
Ein Sensor ist nicht genug
Diese Seite hat nicht direkt etwas mit dem James Bond Titel "Die Welt ist nicht genug" zu tun aber soll ihnen zeigen, dass bei der Überwachung eines Systems auch ein Prüfpunkt zu wenig sein kann.
Ein Sensor ist nicht genug
https://youtu.be/x_sHOaAE9Js
Wo ist der Fehler?
Bei der Überwachung der Cloud-Dienste "Exchange Online" und "Microsoft Teams" durch das Programm Rimscout (https://www.rimscout.com) habe ich bei einem Client folgende interessante Information bekommen:
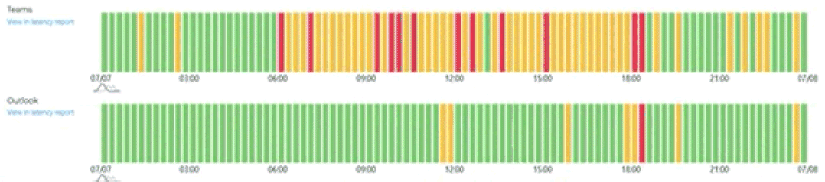
Quelle: Rimscout (https://www.rimscout.com) Portal
Die Abbildung stammt aus dem Rimscout Adminportal. Weitere Informationen zu Rimscout finden Sie hier https://www.rimscout.com
Diese vereinfache Anzeige zeigt einen 24h Tag mit der gefühlten Antwortzeit von https://teams.Microsoft.com und https://outlook.office.com. Eigentlich gehe ich davon aus, dass der Weg von meinem Client über die Router und Firewalls bis zu Microsoft gleich ist und sich erst kurz vor dem Ziel die Pakete dann zur einen Seite in den Teams-Pool oder auf der anderen Seite zu einem Exchange Frontend Proxy aufteilen. Dennoch ist hier gut zu sehen, dass die Performance der Exchange Server fast durchweg "grün" ist, während die Server hinter https://teams.Microsoft.com während der Arbeitszeit schon deutlich träger reagieren.
Pfad und Ziele
Die Frage stellt sich hier natürlich, ob da nun ein Problem mit dem oder den Servern vorliegt oder auf dem Weg zum Server ein Engpass ist. Sie sehen aber sofort, dass ein einfacher HTTP-Check zwar den Service selbst überwacht und bei einem "alles Grün" auch keine weiteren Untersuchungen erforderlich sind.

Wenn Sie aber ein Problem haben, dann wären es von Vorteil, wenn Sie noch weitere Informationen mit erfasst hätte. In Bezug auf einen Webserver gibt es da sogar gleich mehrere Ansätze, denn auch der einfache HTTP-Request kann in mehrere Phasen unterteilt werden.
- TCP-Connection
Vor jeder HTTP-Übertragung steht aktuell noch ein 3-Wege Handshake (TCP SYN ACK RES) aus. Schon die erste ACK-Antwort auf den initialen SYN-Request zeigt uns an, wie schnell der Server antwortet. Diese Messung ist aber eingeschränkt, denn manchmal ist es auch ein Loadbalancer, der hier schon antwortet. Bei einer Übertragung per QUIC - UDP mit TLS statt TCP fällt dieser Test weg - TLS Handshake (Optional)
Heute werden die meisten Verbindungen per HTTPS abgesichert und daher kommt nach dem TCP-Handshake die TLS-Aushandlung (TLS Handshake). Auch diese Zeit geht in die komplette HTTP-Messung mit ein und kann individuell ermittelt werden. Bei einer Übertragung per QUIC - UDP mit TLS statt TCP ist der Handshake und TLS-Check zusammen zu betrachten - HTTP-Head
Als Probe kann ich von dem Webserver nun einfach z.B. den Header der Default-Seite abrufen. Das sollten den Webserver nur minimal belasten und damit schnell gehen. Zumindest sollte er dazu nichts "berechnen" oder ich rufe eine Seite ab, die es nicht gibt. Der damit generiert 401-Fehler erlaubt mit dennoch die Zeit zu messen. Allerdings könnte ein CDN oder ein ReverseProxy hier dann die Werte in positiver Richtung verfälschen. - HTTP-Payload
Perfekt auf für den Webserver auch teurer wird der Abruf einer Inhaltsseite. Der Webeserver muss dazu die Seite erst einmal zusammenstellen und die Antwort ist entsprechend größer, so dass die Latenzzeit länger dauert. Sie könnten hier nur die "Time to first Byte" nutzen, um die Verzögerung durch die Payload heraus zu rechnen.
Und wenn ich dann noch die Zwischenstationen erfassen will und die Router brav auf einen ICMP-Ping oder ICMP-TTL-Exceeded antworten, dann kann ich auch den Weg dorthin mit erfassen.

Wenn Sie diese unterschiedlichen Zeitpunkte ermitteln wollen, dann reicht natürlich kein "Invoke-Webrequest" per PowerShell oder ein Rückgriff auf WinHTTP. Hier müssen Sie dann schon selbst über die TCP-Sockets eine Verbindung aufbauen, den TLS-Handshake initiieren und den HTTP-Request formulieren. Aber auch das ist nicht wirklich knifflig. Ein Beispiel finden Sie auf der folgenden Seite:
Fächerschuss
Auf eine weitere Besonderheit sollten Sie vorbereitet sein. Kaum ein seriöser Cloud-Anbieter stellt ihnen nur einen Server bereit, sondern nutzt verschiedene Wege, eine hohe Verfügbarkeit und Skalierbarkeit zu erreichen. In der Regel kommt eine oder eine Kombination der folgenden Bausteine zum Einsatz:
- DNS Round Robin / Geo-DNS
Anstatt nur einen Server zu betreiben, werden mehrere Server mit dem gleichen Inhalt bereitgestellt, die im DNS alle mit dem gleichen Namen veröffentlicht werden. Ihr Client bekommt per DNS also mehrere IP-Adressen und verbindet sich in der Regel mit dem ersten Server. Die DNS-Antwort kann den Anbieter auch noch anhand ihres Netzwerkstandortes optimieren. So lassen sich Lasten auf viele Server verteilen. Für das Monitoring bedeutet dies aber, dass Sie immer nur einen Server und keinen bestimmtes System abfragen, welche auch immer wieder ein anderes System sein kann. Sie können die Ergebnisse durch mehrere Messungen "verbessern", um Ausreißer nach oben und unten zu eliminieren. - WebApplicationFirewall/Reverse Proxy/CDN
Ein anderer Weg ist die Veröffentlichung des Servers durch einen Reverse Proxy, der auch gleich unerlaubte URLs abblockt, SSL-Offloading betreibt und die Last auf den besten Server im Backend weiter gibt. Manchmal können Sie, wie z.B. bei Outlook.office.com, anhand eines HTTP-Headers noch erkennen, welcher Server real geantwortet hat. Die Messungen hinsichtlich TCP-Handshake und TLS-Handshake terminieren aber immer auf diesem Reverse Proxy und sind damit keine verlässliche Messung zum eigentlichen Service. Allerdings würde ich dennoch nicht darauf verzichten, da die "Innenverbindung" beim Anbieter meinst nicht das Problem ist.
Wenn Sie wissen, dass es mehrere Server gibt und diese mit eigenen IP-Adressen erreichbar sind, dann könnten Sie natürlich diese Server parallel abfragen und die Performance messen. Das ist aber keine praktikable Herangehensweise für große Cloud-Anbieter wie Microsoft, Amazon, Google und Co, sondern eher für kleine gehostete Dienste für ihre Firma geeignet.
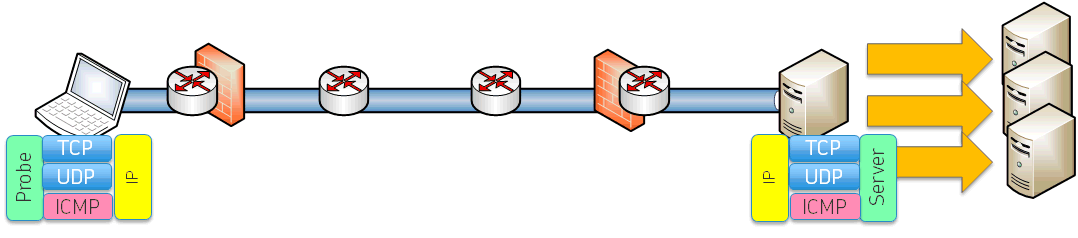
Wenn Sie z.B. zwei oder drei Mailserver im Internet über den MX-Record veröffentlichen, dann können Sie so die Server individuell prüfen. Das funktioniert auch bei einem Hosting eines eigenen VPN-Services mit mehreren Servern o.ä. Es funktioniert aber nicht, wenn der Service selbst mit nur einer IP-Adresse angesprochen wird. Wenn die Server aber nicht direkt ansprechbar sind, dann bleibt der Unterbau hinter den direkt erreichbaren Services unbekannt.
Sensor Kombination
Wenn ihre Monitoring-Lösung keine entsprechend ausgeweitete Überwachung eines Service erlaubt, können Sie natürlich mehrere einzelne Sensoren aufbauen. Es hindert sie ja niemand daran, zu einem System sowohl einen HTTP-Sensor und TCP-Connect-Sensor zu jedem Server als auch ein paar PINGs zu den Zwischenstationen zu konfigurieren und dann gegenüber zu stellen. Da kommen dann schon interessante Werte heraus, wenn zwei Server nebeneinander im gleichen LAN stehen und einer sich anders verhält.













