
Exchange Bluescreen Bugcheck
Was machen Sie, wenn ihr Exchange Server immer wieder einen Bluescreen hat? Zuerst prüfen, ob Exchange schuld ist.
Bluescreen
Früher war ein "Bluescreen" auf einem Windows Server fast immer ein Zeichen für defekte Hardware oder Treiber. Oft waren schlechte Speichermodule, wackelige Festplattenkabel oder auch eine überhitzte CPU Schuld. Auf der anderen Seite gibt es natürlich auch Software-Fehler, die Windows zu einem "ungeplanten normalen Ende" bewegen. Es handelt sich dabei aber immer um eine sehr kritische Situation, bei denen Windows besser "stehen" bleibt, anstatt weiter zu machen. Bei Windows NT und neuer hat der Code unterschiedliche Berechtigungsstufen. Sie kennen die Begriffe "Kernel/System" und "UserSpace". Windows kennzeichnet zudem jede Speicherstelle, ob diese Programmcode oder Daten enthält und zu welchen Prozess diese gehören. Wenn alles seinen geregelten Gang läuft, dann werden Daten nie ausgeführt und Programme nicht verändert. Ein Zugriff von Prozessen auf andere Prozesse sollte ebenso verhindert werden und Kernel-Speicher ist sowie besonders geschützt.

Normale Anwendungsprogramme wir Word, Excel, PowerPoint, Outlook aber auch der Windows Explorer und viele weitere Programme laufen im "Userspace" und haben keinen direkten Zugriff auf die Hardware. Hardwarenahe Treiber werden allerdings im Kernel ausgeführt und sollten daher besonderen Qualitätsanforderungen entsprechen. Sie müssen auch digital signiert sein. Wenn aber Windows eine Situation erkennt, die keine Korrektur, z.B. durch beenden des Prozesses, erlaubt und die Integrität des Systems gefährdet, dann ist es besser sofort zu stoppen. Stellen Sie sich einmal vor, eine CPU hat sich verrechnet oder eine Malware ist es gelungen in LSASS einzugreifen oder ein Festplattentreiber hat einen Softwarefehler, der im schlimmsten Fall eine Korrumpierung des Dateisystems verursacht.
Ein "Bluescreen" ist in der Regel ein schwerwiegendes Ereignis und sollte sie dazu bringen, die Ursache zu finden und zu beheben.
- The application or service crashing
behavior troubleshooting guidance
https://learn.microsoft.com/en-us/troubleshoot/windows-server/performance/troubleshoot-application-service-crashing-behavior
Eventlog BugCheck Event 1001
Früher blieb Windows nach einem "Bluescreen" einfach stehen und der Administrator wurde entsprechend unsanft aus seinen Träumen gerissen. Er konnte aber auf dem Bildschirm ein paar Details zum Fehler sehen. Mittlerweile startet Windows aber nach einem Bluescreen einfach neu und wer seine Server nicht überwacht, wird dies vielleicht gar nicht bemerken. Daher lohnt sich ein Blick ins System-Eventlog mit der ID 1001.
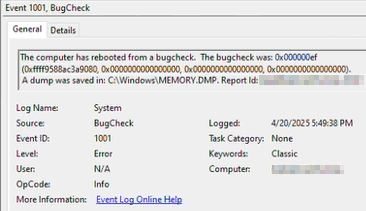
Dort finden Sie für jeden Bluescreen einen Eintrag mit der Fehlernummer, hier 0x000000ef, und dem Hinweis auf den Dump:
- The application or service crashing
behavior troubleshooting guidance
https://learn.microsoft.com/en-us/troubleshoot/windows-server/performance/troubleshoot-application-service-crashing-behavior
BlueScreenView
Sie können die Memory-Dumps mit den DebuggingTools von Microsoft analysieren aber die meisten Administratoren werden damit überfordert sein. Aber die Firma Nirsoft hat ein kleines Tool, welches ganz ohne Installation einen schnellen Blick in die Minidumps erlaubt.
Nirrsoft BlueScreenView v1.55
https://www.nirsoft.net/utils/blue_screen_view.html
Sie packen das ZIP-Archiv aus und starten die EXE. Das Programm öffnet direkt C:\Windows\Minidump aber sie müssen das Skript nicht auf dem Server starten, sondern können auch ein anderes Verzeichnis mit den Minidumps öffnen.
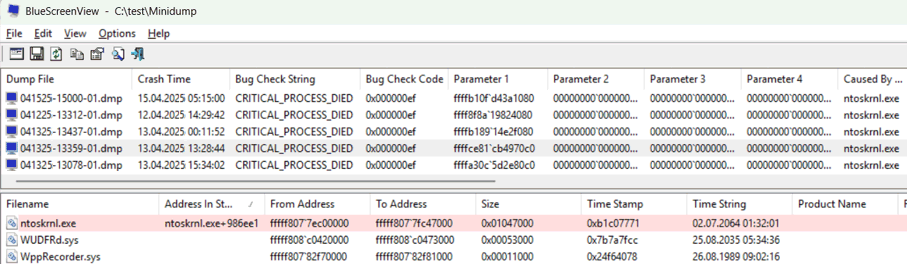
Hier sehen sie gleich fünf Minidumps, die alle mit dem Fehler 0x000000ef erzeugt wurde, weil ein "CRITICAL_PROCESS_DIED" ausgelöst wurde. Normalerweise kenne ich das, wenn z.B. der LSASS-Prozess aufgrund eines Fehler ungeplant beendet wird. Da Windows dann keine Authentifizierungen durchführen und Berechtigungen prüfen kann, ist ein plötzliches Ende angeraten. Microsoft hat sehr ausführlich zu jedem Error eine Seite veröffentlicht:
- Referenz für Fehlerprüfungscode
https://learn.microsoft.com/de-de/windows-hardware/drivers/debugger/bug-check-code-reference2 - Bugcheck 0xEF: CRITICAL_PROCESS_DIED
https://learn.microsoft.com/de-de/windows-hardware/drivers/debugger/bug-check-0xef--critical-process-died
Exchange BugCheck
Das war aber hier nicht der Fall, denn ausgehend von Uhrzeit haben wir im Eventlog nach benachbarten Fehlern gesucht und wurden in Form der Event IOD 9009 fündig.

Die Details geben uns wichtige Hinweise:
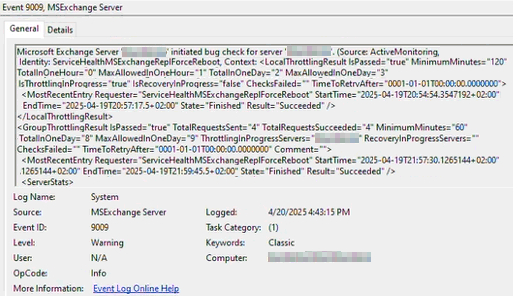
Interessant ist der Text direkt am Anfang des Eventlogs:
Microsoft Exchange Server 'EX01' initiated bug check for Server 'EX01'. (Source ActiveMonitoring, Identity: ServiceHealthMSExchangeReplForceReboot, ....
Die nachfolgende XML-Struktur liefert nur noch eingeschränkt weitere Informationen:
<LocalThrottlingResult IsPassed="true"
MinimumMinutes="120"
TotalInOneHour="0"
MaxAllowedInOneHour="1"
TotalInOneDay="2"
MaxAllowedInOneDay="3"
IsThrottlingInProgress="true"
IsRecoveryInProgress="false"
ChecksFailed=""
TimeToRetryAfter="0001-01-01T00:00:00.0000000">
<MostRecentEntry Requester="ManagedAvailabilityStartup"
StartTime="2025-04-14T17:03:22.5+02:00"
EndTime="2025-04-14T17:08:22.5+02:00"
State="Finished"
Result="Succeeded"/>
</LocalThrottlingResult>
<GroupThrottlingResult IsPassed="true"
TotalRequestsSent="4"
TotalRequestsSucceeded="4"
MinimumMinutes="60"
TotalInOneDay="8"
MaxAllowedInOneDay="9"
ThrottlingInProgressServers="EX01"
RecoveryInProgressServers=""
ChecksFailed=""
TimeToRetryAfter="0001-01-01T00:00:00.0000000"
Comment="">
<MostRecentEntry Requester="ManagedAvailabilityStartup"
StartTime="2025-04-14T17:06:36.5+02:00"
EndTime="2025-04-14T17:11:36.5+02:00"
State="Finished"
Result="Succeeded"/>
<ServerStats>
<EX01 TotalSearched="2"
MostRecentEntryStartTimeUtc="2025-04-14T14:55:15.5Z"
MostRecentEntryEndTimeUtc="2025-04-14T15:00:15.5Z"
TotalActionsInADay="1"
IsThrottlingInProgress="false"
IsRecoveryInProgress="false"
HostProcessStartTimeUtc="2025-04-14T15:00:28.1312489Z"
SystemBootTimeUtc="2025-04-14T15:00:15.5Z"/>
<EX02 TotalSearched="7"
MostRecentEntryStartTimeUtc="2025-04-14T15:06:36.5Z"
MostRecentEntryEndTimeUtc="2025-04-14T15:11:36.5Z"
TotalActionsInADay="4"
IsThrottlingInProgress="false"
IsRecoveryInProgress="false"
HostProcessStartTimeUtc="2025-04-14T15:11:50.1167296Z"
SystemBootTimeUtc="2025-04-14T15:11:36.5Z"/>
</ServerStats>
</GroupThrottlingResult>
Hier hat also die "Exchange Managed Avaiability" zugeschlagen und einen so schwerwiegenden Fehler in der Funktion gefunden, dass es wohl besser ist den Exchange Server in einen Bluescreen zu senden und weder auf den Administrator zu hoffen noch die Dienste erst herunterzufahren.
Das "ServiceHealthMSExchangeReplForceReboot" dürfte auf Probleme der DAGS-Replikation hinweisen und wenn der Server z.B. keine Verbindung mehr hat, dann muss er davon ausgehen, dass der andere Server das Problem erkannt und einen Failover initiiert hat. Dann ist es wirklich besser direkt einen Reboot zu starten.
- Responder
ServiceHealthMSExchangeReplForceReboot
causes Exchange Server to restart with Stop
Error
https://learn.microsoft.com/en-us/troubleshoot/exchange/administration/exchange-restarts-frequently-stop-error
Eventlog: Microsoft-Exchange-ActiveMonitoring/ProbeResult
Mit dem Wissen können wir im Eventlog "Microsoft-Exchange-ActiveMonitoring/ProbeResult" weiter suchen und werden auch hier fündig.
Log Name: Microsoft-Exchange-ActiveMonitoring/ProbeResult Source: Microsoft-Exchange-ActiveMonitoring Event ID: 2 Task Category: Probe result Level: Error User: SYSTEM Computer: EX01.msxfaq.de Description: Probe result (Name=ServiceHealthMSExchangeReplEndpointProbe/TCP/MSExchangeRepl)Check 'Microsoft.Exchange.Monitoring.TcpListenerCheck' thrown an Exception! Exception - Microsoft.Exchange.Monitoring.ReplicationCheckHighPriorityFailedException: High priority check TcpListener failed. Error: The health test of the TCP listener for the Microsoft Exchange Replication service on server 'EX01' failed. This server cannot participate in replication until the error is resolved. Error: Couldn't determine the IP address for server 'EX01' because DNS didn't return any information. at Microsoft.Exchange.Monitoring.ReplicationCheck.FailInternal() at Microsoft.Exchange.Monitoring.ReplicationCheck.Fail(LocalizedString error) at Microsoft.Exchange.Monitoring.TcpListenerCheck.InternalRun() at Microsoft.Exchange.Monitoring.ReplicationCheck.Run() at Microsoft.Exchange.Monitoring.ActiveMonitoring.HighAvailability.Probes.ReplicationHealthChecksProbeBase.RunReplicationCheck(Type checkType) Check 'Microsoft.Exchange.Monitoring.TcpListenerCheck' did not Pass! Detail Message - The health test of the TCP listener for the Microsoft Exchange Replication service on server 'EX01' failed. This server cannot participate in replication until the error is resolved. Error: Couldn't determine the IP address for server 'Exch1' because DNS didn't return any information.
Hier meldet Exchange, dass es keine DNS-Auflösung hatte und seine eigene IP-Adresse nicht auflösen konnte. Der Test bestätigt also indirekt, dass der Server nicht mehr "im Netzwerk" ist und wenn Clients ihn nicht erreichen können, dann ist es besser die bestehenden Verbindungen zu kappen. So können Clients und Loadbalancer auf einen anderen Server wechseln und senden nicht noch weitere Mails an den Server, der die Änderungen nicht mehr auf seine DAG-Mitglieder replizieren kann.
Weitere Ursachen für einen Reboot können Sie wie folgt auf dem Server abfragen:
(Get-WinEvent -LogName Microsoft-Exchange-ManagedAvailability/* `
| Foreach-Object {`
[XML]$_.toXml()`
}`
).event.userData.eventXml `
| Where-Object {$_.ActionID -like "*ForceReboot*"} `
| Format-Table RequesterName
Weitere Analyse
Wir wissen nun, dass Exchange den Server mit einem Bugcheck in einen Bluescreen schickt. Um hier eine weitere Fehleranalyse zu machen, möchte ich den Reboot unterdrücken um die Fehlersituation am quasi "lebenden Objekt" zu analysieren. Genau genommen ist der Server in der Zeit aber vermutlich nicht funktionsfähig. Sie sollten als Administrator also wachsam sein oder die Checks selbst ausführen.
Damit aber der "Exchange Health Management" den Server nicht neustartet, könnten Sie die einzelnen Checks deaktivieren oder den Dienst komplett beenden und deaktivieren:
Stop-Service MSExchangeHM -Force Stop-Service MSExchangeHMRecovery -Force Set-Service MSExchangeHM -StartupType Disabled Set-Service MSExchangeHMRecovery -StartupType Disabled
Damit wird der Exchange Server aber nicht mehr von sich selbst überwacht.. Alle davon abhängigen Prüfungen finden also auch nicht statt oder bekommen keine Meldungen. Sehr häufig nutzen Firmen die Ausgaben von ExchangeHM in ihrer eigenen Monitoring-Lösung weiter, die dann fehlende Statusberichte melden wird. Prüfen Sie, dass hier nicht auch korrigierende Maßnahmen durchgeführt werden.
Hier kommt nun ihre eigentliche Fehlersuche nach der
Wenn Sie ihren Fehler dann gefunden, nachgestellt und letztlich die Ursache behoben haben, können wir die Dienste wieder starten.
Set-Service MSExchangeHM -StartupType Automatic Set-Service MSExchangeHMRecovery -StartupType Automatic Start-Service MSExchangeHM Start-Service MSExchangeHMRecovery
Danach ist ihr Server wieder im normalen Überwachungsbetrieb.
- Overview of Exchange services on Exchange servers
https://learn.microsoft.com/en-us/exchange/plan-and-deploy/deployment-ref/services-overview
Bugcheck selbst auslösen
Was Exchange kann, kann ich auch als Admin oder Entwickler oder sogar Benutzer durchführen. Das Ziel dabei ist, ein Memory-Dump für weitere Analysen zu erzeugen. Es ist also definitiv keine Regeltätigkeit und der "plötzliche Stop" eines Betriebssystem kann auch Datenverluste bedeuten.
Microsoft hat zur Auslösung eines Bugcheck mehrere Wege vorgesehen:
| Weg | Beschreibung |
|---|---|
NtRaiseHardError |
Die Funktion "NtRaiseHardError" in der NTDLL.DLL kann ich relativ einfach per PowerShell aufrufen, um einen Bugcheck auszulösen: $code = @"
using System;
using System.Runtime.InteropServices;
public static class BsodHelper
{
[DllImport("ntdll.dll")]
public static extern int RtlAdjustPrivilege(
int Privilege,
bool Enable,
bool CurrentThread,
out bool Enabled
);
[DllImport("ntdll.dll")]
public static extern int NtRaiseHardError(
uint ErrorStatus,
uint NumberOfParameters,
uint UnicodeStringParameterMask,
IntPtr Parameters,
uint ValidResponseOption,
out uint Response
);
}
"@
Add-Type -TypeDefinition $code -ErrorAction Stop
# 19 = SeShutdownPrivilege
$oldEnabled = $false
[void][BsodHelper]::RtlAdjustPrivilege(19, $true, $false, [ref]$oldEnabled)
# 0xC0000420 = STATUS_ASSERTION_FAILURE, 6 = Option "ShutdownSystem"
$response = 0
[void][BsodHelper]::NtRaiseHardError([uint32]"0xC0000420", 0, 0, [IntPtr]::Zero, 6, [ref]$response)
Sollte der Computer nicht neu starten sondern einen Fehler "3221225569" liefern, dann haben Sie nicht die erforderlichen Rechte. |
|
NotMyFault (Sysinternals) |
Auf der Sysinternals-Seite gibt es schon länger das Programm "NotMyFault", welches die gleiche API aufruft. notmyfault64.exe /crash NotMyFault v4.4 |
|
CTRL-ScrollLock |
Wenn Sie den folgenden Registrierungsschlüssel setzen, dann können Sie als Anwender allein über die Tastatur einen Bugcheck/Bluescreen auslösen. New-ItemProperty ` -Path "HKLM:\System\CurrentControlSet\Services\kbdhid\Parameters" ` -Name CrashOnCtrlScroll ` -Value 1 ` -PropertyType DWord ` -Force Wenn Sie dann die "rechte Strg" gedrückt halten und dann Scroll Lock zweimal drücken, wird ein Bugcheck durch den Tastatur-Treiber ausgelöst. |
KeBugCheckEx |
Dies Funktion kann nur ein Kernel-Treiber auslösen und ist daher nur für Entwickler von Treibern relevant. Sie können bei Fehlern damit einen Memory-Dump zur weiteren Analyse generieren
|
Es ist also gar nicht schlimm, wenn ein Bugcheck ausgelöst werden, wenn ein Entwickler oder Admin einen Memory-Dump für das gesamte System erzeugen möchte, z.B. weil es Probleme mit Treibern o.ä. gibt. Ein Bugcheck ist aber nicht der richtige Weg, wenn Sie einen UserProzess dumpen wollen. Das geht über den Taskmanager:
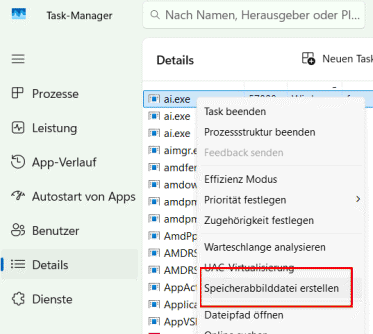
Der klassische Bluescreen ist für systemnahe anders nicht lösbare Probleme oder Analysen.
Zusammenfassung
Ein Bluescreen ist nicht nur ärgerlich, sondern auch ein Alarmzeichen, dass der Server in der ein oder anderen Form ein ernsthaftes Problem hat. Wir können aber drei Szenarien unterscheiden:
- Windows Kernel Fehler
Die in Windows eingebauten Schutzfunktionen erkennen einen schwerwiegendes Fehlverhalten, welches einen weiteren Betrieb nicht mehr sinnvoll machen und zum Schutz der Datenkonsistenz der Server unsanft neu gestartet wird. - Treiber/Entwickler-Aktion
Wer systemnahe Software, z.B. Treiber, entwickelt, wird manchmal eine Momentaufnahme des Treibers benötigen und daher wissentlich einen Bugcheck auslösen. Solcher Debug-Code sollte natürlich nie in Produktion erscheinen. Es kann natürlich gewünscht sein, um nicht anderweitig lösbar Situationen abzufangen. Wenn z.B. eine Festplattentreiber nicht mehr schreiben kann, macht es auch keinen Sinn, dass Anwender weiter den Dateiserver nutzen und ein herunterfahren wird vermutlich lange dauern, weil jeder auf die Schreibzugriffe warten würde. - Applikationsmeldungen
Darunter fällt Exchange. Idealerweise ist ein Exchange Server auch wirklich nur Exchange Server und wenn Exchange Managed Availability ein ernsthaftes Problem erkennt, dann kann er den Server besser durchstarten. Der Bluescreen ist dann aber eher die Folge und nicht die Ursache.
Wenn Exchange einen Bugcheck auslöst, dann ist es die Folge eines angeblich erkannten Fehlers, der so schlimm ist, dass es besser ist, den Server hart zu stoppen und neu zu starten.
Leider habe ich keine Statistik, wie viele Bugchecks die Exchange Server der Welt auslösen. Ich befürchte, dass die meisten Administratoren das gar nicht überwachen und nicht mal bemerken.
Weitere Links
- Exchange Managed Availability
- Managed availability
https://learn.microsoft.com/en-us/exchange/high-availability/managed-availability/managed-availability - CSS-Exchange
ManagedAvailabilityTroubleshooter
https://microsoft.github.io/CSS-Exchange/Diagnostics/ManagedAvailabilityTroubleshooter/
https://github.com/jcoiffin/ManagedAvailabilityTroubleshooter
https://github.com/microsoft/CSS-Exchange/releases - Quick Tip: What Restarts Has Managed
Availability Issued
https://blog.rmilne.ca/2015/02/14/quick-tip-what-restarts-has-managed-availability-issued/ - Responder
ServiceHealthMSExchangeReplForceReboot
causes Exchange Server to restart with Stop
Error
https://learn.microsoft.com/en-us/troubleshoot/exchange/administration/exchange-restarts-frequently-stop-error - The application or service crashing
behavior troubleshooting guidance
https://learn.microsoft.com/en-us/troubleshoot/windows-server/performance/troubleshoot-application-service-crashing-behavior - [Exchange Monitoring]: Introduction to
Managed Availability
Part 1: https://www.enowsoftware.com/solutions-engine/exchange-center/exchange-monitoring-introduction-to-managed-availability-part-1
Part 2: https://www.enowsoftware.com/solutions-engine/exchange-center/exchange-monitoringmanaged-availability-part-2
Part 3: https://www.enowsoftware.com/solutions-engine/exchange-center/exchange-monitoring-introduction-to-managed-availability-part-3 - Exchange Managed Availability
https://blog.icewolf.ch/archive/2022/04/17/exchange-managed-availability/ - Checking for a TCP Listener Connection
https://learn-powershell.net/2015/02/28/checking-for-a-tcp-listener-connection/














