
End2End Status
Seit Beginn des Monitoring machen sich Entwickler Gedanken über die Erfassung der Ergebnisse. Es ist leider nicht einer binären Logik getan, die einfach nur ein "OK" oder "DOWN" liefert. Sehr schnell kommen aber noch Zwischenstufen dazu, weil auch ein "Langsam" interessant ist und ein Fehler seitens der Überwachung selbst ebenfalls erkennbar sein muss.
Beispiele
Wenn Sie sich z.B. Nagios anschauen, dann gibt es dort vier Rückmeldungen der Plugins.
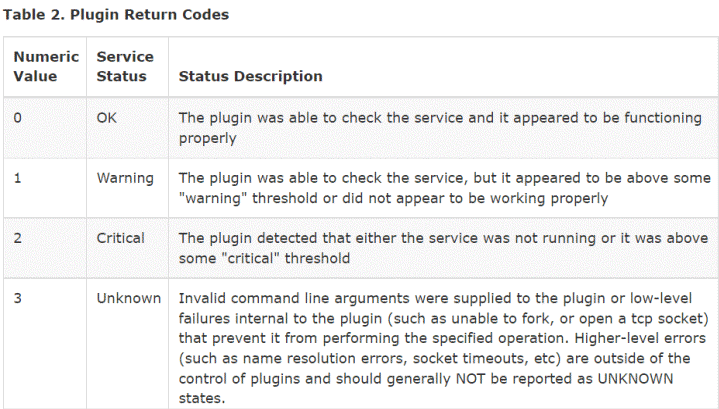
Quelle:
Nagios Plugin Return Codes
https://nagios-Plugins.org/doc/guidelines.html#AEN78
Es gibt die drei Meldungen bezüglich der "Performance" oder einer generellen Fehlermeldung, wenn das Plugin nichts liefern kann. Im letzten Fall ist der Messwerte nicht weiter aussagekräftig.
Bei PRTG gibt es eine weitere Unterscheidung im letzten Fall:
| Exitcode | Bedeutung | Beschreibung |
|---|---|---|
0 |
OK |
Fehlerfreie Ausführung. Nutzen Sie doch das Feld "Message" um vielleicht mehr Details zu melden |
1 |
Warnung |
Das Skript kann so melden, dass z.B. ein Sensor an einer Warngrenze ist. Gemeldete Werte werden als "0" erfasst. |
2 |
Critical |
Die Werte sind über den "Critical" Grenzwert oder der Sensor konnte keine Daten erhalten, z.B. weil das Zielsystem nicht erreichbar ist, falsche Parameter angegeben wurden o.ä. Ein guter Sensor schreibt in die Message die Details zum Fehler. Gemeldete Werte werden als Fehler ignoriert und die Zeit wird als "Ausfallzeit" gewertet. |
3 |
Protokollfehler |
Mit diesem Fehler sollte ein Sensor melden, wenn er zwar die angesprochene API erreicht hat, aber z.B. aufgrund von Berechtigungen keine Daten zur Auswertung gewinnen konnte. Gemeldete Werte werden als Fehler ignoriert und die Zeit wird als "Ausfallzeit" gewertet. |
4 |
Contentfehler |
Mit diesem Fehler sagt ein Sensor, wenn er erfolgreich Daten erhalten hat (Verbindung und Anmeldung ok) aber die Werte nun gar keinen Sinn machen. Sie können außerhalb der erwarteten Bandbreite sein oder enthalten nicht die erwarteten Inhalte. Gemeldete Werte werden als Fehler ignoriert und die Zeit wird als "Ausfallzeit" gewertet |
PRTG werden vergleichbar zu Nagios die Rückmeldungen der Plugins/Module aus aber wenn die übergebene String/XML/JSON-Struktur nicht verstanden werden kann, gibt es einen Content-Fehler.
Einzeltest
Auch bei der Entwicklung von Rimscout haben wir uns überlegen müssen, welche Messungen wir wie ausführen und wie die Ergebnisse zu interpretieren sind.
Weitere Informationen zu Rimscout finden Sie hier https://www.rimscout.com
Die Anforderungen sind doch relativ ähnlich zu Nagios, PRTG und Co aber letztlich haben wir uns über eine feinere Abstufung entschieden. Microsoft, Google und andere beschreiben für Audio/Video zwar einen absoluten Grenzwert von ca. 100ms Roundtip-Time aber eine solch binäre Aussage hilft mir bei einem Netzwerk Assessment nicht weiter. Auch bei anderen Tests wünsche ich mir schon eine "Vorwarnung", dass eine Messung nahe an einen Grenzwert kommt und erst darüber dann den Status "Kritisch" erreicht. Hinzu kommen Einflüsse von vorherigen Messungen, die speziell bei einem Timeout die Ergebnisse verfälschen können. (Siehe End2End Werte

Wenn der Sensor oder der Test natürlich auf einen Fehler läuft, z.B. keine IP-Adresse, keine Namensauflösung, kein Socket zu öffnen etc., dann ist der Status direkt ein Fehler/ERROR, denn der Test kann gar nicht laufen und liefert nie gültige Daten, egal, wie schnell der Test wieder zurückkommt. Ansonsten nimmt der Test die Werte OK ,Warning, Critical an aber auch da gibt es eine Obergrenze, der eigentlich einen Fehler anzeigt. Denn wenn z.B. eine Firewall die Verbindung einfach unterdrückt und mein Test zwar keinen Fehler aber einfach keine Antwort bekommt, dann wäre es ungeschickt den Timeout als gültigen Messwert in die Bewertung zu übernehmen, nur weil es keinen "Fehler" gegeben hat. Klar könnte man einen Timeout einfach als "Fehler" klassifizieren, aber für die Fehlersuche ist schon ein Unterschied, ob wir einen Fehler im Code oder der Konfiguration haben, oder das Problem auf der Verbindung oder anderweitig zu suchen ist.
| Programmstatus | Messwert | Ergebnis | Messwert | Beschreibung |
|---|---|---|---|---|
OK |
X < Warn |
OK -> Wert messen |
Übernehmen |
Der Test hat funktioniert und die Antwortzeit ist unter der Warnschwelle |
OK |
Warn< X <Critical |
Warn-> Wert messen |
Übernehmen |
Der Test hat funktioniert und die Antwortzeit ist zwar über der Warnschwelle aber noch unter der Ciritcal-Schwelle |
OK |
Critical < X < Timeout |
Critical-> Wert messen |
Übernehmen |
Der Test hat funktioniert und die Antwortzeit ist über der Ciritcal-Schwelle. |
OK |
>Timeout |
Error + Subcode: Timeout |
Wert verwerfen |
Der Test konnte gestartet werden und das Ergebnis wäre "kritisch" aber ist eigentlich ein Timeout, d.h. der Messwerte ist nicht aussagekräftig und wird auch nicht in die Datenbank übernommen. Er würde nur die Mittelwerte u.a. verfälschen. Ursache könnte z.B. eine blockierende Firewall oder ein "Down" der Gegenstelle sein. |
Fehler |
Any |
Error + Subcode |
Wert verwerfen |
"Wir haben keinen Messwert", d.h. wir sind "Blind" und es muss geprüft werden, warum die Überwachung nicht funktioniert. Das kann fehlende IP-Verbindung, keine Namensauflösung o.ä. sein, was den Start des eigentlichen Tests unterbindet. |
In der Tabelle habe ich nicht die weiteren Möglichkeiten aufgeführt, die einige Programme vorsehen wie z.B. wenn keine Messung (UNKNOWN) durchgeführt wurde oder ein Vergleich zur einer Messung am Vortag oder der vorherigen Woche um Veränderungen zu erkennen (UNUSUAL).
Massentests
Bei Rimscout machen wir nun nicht nur einmal in der Minute oder alle 5 Minuten einen Test sondern es gibt auch sehr viel intensivere Tests, bei denen jede Sekunde oder noch häufiger die Gegenstellen abgefragt werden.
Weitere Informationen zu Rimscout finden Sie hier https://www.rimscout.com
Jeder dieser Einzeltests liefert schon Daten und ich kann und will nicht jedes einzelne Ergebnis aufbewahren. Analog gilt dies für Wert, die ich über Wochen, Monate oder gar Jahre erfassen möchte und mich dabei der individuelle Messwert immer weniger interessiert, je weiter die Messung in der Vergangenheit liegt. Ich muss also "Zusammenfassen". Auf der Seite End2End Werte habe ich schon beschrieben, dass "Mittelwerte" und "Median" zwar nett und einfach sind, aber am Ende alles nur noch "weichgespült" ist.
Wenn ich End2End-UDP3478 als Extrembeispiel nehme, dann prüfe ich ca. 50 Mal/Sek die Leitung zu Microsoft, und hoffe, dass die Pakete in weniger als 100ms ankommen. Meist sind es 15-25ms. Ich komme also schon auf 40-50 Messungen von denen aber nicht alle "Perfekt" sind. Es gibt schon einige Messungen, die sehr langsam sind oder sogar ein Paket verloren geht. Zum einen reduziert sich damit die Anzahl der Messungen, da ich in dem Fall ohne Sequence-Nummer o.ä. auf die vorherige Antwort warten muss aber ein Regentropfen macht noch kein Gewitter. Ich muss also überlegen, wie ich viele Einzel-Werte zusammenfasse um damit ein Ergebnis zur Rückmeldung ermittle.
Aktuell zählen wir die Timeout und Fehler während wir von den gültigen Messwerten dann Minimum, Maximum, Mittelwert aber auch Percentile (Siehe End2End Werte), die wir dann in Grafiken anschauen.
Wobei man schon drauf achten muss, dass viele "Fehler" am Ende die Aussagekraft der eigentlich validen Werte fragwürdig machen. Wenn ich 50 Tests mache, von denen dann 40 fehlschlagen, dann wird das Ergebnis nur noch den 10 gemessenen Werten ermittelt. In dem Fall wäre mir wichtiger, dass es so viele Fehler gegeben hat.
Langzeittest
Eine Messung pro Minute ergibt 60 pro Stunde oder 1440 Messungen pro Tag. Das passt wunderbar in eine 24h-Grafik auf einem modernen Bildschirm, ohne dass Werte unterschlagen werden müssen. Wenn ich aber die Werte einer Woche oder eines Monats anzeigen möchte oder die Werte mehrerer Systeme am gleichen Standort zu einem Überblick zusammenfassen möchte, dann muss ich mir ein anderes Verfahren überlegen. Sollte z.B. ein Computer häufige Fehler haben, dann darf das nicht in der Menge der "guten" Clients untergehen. Die gleichen Überlegungen gelten für die Zusammenfassung von Zeiträumen, wenn bei einer Monatsübersicht immer 30 Werte zu einem Ergebniswert führen, dann sollte man mehrere "Bad"-Werte nicht einfach übersehen.
Wir brauchen noch einige Zeit, anhand echter Daten hier eine geeignete Bewertung zu ermitteln.
Weitere Link
- End2End Werte
- Nagios Plugin Return Codes
https://nagios-Plugins.org/doc/guidelines.html#AEN78 - Standard EXE/Script Sensor
https://www.paessler.com/manuals/prtg/custom_sensors#exe_script













