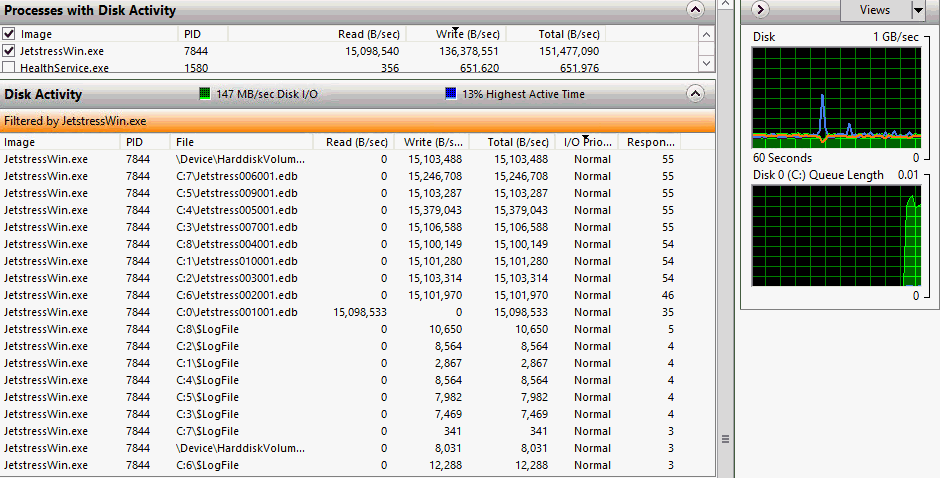
Hier ist zu sehen, dass auf der einen Disk 15 Megabyte/Sek gelesen und auf den anderen Disk summiert ca. 135 Megabyte geschrieben werden. Ich habe das im September bei einer Messung etwas genauer untersucht, warum ein sehr schnelles Subsystem mit JBOD-Disks ca. 10mal so langsam war, wie ein COPY. Die Ursache dürfte in der Art und Weise liegen, mit der JetStress schreibt, was man mit Procmon (Sysinternals) schön sehen kann:
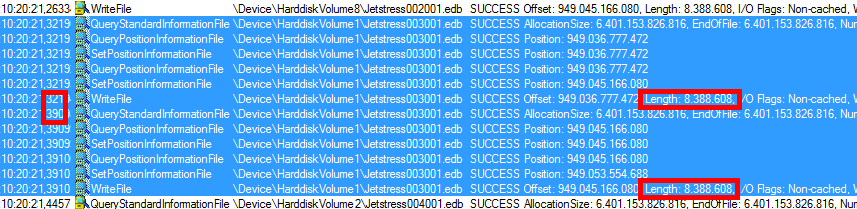
Anscheinend liest Jetstress von einer Disk und schreibt dann aber die 2x8MByte Blöcke doch wieder sequentiell auf alle Disks und wartet dabei auf die Rückmeldung der Disks. Da das durchaus auch mal 50-70ms dauern kann. 16 MB in 120ms ergibt aber maximal 130 Megabyte/Sek. Für eine Festplatte ist das schon wenig für sequentielles Schreiben. Für 10 Disks parallel ist das aber nicht hinnehmbar.
Da nutze ich dann doch lieber eine COPY-Kette mit der ich als CMD-Datei parallele Kopieraktionen starte:
start copy C:\disks\Disk1\Jetstress001001.edb C:\disks\Disk2\Jetstress002001.edb /y /z start copy C:\disks\Disk1\Jetstress001001.jfm C:\disks\Disk2\Jetstress002001.jfm /y /z start copy C:\disks\Disk1\Jetstress001001.edb C:\disks\Disk3\Jetstress003001.edb /y /z start copy C:\disks\Disk1\Jetstress001001.jfm C:\disks\Disk3\Jetstress003001.jfm /y /z start copy C:\disks\Disk1\Jetstress001001.edb C:\disks\Disk4\Jetstress004001.edb /y /z start copy C:\disks\Disk1\Jetstress001001.jfm C:\disks\Disk4\Jetstress004001.jfm /y /z start copy C:\disks\Disk1\Jetstress001001.edb C:\disks\Disk5\Jetstress005001.edb /y /z start copy C:\disks\Disk1\Jetstress001001.jfm C:\disks\Disk5\Jetstress005001.jfm /y /z
Wichtig ist, dass die parallelen Jobs auch möglichst die gleichen Daten gleich schnell kopieren, damit diese nur einmal aus der Quelle geladen werden müssen.
Phase 3: Datenbanken Test 32k Random R/W
Nachdem die Testdatenbanken nun alle bereit stehen, beginnt der eigentliche Test, der per Default auch nur 2 Stunden dauert. Jetstress simuliert je nach Einstellung einen "maximalen IO" zum Messen der Belastung. Diese Werte können mit den Ergebnissen des Exchange Calculators abgeglichen werden. Alternativ kann JetStress auch eine bestimmte Anzahl an Postfächern simulieren und die Antwortzeiten messen. Auf jeden Fall bekommen alle Disks recht viel zu tun:
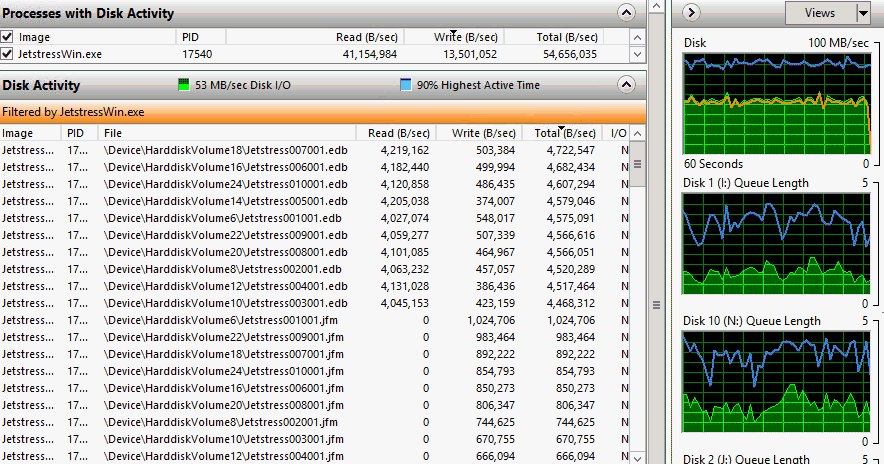
Nicht ganz erklären kann ich mir, warum die Leserate hier ca. 10fach höher ist als die Schreibrate, wo doch das Profil was anderes eingestellt hat:
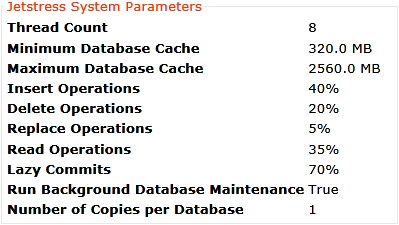
JetStress durchläuft im "Performance Mode" verschiedene Profile mit einer unterschiedlichen Anzahl an Sessions. Ansatzweise kann man das an den Grafiken sehen.
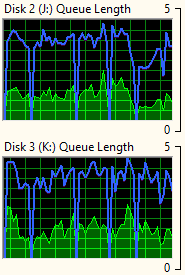
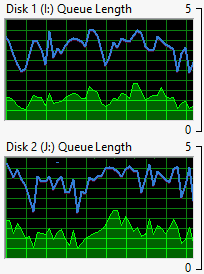
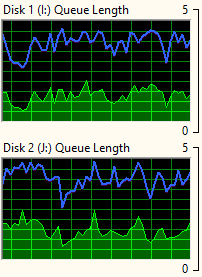
Auch hier habe ich mit Procmon versucht zu sehen, was JetStress so anstellt:
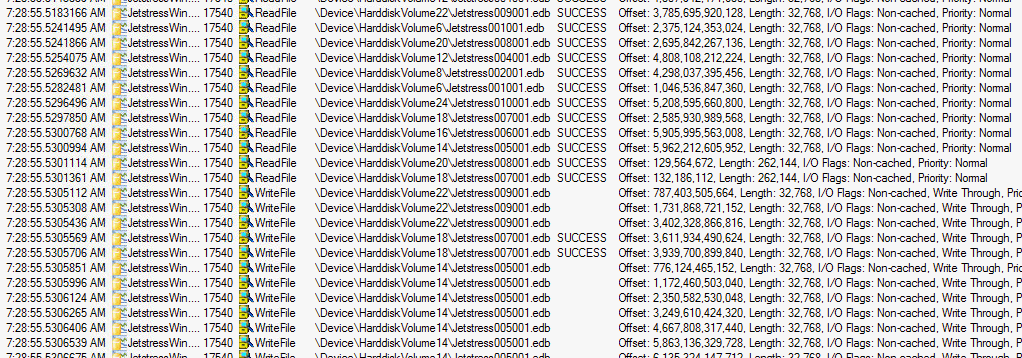
Man sieht überwiegend, dass Jetstress 32k Blöcke liest und schreibt und dabei die Policy "noncached" und "Write.Thought" verwendet. Der Windows eigene Cache wird also umgangen. Was der RAID-Controller oder der Cache auf der Festplatte selbst darauf macht, ist vom Treiber und der dortigen Konfiguration abhängig.
Nach dem Abschluss dieses Belastungstests erstellt Jetstress schon den Performance Report.
Phase 4: Überprüfung der Checksummen
Um sicher zu gehen, dass das Speichersystem auch sauber gearbeitet hat, nutzt JetStress die in der ESE-Engine eingebaute Logik über jede Datenbankseite eine Prüfsumme zu erstellen. Es dauert schon seine Zeit, nun wieder parallel alle Disks zu lesen.
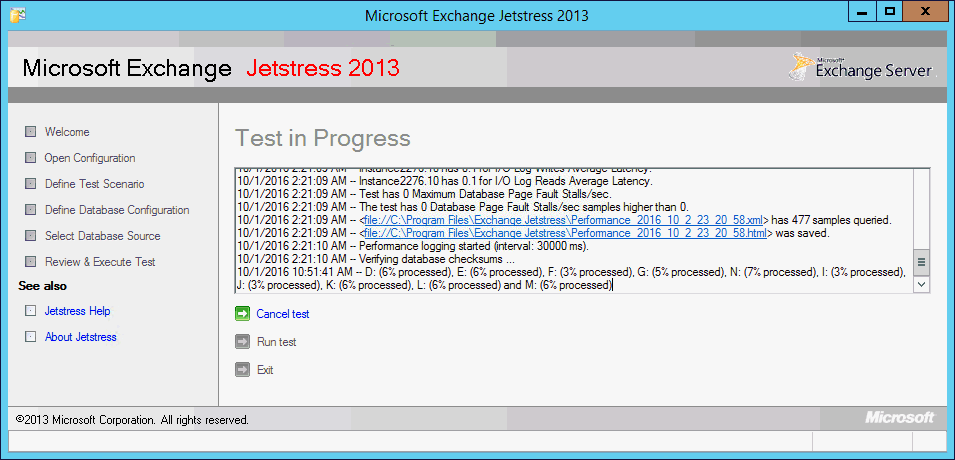
JetStress weiß natürlich auch hier nichts über die physikalische Struktur der Disks. Wer also z.B. mehrere Datenbanken auf einer physikalischen Disk ablegt, hat hier vielleicht eine deutlich schlechtere Performance, da der Lesekopf viel mehr springen und positionieren muss, als wenn die Daten sequentiell gelesen werden.
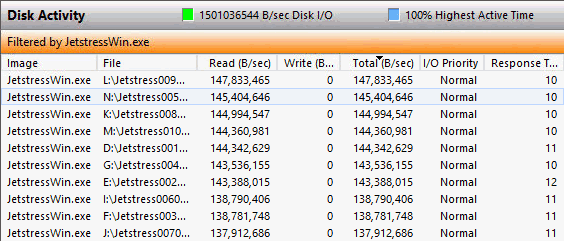
Im Performance Monitor ist aber gut zu sehen, dass alle Disk parallel gelesen werden. Auf jeden Fall schneller als beim Kopieren in der Phase 1. Allerdings dauert es natürlich bei z.B. 3 TB auch mal 18000 Sekunden = 5 Stunden.
JetStress und "Ausfälle
Wenn Sie mit ihren Performancetests abgeschlossen haben und ihr System entspricht den Erwartungen, dann sollten sie Jetstress noch nicht beiseite legen. Es gibt noch einen zweiten Anwendungsfall. Gerade wen Sie mit JBOD aber auch mit RAID arbeiten, dann sollten Sie mit Jetstress das Storagesystem unter Last halten und dann einen Fehler simulieren. Sie können z.B. einfach eine Festplatte "ziehen" oder eine Kabelverbindung abbrechen. Sie können eine Festplatte auch einfach "offline" schalten (Powershell). In allen Fällen darf Jetstress nicht abbrechen und über Perfmon können sie auch ermitteln, wie lange der Server oder der RAID-Controller versuchen die defekte zu "heilen".
Wenn Sie den Ausfall überstanden haben, dann kommt als nächste das "Reparieren". Gerade bei einem RAID-Controller ist es schon wichtig zu sehen, welche Performance bei einem Rebuild übrig bleibt. Sicher können Sie in einer DAG so einen "verletzten Server" aus der Last rausnehmen, so dass er nur noch passive Kopien hat. Aber unter Volllast ein Storagesystem zu stören ist schon etwas anderes als ein System, welches "idle" ist.
JetStress, Cache und IOPS
Über die Notwendigkeit und Sinnhaftigkeit von Cache-Modulen zwischen Exchange und der Festplatte wird immer wieder diskutiert. Natürlich hat jede Festplatte einen Cache, der aber eher in Megabyte denn Gigabyte gemessen wird. RAID-Controller hingegen haben schon mehr Speicher zum Buffern, der zudem konfigurierbar ist (Lese/Schreib-Anteil) und sich auch ne nach RAID-Level und Zustand der Batterie anders verhält. Gerade das Thema "Energie" ist hier wichtig. Ein Server darf erst stromlos gemacht werden, wenn alle Informationen im Cache von Controller und Disk auch weggeschrieben sind. Eine USV ist also zwingend erforderlich, insbesondere, wenn der Cache größer ist und daher das Zurückschreiben einige Zeit dauern kann.
Ein Cache ist aber nicht generell ein "Beschleuniger". Die IOPS-Raten von Exchange sind nämlich kontinuierliche IOPS und das dahinter liegende Subsystem MUSS diese Leistung auf Dauer liefern können. Irgendwelche Rechnungen, dass der Cache die Schreibzugriffe schnell bestätigt und hinten raus dann auf die langsameren Disks schreibt, verblendet die Wirklichkeit. Ein Cache kann IOPS-Spitzen abfedern, wenn es auch wieder IOPS-arme Zeiten gibt, in der ein Cache seine Daten auch wieder loswerten kann.
Ein Cache kann auch ineffektive Zugriffe von Software verbessern, indem er eben die Daten noch im Cache hat und verzögert schreibt. Es soll Programme geben, die mehrfach die gleichen Blöcke schreiben. Hier kann ein Cache-Controller natürlich helfen, indem er die Werte sammelt und erst nach einiger Zeit "Ruhe" den Block letztlich auf die Disks überträgt.
Diese Verhaltensmuster gelten aber nicht für Exchange und nicht für JetStress im "Test-Mode". Ich muss aber zugeben, dass ein Cache-Controller die ungünstige Art beim Vorbereiten der Datenbanken deutlich beschleunigen kann. Das ist aber eher ein Fehler bei JetStress und sollte Sie nicht dazu verleiten, dass für Exchange anzunehmen.
- Understanding controller caching and
Exchange performance
http://blog.enowsoftware.com/solutions-engine/understanding-controller-caching-and-exchange-performance
JetStress Auswertung
Jetstres schreibt sehr ausführliche Berichte über die Aktivitäten und insbesondere die Leistungswerte. Ich möchte hier nicht auf jeden einzelnen Wert eingehen aber zwei Kennzahlen sollten Sie je Disk im Blick haben:
- Erreichte IOPS
Diese Zahl ist wichtig um zu sehen, ob das Speichersystem überhaupt die mit dem Sizer ermittelte Leistung erbringt und schritthalten kann - IO-Latenz
Die Dauer eines Zugriffs ist natürlich auch wichtig für die "Reaktionsfreude" des Servers.
In der HTML-Ausgabe von JetStress ist dies auch schön aufgelistet und Probleme werden von JetStress auch farblich rot gekennzeichnet:
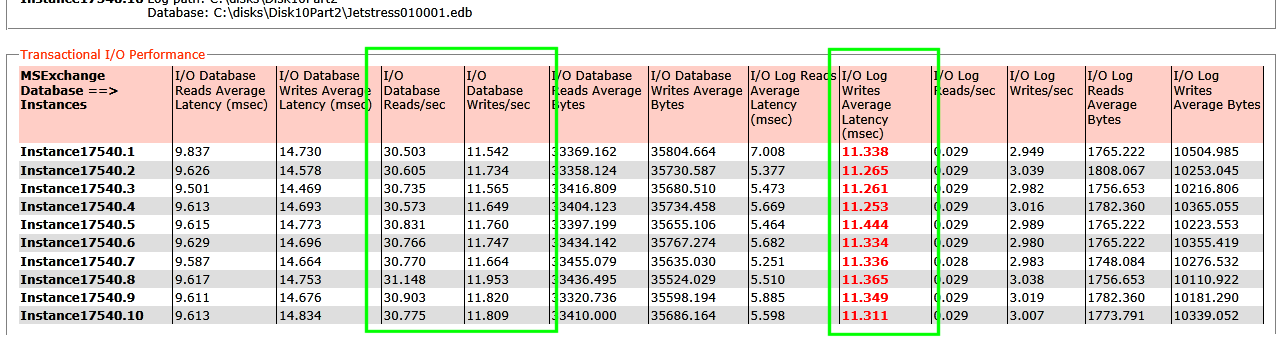
In diesem Fall ist die "IOPS-Latency" beim schreiben der Transactionprotokolle nicht unter den erforderlichen 10ms. Alle anderen Werte sind in Ordnung. Bei den Datenbanken sind die 96,/14,4ms für die IOPS tolerierbar. Dieses System schafft aber auch eine ganz stattliche Anzahl von IOPS. Die "langsame" LOG-Latenz war hier durch einen RAID-Controller verursacht, der keinen Schreib-Cache hatte. Mit 10ms Zugriffszeit der Disk kann die Schreiblatenz auch nie geringer sein.
Weitere Links
- Installing Exchange Jetstress without full installation
media.
http://frankdenneman.nl/2014/02/05/installing-exchange-jetstress-without-full-installation-media/ - Disk Performance Testing with JetStress 2013
http://www.msexchange.org/articles-tutorials/exchange-server-2013/planning-architecture/disk-performance-testing-jetstress-2013.html - Exchange 2016: Storage Performance mit Jetstress testen
(Vergleich NTFS zu ReFS)
Teil 1: https://www.frankysweb.de/exchange-2016-storage-performance-mit-jetstress-testen-vergleich-ntfs-zu-refs-teil-1/
Teil 2: https://www.frankysweb.de/exchange-2016-storage-performance-mit-jetstress-testen-vergleich-ntfs-zu-refs-teil-2/ - Disk Bottleneck Detected
https://technet.Microsoft.com/en-us/library/aa995945(v=exchg.80).aspx - EXCHANGE PERFORMANCE TROUBLESHOOTING – FÄLLE AUS DER PRAXIS
https://advis.ch/Documents/InfoNetDay/2016/Exchange%202016%20-%20Troubleshooting%20-%20Markus%20Hengstler%20-%20UMB.pdf













