
End2End-HTTP
Die Performance und Erreichbarkeit eines WebServices sollte nicht nur durch passive Überwachung von CPU, RAM, Disk-IO und Netzwerkkarte erfolgen. Diese Daten liefern nicht immer zuverlässige Daten und sie sind Blind für Probleme auf dem Übertragungsweg. Der Anwender merkt diese aber sehr wohl und speziell mit Office 365 ist es um so wichtiger, die Erreichbarkeit und den Weg zu den Cloud-Diensten zu überwachen. Mit End2End-HTTP habe ich mir ein entsprechendes Werkzeug geschaffen.
Beachten Sie dazu auch die Informationen auf End2End-SharePoint und Last Mile Telemetrie
Überlegungen
Für die Überwachung von Office 365-Verbindungen ist ein einfacher PING nicht gut genug. Die meisten Office 365-Dienste nutzen HTTPs und da bietet es sich an, diese Daten immer wieder regelmäßig abzufragen und die Antwortzeit und Reaktionszeit zu überwachen. Wie ich schon mehrfach auf Ende zu Ende Monitoring beschrieben habe, ist es wichtig hier nicht nur die Erreichbarkeit eines Dienstes zu überprüfen sondern auch die Performance aus Sicht des Clients zu überprüfen. beachten Sie dazu auch End2End ClientCheck, mit dem ich auf einem Client unterschiedliche Dienste überwachen kann. Mit End2End-HTTP hingegen möchte ich als Administrator die Verbindung von meinem LAN zu einem WebService sehr eng überwachen ohne einen Last-Test zu fahren.
Aus meiner Sicht ist die Funktion einer "Lastsimulation" von der Überwachung getrennt zu sehen, auch wenn beide das Gleiche nur mit andrem Volumen machen. Ich kann aber problemlos beide Bausteine derart kombinieren, dass meine kleine Dauerüberwachung natürlich eine Veränderung feststellen wird, wenn eine Lastsimulation die gleiche Leitung belegt. Ich muss dann gar nicht unbedingt die Performance der Last-Simulation genau erfassen. Bei der Lastsimulation interessiert natürlich schon, wie viel Bandbreite, wie viele Requests und mit welcher Latenzzeit die Aufgaben erledigt werden. Eine Lastsimulation ist aber keine Daueraufgabe sondern dienst der Verifikation vor einem Umbau und nach einem Umbau der Verbindungen oder Veränderungen am Lastprofil.
Hier ist die Dauerüberwachung als Grundlagenmessung sogar bedeutender, da sie über Tage und Wochen hinweg die Erreichbarkeit eines Dienstes und die Performance vom Client auf dem der Test läuft bis zum Ziel misst.
Eine Messung mit HTTP benötigt natürlich eine Gegenstelle, die nicht drosselt und ausreichend schnell reagiert, damit auch wirklich etwas gemessen werden kann. Ideal sind dabei statische Dateien wie z.B. Bilder, so dass der Webserver diese nicht immer neu berechnen muss. Auf der anderen Seite kann dann aber auch ein WAN-Optimierer oder Content Delivery Netzwerk die Messung beeinflussen. Dafür funktioniert die Messung auch über einen HTTP-Proxy, wenn eine Firewall eine direkte TCP-Verbindung unterbindet.

Dennoch setzt sich die gemessen Zeit aus mehrere Komponenten zusammen und darf nicht mit der Zeit bei einem ICMP-Ping (Siehe auch End2End-Ping) verglichen werden.
Ich habe mir überlegt, dass ich z.B. jede Sekunde einen HTTP-Request ausführe und die Dauer und Datenmenge dazu erfasse. Nun kann und will ich nicht für jede Sekunde einen Messwert an mein Monitoring übergeben. Für eine Fehlersuche und eine Detailauswertung schreibe ich natürlich eine lokale CSV-Datei. Für die Auswertung habe ich mir aber zwei andere Dinge überlegt.
Mit jedem Abruf erhalten ich die Anzahl der Bytes, einen Status und die Dauer, die der Abruf benötigt hat. Diese Werte bereite ich entsprechend auf, damit ich folgende Kennzahlen in einem gegebenen Messintervall ermitteln kann.
- Gleitender Mittelwert der Antwortzeiten
Ich ermittelt den Mittelwert der letzten Anfragen. Um Veränderungen über den Tag hinweg zu erkennen, wird der Mittelwert aus der Summe aller Anfragen im Messintervall geteilt durch die Anzahl der Anfragen ermittelt. - Längste Antwortzeit
Von allen erfolgreichen Abfragen im Messintervall wird der Maximal wert gesammelt - Kürzeste Antwortzeit
Auch die Zeit für die schnellste Anfrage im Messintervall wird festgehalten - Anzahl der guten/absolut
langsamen/relativ langsamen/fehlerhaften
Anfragen
Neben den Zeiten in ms zählt die Auswertelogik den Status der Abfragen. Neben der Anzahl der fehlerhafte Anfragen wird bei den anderen drei Klassen die Dauer der Anfrage bewertet. Es gibt einmal eine absolute Obergrenze, über der eine Anfrage als "Absolut langsam" gezählt wird. Zudem führt das Skript intern einen Mittelwert der letzten 10 Abfragen mit und bewertet die Anfragen als "relativ langsam", die zu weit von dem Mittelwert entfernt sind. Dieser Abstand wird durch einen Faktor vorgegeben
So kann ich am Ende jeder Mess-Periode nicht nur einen Wert liefert, sondern mehrere Werte, die durch geeignete Programme entsprechend visualisiert werden können.
Melden und Auswerten
Das Skript kennt drei Möglichkeiten, die Daten zu übermitteln. Alle Datenziele sind optional nutzbar.
- CSV-Datei
Alle Messwerte werden im Sekundentakt in eine CSV-Datei geschrieben. Diese Daten können später mit Excel, PowerShell, Power Bi oder anderen Tools ausgewertet werden. - Pipeline
Alternativ können Sie Ergebnisse auch über die Pipeline an ein Skript zur eigenen Weiterverarbeitung senden lassen. - SMTP-Mail
Werden die Werte für den Mailserver und Empfänger als Parameter übergeben, dann sendet das Skript immer dann eine Meldung, wenn eine Abfrage nicht in Ordnung war. Das kann also ein fehlgeschlagener Abruf oder auch zu lange Antwortzeiten sein. Dieser Weg ist aber eher für ein Ad-Hoc-Monitoring, da es keine grafische Aufbereitung gibt und im Fehlerfall sehr viele Mails entstehen. Es ist aber dennoch hilfreich, wenn Sie End2End-HTTP z.B. mit längeren Abständen eine Webseite prüfen lassen. Solche Tests kann aber eine normale "Monitoring-Software" meist auch. - PRTG-Sensor
Da das Skript ein "Langläufer" ist, macht es keinen Sinn es per PRTG alle 5 Minuten zu starten. Zudem ist auf dem Mess-Client nicht immer auch eine PRTG-Probe installiert. Daher nutzt das Skript die Funktion der PRTG - HTTP Push-Sensoren, um die ermittelten Werte an PRTG zu übergeben. PRTG dient dann nur als Datensammler und zur Darstellung
Das Skript ist im Prinzip zwar auf einen Dauerbetrieb ausgelegt. Einige dazu erforderliche Funktionen (Starten als Dienst, Meldungen im Eventlog etc.) sind aber nicht implementiert. Ich lasse es daher entweder "interaktiv" oder über den Taskplaner (PowerShell und Taskplaner) starten. PRTG ist ja so smart und kann einen Alarm auslösen, wenn die Ergebnisse ausbleiben.
Parametrisierung
Alle relevanten Parameter zur Steuerung des Programs sind als PARAM-Block hinterlegt:

Als "Text-URL" nutze ich einfach das Favicon (7Kbyte) von OWA, welches anonym abgerufen werden kann. ich lasse alle Daten für eine Fehlersuche in eine CSV-Datei schreiben aber sende die Daten nicht zusätzlich an die Pipeline und Mails möchte ich auch keine haben. Der Mailserver ist daher leer. Alle Anfragen, die länger als 1000ms (slowabsms) dauern, sind definitiv zu langsam. Als Faktor für die Abweichung vom Mittelwert habe ich 5 (slowavgfactor) gesetzt. Wenn der Mittelwert z.B. 150ms beträgt, dann ist ein Abruf mit über 5*150m = 750ms ebenfalls "slow".
Nachdem eine Messung erfolgt ist, "schläft" das Skript 1000ms und nach spätestens 86400 Durchläufen, also einen Tag zzgl. der aktiven Laufzeit beendet es sich alleine. Alle 60 Sekunden kann eine Zusammenfassung der ca. 60 Messwerte per HTTPPush an die angegebene PRTG-URL gesendet werden. Den Sensor muss ich natürlich manuell vorab anlegen und in der URL die IP-Adresse, den Port und das Sensor-Token hinterlegen.
Das Skript unterstützt natürlich eine "Verbose"-Ausgabe zur Fehlersuche. Diese macht die Abfragen natürlich deutlich langsamer durch das "Scrollen" auf dem Bildschirm. Im normalen Betrieb gibt das Skript zu jeder Messing ein einzelnes Zeichen mit Write-Host aus:

Ein "." steht für eine erfolgreiche Messung. Das "P" bedeutet, dass ein Datensatz an PRTG gesendet wurde. Weiterhin gibt es "E" für Fehler, und "S" (Slow) für langsame Abfragen.
Eine Messung eines Vodafone Kabel-Anschluss (32MBit) über WLAN ergibt andere Werte:

Das Skript wartet auf Tastatureingaben und ein "X" beendet das Skript nach dem nächsten abgeschlossenen Durchlauf und schließt alle Dateien. Jede andere Eingabe führt zu einer Anzeige, dass das Skript mit "x" beendet werden kann.
Beispiel mit PRTG
Ich habe auf einem PC das PowerShell-Skript kontinuierlich laufen und es meldet alle 15 Sekunden seinen "Datensatz" an PRTG. So kumuliert das Skript im Schnitt die Ergebnisse von 14-15 Messungen in einem Datensatz zusammen.
- Anzeige der Abrufanzahl:
Es ist gut zu sehen, dass die allermeisten Anfragen "gut" sind. und ab und an eine Anfrage als "Absolut zu langsam" erfasst wird. Durch die Addition der Anfragen im Sensor selbst ist es auch nicht mehr so wichtig, ob man nun die Werte alle Sekunde, alle 10 Sekunden oder wie hier alle 60 Sekunden an PRTG meldet. Die absoluten Zahlen pro Intervall ist für eine Auswertung ausreichend. Man muss nicht auf die Sekunde genau wissen, wann ein einzelner Request zu lange gedauert hat. Einzig kurze "Bursts" lassen sich so noch nicht ermitteln.

- Anzeige der Laufzeiten
Der gleiche Sensor hat ja auch die Daten zur Dauer der Abfrage. Da das Skript auch hier die Antwortzeiten der Einzelmessungen schon vorab auswertet, sieht man gut die Max und Min-Werte mit dem Average in der Mitte. Ich habe hier die Grafik gezoomt, damit die drei Linien besser zu sehen sind
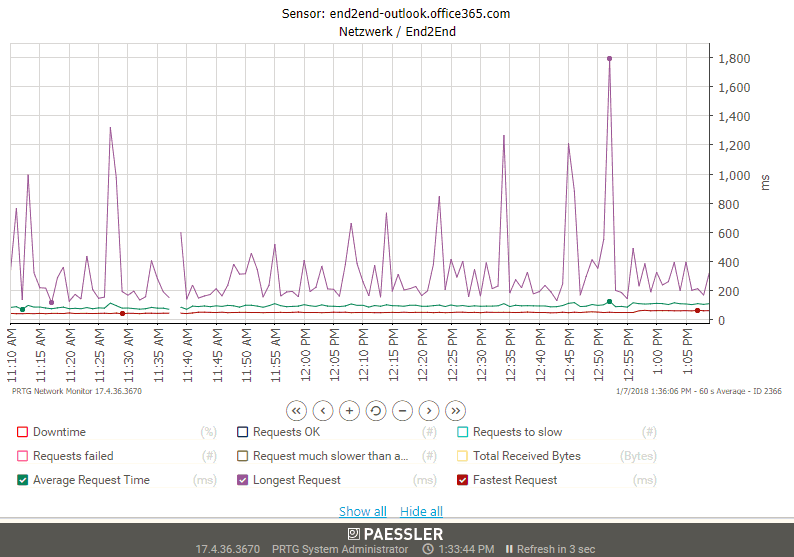
Beide Grafiken sind für die Bewertung einer Verbindung nützlich, denn erst die Vorverarbeitung der vielen Einzelmessungen erlaubt eine sinnvolle Darstellung. Wenn PRTG oder ein anderes Werkzeug die Messung jeder Sekunde verarbeiten müsste, wäre die Datenmenge sehr groß und einzelne Ausreißer würden zu leicht übersehen. So kann ich über den Mittelwert eine allgemeine Abschätzung machen. Wenn der Maximalwert aber sehr hoch ist oder der Mittelwert ansteigt, dann blende ich mir einfach noch die entsprechende Linie für die "Anzahl langsame/fehlerhafte" Anfragen mit ein um besser einen einmaligen Ausrutscher von einer Störung zu unterscheiden.
Bei all den Tests darf man aber nicht übersehen, dass 7kB/Sek ca. 420kB/Min oder 25 MB/Stunde bedeutet. So kommen allein durch den Grundlasttest 18 GB/Monat zusammen. Das ist natürlich ein Klacks wenn man später die Anwender produktiv arbeiten lässt. Sie können ja heute schon mal mit PRTG, NetFlow, IISLogs etc. ermitteln, wie viel Bytes alleine ihre Clients mit dem Exchange Server austauschen. Das wird später über die Leitung mit Exchange Online anliegen.
Wenn Sie die CSV-Datei in Power Bi importieren, dann können Sie auch nette Grafiken erstellen und filtern:
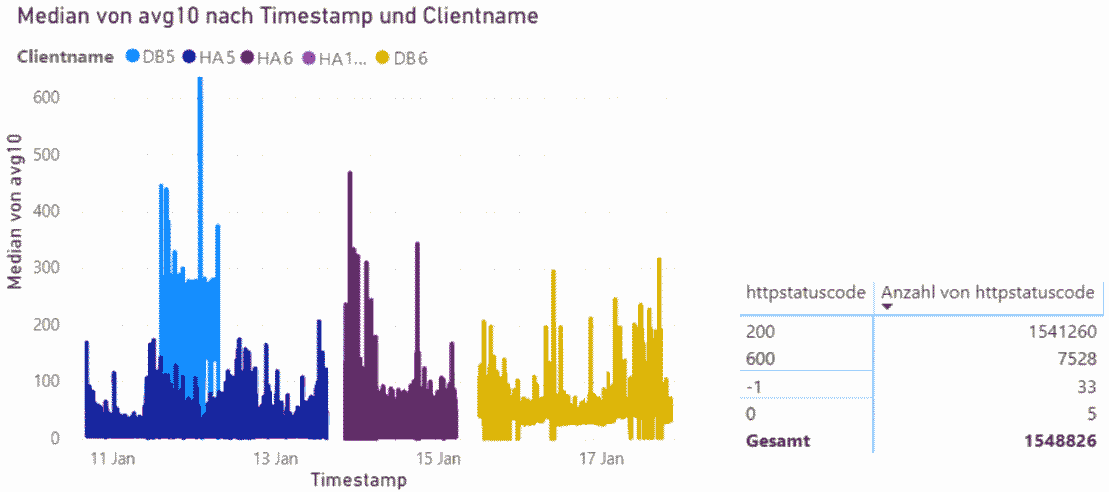
Eine weiteres Beispiel zum Einsatz von End2End-HTTP finden Sie auf der Seite Network Assessment:Grundlastmessung
Download
Der Code ist ein einfaches PowerShell-Script, welches keine weiteren externen Abhängigkeiten hat. Es kann von jedem normalen Anwender ohne administrative Rechte aufgerufen werden. Allerdings ist es keine "Plug and Play"-Software, die man einfach aufruft und etwas später das Ergebnis begutachten kann. Der Einsatz muss auf ihre Umgebung abgestimmt werden. Auch die Einrichtung in PRTG, die Bewertung der Ergebnisse u.a. sind beratungsintensiv. Daher nutze ich das Skript aktuell noch im Rahmen von Projekten bei Kunden. Es ist auch noch sehr früh in der Entwicklung und muss erst noch ein paar Wochen im Feld sich beweisen. Zudem macht es so alleine nur bedingt Sinn. Man misst damit quasi eine "leere" Leitung. Sie benötigen also immer noch ein Modul zur Simulation von Last.
end2end-http.ps1.txt
Mindestvoraussetzung ist PowerShell 3.0 wegen
Invoke-WebRequest
Sie können das Skript einfach herunterladen und ausführen. Es prüft alle Sekunde die favicon.ico und gibt einen Status auf dem Bildschirm aus.
Microsoft 365 Gegenstellen
Ein End2End-Check muss natürlich gegen einen WebServer gehen, der idealerweise anonym erreichbar ist, um im Skript keine Anmeldedaten zu benötigen. Zudem sollte die andere Seite kein Problem mit den andauernden Anfragen haben. Webhoster und Cloud-Anbieter können durchaus solche "regelmäßige Muster" erkennen und Gegenmaßnahmen einleiten. Ein gezieltes Drosseln würde nur ihre Messung stören aber eine temporäre Blockade ihres Subnetzes oder gar des Providers würde schon Auswirkungen auf den Betrieb haben.
Für die Nutzung der vorgestellten URLs übernehme ich keine Haftung.
Folgende URLs sind aber gute Kandidaten. Microsoft stellt selbst auch ein paar "erreichbare" Adressen bereit, die als Gegenstelle genutzt werden können:
- Manage connection endpoints for Windows
10 Enterprise, version 1809
https://docs.microsoft.com/en-us/windows/privacy/manage-windows-1809-endpoints
| URL | Größe | Beschreibung |
|---|---|---|
https://outlook.office365.com/owa/favicon.ico |
7kB |
Bei Favorit ist natürlich das kleine Icon in der Browser-Zeile, wenn Sie auf Outlook Web Access zugreifen. |
https://graph.microsoft.com/v1.0/$metadata |
1MB |
Graph liefert eine recht große XML-Datei mit den Metadaten zu den verfügbaren Schnittstelen anonym aus. Die Größe wird sicher wachsen, wenn Graph von Microsoft erweitert wird |
https://graph.microsoft.com/beta/$metadata |
2,7MB |
Die Beta-Informationen sind schon deutlich größer |
http://ipv6.msftconnecttest.com/connecttest.txt http://www.msftconnecttest.com/connecttest.txt http://www.msftconnecttest.com/redirect |
22 Byte |
Diese URLs werden von Windows und Browsers abgefragt, um die Erreichbarkeit des Internets zu ermitteln. |
https://outlook.office365.com/owa/healthcheck.htm |
NA |
Dieser Zugriff hat früher immer noch funktioniert und man konnte damit im HTT-Header auch den FQDN des Frontend-Servers ermitteln. Das geht aber seit ca. 2020 nicht mehr. |
https://outlook.office365.com/owa/smime/owasmime.msi |
729kB |
Das SMIME Installationspakete ist anonym erreichbar und mit 729 KB groß genug für einfache Belastungstests |
https://login.microsoftonline.com/common/oauth2/authorize |
140kB |
Eine recht umfangreiche HTML-Seite |
https://%tenantname%.sharepoint.com/ https://%tenantname%.sharepoint.com/_layouts/15/SPAndroidAppManifest.aspx https://%tenantname%.sharepoint.com/_layouts/15/images/spmobileandroidappicon.png https://%tenantname%.sharepoint.com/_layouts/15/blank.js https://%tenantname%-my.sharepoint.com/ |
|
Diese URLs sollten alle von einem Frontend-Server geliefert werden, die zu ihrem Tenant gehören. Teilweise liefern Sie auch Metadaten mit Siehe auch End2End-SharePoint |
https://%tenantname%.crm4.dynamics.com/_static/Tools/Diagnostics/smallfile.txt |
12 Byte |
Einfache Test-URL für Navision CRM. Es liefert als Payload neben dem HTTP-Header nur ein "latency test"-String.
|
mscrl.microsoft.com crl.microsoft.com ocsp.msocsp.com www.microsoft.com |
|
Die CRL-Punkte sind eigentlich immer gut zu erreichen aber ohne Parameter bekommt man einen HTTP 400 Fehler. Für eine Zeitmessung reicht es aber schon. |
https://aadap-portcheck-seaus.connectorporttest.msappproxy.net https://watchdog.servicebus.windows.net |
|
Diese URLs habe ich bei verschiedenen Analysen von Tools gefunden, Sie reagieren aber nicht immer und sind nicht sehr verlässlich. zudem wissen wir nicht, wo der Server physikalisch steht. |
https://login.windows.net https://login.microsoftonline.com |
178kB |
Diese allgemeinen Windows Anmelde-URLs dürften immer sehr nahe zum Client sein und daher sehr schnell antworten. |
https://outlook.office365.com/autodiscover/metadata/json/1 |
6,3kb |
Metadaten für Exchange Online Autodiscover OAUTH2. Liefert u.a. auch auf das "Microsoft Exchange Server Auth Certificate" |
https://autodiscover.<domain>.de/autodiscover/metadata/json/1 |
1,6k |
Metadaten für Exchange On-Premises Autodiscover OAUTH2. Liefert u.a. auch auf das "Microsoft Exchange Server Auth Certificate" |
https://<domain>.sharepoint.com/_layouts/15/metadata/json/1 |
3,4k |
Metadaten für SharePoint OAUTH2. Liefert u.a. auch auf das "Microsoft Exchange Server Auth Certificate" |
"https://accounts.accesscontrol.windows.net/<tenant>.onmicrosoft.com/metadata/json/1" "https://login.windows.net/<tenant>/federationmetadata/2007-06/federationmetadata.xml" |
21kB |
Federation Metadata für Exchange Hybrid OAUTH |
https://status.aws.amazon.com/ |
5,7 MB ! |
Auch andere Cloud-Dienste kann man
einfach anzapfen. |
- Manage connection endpoints for Windows
10 Enterprise, version 1809
https://docs.microsoft.com/en-us/windows/privacy/manage-windows-1809-endpoints
Andere Gegenstellen
Sie können per HTTPS natürlich jegliche andere Gegenstelle abprüfen. Allerdings sollten sie nicht erwarten, dass dies unbemerkt bleibt. Wenn sie, was naheliegend ist, einfach jede Sekunde mal die Google-Suche abprüfen, dann geht das einige Zeit gut aber irgendwann sehen Sie Anwender ein Captcha mit einer Warnung in der Suchmaske:

Allzu viele regelmäßige Anfragen von der gleichen Source-IP nach einem festen Muster können aber durch Analyse-Tools erkannt und sogar blockiert werden. Sie sollten es also nicht übertreiben oder einen Weg suchen der von der anderen Seite nicht als bösartig angesehen wird. Die IP-Adresse hier gehört zufällig zu "Zscaler", über die sehr viele Kunden vermutlich auch Google nutzen und Google hat diese Adresse wohl noch nicht ausreichend "gelernt".
Applikationsperformance
Mein einfaches PowerShell-Skript kann einfach nur HTTP-Anfragen an eine vorgegebene URL absetzen und die Zeit messen. Eine komplettes "Application Experience Monitoring" ist damit natürlich nicht möglich und auch nicht das Ziel. Aber es kann natürlich sein, dass Sie genau das haben wollen, z.B. indem ein Skript automatisiert auf eine Webseite geht, sich anmeldet, einen Button drückt u.a. und am Ende die Zeit für die einzelnen Schritte misst. Solche Programme und Skripte gibt es natürlich simulieren einen Browser oder steuern einen Browser fern. Sehr schnell verlassen sie hier aber die Eigenbaulösungen mit PowerShell und sie nutzen fertige Frameworks. Diese Funktionen sind aber automatisierbar und wiederholbar und eignen sich nicht nur zum Performance-Monitoring der Applikation sondern auch generell zur Funktionsüberwachung.
Andere Ansätze nutzen den Browser selbst, indem der Anwendungsentwickler entsprechenden Code einbaut, der die Ladezeiten und Anzeigeverzögerungen beim Client misst und meldet. Solche Telemetrie-Funktionen sind gängige Praxis. Wieder andere Tools liefern ein Plugins für den Browser, um das Verhalten einer fremden Applikation anhand der Ladezeiten zu erfassen. Diese Lösungen funktionieren natürlich nur, wenn der Anwender auch mit der Applikation arbeitet. Die Überwachung ist dann nicht lückenlos.
- Last Mile Telemetrie
- Digital Experience von Cloud-Anwendungen
https://www.netcor.de/performance/digital-experience
Offen
Ein Skript ist nie fertig und auch End2End-http wird kontinuierlich weiter entwickelt und erweitert. Wünschenswert fände ich noch:
- Ermitteln der eigenen Client-IP und des
Default Gateway
um z.B. Netzwerkwechsel in den Logs mit zu bekommen - Mittelwerte von Applikationswerten
Mittlerweile erfasst End2End-HTTP auch die SharePoint Performance Header aber macht noch keine Mittelwerte in die Summary.CSV
Es fehlt noch eine Beschreibung, wie man den Job als "Geplanter Task" einstellt und natürlich sollte das Skript einen Blick auf die Größe der CSV-Datei legen und ggfls. alte Versionen löschen, da eine 24h Aufzeichnung gerne bis zu 7 Megabyte/Tag groß wird.
Weitere Links
- End2End-SharePoint
- Last Mile Telemetrie
- Ende zu Ende Monitoring
- End2End ClientCheck
- End2End EWS
- PRTG Bandbreite
- PRTG - HTTP Push-Sensoren
- PowerShell und Taskplaner
- End2End-SharePoint
-
Exchange Function to Test MRSProxy Endpoint
Authentication
https://www.undocumented-features.com/2021/04/15/exchange-function-to-test-mrsproxy-endpoint-authentication/ -
Manage connection endpoints for Windows 10
Enterprise, version 1809
https://docs.microsoft.com/en-us/windows/privacy/manage-windows-1809-endpoints -
Cachefly 10 MB Testdatei
http://cachefly.cachefly.net/10mb.test -
CloudHarmony
https://cloudharmony.com/speedtest-for-aws
Auch andere Firmen bieten "Cloud Performance Tests" an. Allerdings aus ihrem DataCenter zu den Cloud-Diensten













