
End2End Werte
Meine End2End-Skripte erfassen die Performance von Diensten und um dies möglichst detailliert zu machen, prüfe ich nicht nur alle paar Minuten die Erreichbarkeit wie dies klassische Lösungen (Nagios, PRTG, Icinga, Hostmon etc.) machen, sondern viel häufiger. Damit produziere ich natürlich auch viel mehr Ergebnisse. Um aus all diesen Zahlen sinnvolle Aussagen zu erhalten, habe ich mir Gedanken machen müssen.
Klassisches Monitoring
Wenn Sie heute über "Netzwerküberwachung" nachdenken, dann finden sie immer Produkte, die per SNMP die Router und Firewalls abfragen. Das machen diese z.B. alle Minute oder sogar nur alle 5 Minuten. Heraus kommt eine Tabelle in der Form:
"Timestamp","paketIn","packetOut","ByteIn","ByteOut" "2019-12-18 14:25:01Z","231","31","343111","143445" "2019-12-18 14:26:01Z","2341","231","7434","12343445" "2019-12-18 14:27:01Z","122","131","7434574","1223445" "2019-12-18 14:28:01Z","634","332","125423","1234235" "2019-12-18 14:29:01Z","34","64","25822","22354" "2019-12-18 14:30:01Z","9876","361","34456","3323445" "2019-12-18 14:31:01Z","343","81","998533","12344" "2019-12-18 14:32:01Z","734","141","854565","123479"
Wenn Sie diese Werte in eine Grafik umsetzen, die nur 10 Minuten als X-Achse hat, dann sehen sie diskrete Messwerte. Wenn ich aber einen ganzen Tag damit abbilde, dann habe ich mit 60Minx24h=1440Messwerte eine lückenloste Grafik, wie Sie hier als Beispiel abgebildet ist:

Das ist z.B. eine 100MBit Leitung im Jahr 2023, deren Belegung auf den ersten Blick sehr gering ist. Das System erfasst jede Minute die Auslastung, indem es die Pakete In/Out und Bytes In/Out ausliest und in der Grafik anzeigt. Dieses Monitoring liefert eher eine generelle "Uptime"-Überwachung und Volumenangaben aber natürlich keine Informationen über Latenzzeiten. Die "Peak" von knapp 100MBit sind auch oben zu sehen aber der Average ist weniger als 10 MBit.
Die Einschränkung ist hier aber schon leicht zu erklären, denn dummerweise dauern Engpässe auf einer WAN-Verbindung nicht mehrere Minuten sondern manchmal nur wenige Sekunden. Wenn hier eine Leitung z.B. 10 Sek auf 100% Last ist und die restlichen 50 Sek wieder bei 20% liegt, dann sind das über 1 Minute auch nur 40%. Keine Zahl, bei der man Alarm schlagen würde aber das wäre falsch.
Dass ein Mittelwerte noch weiter in die Irre führen kann, sehen Sie z.B.: bei einem größeren Wertebereich. Wenn ich die gleichen Werte nun über eine Woche ausgeben lasse, dann scheint die Leitung sogar noch weniger belastet zu sein.
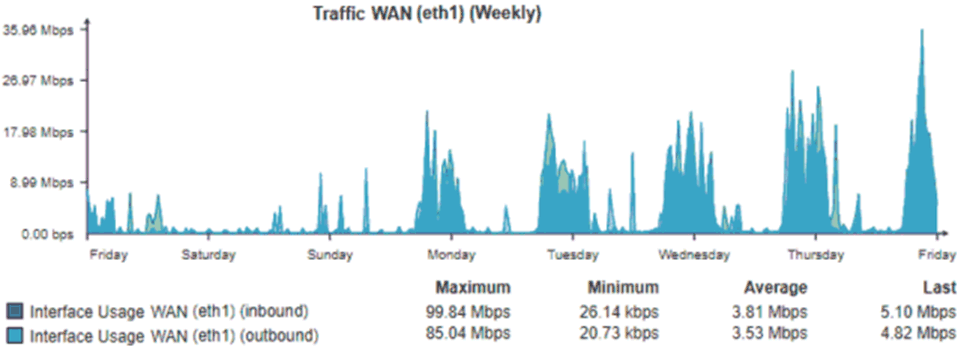
Wer nur die Grafik betrachtet, könnte den Peak bei 35Mbit dazu verleiten, dass die 100 MBit-Leitung doch gar kein Problem habe. Auch alle anderen Werte sind durch die "Mittelung" ebenfalls niedriger angegeben. Nur im Text steht das Maximum der Woche, wobei diese einzelne Zahl nichts sagt, ob dies ein einmalige Maximum war, was ja immer mal auftreten kann. Anstatt das Maximum von allen Werten zu liefern, wir hier ein Percentil interessanter, z.B.: bei wieviel MBit eine gewisse Anzahl, z.B.: 95/99% darunter liegen.
Engere Intervalle und Datenmenge
Wenn aber nun eine Messung pro Minute nicht ausreicht, dann stellt sich automatisch die Frage nach dem richtigen Intervall. Mit End2End-HTTP und End2End EWS u.a. habe ich einfach nur jede Sekunde gemessen und die Daten in eine CSV-Datei geschrieben. Das bedeutet natürlich mehr Last für das abfragende System aber auch das Netzwerk und die Gegenstelle. Zudem habe ich jede Messung natürlich mit Zeitstempel etc. protokolliert. So habe ich dann ca. 100 Bytes/Sekunde in ein Log-File geschrieben, was bei einem 24h Betrieb aber auch "nur "86400 "Zeilen" a 100Bytes = 864 Kilobyte erzeugt. Das sind wirklich keine Datenmenge, die mich erschrecken sollten. Erst wenn viele Clients viele Tests machen und alle Daten konsolidiert werden, dann ist diese Genauigkeit vielleicht nicht mehr sinnvoll.
Ich habe nun ausreichend Messpunkte, um zu jeder Sekunde des Tages den momentanen Status zu lesen. Mit der passenden Auflösung sehe ich jede einzelne Messung und sogar Aussetzer, weil das Schreiben der Ergebnisse etwas Zeit gedauert hat und damit die Messung bei einem sequentiellen PowerShell-Skript pausiert wurde.
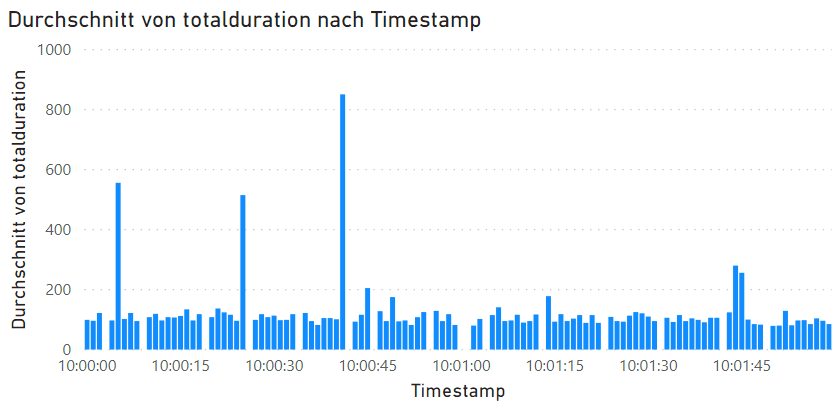
Es sind auch die Peaks in dieser Zeitspanne zu sehen. Allerdings sehe ich hier auch nur ein Intervall on ca. 2 Minuten und müsste nun ganz viele Abschnitte überprüfen. Das macht keinen Sinn. Sobald ich aber einen größeren Abschnitt anzeige, meldet mir hier PowerBI schon, dass er eine "repräsentative" Stichprobe anzeigt.
- High-density line sampling in Power BI
https://docs.Microsoft.com/en-us/power-bi/desktop-high-density-sampling
Die Frage stellt sich nun, wie aussagekräftig dann eine so zusammengefasste Anzeige ist

Je länger der Zeitraum ist, desto mehr Messwerte werden irgendwie zusammengefasst. Wenn ich nun eine Grafik eines Tages aus 86400 Datenpunkten erstelle, dann ist die zwar sehr "dicht" aber die wichtigen Informationen ersaufen sprichwörtlich darin. Kleinen Peaks gehen unter, wenn so ein Tag auf einer Grafik abgebildet werden. Bei 1000 Pixel Breite werden ja 86 Werte zusammengefasst. Wenn ich wirklich jeden Tag 86400 Messwerte erhalte, dann ähnelt es schon der Suche einer Nadel im Heuhaufen, wenn da z.B.: immer mal wieder Aussetzer für einige Sekunden gibt.
Selbst wenn ich jede Stunde einzeln betrachte, wären es immer noch 60x60 =3600 Messwerte und eine Grafik mit 800px Breite müsste vier Werte zusammenfassen. Ich müsste im Umkehrschluss aber 24 Mal so viele Bilder betrachten. Ich denke das Problem ist verständlich.
Das Ziel liegt eher in der Richtung, dass das Skript über einen überschaubaren Messzeitraum von z.B. 60 Sekunden eine Aussage über das Netzwerk im Stiel einer Benotung "Sehr Gut, Gut, Mittel, Schlecht" oder Farbampel (Rot, Gelb, Grün) macht und bei späteren Zusammenfassungen z.B. die Anzahl gezählt wird.
Ich habe alternativ auch noch mal die Latenzzeiten auf die X-Achse und die Anzahl der Vorkommen auf die Y-Achse aufgetragen und sieh sehen hier, dass die meisten Anfragen schon im Bereich 70-150ms sind.
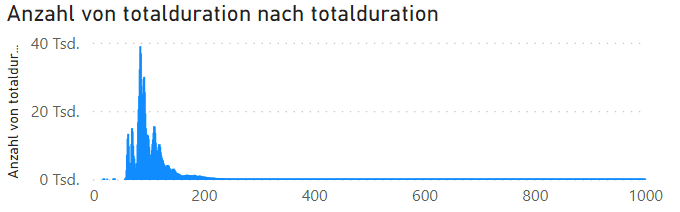
Die X-Achse kann man auch noch mal strecken, so dass die Wert von 0-200ms deutlicher dargestellt werden
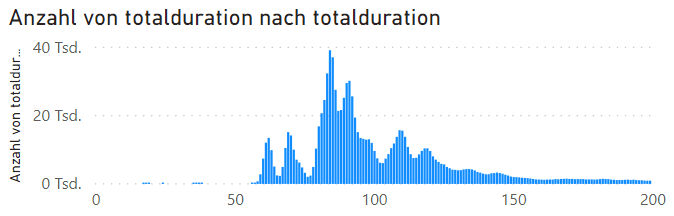
Das ist aber nun keine schöne Verteilung deren Ursache ich aber auch einfach erklären kann. Ich habe alle Messwerte einer Serien von 7 Tagen hier in eine Grafik gepackt. Es gibt hier also Messungen bei mir zuhause (DSL 100), in Gästenetzwerken von Kunden und im Firmennetzwerk. Insofern überlagern sich hier mehrere Messungen. Ich darf bei einer Auswertung also nicht zu viele Messwerte zusammen werfen oder ich muss die Netzwerkwechsel erkennen. Aber Sie können hier auch sehen, dass es auch "unmöglich" Ergebnisse geben kann, z.B. gibt es doch einige Antworten, die bei ca. 14-40ms liegen, was eigentlich nicht sein kann.
Die ganze bisherige Beschreibung bezog sich auf einen HTTP-Test, der einmal pro Sekunden geprüft hat. Wenn ich nun UDP-Pakete für VoIP messe, die alle 20ms einen Messwerte produzieren, dann sehen Sie schon wie hoffnungslos die Erfassung aber auch Darstellung solcher Daten ist. Das darf aber nicht als Argument genommen werden, nun nicht so eng zu messen. Ich muss die Datenpunkte eben nur irgendwie sinnvoll zusammenfassen.
- Wenig Verlust der Aussagefähigkeit
- Reduzierung der zu speichernden Datenmenge
- Minimierung der zu übertragenden Daten
- Robustheit gegen Ausreißer
Da ist dann eigentlich der Mathematiker mit Stochastik und Stichproben gefragt.
Min/Max/Average
Also habe ich angefangen die Messwerte schon bei der Erfassung zusammen zu fassen. Eine Auflösung bis auf die Sekunde oder sogar 20ms genau brauche ich ja gar nicht, wenn ich eigentlich nur ermitteln will, wie gut die Abfragen funktionieren und wie sich sich verändern. Also habe ich angefangen immer alle Messwerte einer Minute zusammen zu fassen und drei Werte zu bilden:
- Minimum (Min)
Der schnellste Request ist ein guter Indikator, wie schnell die Verbindung sein könnte. Bei fast allen Verbindungen hat man einmal Glück, dass sie fast unbenutzt ist. Zudem ist die Verteilung des Minimum über die Zeit interessant um die Grundlast zu messen. - Maximum (Max)
Auch die maximale Anforderung muss man im Blick behalten, da langsame Pakete die Arbeit behindern und ein deutliches Zeichen für die Überlastung sind. - Mittelwert (Avg)
Daher ist der Mittelwert aller Messungen im Intervall der aussagekräftigste Faktor. Das gilt aber nur, wenn wenige langsame Messungen nicht so extrem ausreißen, dass Sie den Mittelwert nach oben verlagern.
Diese Logik finden Sie bei einigen End2End-Skripte wie z.B. End2End-HTTP. Ich habe hier alle 60 Messungen einer Minute in einer Zeile farblich aufbereitet. Hier habe ich aber noch statisch die Farbe an der Latenzzeit festgemacht. Aber rechts können Sie für jede Zeile noch erahnen, was die Min/Avg/Max-Werte waren und dass es nach dem gelben Bereich eine Pause (Notebook im Schlafmode) gegeben hat und das neue Netzwerk am Anfang stark belastet war, ehe es dann etwas besser wurde.
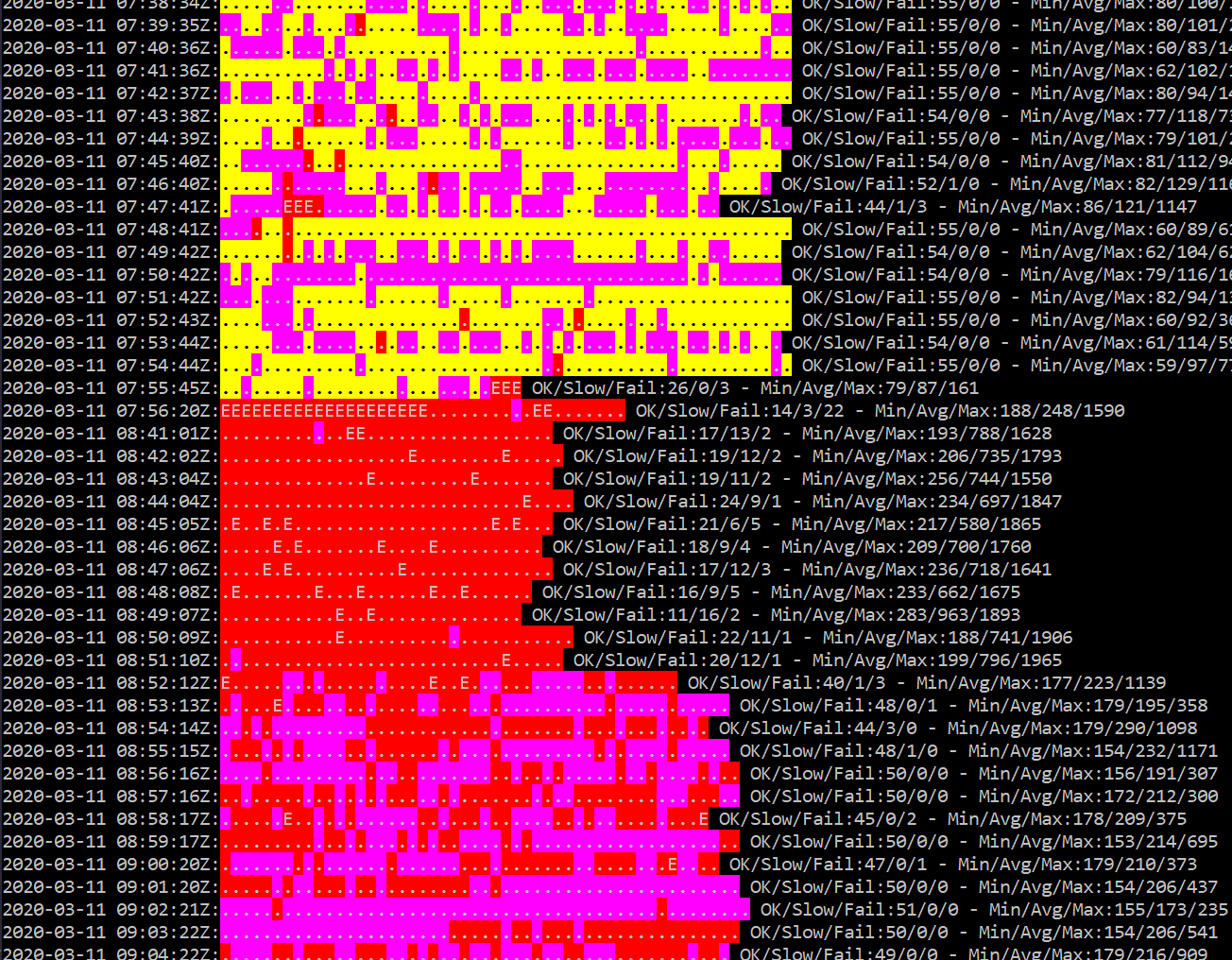
Sie sehen hier aber auch eine Ausgabe für "OK/Slow/Fail". Ich nutzen den Mittelwert und zähle die Paket als "Slow", die einen gewissen Maß über dem Mittelwert sind. Darauf gehe ich im nächsten Kapitel ein. Wenn dass Skript viele Tage läuft und die Ausgabe entsprechend klein gezoomt wird, dann können Sie sehr gut die unterschiedlichen Netzwerkstandorte sehen.






Das ist immer das gleiche Skript, welches an den Unterbrechungen einen Netzwerkwechsel erlebt hat. Selbst große gelbe Flächen haben unterschiedliche Dichten an schlechteren violetten Tests. Sie sehen aber auch Bereiche, die lange violett sind, was eine temporäre Überlastung darstellt. Ganz rechts sehen Sie dann ein sehr flottes Netzwerk, welches aber einen roten Bereich hat. Theoretisch könnte ich nun jede Messung als einen "Pixel" in einer Grafik anzeigen. Ein Bild mit 500x1000 Pixel könnte so 500.000 Messwerte unterbringen. Die Frage ist nur, welche Aussagekraft hierüber dann möglich wäre. Einzelmessungen sind gut aber wir müssen die Daten zusammenfassen.
Die Berechnung eines Mittelwerts ist natürlich naheliegend. Aber auch hier ist eine Interpretation der Daten wichtig, denn das langsamste Paket (max) ist nur ein partieller Indikator, wenn man nicht weiß, wie viele weitere Paket relativ langsam sind. Ein Regentropfen sagt eben auch noch nichts über das Wetter aus. Ich berechne das mal mit 10 Messwerten.
20,22,23,25,26,26,50,75,80,4999
- Min = 20
- Mittelwert = 846
- Max = 4999
Ich weiß mit meinen drei ermittelten Werten also doch nicht so viel über die Qualität. Ich weiß vor allem nichts über die Verteilung. So reicht ein Ausreißer, um den Mittelwert und das Max stark zu überhöhen. Ich könnte nun sagen, dass jede Messung, die z.B. über 1 Sek dauert einfach "zu langsam" ist und auf 1000ms gesetzt wird. Das würde dann aber bei den Tests nicht funktionieren, die wirklich länger dauern. Ich könnte auch dazu übergehen, die schnellsten und langsamsten Pakete zu ignorieren um viele dieser Fehler zu unterdrücken. Reicht es dann aber nur den einen Messwerte an der unteren und oberen Skala zu entfernen sollte sollte ich 2 oder 3 Werte wegstreichen?. Je mehr ich als ungeeignet verwerfe, desto weniger echte Aussetzer bleiben im Spiel.
Ein Mittelwert ist aus meiner Sicht nicht das passende Kriterium einer Leitung, da Burst-Ausfälle unsichtbar werden, je mehr Messwerte zusammengefasst werden. Aber es sind genau die Aussetzer von Sekunden (VoIP) oder Minuten (SharePoint etc.), die etwas über die Qualität der Leitung aussagen.
Schlafmützen zählen
Wenn Min/Avg/Max nicht ausreichen, um die Qualität einer Verbindung einzuschätzen, dann muss ich andere Werte daraus herleiten. Eine gute Leitung hat ja durchaus viele schnelle Pakete. Interessant ist aber der Vergleich unterschiedlicher Anbindungen über den Mittelwert. Aber störend sind Aussetzer oder Einbrüche, auch wenn diese nur wenige Sekunden dauern. Daher habe ich erst mal ohne höhere Mathematik überlegt, wie ich die schlechten Pakete besser erfassen kann. Anders als bei Wahrscheinlichkeitsrechnungen mit Würfeln und Lottozahlen kann ich hier ja nicht einfach mit einer Normalverteilung arbeiten.
Als erste Näherung habe ich dann die Anzahl der Anfragen gezählt, die "zu langsam" sind. Nur was ist genau "zu langsam"?. Einen statischen Wert kann ich nicht nehme, da es ja unterschiedliche Standorte mit unterschiedlichen Entfernungen gibt. Zudem ist die Latenzzeit auch von der Belastung des Netzwerks abhängig, da Pakete dann an Routern vielleicht länger in Warteschlangen warten müssen. Die Belastung eines Netzwerks ist aber fast immer auch von der Tageszeit abhängig. Nachts arbeiten meist weniger Anwender aber dafür können Systemprozesse punktuell die Last verändern. Zuletzt ist auch der Test selbst relevant, denn ein Ping ist schneller als ein HTTPS-Download einer größeren Datei. Fixe Werte für "Gut/Schlecht" sind also nicht geeignet.
Ich habe dann angenommen, dass der Mittelwert ein sehr guter Indikator für die durchschnittlicher Latenzzeit ist. Er sollte recht genau sowohl das Lastverhalten auf der Verbindung wiederspiegeln als auch die Entfernung einbeziehen. Das gilt natürlich nur, wenn viele Pakete etwas gleich schnell sind und nicht einige Ausreißer den Mittelwert übermäßig nach oben heben. Ein Paket, welches "zu langsam" ist, muss also einfach deutlich langsamer als der Mittelwert sein. Wenn normale Pakete zwischen 20-100ms schnell sind, dann würde ich ein Paket mit einer mehr als zehnmal so langen Laufzeit auf jeden Fall als auffällig bezeichnen. Das ist natürlich keine perfekte Abbildung der individuellen Netzwerksituation aber ich habe mir dabei gedacht, dass für normale HTTP-Anforderungen es keinen großen Unterschied macht, wenn die Pakete halbwegs flott unterwegs sind. Ich möchte aber sehr wohl wissen, ob es viele langsame Pakete gibt und nicht nur das eine langsamste messen.
Dieser Wert hat mir tatsächlich mehr Informationen geliefert als das nackte Maximum einer Stichprobe. Allerdings fehlt hier auch noch eine "Burst"-Erkennung, d.h. in welcher Häufung die Pakete hintereinander kommen. Das wäre für VoIP besonders wichtig, da Burst hörbar sind. Für normale Datenverkehre heben viele "langsame Pakete" den Mittelwert dieser Messung an und verraten so indirekt mehr Problempakete. Dumm nur, dass durch die Anhebung des Mittelwerts natürlich auch die Schwelle zur Erkennung eines "langsamen Pakets" angehoben wird und damit der Wert "Anzahl" vielleicht weniger Pakete erfasst. Eine Stichprobe mit einem hohen Mittelwert hat damit auch weniger "Schlafmützen"-Einträge. Ein Administrator könnte sogar glauben, dass alles gar nicht so schlimm sei.
Wenn aber der Durchschnitt mit 200ms schon recht hoch ist, dann sind 10x 200ms = 2 Sek als Grenze für "langsame Pakete" schon viel zu hoch gesetzt. Eigentlich sollte jeder Request maximal 1 Sekunde dauern, es sei denn die Datenmenge ist sehr hoch. Also muss da auch diese Abhängigkeit noch mit rein. Generell stellt sich dann die Frage, ob der Faktor 10 so günstig gewählt ist. Wenn der Mittelwert an sich schon hoch ist, z.B. bei 300ms, dann werden erst Pakete gezählt die länger als 3 Sekunden unterwegs sind. Das ist im realen Betrieb keine akzeptable Verzögerung und muss deutlicher auffallen, als wenn bei einer 50ms Leitung Pakete mal 500ms unterwegs sind. Die Logik sollte weiterhin sich an einer variable durchschnittliche Verbindung orientieren aber auch 1 Sek ist aus meiner Sicht zu langsam.
Ein Paket, welches einmal komplett um die halbe Welt reisen muss, kann dies in 150-200ms schaffen. Signallaufzeiten in Glasfaser sind nun mal ca. 69% langsamer als Lichtgeschwindigkeit im luftleeren Raum. Etwas Zeit geht noch auf dem Router und Switch verloren aber die meiste Verzögerung kommt letztlich durch die Warteschlangen vor einer belasteten Leitung. Wenn ein andere Paket übertragen wird, muss das nächste Paket eben etwas warten. Dennoch lege ich für mich erst mal fest, dass jedes Paket über 1000ms einfach viel zu langsam ist. Für kleine VoIP-Pakete ziehen wir die Grenze sogar eher bei 100-200ms. Bei TCP-Paketen und erst recht bei HTTP-Übertragungen muss man bedenken, dass die Pakete größer sind, der TCP-Handshake und eventuell ein TLS-Handshake dazu kommt. Allein der Mittelwert und die Maximalwerte oder Anzahl der Maximalwerte reicht ja nicht aus.
Zudem nimmt so ein einfacher Graph nicht darauf Rücksicht, dass die Verteilung nicht linear ist. Die Dauer kann ja nie negativ sein und selbst sehr kurze Werte sind unrealistisch. Es gibt also eine Untergrenze der Werte die nicht 0 ist. Nach oben kann ein Paket aber auch theoretisch viele Sekunden unterwegs und erfolgreich sein. Das hilft nur dem Anwender nicht weiter, so dass man auch Pakete über einer gewissen Zeit einfach pauschal als "unakzeptabel" bewerten kann.
Mittelwert und Median
Bei sehr vielen Messungen in kurzen Intervallen ist es nicht möglich, alle Messwerte dauerhaft zu speichern. Wenn ich z.B.: bei End2End-UDP3478 auf 50 Messungen/Sekunde und damit auf ca 3000 Messwerte/Minute komme, dann muss ich Zusammenfassen. Der erste Ansatz geht hier natürlich einfach zum "Mittelwert", d.h. ich addiere alle Werte auf und Teile durch die Anzahl. Stellen Sie sich nun folgende Reihe aus 4 Werten vor:
20,10,30,100
Der Mittelwert errechne sich darauf wie folgt:
20+10+30+100 = 160 und dann 160/4 = 40
Bei Messungen von Laufzeiten in Netzwerk ist die Menge leider nicht symmetrisch, d.h. wenn ich Werte zwischen 0 und 100 messe, dann kann ein Mittelwert geeignet sind. Wenn ich aber Werte zwischen z.B. 10ms und 2000ms erwarte und die meisten Ergebnisse sich zwischen 10ms und 100ms bewegen, dann verfälschen wenige Ausreißer den Mittelwert. Die Problematik gibt es auch in anderen Stichproben und daher gibt es noch eine andere Berechnung. Man nimmt den "Median" der einfach alle Ergebnisse in eine Reihe sortiert und dann die "Mitte" nimmt.
10 ! 20 ! 30 ! 100 Median = 25
Es macht in dem Fall quasi keine Unterschied, ob Ausreißer ob nun 100, 200 oder ca. 1000ms unterwegs sind. Der Median ist "robuster" gegen solche Abweichungen in beide Richtungen. Es ist aber immer noch ein "Mittelwert" aber sagt z.B. nicht über die "Verteilung" der Einzelergebnisse aus.
Das Statistisches Bundesamt hat in 2025 z.B. eine Grafik zum "Durchschnittseinkommen publiziert
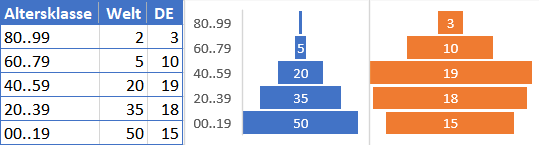
Quelle: Statistisches Bundesamt 2025, Daten von 2024
Der "Durchschnitt" wird hier durch wenige Einkommensmillionäre deutlich nach oben verschoben und verfälscht die Aussagekraft. Der Medien gibt viel besser wieder, über welches Einkommen im Mittel die Bürger verfügen. Vor allem lassen sich so einfacher Veränderungen über die Jahre bewerten, denn in 2024-2025 haben gerade die "Reichen" noch einmal richtig ihr Einkommen erhöht.
Quantile/Percentile
Beim Monitoring im IT-Umfeld ist es eigentlich nur wichtig, ob es "schnell" genug ist. Die Einzelmessung sollte dabei nicht komplett untergehen und ein Trend muss erkennbar sein aber der Mittelwert ist weniger interessant.
Beim Lesen eines Artikels über die Gehälter von IT-Personal wurde ich auf eine andere Kennzahl aufmerksam. Hier kann man einen Mittelwert bilden aber interessanter sind hier ja die Bandbreiten bzw. genauer die Spreizung der Einkommen. In einer Stichprobe gibt es mehrere Personen mit unterschiedlichem Einkommen. Auch hier sagen die Spitzenverdiener und das arithmetische Mittel nur sehr wenig über die Gehaltsverteilung aus.
Ein anderes Beispiel ist das Alter der Bevölkerung. Wir setzen viele "alte Menschen" in einem Staat mit einer hohen Lebensqualität gleich und in Entwicklungsländern sterben viele Menschen jung und es könnte eine Kennzahl für den Entwicklungsstand eines Landes sein. Wenn ich aber nur "Min/Max/Avg" und z.B. "Anzahl der >80 Jährigen messe, dann habe ich dennoch nur einen sehr engen Überblick über die Altersverteilung. Wir kenne ja alle die "Alterspyramide", d.h. die Anzahl der Personen in einer Altersklasse und dass wir in Deutschland keine Pyramide mehr haben.
- Altersstruktur
https://de.wikipedia.org/wiki/Altersstruktur
https://de.wikipedia.org/wiki/Medianalter - Durchschnittsalter
https://de.wikipedia.org/wiki/Durchschnittsalter
Das Durchschnittsalter ist ein Fachbegriff aus der Bevölkerungswissenschaft (Demografie). Es beschreibt das durchschnittliche Lebensalter eines definierten Personenkreises als arithmetisches Mittel des Alters aller Personen dieser Population zu einem bestimmten Zeitpunkt - Medianalter
https://de.wikipedia.org/wiki/Medianalter
Das Medianalter ist das mediane Lebensalter der Individuen einer Bevölkerung. Es ist also jenes Lebensalter, das die beobachtete Gruppe so teilt, dass höchstens 50 % ihrer Mitglieder jünger und höchstens 50 % älter sind als dieses Lebensalter. Es wird als Kennzahl benutzt, um die Alterung der Bevölkerung z. B. eines Staates zu beschreiben. - Die 20 Länder mit dem höchsten Durchschnittsalter der
Bevölkerung im Jahr 2020
https://de.statista.com/statistik/daten/studie/242823/Umfrage/laender-mit-dem-hoechsten-durchschnittsalter-der-bevoelkerung/
Ich mache mal ein sehr einfaches Beispiel mit 5 Altersklassen:

Das jüngste Alter (Min) ist bei beiden Fällen "<1Jahr" und das höchste Alter (Max) irgendwo bei 80-99 Jahren. Dass die Verteilung aber ganz anders ist, kommt bei den Werten nicht zum Ausdruck. Erst beim arithmetischen Mittelwert könnte man sehen, dass der bei "Welt" natürlich niedriger ist. Aber der arithmetischen Mittelwert hilft nicht immer, was ich an der folgenden theoretischen "Altersreihe" zeigen will:
| Standard | Quantil/Percentile | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Reihe | Alter von 10 Personen als Reihe | Min | Avg | Max | 50% | 75% | 90% | 95% | 99% | |||||||||
A |
1 |
2 |
4 |
13 |
20 |
25 |
30 |
40 |
50 |
90 |
1 |
27,5 |
90 |
22,5 |
37,5 |
54 |
74 |
87,2 |
B |
1 |
1 |
2 |
8 |
9 |
10 |
11 |
63 |
80 |
90 |
1 |
27,5 |
90 |
9,5 |
50 |
81 |
86 |
89,3 |
Es ist natürlich unrealistisch, dass eine Bevölkerung zu 70% aus Minderjährigen und 3 Senioren besteht. Aber gerade das zeigt, dass die Messwerte für "Min/Avg/Max" (Grün) bei beiden Messreihen gleich sind.
Interessant wird es aber nun, wenn man den Wert pro Reihe sucht, bei der 50%/75%/90%/95%/99% der Personen unter dem Wert liegen.
- 50% Quantil
Sie sehen schon den Unterschied zwischen diesen Werten und dem arithmetischen Mittelwert "Avg". Dieses Alter ist die Trennung der Probe in der Mitte, d.h. 50% der Personen sind jünger und 50% älter - 90% Quantil
Auch hier ist der Abstand der beiden Wert deutlich zu sehen, d.h. bei Reihe A sind 90% der Personen unter 54 Jahren und damit 10% über 54 Jahren. Bei Reihe B liegt diese 90% Grenze bei bei 81 Jahren. Es gibt also viel mehr Personen im oberen Bereich.
Hier noch ein paar Links zu den Berechnungsgrundlagen:
- Berechnen des Medians einer Gruppe von Zahlen
https://support.office.com/de-de/article/berechnen-des-medians-einer-gruppe-von-zahlen-2e3ec1aa-5046-4b4b-bfc4-4266ecf39bf9 - Rechnet die Excel-Funktion QUANTIL richtig?
https://clevercalcul.wordpress.com/2019/08/27/rechnet-die-excel-funktion-quantil-richtig/ - Die statischen Excel-Funktionen QUANTIL.INKL
und QUANTIL.EXKL
https://clevercalcul.wordpress.com/2017/10/17/die-statischen-excel-funktionen-quantil-inkl-und-quantil-exkl/
Bei meinen End2End-Tests geht es nun natürlich nicht um "Alter" aber um Latenzzeiten und auch hier gibt es entsprechende Verteilungen zu bewerten. Wenn ich also jede Minute oder vielleicht auch jede viertel Stunde eine Reihe von Messwerten gruppiere, dann reicht mit Min/Max/Avg eben nicht aus. Über den Percentil lässt sich viel zuverlässiger eine Qualitätsaussage ermitteln ohne die Einzelwerte genau zu betrachten.
Percentile machen natürlich nur Sinn, wenn es genug Messwerte gibt. Wer nur 10 Werte hat, wird beim 90% Percentil quasi immer zwischen Max und eins drunter landen und mit weniger Werten macht es noch weniger Sinn.
Ich habe noch ein Beispiel:
Sie betreiben eine Pizzeria mit Lieferservice und der Kunde
erwartet eine heiße und keine kalte Pizza. Maßgeblich ist
hier ja die Auslieferungszeit. Ein "Mittelwert" über diese
Dauer sagt nicht viel aus und das Max liefert nur die
langsamste Pizza ohne die Nuancen dazwischen. Wenn Sie aber
nun vorgeben, dass z.B. 5% der Kunden in weniger als 10 Min
ihre Pizza erhalten sollen, dann erfassen Sie einfach das
95% Percentil. Ist es unter 10 Minuten, dann ist alles gut.
Der erfasste Wert erlaubt ihnen sogar eine Einschätzung, wie
viele Reserve sie noch haben.
Die Pizza-Story oder Altersstruktur ist aber gar nicht mal so abweichend zu meiner Fragestellung. Auch im Netzwerk erwarte ich eine maximal Latenzzeit aber kann sie sicher nicht immer halten. Aber Max oder Mittelwert helfen nicht. Wenn ich aber erwarte, dass 99% schneller als eine bestimmte Zeit sind, dann ist das 99% Percentil das richtige Verfahren.
Wenn ich nämlich die bisherigen Grafik mit der Zeit auf der X-Achse und den Ergebnissen auf der Y-Achse transformiere, so dass die Anzahl der Ergebnisse auf der X-Achse und die Millisekunden zur neuen Y-Achse werden, dann sieht das ähnlich aus:
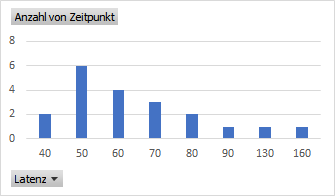

Von 60 Messwerten einer Minute kann man schnell mal den Mittelwert berechnen und davon ausgehend dann die Abstände ermitteln. Auch Min/Max ist schnell zu erfassen aber das Problem dabei ist, dass schneller als schnell nicht geht aber "viel langsamer" immer noch den Mittelwert verfälscht.
- Quartil
https://de.wikipedia.org/wiki/Quartil - https://de.wikipedia.org/wiki/Empirisches_Quantil
- https://de.wikipedia.org/wiki/Quantil_(Wahrscheinlichkeitstheorie)
-
Arithmetisches Mittel
https://de.wikipedia.org/wiki/Arithmetisches_Mittel - Percentil
https://de.m.wikipedia.org/wiki/Empirisches_Quantil#Perzentile
Percentile in Produkten
Dass ich nicht als Erster auf diese Berechnung gekommen bin, ist zu erwarten. Sie brauchen nur etwas herum zu schauen und finden entsprechende Werte an verschiedenen Stellen.
- Exchange Performance Counter

- Azure Performance
- IIS Telemetriedaten
Sie können in ihrem eigenen IISLog z.B. das Feld "TimeTaken" (Siehe Exchange Latenz und Outlook Performance) aktivieren und diese Requests dann z.B. in Wochen zusammenfassen und sowohl die Anzahl der Requests als auch die unterschiedlichen Quantile ausgeben.
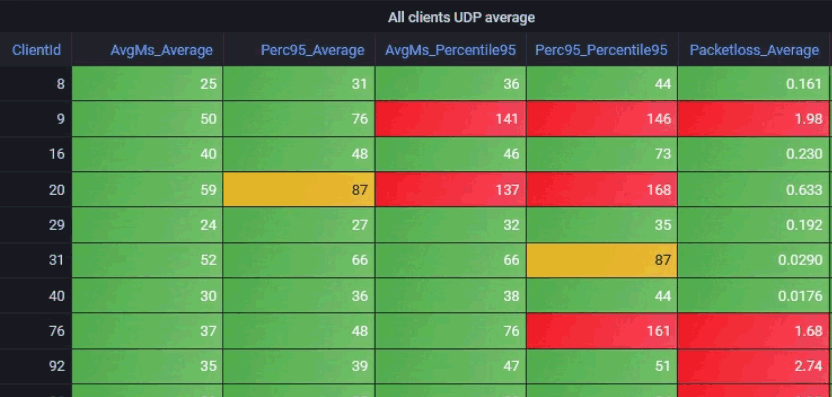
Damit bleibt natürlich immer noch die Frage, was eigentlich eine gute und schlechte Verbindung ist. Das ist aber nicht allgemein zu beantworten sondern vom jeweiligen Test abhängig. Da aber die Wert beim Quantil aber keine prozentualen Werte sind, sondern ja die gemessenen Zahlen enthalten, ist zumindest ein Vergleich zwischen den verschiedenen Werten möglich.
Querschnitt über Querschnitt
Ehe sie nun "Percentile" als das bessere "Average" bezeichnen, sollten Sie auch hie die Grenzen kennen. Bei unserer Analysen zu End2End habe ich die Daten mehrerer Clients über 24h betrachtet und wollte dabei "Problemclients" ermitteln. Das kann ich sehr gut als "Linien-Grafik" mit der Zeit auf der X-Achse und z.B. die Latenzzeit auf der Y-Achse anzeigen. Das wird aber schnell unübersichtlich, wenn ich mehrere Clients parallel sehen möchte. Zudem fallen vielleicht die wenigen "Aussetzer" gar nicht groß auf.
Wenn ich aber z.B. jede Sekunde einen "Ping" mache und mir dann das percentil95 pro Minute merke, dann habe ich 1440 Datenpunkte pro Tag. Ich möchte aber nur einen "Status" haben und dazu muss ich die 1440 Werte weiter zusammenfassen. Das "Maximum" ist viel zu sensibel aber wie ist es mit den anderen Möglichkeiten einer Zusammenfassung. Daher waren ein paar Tests erforderlich:

Die Spalten sind:
- Avgms_Average
Der Mittelwert vom Mittelwert ist auch einfach nur Durchschnitt. Alles sieht "gut" aus, weil die Problemzeiten einfach unterdrückt werden. - Perc95_Average
Dass der Percentil schon besser ist, habe ich schon weiter oben beschrieben. Ein Mittelwert über das Percentil95 scheint aber auch zu unsensibel zu sein - AvgMs_Percentil95
Ein Percentil95 über die Mittelwerte ist interessanterweise empfindlicher als der Mittelwert über den Percentil. - Perfc95_Percentil95
Diese Zusammenfassung liefert noch höhere Werte und kann mir helfen, weitere Problemclients zu ermitteln. Allerdings könnte es auch eine Übersensibilität zeigen, wenn so wird auch der Client 31 noch Gelb gemeldet, der eigentlich ganz gut aussieht.
Wir sehen aber auch, dass der Client 92 mit 2,74% Paketloss als "Average" bei keiner der vier Zusammenfassungen erscheint. Ein Paketverlust wird zwar bei der Messung zur Latenzzeit mit erhoben aber geht nicht in diese Zahlen ein. Irgendwann muss die Messung ja abbrechen aber sie darf diese Zeit natürlich nicht als "Latenzzeit" erfassen. Ein Abbruch nach z.B. 500ms darf nicht als "Latenz= 500ms" erfasst würden. So erhöht sie die gemessenen Latenzwerte nicht unzulässig aber diese Timeouts müssen separat erfasst und ausgewertet werden.
Anzahl statt Percentil
Schon beim Teams QoE-Reporting finde ich Aussagen zur "Durchschnitt" und "Maximum" für Round-Trip Time", Jitter und Paket Loss".

Das sind zwar nette Werte aber aus meiner Sicht nicht aussagekräftig, denn der Mittelwerte ist in einem längeren Meeting auch einfach nur durchschnittlich während der "Max Latenzzeit" anscheinend den einen Zeitpunkt mit dem Peak erfasst. Das kann aber auch nur einmal eine Sekunde gewesen sein und liefert mit daher keine sinnvoll nutzbare Information. Würde ich aber z.B. die Werte jeder Minute in einen Balken bringen, dann habe ich eher die Information, wann ein Client welche Qualität hat:

Allerdings ist es da nicht einfach, die kleinen roten und gelben Abschnitte mit Problemen zu finden. Daher könnte auch eine andere Ansicht hilfreich sein, bei der die Anzahl der Messungen nach dem Problem gruppiert wird.
Sie wird sehr schnell deutlich, wie viele Anteile einer Verbindung "schlecht" sind. Voraussetzung ist natürlich, dass man auch den Begriff "Warnung" und "Schlecht" entsprechend definiert hat, denn die individuellen gemessenen Zeiten sind nicht sichtbar.
Warmup und Protokoll
Abgesehen von den grundsätzlichen Überlegungen zur Messung und Ermittlung von Mittelwerten, Normalverteilungen, der Entfernung zwischen Client und Server in Hops und Kilometern etc. darf natürlich nicht übersehen werden, dass auch das Protokoll und die Datenmenge einen Einfluss auf die Messung hat. Einfach eine WAN-Verbindung mit Millisekunden Latenzzeit zu beschreiben ist nicht vollständig. Die den meisten Fällen wird ja die Latenzzeit als "Roundtriptime" gemessen, d.h. das Paket wird auf die Reise gesendet und auf die Antwort gewartet. Die Faktoren sind dabei eben nicht nur der reine Weg und die Entfernung sondern weitere Einflüsse zählen dazu:
- Paketgröße
Es macht schon einen Unterschied, ob Sie ein 16-Byte "Ping" oder ein 1500Byte UDP-Paket senden oder gar eine 10KByte Datei per HTTP übertragen. - Protokoll
Auch die Frage, ob man nu ICMP, UDP, TCP oder noch höhere Protokolle wie HTTP, SMB etc. nutzt, haben einen Einfluss auf die Messung. Nur ICMP und UDP sind verbindungslos, TCP hingegen "heilt" verlorene Pakete durch erneute Übertragungen. Eine Messung sieht normalerweise keinen Paketverlust sondern maximal eine deutlich höhere Latenzzeit durch den Retransmit. Der dazu erforderliche Handshake kostet Zeit um die sich die Auslieferung der Daten natürlich verzögert - Handshake und Warmup
Verbindungsorientierte Protokolle wie TCP und darauf aufsetzen dann auch HTTP brauchen für die ersten Verbindungen überdurchschnittlich lange, da Sie z.B. mit einem TCP-Handshake (Siehe TCP SYN ACK RES) starten, ehe das erste Paket übertragen wird. Bei HTTPS kommt dann noch der TLS-Handshake und Zertifikatsprüfungen dazu, die am Anfang einer Verbindung sehr lange dauern. Jede Messung sollte also mit einem "Warmup" starten, ehe real gemessen wird. - Antwortzeit der Gegenstelle
Für ein "Roundtrip" brauchen wir eine Gegenstelle, die die Pakete annimmt und wieder beantwortet. Das geht bei ICMP-Ping sehr schnell aber je höher das Protokoll angesiedelt ist, desto mehr kommt auch die Verarbeitung der Gegenstelle in die Formel. Wer z.B. per HTTP dann noch eine größere Information herunterlädt, die der Server erst generieren oder von Festplatten laden muss. - Richtung
Wie bei Straßen gibt es getrennte Fahrspuren für Hin- und Rückweg und die Auslastung kann durchaus unterschiedlich sein. Selbst der heimische DSL-Anschluss ist ja "asynchron". Roundtrip-Messungen lassen daher keinen Rückschluss auf die Richtung zu. Das würde nur gehen, wenn wir quasi eine auf Millisekunden genaue Zeitstempel übertragen würden und die Endstellen eine identische Zeitbasis haben. Der Aufwand hierfür ist hoch und man könnte nicht mehr eine fast beliebige Gegenstelle nutzen. - Proxy, CDN-Cache, WAN-Optimierer
Nicht vergessen werden dürfen die vielen Helfer, die auf dem Netzwerk und von Anbietern zur Optimierung eingesetzt werden. Das fängt schon beim lokalen HTTP-Proxy an, der statische Dateien aus einem Cache liefert. Manchmal sogar trotz explizit gesetzter "NoCache"-Direktive. Auch WAN-Optimierer können aus ihrer Sicht redundant übertragene Informationen wegoptimieren und durch das lokale Gegenstück generieren lassen. Bei den Cloud-Anbietern können Sie ebenfalls davon ausgehen, dass aktiv mit Caches gearbeitet wird, z.B. um statische Bilder, Skripte, Stylesheets etc. dezentral und schnell ausliefern zu lassen.
Intervall oder Warten
Ein letzer Punkt ist natürlich noch die Frage, wann die Messung startet. Die Aussage "Jede Sekunde" ist nämlich nicht eindeutig. Sie kann zwei Dinge bedeuten:
- Start zu jeder Sekunde.
Dann muss das Skript aber entweder parallele Anfragen lossenden oder die vorherige Anfrage abbrechen. Dann könnten aber normale Laufzeiten >1 Sekunde nie gemessen werden
- Start nach 1 Sekunde Pause
Das vereinfacht das Skript, da es einfach eine Sekunde schlafen gelegt wird. Das bedeutet aber, dass jede Messung den nächsten Start weiter verzögert und daher nie 60 Messungen pro Sekunden erreicht werden können.
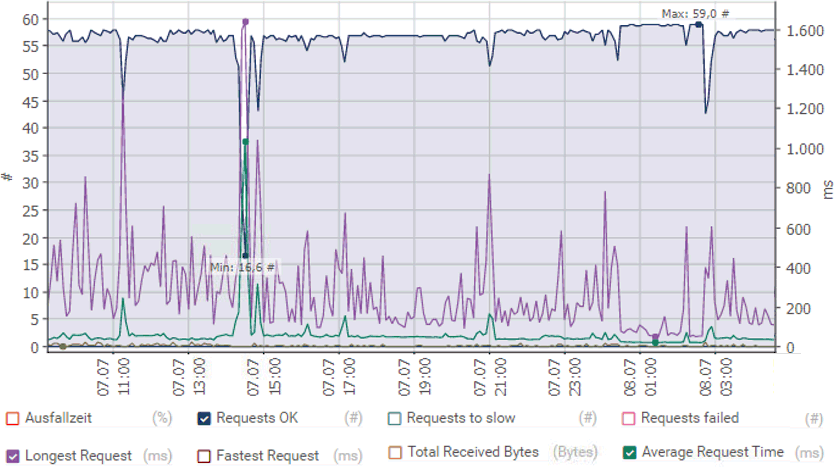
Meine Skripte verfahren nach dem Schema, eine Sekunde zu warten aber ich starte den eigentlichen Test schon mit einem Timeout <1 Sek. Wenn nun jeder Test z.B.500ms dauert, dann startet der nächste Test natürlich erst wieder 1,5 Sek später und auf 60 Minuten komme ich dann auf ca. 40 Ergebnisse. In Auswertungen ist dann aber schon allein über die "Anzahl" der Tests eine Aussage möglich. Hier ein Beispiel, bei dem die "Fläche2 interessant ist. Bei diesem Test sind immer um die 56-57 Messung möglich außen in den Problemzeiten.
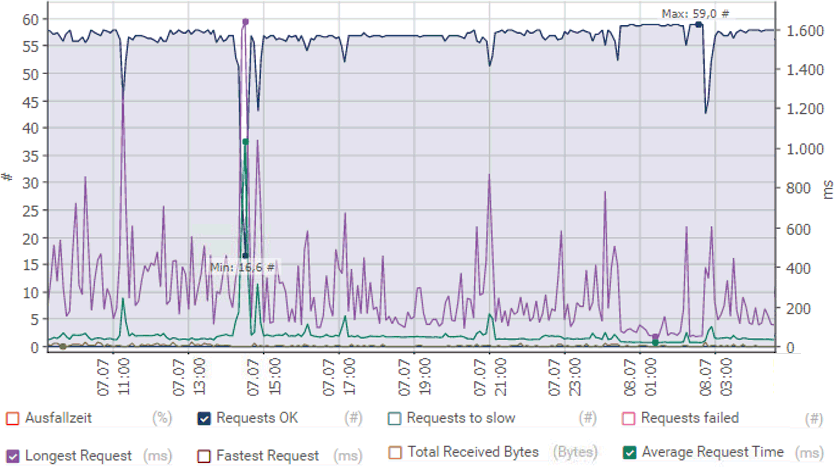
Das ist ein kleiner Nebeneffekt, der immer dann unterwünscht ist, wenn wirklich "genau" gemessen werden soll.
Warnung
Der klassische Spruch der Elektriker "Wer misst, misst Mist" gilt also auch hier und daher sind alle Messungen mit einer gewissen Vorsicht zu betrachten. Es können sich viele Randparameter verschieben aber als große Richtung und als Vergleichsmöglichkeiten zwischen zwei Standorten oder Vorher/Nachher bei Umbauten sind sie mir unersetzbar geworden.
Weitere Links
- TCP SYN ACK RES
- Traceroute TURN
- Exchange Latenz und Outlook Performance
- Normalverteilung
https://de.wikipedia.org/wiki/Normalverteilung - Varianz (Stochastik)
https://de.wikipedia.org/wiki/Varianz_(Stochastik) - Konfidenzintervall
https://de.wikipedia.org/wiki/Konfidenzintervall - Quartil
https://de.wikipedia.org/wiki/Quartil - https://de.wikipedia.org/wiki/Empirisches_Quantil
- https://de.wikipedia.org/wiki/Quantil_(Wahrscheinlichkeitstheorie)
-
Arithmetisches Mittel
https://de.wikipedia.org/wiki/Arithmetisches_Mittel - Percentil
https://de.m.wikipedia.org/wiki/Empirisches_Quantil#Perzentile - High-density line sampling in Power BI
https://docs.Microsoft.com/en-us/power-bi/desktop-high-density-sampling














