
DAG vs. VM
Ich weiß nicht, ob das Festhalten an gewohnten Konstruktionen oder der Zwang eine einmal getroffene Entscheidung eisern zu vertreten die Ursache ist. Aber ich finde häufig Exchange Server, die durch Virtualisierung "hochverfügbar" gemacht wurde. Diese Seite soll aufklären, dass eine DAG für alle beteiligten Teams besser ist, als jede Hochverfügbarkeit durch Virtualisierung.
Vorgeschichte
Ich gebe gerne zu, dass die Exchange "Hochverfügbarkeit" früher schon ein nicht einfaches Thema war. Exchange 2000/2003 Cluster benötigen einen Shared Disk Space, was damals schon teuer war und wieder einen "Single Point of Failure" dargestellt. Exchange 2007 hat mit der CCR-Replikation das erste Mal gezeigt, dass eine eigene Replikation die Verfügbarkeit einfach und kostensparend erhöhen kann, wenn die Software diese Funktion denn bietet. Die Exchange 2010 DAG hat diese Entwicklung fortgesetzt und auch mit Exchange 2013 ist deutlich, dass Microsoft den Weg weiter geht. Letztlich auch weil so die Exchange Dienste in der Cloud (Office 365) einfach günstiger anzubieten sind. Mittlerweile hat auch SQL den Weg eingeschalten um über "SQL-Mirroring" Datenbestände per Software auf weitere Server zu replizieren. Der Bedarf an "hochverfügbaren" (teuren) müssenspeichern wird so wieder reduziert, auch weil sich diese Technik nicht für alle Daten als optimal dargestellt hat.
Damit wird eine Hochverfügbarkeit durch Virtualisierung aber keineswegs überflüssig. Hersteller wie VMWare (ESX) oder Microsoft (Hyper-V) erlauben nicht nur den Betrieb mehrere Gäste auf einem Host sondern auch die Verlagerung einer Gastinstanz auf einen anderen Host im Verbund. Damit dies möglich wird, mussten Anfangs die VM-Datenträger auf einem gemeinsam nutzbaren Storage liegen, der klassische per SAN oder iSCSI bereit gestellt wurde. Nur so war ein Schwenk der VMs auf andere Hosts überhaupt möglich, die erforderliche Performance und Kapazitäten abzubilden und letztlich auch die Verfügbarkeit der Storage auf das erforderliche Niveau anzuheben. Aber der Store muss nun hochverfügbar sein.
Exchange DAG und VM Verfügbarkeit
Allerdings sehe ich leider immer noch, dass Firmen einen Exchange Server virtuell betreiben und als Teil der HA-Lösung dieser im Fehlerfalle des Hosts auf einen anderen Host übertragen wird. Sicher ist Exchange damit "besser" verfügbar, als wenn es eine physikalische Box wäre und zudem lässt sich die Hardware leichter erweitern etc., aber auf der anderen Seite bleibt es ein einzelner Server. Bei einem ungeplanten Ausfall des Hosts muss der Gast auf dem anderen System erst wieder hochgefahren werden und sind Updates o.ä., im Gast erforderlich, dann ist der Service "down".
Wer hingegen eine DAG betreibt, muss nur eine Datenbank schwenken, was automatisch und vor allem schneller erfolgen kann. Allerdings sollten Sie sehr vorsichtig sein, wenn Sie DAG und VM-HA-Techniken kombinieren. Ich rate immer dazu, dass ein DAG-Mitgliedsserver nicht "live" auf einen anderen Knoten umfallen oder migriert werden darf, sondern dazu immer heruntergefahren werden muss. Ansonsten kann es zu sehr unschönen Konstellationen kommen. Aber dann ist es problemlos auch ein DAG-Server virtuell zu betreiben.
Abgesehen davon, das die Verfügbarkeit einer VM-Lösung quasi nur den Ausfall des Hosts oder der Storage Links betrifft, ist es kein Schutz gegen ein Problem der kompletten Storagekette. Es ist leider nicht ungewöhnlich, dass auch ein SAN einen "Schluckauf" hat. Um hier die erforderliche Verfügbarkeit zu erreichen, investieren Firmen viel Geld in redundante Storage Systeme aber vergessen dabei, dass nicht nur Lizenzen und Disks Geld kosten, sondern dass es auch eine synchrone Replikation ist. Ein logischer Fehler im Dateisystem (z.B. Virus, Admin o.ä.) ist auch immer in der Kopie vorhanden. Ein "Ausschalten" eines Gasts, was einem einen Ausfall eines Hosts gleichzusetzen ist, hinterlässt ein inkonsistentes Dateisystem, welche eventuell erst nach einem zeitintensiven Checkdisk wieder online geht.
Irrtümlich werden die Schwerpunkte auf die Bereitstellung eines Dienstes im Fehlerfall gelegt, was meiner Meinung nach gar nicht so oft passiert. Viel häufiger sind es geplante Servicearbeiten, die eine Dienstunterbrechung mit sich bringen. Und da hilft die Verfügbarkeit mit Virtualisierung nicht wirklich weiter.
Exchange VM Verfügbarkeit im Beispiel
Schauen wir uns diese einfache Struktur an: Zwei VM-Hosts nutzen einen replizierten Storage um eine Exchange VM auf einem Host zu betreiben. Wenn wir all die RAID-Levels weg lassen, benötigen wir in beiden Storage Systemen die Kapazität. Um den Failover sicher zu gewährleisten, müssen auf dem zweiten Hosts auch Ressourcen vorhalten.
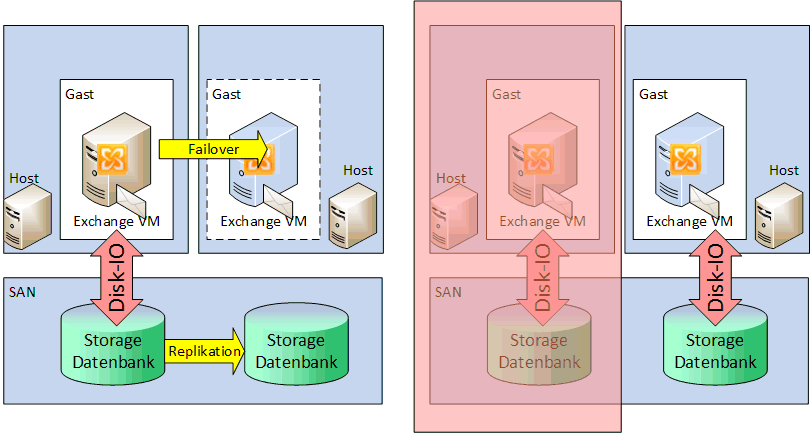
Fällt hier der linke Hosts aus, dann kann der rechte Hosts natürlich die VM "übernehmen" indem er die Kopie des Storage zum Start nutzt. Das dauert natürlich und hoffentlich ist die Kopie ausreichend Konsistent, dass Windows startet und die Datenbanks ich wieder fängt. CHKDSK für NTFS und die Exchange Rollback-Funktion sind hier ggfls. verzögernd zu betrachten.
In einer einfachen DAG hingegen gibt es natürlich zwei Server, die auch beide aktiv sein können. Entsprechend müssen die Exchange Server Lizenzen eingeplant werden. Von der Disk-Kapazität benötige ich pro Server die Kapazität, die aber im Backend nicht durch das SAN repliziert werden muss. Unterm Strich ist der Datenbedarf damit identisch, wenn weiterhin das SAN genutzt wird. Ich kann natürlich auch günstigeren Storage nutzen.
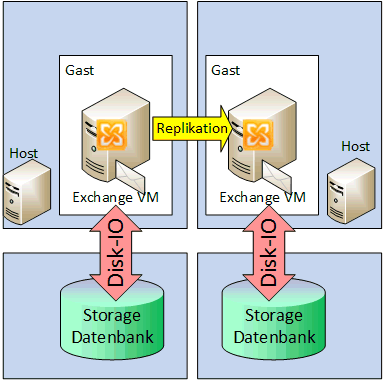
Damit entspannt sich nicht nur das Budget, sondern es macht auch die Konfiguration einfacher.
Ganz besonders irritierend finde Lösungen, bei denen mehrere einzelne Server quasi als Bulk auf der gleichen VM-Farm betrieben werden aber nicht als DAG konfiguriert sind. Hier sind die Exchange Server Lizenzen schon da und unter VM-Umgebungen wird Windows auch oft als Datacenter lizenziert, so dass auch dies nicht mehr addiert werden muss. Hier müssten dann einfach die bislang replizierten Disks aufgebrochen, entsprechend verteilt und die Datenbank repliziert werden.
Brauche ich dann noch VM Cluster ?
Ja, natürlich gibt es sinnvoll Einsatzbereiche für die Bereitstellung als VM mit Failover auf andere Hosts. Die Vorteile der Virtualisierung lassen sich ja nicht wegdiskutieren und es gibt sehr viele Server, die keine eigenen HA-Techniken unterstützen. Hier ist ein VM mit Snapshots und Failover eine legitime Technik um die Verfügbarkeit einfach zu erhöhen. Weil es eben nicht anderes gibt oder andere Lösungen vielleicht zu teuer sind.
Neben Exchange gibt es noch andere Dienste, die sie nicht wirklich per VM-Clustering bereitstellen sollten. Warum sollte ein Domaincontroller auf einem Hosts auf einen anderen Server umschwenken? natürlich kann man das machen und mit DCs ist das sogar einfacher, da es eine Multimasterreplikation ist und ein DC keine Funktion "übernimmt" nur weil ein anderer DC im LAN nicht mehr erreichbar ist. Aber man muss es nicht tun, genauso wenig wie DNS-Server, DHCP-Server etc. Dienste die per Design schon besser verfügbar gemacht werden können, können durchaus virtualisiert werden, aber müssen nicht noch per VM "hochverfügbar" getrimmt werden. für Exchange gilt das gleiche.
Aber natürlich ist so eine Änderung eine Veränderung einer vielleicht in der Vergangenheit entschiedenen "Alles ins SAN" und "Alles Virtuell"-Strategie. Das ist nicht immer einfach hier mit Fakten für einen "Sonderweg" zu argumentieren, wenn anderen Schwergewichte in ihrer IT größere Beträge in eine Top Infrastruktur gesteckt haben und dafür nun verzweifelt nach Nutzern suchen.
Tabellarische Betrachtung
Ich habe hier versucht einfach die beiden zuerst vorgestellten Optionen gegenüber zu stellen. Einmal ein Exchange Single Server, der per VM-Technik besser verfügbar gemacht wird und einmal eine DAG aus zwei Exchange Servern
| Thema | VM Cluster | DAG Cluster |
|---|---|---|
Windows Lizenzen |
1x Windows, eventuell aufgrund von Datacenter kostenfrei |
2x Windows, eventuell aufgrund von Datacenter kostenfrei |
Exchange |
1x Exchange Standard Server oder Enterprise Server für einen Server |
2x Exchange Standard Server oder Enterprise Server |
Hardware |
1x VM
Resourcen auf
aktivem Host |
1x VM
Resourcen auf
Host 1 |
Performance |
Ein Single Server bedient alle User. 100% Provisioning |
Jeder Server muss im Regelbetrieb 50% der Benutzer bedienen, wenn mehrere Datenbanken genutzt werden. Server müssen aber ebenfalls für 100% ausgelegt werden für den Fehlerfall. |
Filesystem |
Repliziert aber Bitidentisch., Fehler wirken auf beide Systeme |
Jeder Server hat sein eigenes unabhängiges Dateisystem und sind daher besser geschützt |
Geplante Downtime |
Updates bedeuten ein "Down" des Servers oder Dienstes über längere Zeit |
Ein Server kann im Wartungsmode ohne Einfluss auf die Clients risikolos aktualisiert werden. |
Backup |
Single Instanz der Datenbank erfordert häufiges Backup |
Die Daten liegen 2 mal vor. Denkbar sind längere Backupzyklen, da das Replikation ja schon "das erste Backup" ist |
Downtime bei Hostdefekt |
Server muss auf anderem Host neu hochfahren und ggfls. CHKDSK ausführen |
Failoverzeit für 50% der Datenbanken auf diesem Server im Bereich von Sekunden. |
Downtime bei Gastdefekt |
Dienste oder komplette Server ist neu zu booten. ggfls. Reparaturinstallation oder mehr |
Datenbank werden auf zweiten Knoten geschwenkt und dann kann der erste Knoten in Ruhe diagnostiziert und im Extremfall neu aufgesetzt werden. Benutzer können weiter arbeiten |
Verluste bei OS- Diskfehler |
Ist die OS-Platte betroffen, könnte ein Snapshot vielleicht helfen. Ansonsten Recoveryinstallation. |
Datenbank werden auf zweiten Knoten geschwenkt und dann kann der erste Knoten in Ruhe diagnostiziert und im Extremfall neu aufgesetzt werden. Benutzer können weiter arbeiten |
Verluste bei DB- Diskfehler |
Datenbank muss vom Backup oder aus früherem Snapshot wieder hergestellt werden. Restore dauert länger (Recovery Time Objective) und der Datenbestand kann älter sein (Recovery Point Objective) |
Datenbank werden auf zweiten Knoten geschwenkt und dann kann der erste Knoten in Ruhe diagnostiziert und im Extremfall neu aufgesetzt werden. Benutzer können weiter arbeiten. Datenverlust ist nicht vorhanden. Reseeding des ausgefallenen Servern kann vom laufenden Knoten erfolgen. |
Downtime für Windows Updates, TreiberUpdates |
Downtime mehrere Minuten bis alle Dienste wieder online sind. |
Minimale Downtime, da Datenbanken innerhalb weniger Sekunden geschwenkt werden. |
Probleme im SAN |
Der Server ist gestört und auch der Failover auf den anderen Host ist nicht zwingend möglich. Indifferentes Zustandsbild |
Idealerweise nutzt Exchange kein "Shared SAN" sondern 1:1 zugewiesene Festplatte, so dass alle Probleme von "Shared Systemen" nicht zutreffen und selbst mit SAN es wahrscheinlich ist, dass nur ein Knoten betroffen ist. Die Datenbanken schwenken in wenigen Sekunden mit minimalem Datenverlust. |
CAS und HT |
Ein Single Server kann auch diese Rollen einfach mit bedienen. Wenn Sie aber schon zwei Single Server virtuell betreibe, sollten sie auch ein CAS-Array mit Loadbalancer nutzen |
CAS und HT auf einer DAG sind möglich, aber sie benötigen dann einen Loadbalancer davor, um die Clients zu einem funktionierenden Knoten zu lenken. NLB funktioniert nicht aber wer über HA nachdenkt, wird in der Regel auch über Loadbalancer nachdenken. |
Sicher finden Sie noch eigene Punkte und bewerten vielleicht ein paar Aussagen anders. Es sollte aber ersichtlich sein, dass eine DAG fast immer die bessere Wahl ist und selbst die Kosten für Lizenzen durch Einsparungen an andere Stelle in der Regel schon beim der Beschaffung wettgemacht werden können.
Ich will wechseln !
Der umbau eine Umgebung mit einem virtuellen Exchange Server gegen einen replizierten Backend Storage geht fast immer im laufenden Betrieb. Seitens Windows und Exchange ist die Einrichtung einer DAG im laufenden Betrieb möglich. Bliebe zu klären, ob Sie das Replikat des Storage einfach abtrennen und als neue LUN dem zweiten Server bereitstellen können, der natürlich zu installieren ist. Sollten Sie aber schon zwei einzelne Exchange Server betreiben, dann ist es ja noch einfacher da Sie das Replikation einfach ablösen und dem anderen Server als weitere Disk geben und dann die Replikation einrichten
Wichtig: Die Pfade einer Datenbank müssen innerhalb einer DAG eindeutig sind, Wenn Sie also zwei einzelne Server haben, dann könnte es sein, dass die Datenbanken im gleichen Pfad liefen, dann sollten Sie zumindest auf einem Server die Pfade anpassen ehe Sie die DAG formen. Ein Verschieben von Pfaden einer DAG ist kniffliger als bei einem einzelnen Server.
Danach müssen Sie nur die Datenbanken auf den jeweils anderen Server seeden und die Aktivierungsreihenfolge einstellen. Denken Sie auch daran, dass sie ggfls. einen Loadbalancer einsetzen müssen, um die Zugriff auf die Rollen CAS und HT zu verteilen. Ich würde einen Loadbalancer vorziehen und nicht zusätzliche CAS/HT Server installieren. Zum einen spart dies Server, Lizenzen und Betriebskosten aber auch mit separaten Servern für CAS/ und HT müssten sie Loadbalancer davor stellen oder NLB nutzen. NLB ist aus meiner Sicht keine gute Wahl und auf einem Cluster sowieso nicht installierbar.














