
MiniSFT
Diese Seite beschäftigt sich einer Lösung zum Failover von IP-Adressen im Falle eines Defekts eines Servers. Dies funktioniert natürlich nicht für Server, die Daten halten (Exchange Mailboxen, Dateiserver, SQL-Server). Aber es kann wunderbar für Frontend Server, Connectoren, Virenscanner, Webserver etc. funktionieren. Hochverfügbarkeit einmal ohne Microsoft Cluster Server und Network Load Balancing.
MiniSFT ist genau wie NLB eher ein Notbehelf. Prüfen Sie auf jeden Fall den Einsatz eines LoadBalancer
Alle Skripte sind Muster ohne jede Gewährleistung oder Funktionsgarantie. für Schäden bin ich nicht verantwortlich. Achten Sie auf Zeilenumbrüche bei der Übernahme.
Exchange 2010 Cluster und CAS
Wer Exchange 2010 mit
Database Availability
Groups auf Cluster installiert und keine separaten CAS-Server bereit
stellt, muss externe Load Balancer verwenden, um die Clients beim
Ausfall eines Knotens zum noch aktiven CAS-Server zu lenken. Die
Kombination von
Network Load
Balancing mit Cluster ist nicht möglich. MiniSFT könnte hier helfen,
indem die IP-Adresse des ausgefallenen Clusters auf dem anderen einfach
zusätzlich automatisch gebunden wird. (Muss noch verifiziert werden)
Hochverfügbarkeit ist für Exchange und verwandte Dienste natürlich sehr wichtig und es gibt mit dem Exchangecluster eine elegante Möglichkeit, den Datenspeicher höher verfügbar zu machen. Exchange 2007 wird mit dem Local Continuous Replication eine weitere Option für eine höhere Verfügbarkeit bereitstellen. für die Verfügbarkeit von Frontend Servern eignet sich hingegen besser ein Network Load Balancing, mit dem bis zu 32 Server mit der gleichen IP-Adresse erreichbar sein können und damit die Nachteile eines DNS-Round-Robin vermieden werden. Auf Clustergrundlagen können Sie weitere Ansätze für eine höhere Verfügbarkeit nachlesen.
Microsoft Cluster ist primär für die hohe Verfügbarkeit von Datenbanken (Exchange, SQL, Dateiserver) zuständig und für viele Anwendungsfälle zu teuer (Teuer bezieht sich hier weniger auf die Lizenzkosten von Microsoft, sondern eher auf die Hardware und das erforderliche Know-how). Network Load Balancing ist zwar schon nett, aber eignet sich nur für TCP-Verbindungen und schützt einen kompletten Ausfall des Server, aber überwacht keine Dienste. Zudem sollte der Swicht "Ethernet-Muticast unterstützen, damit aus dem Switch durch Paketflooding kein Hub wird.
Natürlich könnten Sie nun den kompletten Server einfach z.B.: mit VMware ESX auf eine andere Hardware spiegeln um im Falle eines Ausfalls der Hardware einfach umzuschalten und einige Dritthersteller (Marathon etc.) haben sogar besondere Hardware für hoher Verfügbarkeit. Also warum dann noch ein Script, welches im Falle eines Ausfalls "gegensteuert" ?
Denkansatz und Funktion
Das Prinzip dieser "Hochverfügbarkeit" basiert darauf, dass ein Dienst unter einer IP-Adresse angesprochen wird, die meist im DNS veröffentlicht ist. Dabei macht es für viele Dienste aber keinen unterschied, welches System physikalisch den Dienst bereit stellt. Hat man demnach mehrere Server, die die gleiche Funktion bereitstellen können, dann kann durch das Übertragen einer IP-Adresse von einem ausgefallenen Server zu einem anderen Server die Funktion erhalten werden. Ein Prinzip, was auf Unix-Systemen ebenfalls gerne eingesetzt wird. Versuchen Sie damit aber nicht Dienste "Hochverfügbar" zu machen, die dies aus Prinzip nicht benötigen. So können DNS, Active Directory einfach mit mehreren Server ohne weitere "Tricks" eine Verfügbarkeit sicherstellen.
Normalbetrieb
Stellen Sie sich zwei Server vor, von denen jeder eine eigene IP-Adresse (IP=1 und IP=2) hat. Auf beiden Servern sind die gleichen Dienste installiert und aktiv. (z.B.: ein SMTP-Server oder Webserver.) Dieser Dienst ist aber nicht auf die primäre IP-Adresse des Servers gebunden, sondern auf eine dritte IP-Adressen (IP=3), die nur einem der beiden Server gehört, gebunden.
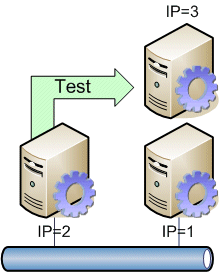
Da auch der Eintrag im DNS auf IP=3 verweist, erfolgen die Zugriff auf IP=3, was in dem Bild der Server IP=1 ist. Es ist kein Problem, dass ein Server mehrere IP-Adressen verwendet, solange die Anwendung dies unterstützt. Der Server IP=2 prüft allerdings regelmäßig die Erreichbarkeit des Dienstes unter der IP-Adresse IP=3.
Ausfall
Fällt nun der Server IP=1 aus, dann ist auch der Dienst unter IP=3 nicht mehr erreichbar. Nun kann das Script auf Server IP=2 sich selbst nun die Adresse IP=3 binden. Wenn der lokale Service diese dynamische Erweiterung erlaubt, dann wird die Anwendung sehr schnell wieder zur Verfügung stehen.

Allerdings müssen die früher bestandenen IP-Verbindungen wieder frisch durch die Anwendung aufgebaut werden. Der Verbindungstatus des Server IP=1 ist mit dem Ausfall natürlich verloren gegangen. Im Gegensatz zu DNS Round Robin werden aber alle neuen Verbindungen wieder angenommen. Bei DNS- Round Robin werden ja auch IP-Adressen von ausgefallenen Servern an die Clients gemeldet. Beim Failover kann es sein dass der Router jedoch die "falsche" alte MAC-Adresse der Netzwerkkarte von Server IP=1 noch im Cache hat. Router lernen das aber sehr schnell, wenn dieser Wechsel nicht irrtümlich für einen Angriff gehalten wird.
Fällt natürlich der Server IP=2 aus, dann läuft ja IP=1 weiter und es passiert nicht. Fallen beide aus, dann gibt es auch nichts umzuschalten.
Recovery
Wenn nun der Server IP=1 wieder hergestellt oder auch einfach nur gestartet wird, dann versucht er natürlich ebenfalls die IP=3 zu binden. Allerdings prüft ein Server vorher mittels ARP-Anfrage, ob ein anderes System die IP-Adresse belegt. Dies ist natürlich der Fall und so startet zwar Server IP=1 mit seiner eigenen Adresse aber kann die IP=3 nicht binden. ( Meldung im Eventlog!).
Die Funktion bleibt also auf dem Server IP=2 und muss manuell zurück geschaltet werden.

Der "Fallback" erfolgt nun derart, dass das Überwachungsskript auf dem IP=2 angehalten wird, dann die IP-Adresse IP=3 vom ServerIP=2 entfernt wird und diese dann auf dem Server IP=1 erneut aktiviert wird (z.B. Netzwerkkarte deaktivieren und wieder aktivieren oder frisch eintragen.). Wenn Server IP=1 nun wieder funktioniert, kann auch das Testskript wieder aktiviert werden. Der Fallback bedeutet natürlich, dass der Dienst ein paar Minuten nicht erreichbar ist.
Allerdings können Sie sich bei gleichen Servern dieses Zurückschwenken auch schenken. Allerdings muss dann Server IP=1 die Überwachung von IP=3 in umgekehrter Richtung übernehmen.
Aktiv/Aktiv
Nun ist es natürlich schade, wenn ein Server so untätig läuft. Und es ist tatsächlich einfach möglich, diesem Server auch eine Aufgabe zuzuweisen. Jeder der Server kann neben seiner primären IP-Adresse ja noch weitere IP-Adressen bekommen und auf beiden Server kann der gewünschte Dienst aktiv sein. Natürlich hat jeder Instanz des Dienstes eine eigene IP-Adresse (IP=3 und IP=4)

Damit beide Dienste gleichmäßig genutzt werden, sollten diese per DNS Round Robin veröffentlicht und über den Namen angesprochen werden. Die Server überwachen sich nun gegenseitig. Fällt nun ein Server aus, dann erkennt dies das Script auf dem anderen Server und bindet sich die Dienst IP-Adresse (IP=3) des ausgefallenen Servers, so dass nun beide Dienste auf dem verbliebenen Server laufen,.
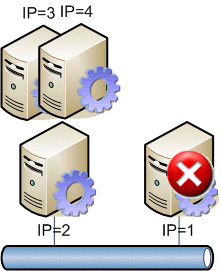
Natürlich ist auch hier wieder das Thema "Fallback" zu klären. Ebenso müssen Sie sicher sein, dass die Dienste problemlos eine solche IP-AdressÄnderung akzeptieren. Vielleicht ist auch ein Neustart der Dienste erforderlich.
Diese Konstruktion kann natürlich fast beliebig erweitert werden. Interessant wäre auch die Funktion eines automatischen Fallback. Da per Script die Existenz des physikalischen Servers geprüft werden kann, wäre es durchaus möglich, dass in diesem Fall der Server IP=2 per Test die Erreichbarkeit von IP=1 prüft und sobald dieser wieder läuft, die übernommenen IP-Adressen freigibt. Dies könnte dann das Überwachungsskript auf IP=1 erkennen und sich so seine Adresse wieder zurückholen.
Allerdings würde dadurch so ein Script komplex und unübersichtlich. Zudem möchte ein Administrator den Fallback sicher selbst steuern. Schließlich bedeutet die Erreichbarkeit von IP=1 nicht, dass die darauf installierten Dienste auch schon funktionieren. Vielleicht wird der defekte Server ja gerade repariert bzw. Installiert. Das ist auch ein Grund, warum bei Network Load Balancing auch ein neues System nicht sofort wieder im Team aktiv werden sollte.
Es gibt immer einen Grund für einen Ausfall und der ist zu finden und zu beheben.
Die Logik
Die Funktion des einfachen Programms ist am besten anhand eines Flussdiagramms zu verstehen. Das Script prüft über zwei Verfahren die Funktion des zu überwachenden Dienstes ab:
- LooksAlive mittels Ping
Ein PING ist mit wenig CPU-Aufwand zu erledigen und kann prüfen, ob das Zielsystem überhaupt vorhanden ist. Ist es nicht erreichbar, dann ist der Fehler schon erkannt und ein Failover muss eingeleitet werden. - IsAlive mit Funktion
Eine natürlich je Dient anzupassende Funktion prüft wirklich die Funktion des Dienstes (z.B.: Abholen einer Webseite, Verbindungsversuch mit TCP-Port o.ä.). Funktioniert dies, dann ist der Test erfolgreich. Da der Test "teuerer" ist, kann er nicht alle paar Sekunden wiederholt werden.
Entsprechend wird also sehr viel häufiger ein "LooksAlive" als ein "IsAlive"-Test durchgeführt.

Sie sehen aber auch rechts einen Fall, in dem das Script fehlschlägt. Nämlich genau dann, wenn der Dienst nicht mehr funktionstüchtig ist, aber der Server selbst auf einen Ping noch antwortet. Hier kann eigentlich nur ein Alarm ausgelöst werden, denn der andere Server kann die IP-Adresse nur übernehmen, wenn der erste Server nicht mehr per IP erreichbar ist.
Das Skript
Das Script ist so nur bedingt einsetzbar !!
In der Klasse müssen Sie ihren Code für die Funktion "IsAlive" selbst beisteuern.
Ich weiß ja nicht, was Sie überwachen wollen. Im
Script ist "LooksAlive" als einfacher "PING" ausgeführt und "IsAlive"
ist immer "True", was natürlich für den Anfang
auch ausreichen kann.
Das Skript benötigt natürlich einige Konfigurationsinformationen, die am Anfang durch Konstanten anzugeben sind:
- const MONITORIP = "192.168.0.44"
Geben Sie hier die IP-Adresse an, die zu überwachen ist - const MONITORSUBNET = "255.255.255.0"
Die ist die dazu gehörige Netzmaske. für die Überwachung ist diese noch nicht erforderlich aber fr die spätere Übernahme der IP-Adresse im Fehlerfall - const LOCALIP = "192.168.0.10"
Dies ist die IP-Adresse der lokalen Netzwerkkarte, an die im Fehlerfall die Adresse von "MONITORIP" gebunden wird. Besonders wichtig, wenn ihr Server mehrere Netzwerkarten hat. Es MUSS natürlich eine Netzwerkkarte im gleichen Subnetz wird des anderen Servers sein, d.h. damit auch das IP-Routing den Weg zu der Karte findet. Das Script nutzt diese Adresse um die richtige Karte zu finden. Es darf daher keine Adresse sein, die ebenfalls per "failover" umgeschaltet werden kann. - const LOOKSALIVEINTERVAL = 3
Dieser Parameter gibt die Wartezeit zwischen zwei "LooksAlive"-Test an. Es macht ja keinen Sinn, im Millisekundentakt den anderen Server anzupingen. Am Ende beschäftigen sich die beiden Server mehr mit sich selbst als mit ihrer eigentlichen Funktion. 3 Sekunden ist aus meiner Sicht ein ganz praktikabler Wert der Zudem mit dem LOOKSALIVERETRY-Interfall multipliziert werden muss. - const LOOKSALIVERETRY = 3
Es kann ja mal passieren, dass ein "Ping" nicht ankommt. Ein Failover wäre dann natürlich kontraproduktiv. Daher können Sie mit diesem Wert angeben, wie lange nacheinander ein Ping fehlschlagen muss, ehe ein Failover stattfindet. - const ISALIVEINTERVAL = 10 ' in Sekunden Wiederholungsinterfall für IsAlive
Dieses Intervall beschreibt die Zeit, zwischen zwei IsAlive-Tests. Wenn Sie das Script sehen, dann ist diese Zeit nicht immer 100% zu erreichen, da ein IsAlive erst durchgeführt wird, wenn der LooksAlive erfolgreich war. Insofern sollte dieser Wert ein höher als IsAlive sein. Da dieser Test auch aufwändiger sein wird, können hier auch höhere Werte stehen.
Das generelle Problem bei jeder Hochverfügbarkeit bleibt immer die Erkennung des Ausfalls. Ein funktionierendes PING sagt noch nichts über die Funktion aus. Auch eine einfache Abfrage einer Webseite sagt nur, dass der Webserver anscheinend funktioniert aber gibt keine Hinweise auf falsche Inhalte einer Webseite. Insofern ist der primäre Zweck natürlich den Totalausfall eines Servers zu erkennen und den Schaden zu minimieren.
Eine hohe Verfügbarkeit ist nicht das Ergebnis eines 15 kbyte großen
VBScripts, sondern hängt von vielen Komponenten ab. Lesen Sie dazu auch
Hochverfügbarkeit.
Daher steht dieses Script nicht zum allgemeinen Download zur Verfügung.
Informationen, warum diese Skripte nicht öffentlich sind, finden Sie auf
nicht public.
Geplante Weiterentwicklung
Das Script ist einfach und funktional, aber dennoch kann noch einiges dabei verbessert werden. z.B.:
- Eventlog
Auf die Dauer ist ein einfacher Eintrag mit WSH als Quelle nicht besonders nett. Leider kann man aus VBScript wohl keine anderen Events schreiben. Also bleibt das ein Wunsch für eine .NET-Version - Alerting und MOM Integration
Events schreiben ist das eine, aber dass ein Failover stattgefunden hat, sollte ein Administrator schnell mitgeteilt bekommen. Natürlich könnte ich nun das Script um einen SMS-Sender, Mailsender etc. aufbohren. Aber mit MOM und anderen Programmen gibt es ja professionelle Überwachungstools. Also fehlt nur noch ein MOM Management Pack für MiniSFT - Pooling und Synchronisation
Die Luxusversion könnte ich mir wie folgt darstellen: Jeder Server hat seine eigene IP-Adresse und die Dienst-IP-Adressen sind als Pools definiert. Jedes Mitglied kennt dann sowohl den Pool als auch die Mitglieder und die Verteilung der Adressen. Jedes Mitglied überwacht dann einfach seinen "Nachbar" oder vielleicht auch alle anderen. Wird der Ausfall eines Mitglieds erkannt, könnte man anhand einer Formel bestehend aus der Reihenfolge und aktuellen Last- bzw. Adressen-Verteilung ein Mitglied zur Übernahme der IP-Adressen veranlassen. Natürlich müssten dann die einzelnen Mitglieder miteinander einen Status austauschen oder am besten die Konfiguration abgleichen. Das dürfte aber alles nicht mehr mit VBScript möglich sein. Zudem dürfte so eine Lösung dann in Umfeldern zum Einsatz kommen, die wirklich "Verfügbarkeit" benötigen und sich sicherlich nicht auf ein kostenfreies Skript mit eingeschränktem Support verlassen würden.
Wenn Sie sich fragen, woher der Name MiniSFT kommt, dann erinnern Sie sich mal an die "guten alten Novell-Zeiten". Da gab es NetWare 2.x, 3.x und NetWare 4.x. Dort gab es die Begriffe SFT1, SFTII und SFTIII. SFT1 stand für Mirroring (Festplattenspiegelung), SFTII für Duplexing (Spiegelung mit zwei Controllern), SFTIII für Cluster mit IO-Engine und MS-Engine. Und SFT selbst steht für "System Fault Tolerance".
Weitere Links
- Hochverfügbarkeit
- Cluster
- Network Load Balancing
- NLB: Monitoring Application Level Health
http://msdn.microsoft.com/en-us/library/cc307934(VS.85).aspx - Win32_NetworkAdapterConfiguration
http://msdn.Microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/win32_networkadapterconfiguration.asp - EnableStatic Method of the Win32_NetworkAdapterConfiguration Class
http://msdn.Microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/enablestatic_method_in_class_win32_networkadapterconfiguration.asp - Assign a Static IP Address
http://www.Microsoft.com/technet/scriptcenter/scripts/network/client/modify/nwmovb01.mspx - Configuring Network Settings
http://www.Microsoft.com/technet/scriptcenter/scripts/network/client/modify/default.mspx - Assign a Static IP Address
http://www.Microsoft.com/technet/scriptcenter/scripts/network/client/modify/nwmovb01.mspx - EnableStatic Method of the Win32_NetworkAdapterConfiguration Class
http://msdn.Microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/enablestatic_method_in_class_win32_networkadapterconfiguration.asp - WMI Tasks: Networking
http://msdn.Microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/wmi_tasks__networking.asp - Win32_NetworkAdapterConfiguration
http://msdn.microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/win32_networkadapterconfiguration.asp - EnableStatic Method of the Win32_NetworkAdapterConfiguration Class
http://msdn.microsoft.com/library/default.asp?URL=/library/en-us/wmisdk/wmi/enablestatic_method_in_class_win32_networkadapterconfiguration.asp - Part 4 - Scripting IP Address Allocation on Clients
ms-help://MS.TechNet.2005DEC.1033/scriptcenter/tnoffline/scriptcenter/guides/autonet/atncpt04.htm - Wackamole Projekt
http://www.backhand.org/wackamole/
Jeder Knoten hat eine eigene IP-Adresse und der bereitgestellte Dienst läuft auf jedem Knoten. Dazu gibt es einen Pool von IP-Adressen, für die von Wackamole sichergestellt wird, dass jede Adresse immer auf einem der Knoten "online" ist. Fällt ein Knoten aus, dann handelt der Rest aus, welcher Knoten die Adresse "übernimmt". - BalancerNG
http://www.inlab.de/balanceng/index.html
Software loadbalancer auf Unix-Basus














