
PowerShell Hashtabellen
Neben Arrays und anderen Speichern sind Hashtabellen eine schnelle Möglichkeit, Daten vorzuhalten. Verwechseln Sie dies nicht mit der "Hash"-Funktion (Siehe PowerShell und Hashfunktionen)
Hashtable
Informationen zum Thema "Hashtable" finden Sie auf PS Variablen
PowerShell erlaubt wie jede Hochsprache eine Typisierung von Variablen. Anstatt also nur Bits und Bytes zu speichern, kann ich als Entwickler "Typ" einer Variabel vorgeben und der Interpreter/Compiler überprüft Zuweisungen auf ihre Plausibilität. Mit Strings darf man nicht rechnen und zählen während numerische Werte nicht zeichenbasiert verglichen werden dürfen. Siehe dazu auch PS Variablen. Eine besondere Typdefinition ist dabei die Hashtable, die unter VBScript als Dictionary-Objekt bezeichnet wurde. Sie können sich diese wie eine zweispaltige Tabelle vorstellen:
| Key | Wert |
|---|---|
hash1 |
Wert1 |
hash2 |
Wert2 |
Die Werte können jeden Typ annehmen, also neben einem String oder Zahl auch ein komplexes Objekt sein die mit einem primären Schlüssel verbunden werden. Auch der Schlüssel kann ein beliebiges Objekt sein.
[hashtable]$hash=@{}
$hash.add("key1","value1")
$hash.add("key2","value2")
Eine andere Schreibweise ist:
[hashtable]$hash=@{
key1="value1"
key2="value2"
}
PowerShell ermittelt dann einen Hashwert über den "Key" und speichert den Wert mit dem Key in der Tabelle. Als Ausgabe sieht das noch unspektakulär aus:
PS C:\> $hash Name Value ---- ----- key1 value1 key2 value2
Interessant wird das erst, wenn Sie schnell die Information zu einem bestimmten Wert suchen, der zugleich ein "Key" ist. Sie können ohne Suchen direkt über den Key auf die Werte zugreifen. Die Werte müssen dabei sich nicht auf Zeichenketten (strings) oder numerische Werte beschränken, sondern können auch komplexe Objekte sein.
Write-Host "Value of Key1:" $hash.item("key1")
Auch hier errechnet PowerShell wieder den Hashwert zu dem gegebenen Key und kann damit sehr schnell erkennen, ob eine Information zu dem Key gespeichert ist und da der Hashwert numerisch ist, ist der Vergleich sehr schnell. Bedeutend schneller als z.B. mit String-Vergleichen durch eine Tabelle zu flitzen. Da Hashwerte in der Tabelle auch immer gleich lang sind, kann man auch mit wenigen Schritten direkt an die Stelle springen und muss nicht sequentiell durchlaufen. Intern kann man an die Mitte springen und vergleichen ob der Hash größer oder kleine ist und dann wieder die Mitte der Hälfte anspringen etc.
- Microcode: PowerShell
Scripting Tricks: The Joy of using Hashtables with Windows
PowerShell
http://blogs.msdn.com/b/mediaandmicrocode/archive/2008/11/27/microcode-PowerShell-scripting-tricks-the-joy-of-using-hashtables-with-windows-PowerShell.aspx - PowerShell updating hash
table values in a foreach loop?
http://stackoverflow.com/questions/5879871/PowerShell-updating-hash-table-values-in-a-foreach-loop - HashTable-Class
http://msdn.microsoft.com/en-us/library/system.collections.hashtable%28VS.80%29.aspx
Hashtabellen und Performance
Eine Hashtabelle hat gegenüber einer klassischen Tabelle den großen Vorteil, dass es einen primären Index, also den "Key" gibt, der zwingend eindeutig sein muss. Der "Value" kann dann wieder ein String, eine Zahl aber auch ein komplexes Objekt sein. Um schnell auf genau ein Objekt zuzugreifen, müssen Sie nur über den Key darauf zugreifen. Doch wie schnell ist das und wie kann dies optimiert werden.
Zuerst habe ich das Anlegen und Addieren mir angeschaut. Folgenden Beispielcode habe ich dazu genutzt:
# Testfunktion für Hashwertperformance
foreach ($anzahl in (1,1,10,10,100,100,1000,1000,10000,10000,100000,100000,1000000,1000000)) {
Write-Host "Create" -nonewline
$fill = (measure-command {
$hashtable = @{}
Foreach ($count in (1..$anzahl )){
$hashtable[$count]=[PSCustomObject][Ordered]@{
Keyvalue = $count
Feld1 ="Feld1"
Feld2 ="Feld2"
Feld3 ="Feld3"
Feld4 ="Feld4"
}
}
}
).TotalSeconds
Write-Host " Access" -nonewline
$access = (measure-command {
Foreach ($count in (1..$anzahl )){
}
$hashtable[(get-random)+1]
}
).TotalSeconds
Write-Host " Count:$($anzahl.ToString('0000000')) Seconds to fill $($fill) Seconds to randomaccess $($access)"
}
Über Anzahl und "Measure-Command" habe ich die Funktion auf einem Laptop (T480s, Bj 2019, Intel i7-8550U) mit PowerShell 7.4.5 ausgeführt. Die Performance dürfte mittlerweile höher sein. Besonders bei den kleinen Laufzeiten gibt es Abweichungen, die aber eher auf lokale Effekte zurückzuführen sind, z.B. war das Testsystem natürlich nie "lastfrei" und je weniger Iterationen anstehen, desto mehr schlägt die Initialisierung der Hashtable durch.
| Anzahl | PS 5.1 Anlegen | PS 5.1 Random Lesen | PS 7.4.5 Laufzeit | PS 7.4.5 Laufzeit |
|---|---|---|---|---|
1 |
0,1msms |
2ms |
0,1 ms |
2 ms |
10 |
0,3 ms |
0,1ms |
0,3 ms |
0,1 ms |
100 |
48ms |
0,4ms |
2 ms |
0,4 ms |
1000 |
21ms |
0,5ms |
20 ms |
0,5 ms |
10.000 |
173ms |
6 ms |
201 ms |
6 ms |
100.000 |
2,8 Sek |
39ms |
2,9 Sek |
48ms |
1.000.000 |
33 Sek |
450ms |
33,7 Sek |
459ms |
Speicher am Ende |
1,5 GB |
|
37 MB |
|
Die sehr kleinen Werte sind nicht aussagekräftig da wohl der Start des PS1-Skripts und Measure-Command mehr Zeit als der eigentliche Code braucht. In den höheren Bereichen scheint sich die Zeit linear zu steigern. Bei allen Tests wurden mit Ausnahme der Ergebnisse keine Ausgabe auf den Bildschirm oder eine Datei durchgeführt, welche die Messung verlangsamt hätte. Allerdings sollten Sie auch immer einen Blick auf den Hauptspeicher haben, der deutlich ansteigen kann und auch nach dem Ende des Skripts nicht sofort wieder freigegeben wird
s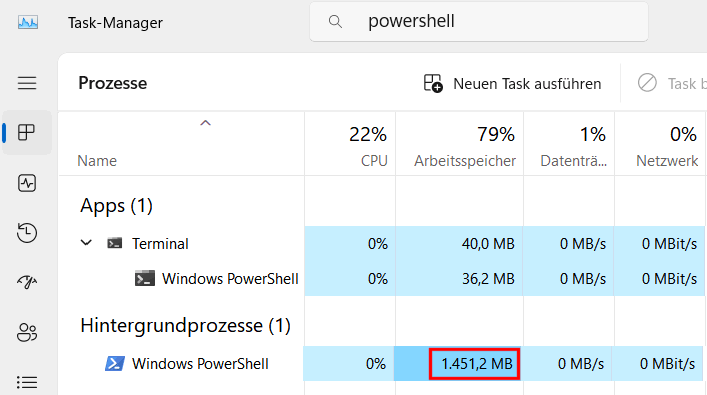
Auch eine manuell gestartete "Garbage Collection". gibt nur einen Teil des Speichers frei, obwohl das Skript zu Ende und damit alle darin lokal genutzten Variablen ja obsolet sind.
[System.GC]::Collect()
Interessen ist aber auch, dass die Powershell 7 mit dem gleichen Code deutlich weniger Speicher verwendet.
All diese Messungen würde ich aber nicht als Referenz ansehen, sondern eher als Hinweis, dass Sie bei der Entwicklung von PowerShell-Skripten und der Nutzung von Hashwerten durchaus auch solche Randparameter beachten müssen.
In meiner Arbeit als Enterprise Consultants passiert es schon einmal, dass ich mit "Get-Recipient" in Exchange auch mal 20.000 und mehr Elemente zurückbekomme und z.B. die Mailadressen in einer Hashtabelle zwischenspeichern möchte. Zumindest beim ersten Lauf sollten Sie die Daten im Blick haben oder direkt im Skript auswerten, z.B. mit:
# Anzeiger des gesamten Speicherverbrauchs der Sessoin [System.GC]::GetTotalMemory($true) # WorkingSet des eigenen Prozesses (Get-Process -PID $pid).workingset
Es gibt meines Wissens keine einfache Möglichkeit, den Speicherbedarf einer bestimmten Variable zu ermitteln. Ich kann aber mit folgendem Befehl eine Hashtabelle erzeugen, in der schon mal 100.000 Einträge vordefiniert sind. Hashtabellen werden nämlich als Array verwaltet und die Erweiterung eines Array ist aufwändiger als gleich von Anfang an den Platz vorzusehen.
$hashtable = New-Object Hashtable 100000
As for += for hashtables, it's extremely slow in PowerShell because the entire
collection is copied, so simply use direct assignment: $hashtable[$key] = $value
Quelle:
https://stackoverflow.com/questions/7523143/powershell-2-and-net-optimize-for-extremely-large-hash-tables
- Hashtable Constructors
https://learn.microsoft.com/en-us/dotnet/api/system.collections.hashtable.-ctor
Auch intern gibt es weitere Unterschiede zur Performance, wenn wir auf die Elemente zugreifen wollen. Auch hier habe ich wieder eine Hashtable angelegt und unterschiedlich zugegriffen, z.B.: mit:
$hashtable[(get-random 100000)+1] hashtable.item((get-random 100000)+1)
Ich konnte hie aber auch bei 100.000 zufälligen Zugriffen keinen signifikanten Unterschied erkennen. Auf dem folgenden Blog sieht das aber anders aus:
- Measuring PowerShell hashtables
performance
https://heavymetaldev.com/powershell-hashtables
Vielleicht sollten Sie einfach in ihrem Code an verschiedenen Stellen immer mal wieder "Messungen" einbauen, wenn der Code langsam unterwegs ist.
Je nachdem, wie Sie ihren Code schreiben, welche Schnittstellen Sie nutzen, wie die ggfls. parallelisieren und welche Felder sie wegfiltern, können Sie die das gleiche Ergebnis in ganz unterschiedlichen Zeiten erhalten.
Weitere Links
- PowerShell und Hash-Werte
-
Easily Create a PowerShell Hash Table
https://devblogs.microsoft.com/scripting/easily-create-a-powershell-hash-table/ -
Dealing with PowerShell Hash Table Quirks
https://devblogs.microsoft.com/scripting/dealing-with-powershell-hash-table-quirks/ -
Measuring PowerShell hashtables performance
https://heavymetaldev.com/powershell-hashtables -
Hash Buckets
https://www.databricks.com/glossary/hash-buckets -
Wikipedia Hashtabelle
https://de.wikipedia.org/wiki/Hashtabelle














