
Exchange 2013 Managed Availability
Beachten Sie dazu unbedingt auch die Seite E2013 Troubleshooting
Die meisten werden eine neue Funktion von Exchange 2013 gar nicht aktiv bemerken, aber Microsoft hat sehr viele Checks und Prüfungen fest in das Produkt eingebaut, um die Funktionsfähigkeit der einzelnen Rollen aktiv zu prüfen. Je mehr Exchange in die "Cloud" kommt, desto mehr Server muss Microsoft selbst betreiben und es lohnt sich, wenn Server sich gegenseitig überwachen und Komponenten mit einem Problem einfach umgehen. Das geht natürlich nur in dem Maße, in dem es Ersatzwege gibt. Mit Blick auf Exchange 2013 sind dies mehrere CAS-Server in einem Verbund mit Loadbalancer oder mehrere Mailboxserver in einer DAG.
What's that alert - Exchange
Managed Availability
http://channel9.msdn.com/Events/MEC/2014/ARC310
Microsoft Exchange Server 2013
Managed Availability
http://channel9.msdn.com/Events/TechEd/NorthAmerica/2013/OUC-B315
Microsoft Exchange Server
2013 Management Pack
http://www.microsoft.com/en-us/download/details.aspx?id=39039
New Managed Availability
Documentation Available
http://blogs.technet.com/b/scottschnoll/archive/2013/11/25/new-managed-availability-documentation-available.aspx
Der klassische Ansatz
Um zu Versehen, warum Microsoft in dem Bereich etwas getan hat, müssen Sie den klassischen Weg einer Überwachung verstanden haben und welche Schritte bei einem Fehler durchlaufen werden.
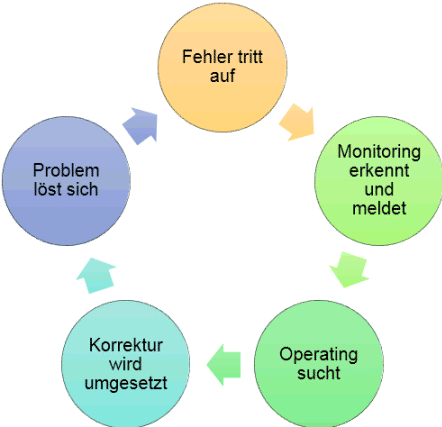
- Eine Fehlersituation tritt ein
- Es dauert einige Zeit bis ein automatisierter Test z.B. von SCOM den Fehler erkennt und einen Alarm sendet
- Es dauert einige Zeit bis der Empfänger (Sie als Administrator) die Meldung annehmen und die Bearbeitung starten
- Es dauert einige Zeit, bis sie die Ursache analysiert, die Lösung gefunden und korrigierend eingegriffen haben.
- Der Fehler ist gelöst aber auch das Monitoring muss dies erkennen und den Status auf "grün" setzen.
Dieser Kreislauf dauert im günstigen Fall nur wenige Minuten, eher aber länger und zudem müssen Sie Arbeitszeit aufwänden. Wie wäre es nun, wenn Exchange selbst die Fehler erkennt und soweit möglich diese auch korrigiert? Genau das ist "Managed Availability".
Merke ich das?
Ja, denn wenn Exchange sich selbst überwacht und Fehler erkennt, dann greift es auch korrigierend ein. Das kann dazu führen, dass Exchange Dienste scheinbar alleine neu starten oder sogar der ganze Server neu startet. Und alles nur, weil Exchange Managed Availability keine andere Möglichkeit mehr gesehen hat den Fehler zu beseitigen.
Aber auch für ihr eigenes "Management" ist es wichtig diese Funktion zu können. Während Sie bei Exchange 2010 und früher einen Dienst fast ungefragt stoppen konnten, sollten Sie bei Updates und Servicepacks hier eventuell Zwischenschritte einlegen. Es könnte sonst passieren, dass diese Überwachung die von ihnen angehaltenen Dienste neu startet und nach einigen Versuchen sogar der Server durchstartet. Das passiert meist zum unpassenden Zeitpunkt.
Sie sollten bei Exchange 2013 noch mehr die Prozesse für Updates strukturieren und einen Service gezielt außer Dienste nehmen. Bei einem HubTransport Server bzw. für den kompletten Server kann das etwas so aussehen.
Set-ServerComponentState ` -identity EX2013ServerA ` -Component HubTransport ` -State Draining ` -Requester Maintenance Redirect-Message ` -Server EX2013ServerA ` -Target EX2013ServerB.msxfaq.net Set-ServerComponentState EX2013ServerA ` -Component ServerWideOffline ` -State InActive ` -Requester Maintenance
- What Did Managed
Availability Just Do To This
Service?
http://blogs.technet.com/b/exchange/archive/2013/06/13/what-did-managed-availability-just-do-to-this-service.aspx - Installing Cumulative Updates für Exchange Server 2013
http://exchangeserverpro.com/exchange-2013-installing-cumulative-Updates/ - [updated] Script: putting
Exchange Server 2013 into
Maintenance Mode
http://michaelvh.wordpress.com/2013/04/08/script-putting-exchange-server-2013-into-maintenance-mode/ - Placing Exchange 2013 Into
Maintenance Mode
http://blog.c7solutions.com/2012/10/placing-exchange-2013-into-maintenance.html - Exchange 2013 Maintenance
Mode
http://letsexchange.blogspot.de/2013/03/exchange-2013-maintenance-mode.html
Worker und Controller
Schon mit Exchange 2010 hat Microsoft die UM-Rolle derart stabiler gemacht, dass es nicht mehr den einen UM-Service gibt, der die ganze Arbeit macht, sondern dass der Dienst selbst nur zwei weitere Dienste startet und diese überwacht. Die "Arbeit" übernehmen also eigene Tasks während der in der Systemsteuerung sichtbare Dienst einfach nur Wachhund spielt. Bei Exchange 2010 wurden die UMWorker immer mal wieder neu gestartet, z.B. wenn Sie nicht mehr reagiert haben oder zu viel Speicher verbraucht haben.
Auch die Hub-Transport-Rolle wurde schon bei Exchange 2010 verändert, indem die Mailverarbeitung in eigene Tasks ausgelagert wurde. Hat sich dann ein Task an einer Mail "verschluckt", d.h. ist abgestürzt, dann konnte der Controller den Task einfach neu starten. Wenn eine Mail mehrfach einen Absturz verursacht hat, dann konnte der Überwachungsprozess die problematische Mail in die "Poison"-Queue verschieben. Siehe auch Poison.
Dieses Konzept wurde bei Exchange 2013 nun auch auf den Store und andere Prozesse ausgedehnt. Jede Datenbank hat nun ihren eigenen STORE.EXE-Prozess und wenn eine Datenbank einen nicht abgefangenen Fehler enthält, dann stört dies im schlimmsten Fall nur die Anwender dieser einen Datenbank. Wenn diese in der DAG läuft, dann wird die Kopie auf einem anderen Server aktiv geschaltet.
ähnliches gilt auch für andere Komponenten wie z.B. OWA etc., bei denen Exchange Dienste ein Problem recht schnell erkennen und die Anfrage des Clients über einen anderen Weg leiten, so dass der Anwender nichts oder nur minimal davon betroffen ist. Natürlich muss der Betreiber aktiv von solchen Problemen erfahren, denn jede Verfügbarkeit ist nur so gut wie ihre Überwachung.
Exchange Health Manager Service (MSExchangeHMHost.exe)
Die mit Exchange 2013 neue Komponente ist der Exchange Health Manager Service, der die "Gesundheit" des Systems überwacht. Er nutzt selbst dazu mehrere Worker, die sich die Arbeit teilen. Folgende drei Funktionseinheiten gibt es
- Probe Engine
Diese Komponente sammelt Betriebsdaten und führt Tests aus. Die Ergebnisse übergibt sie an den Monitor - Monitor
Der Monitor nimmt die Daten der Probe Engine und bewertet diese. Diese Instanz bestimmt also, ob der Server oder Service "Healthy" ist. - Responder Engine
Wurde der Status als "nicht Healthy" angesehen, dann ist es die Aufgabe der Responder Engine entsprechende Aktionen auszulösen. Zuerst wird die Engine versuchen z.B. den Dienst neu zu starten und wenn das nicht hilft, wird ein Eventlogeintrag geschrieben.
Die Ergebnisse dieser Überwachung werden aber auch von anderen Diensten genutzt, um z.B. in einer DAG den "Besten" Server zu ermitteln, der einen ausgefallenen Dienst übernehmen soll.
Diese automatischen Überwachungen sind in vielen Jahren Exchange Betrieb bei Office 365 entstanden und daher schon gut austariert. Es ist aber dennoch möglich, die Einstellungen anzupassen
- Get-ServerMonitoringOverride
http://technet.Microsoft.com/de-de/library/jj218664(v=exchg.150).aspx - Add-ServerMonitoringOverride
http://technet.Microsoft.com/de-DE/library/jj218628(v=exchg.150).aspx
Des weiteren Empfehle ich ihnen die Artikel auf dem Exchange Team Blog
- Lessons from the Datacenter:
Managed Availability
http://blogs.technet.com/b/exchange/archive/2012/09/21/lessons-from-the-datacenter-managed-availability.aspx - Storage, High Availability
and Site Resilience in Exchange
Server 2013
Part 1:http://blogs.technet.com/b/scottschnoll/archive/2012/09/19/storage-high-availability-and-site-resilience-in-exchange-server-2013-part-1.aspx
Part 2:http://blogs.technet.com/b/scottschnoll/archive/2012/10/01/storage-high-availability-and-site-resilience-in-exchange-server-2013-part-2.aspx
Transport-Routing
Auch die Transportfunktion wird aktiv überprüft. Das sehen sie z.B. schon alleine daran, wenn Sie einen Exchange 2013 Server neu installieren und gar keine Postfächer o.ä., anlegen. Schon hier werden viele Mails hin und her gesendet, wie das Messagetracking verrät.
[PS] C:\>(Get-MessageTrackingLog -Start (get-date).addminutes(-5) -EventId receive)
EventId Source Sender Recipients MessageSubject
------- ------ ------ ---------- --------------
RECEIVE SMTP HealthMailboxd57de77e5d4d4838b... {HealthMailboxd57de77e5d4d4838... MBTSubmission/StoreDriverSubmi...
RECEIVE SMTP HealthMailboxd57de77e5d4d4838b... {HealthMailboxd57de77e5d4d4838... MBTSubmission/StoreDriverSubmi...
RECEIVE SMTP HealthMailbox2dea1dea01264d95a... {HealthMailbox2dea1dea01264d95... Client submission probe
RECEIVE SMTP inboundproxy@inboundproxy.com {HealthMailbox2dea1dea01264d95... Inbound proxy probe
RECEIVE STORE... HealthMailboxd57de77e5d4d4838b... {HealthMailboxd57de77e5d4d4838... MBTSubmission/StoreDriverSubmi...
RECEIVE STORE... HealthMailboxd57de77e5d4d4838b... {HealthMailboxd57de77e5d4d4838... MBTSubmission/StoreDriverSubmi...
Sie können schon hier sehen, dass die Server sich untereinander Mails über die spezielle "HealthMailbox" senden und die Zustellung überprüfen.
Transport-Proxying
Anhand der Exchange 2013 funktionsweise wissen Sie ja nun, das der CAS eingehende Verbindungen einfach als ReverseProxy auf den Mailboxserver weiter gibt. Auch diese Funktion wird "getestet" und ist gut in den Logs zu sehen.
Etwas ungewöhnlich ist, dass Microsoft mit "inboundproxy@inboundproxy.com" SMTP-Adresse als Absender verwendet, die Microsoft zumindest nicht sichtbar gehört und erst einen Monat nach dem Release von Exchange 2013 registriert wurde.
Domain Name:
INBOUNDPROXY.COM
Registrar: 101DOMAIN, INC.
Whois Server: whois.101domain.com
Referral URL: http://www.101domain.com
Name Server: NS1.SEDOPARKING.COM
Name Server: NS2.SEDOPARKING.COM
Status: ok
Updated Date: 02-feb-2013
Creation Date: 13-jan-2013
Expiration Date: 13-jan-2014
Quelle:
http://www.whois.com/whois/inboundproxy.com
82.98.86.172. Inboundproxy.com resides at
Plus.line AG in Germany.
Quelle:
http://www.ip-adress.com/whois/inboundproxy.com
Sollte die Domäne wirklich jemand anderem gehören und würde er einen Mailserver aufsetzen, dann bekäme er sehr viele NDRs wenn die Testmails nicht zugestellt würden. Man kann auch sagen er bekäme eine nette Liste von installierten Exchange 2013 Umgebungen mit deren Outbound Hosts. Was auch immer man damit anfangen wollte.
Set-ContentFilterConfig -BypassedSenderDomains inboundproxy.com
- Exchange Server 2013 and the
Inboundproxy.com NDR Message
Problem
http://exchangeserverpro.com/exchange-server-2013-inboundproxy-com-ndr/ - Exchange 2013:
inboundproxy@inboundproxy.com, HealthMailbox stuck in Queue
http://social.technet.Microsoft.com/Forums/exchange/en-US/284ec38e-1f2b-4571-aead-66826079af20/exchange-2013-inboundproxyinboundproxycom-healthmailbox-stuck-in-queue
healtchcheck.htm Prüfung
Hinweis:
Diese URLs haben bis ca. Nov 2019
auch mit Exchange Online über die Url
https://outlook.office365.com/owa/healthcheck.htm u.a.
funktioniert. Seit ca Dez 2019 kommt hier aber immer nur ein
404-Fehler.
Endlich hat Microsoft viele Administratoren erhört und eine healthcheck.htm-Datei in den virtuellen Verzeichnissen abgelegt.
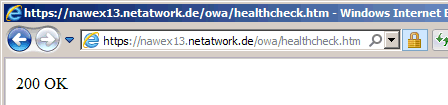
Diese Datei gibt es natürlich nicht wirklich sondern wird dynamisch erzeugt. Dies ist ein sehr guter Indikator, damit z.B. Loadbalancer diese Datei prüfen können und so CAS-Server aus der Verteilung nehmen, die kein "200 OK" melden. Diese Prüfung ist mit allen virtuellen Exchange Verzeichnissen möglich:
https://<servername>/owa/healthcheck.htm https://<servername>/ecp/healthcheck.htm https://<servername>/ews/healthcheck.htm https://<servername>/OAB/healthcheck.htm https://<servername>/rpc/healthcheck.htm https://<servername>/mapi/healthcheck.htm https://<servername>/Microsoft-Server-ActiveSync/healthcheck.htm
Bei einem Exchange Backend Server müssen Sie eine etwas andere URL verwenden
https://<servername>:444/ecp/exhealth.check
Natürlich können Sie diese einfachen Checks auch mit Nagios oder anderen Werkzeugen nutzen, um eine bessere Verfügbarkeitsprüfung von Exchange Webdiensten zu erhalten.
Hinweis zu Loadbalancer
In der Regel konfiguriert man einen Loadbalancer
so, dass er die Erreichbarkeit des Backend
Service prüft. Statt eines einfachen PING sind
"hochwertigere" Checks ratsam, wozu sich diese
healthcheck.htm anbietet. Muss der Kemp nun
mehrere Dienste auf dem gleichen Backend IIS
prüfen, so nutzt er die gleiche TCP-Verbindung.
Exchange 2013 terminiert aber die TCP-Connection
aktiv, wenn die Anfrage ein "Fail" liefert.
Einige Loadbalancer können die anderen
Services dann auch nicht mehr prüfen, da die
TCP-Connection schon weg ist und setzen weitere Dienst auf
dem Server auf "Down".
Lösung: Stellen Sie in der Abfrage auf HTTP 1.0 um, dann prüft z.B. Kemp jede URL über eine eigene
TCP-Session und der RESET des Servers ist kein
Problem mehr. Hier am Beispiel eines Kemp
Loadmaster
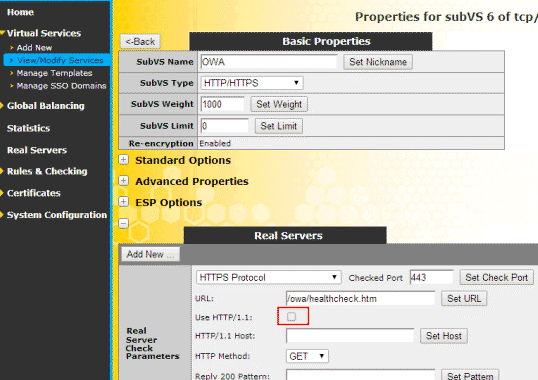
CAS Check
Aber auch untereinander prüfen Sie die CAS-Server gegenseitig über "PINGs" ab. Hier der Auszug eines Exchange 2010 IISLogs in einer gemischten Umgebung. Der Exchange 2013 CAS prüft die Erreichbarkeit der Exchange 2010 Dienste:
2013-06-07 15:36:37 192.168.100.8 GET /owa - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 301 0 0 0 2013-06-07 15:36:37 192.168.100.8 GET /owa/ - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0 2013-06-07 15:36:37 192.168.100.8 GET /owa/auth/logon.aspx URL=https://ex2010.msxfaq.de/owa/&reason=0 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 200 0 0 0
Aber auch ein Exchange 2013 CAS Server alleine schreibt ca. 12 Megabyte IISlog pro Tag alleine für seine Selbstüberwachung.
Dabei werden auf dem CAS-Server folgende URLs angesprochen.
POST /owa/auth.owa - 443 HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de 127.0.0.1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING;+OWACTP) - 302 0 0 15 GET /OWA/Calendar/HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de/calendar/calendar.html - 443 - 127.0.0.1 AMProbe/Local/ClientAccess - 200 0 0 15 GET /ecp/ReportingWebService/ - 443 - ::1 AMProbe/Local/ClientAccess - 302 0 0 15 2013-05-04 00:02:44 ::1 GET /AutoDiscover/ - 443 MSXFAQ\SM_f1404bcce2364f13b ::1 AMProbe/Local/ClientAccess - 200 0 0 15 2013-05-04 00:02:44 127.0.0.1 GET /Microsoft-Server-ActiveSync/default.eas - 443 HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de 127.0.0.1 AMProbe/Local/ClientAccess - 200 0 0 15 2013-05-04 00:02:44 127.0.0.1 GET /OAB/ - 443 MSXFAQ\SM_f1404bcce2364f13b 127.0.0.1 AMProbe/Local/ClientAccess - 200 0 0 0 2013-05-04 00:02:44 ::1 GET /ews/ - 443 MSXFAQ\SM_f1404bcce2364f13b ::1 AMProbe/Local/ClientAccess - 200 0 0 0 2013-05-04 00:02:50 127.0.0.1 POST /owa/service.svc action=GetFolderMrUConfiguration 443 HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de 127.0.0.1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING;+OWACTP) - 200 0 0 46 2013-05-04 00:02:50 127.0.0.1 GET /owa/logoff.owa - 443 HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de 127.0.0.1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING;+OWACTP) - 302 0 0 15 2013-05-04 00:02:57 127.0.0.1 GET /OWA/Calendar/HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de/calendar/calendar.html - 443 - 127.0.0.1 AMProbe/Local/ClientAccess - 200 0 0 15 2013-05-04 00:03:00 ::1 RPC_IN_DATA /RPC/rpcproxy.dll 1f3772cb-4b57-4f8d-9297-a7b579649b42@msxfaq.de&RequestId=199f97df-a8e7-4056-996a-9b0be234ddcf 443 MSXFAQ\SM_f1404bcce2364f13b ::1 AMProbe/Local/ClientAccess - 200 0 0 0 2013-05-04 00:03:19 fe80::fdf3:c513:ee8a:81df%13 POST /PowerShell clientApplication=ActiveMonitor;PSVersion=3.0&sessionID=Version_15.0_(Build_619.0)=rJqNiZqNgbG+qLqnzszRkZqLnouIkI2U0Zuagc7Gy87GxsnOy8+Bz8vRz8rRzc/OzN/Pz8XOzsXOxg== 80 MSXFAQ\SM_f1404bcce2364f13b fe80::fdf3:c513:ee8a:81df%13 Microsoft+WinRM+Client - 200 0 0 93 2013-05-04 00:05:07 fe80::fdf3:c513:ee8a:81df%13 POST /ecp/RulesEditor/InboxRules.svc/GetList msExchEcpCanary=Cc2JvWbJ2U2l2DS8jmSVltNHCSxyFtAIr6cn-Z04-IiA71lLTBuqolmH_Ze048b7plS8oco-zA0. 443 HealthMailbox9d246b94d86a47e69d886eb053a0a32a@msxfaq.de fe80::fdf3:c513:ee8a:81df%13 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING) - 200 0 0 93 ...
Noch extremer ist es auf dem MB-Server, der letztlich auch die Anfragen bedient. Hier kommen schon allein bei "Ruhe" knapp 50 MB/Tag zusammen:
Hier werden z.B. folgende URLs angesprochen:
2013-05-01 00:00:11 ::1 GET /ews/exchange.asmx/s/GetUserPhoto email=HealthMailbox846b84af54404debb80b3688b3d58207@msxfaq.de&size=HR96x96&trace=1 444 - ::1 - - 401 1 2148074254 0 2013-05-01 00:00:14 127.0.0.1 POST /ews/exchange.asmx - 444 - 127.0.0.1 AMProbe/EwsMailbox+(ExchangeServicesClient/15.00.0620.000) - 401 0 0 46 2013-05-01 00:00:14 fe80::fdf3:c513:ee8a:81df%13 RPC_IN_DATA /rpc/rpcproxy.dll ex2013.msxfaq.de:6001&RequestId=431e7aa7-5cd1-4be0-9062-5c13adb7e4d1 444 - fe80::fdf3:c513:ee8a:81df%13 MSRPC - 401 1 2148074254 0 2013-05-01 00:00:16 ::1 GET /owa/exhealth.check - 444 - ::1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING;+OWASELFTEST) - 200 0 0 15 2013-05-01 00:00:16 ::1 GET /ecp/ping.ecp ActID=799f5ede-6554-450c-96e9-7d9cb39a55c0 444 - ::1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING) - 200 0 0 31 2013-05-01 00:00:39 ::1 OPTIONS /Microsoft-Server-ActiveSync/Proxy - 444 - ::1 TestActiveSyncConnectivity - 401 1 2148074254 15 2013-05-01 00:00:39 ::1 POST /owa/proxylogon.owa - 444 MSXFAQ\SM_d5199e27fb6c4e62a ::1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING;+OWADEEPTEST) - 241 0 0 15 2013-05-01 00:00:39 127.0.0.1 POST /ecp/RulesEditor/InboxRules.svc/GetList msExchEcpCanary=Ic4l59RYuECT0FGZ3WoUOJX4dWGoFdAImq1vv_ezQ2YiFbwqvykTN86_apPtd6yS84lpwnWDyUU.&ActID=69a39593-faf9-44c2-af62-bf1ca031d59f 444 MSXFAQ\SM_d5199e27fb6c4e62a 127.0.0.1 Mozilla/4.0+(compatible;+MSIE+9.0;+Windows+NT+6.1;+MSEXCHMON;+ACTIVEMONITORING) - 200 0 0 78
Aber auch Exchange 2010 Server bleiben nicht ungeschoren. Der Exchange 2013 prüft immer wieder die "Verfügbarkeit" von Exchange 2010 Webserivces, damit er Client, die während der Migration über den Exchange 2013 CAS ankommen auch auf einem verfügbaren Exchange 2010 CAS durch geleitet werden (Proxy)
2013-06-09 00:00:05 192.168.100.8 HEAD /OAB - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0 2013-06-09 00:00:05 192.168.100.8 HEAD /EWS - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 0 0 0 2013-06-09 00:00:10 192.168.100.8 HEAD /PowerShell - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 0 0 124 2013-06-09 00:00:24 192.168.100.8 HEAD /owa/Calendar - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 400 0 0 0 2013-06-09 00:00:36 192.168.100.8 GET /owa - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 301 0 0 0 2013-06-09 00:00:36 192.168.100.8 GET /owa/ - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0 2013-06-09 00:00:36 192.168.100.8 GET /owa/auth/logon.aspx URL=https://nawex001.netatwork.de/owa/&reason=0 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 200 0 0 15 2013-06-09 00:00:44 192.168.100.8 HEAD /Autodiscover - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 301 0 0 0 2013-06-09 00:00:44 192.168.100.8 HEAD /Autodiscover/ - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 200 0 0 0 2013-06-09 00:00:44 192.168.100.8 HEAD /ecp - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 302 0 0 0 2013-06-09 00:00:44 192.168.100.8 HEAD /ecp/ - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 404 4 2 0 2013-06-09 00:00:46 192.168.100.8 RPC_IN_DATA /rpc/rpcproxy.dll - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0 2013-06-09 00:00:54 192.168.100.8 GET /owa - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 301 0 0 0 2013-06-09 00:00:54 192.168.100.8 GET /owa/ - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0 2013-06-09 00:00:54 192.168.100.8 GET /owa/auth/logon.aspx URL=https://nawex001.netatwork.de/owa/&reason=0 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 200 0 0 0 2013-06-09 00:00:54 192.168.100.8 HEAD /Microsoft-Server-ActiveSync/default.eas - 443 - 192.168.100.32 HttpProxy.ClientAccessServer2010Ping 401 2 5 0
Und das wird jede Minute wiederholt. Zugriffe eines Clients auf den Server erkennt man aber gut an der Authentifizierung:
2013-06-09 07:32:32 192.168.100.8 POST /ews/exchange.asmx - 443 - 192.168.100.32 ExchangeInternalEwsClient-EwsStoreDataProvider+(ExchangeServicesClient/15.00.0620.000) 401 0 0 0 2013-06-09 07:32:32 192.168.100.8 POST /ews/exchange.asmx - 443 MSXFAQ\NAWEX13$ 192.168.100.32 ExchangeInternalEwsClient-EwsStoreDataProvider+(ExchangeServicesClient/15.00.0620.000) 200 0 0 156 2013-06-09 07:32:32 192.168.100.8 POST /ews/exchange.asmx - 443 - 192.168.100.32 ExchangeInternalEwsClient-EwsStoreDataProvider+(ExchangeServicesClient/15.00.0620.000) 401 0 0 0 2013-06-09 07:32:32 192.168.100.8 POST /ews/exchange.asmx - 443 MSXFAQ\NAWEX13$ 192.168.100.32 ExchangeInternalEwsClient-EwsStoreDataProvider+(ExchangeServicesClient/15.00.0620.000) 200 0 0 93
Test-Commandlets
Eine Suche nach "health" in den PowerShell Commandlets zeigt, dass es eine Gruppe von Befehlen rund um "Managed Availability" gibt:
[PS] C:\get-help "health" Name Category Module Synopsis ---- -------- ------ -------- Get-HealthReport Cmdlet use the Get-HealthReport cmdlet to return heal... Get-ServerHealth Cmdlet use the Get-ServerHealth cmdlet to return heal... Test-AssistantHealth Cmdlet use the Test-AssistantHealth cmdlet to verify ... Test-MRSHealth Cmdlet use the Test-MRSHealth cmdlet to test the heal... Test-ReplicationHealth Cmdlet use the Test-ReplicationHealth cmdlet to check... Test-ServiceHealth Cmdlet use the Test-ServiceHealth cmdlet to test whet...
Interessant ist dabei natürlich alles, was mit "Test-" beginnt. Hier eine Beispielausgabe.
[PS] C:\>Test-ServiceHealth
Role : Mailbox Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeDelivery, MSExchangeIS,
MSExchangeMailboxAssistants, MSExchangeRepl, MSExchangeRPC, MSExchangeServiceHost,
MSExchangeSubmission, MSExchangeThrottling, MSExchangeTransportLogSearch, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Client Access Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeMailboxReplication, MSExchangeRPC,
MSExchangeServiceHost, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Unified Messaging Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeServiceHost, MSExchangeUM, W3Svc, WinRM}
ServicesNotRunning : {}
Role : Hub Transport Server Role
RequiredServicesRunning : True
ServicesRunning : {IISAdmin, MSExchangeADTopology, MSExchangeEdgeSync, MSExchangeServiceHost,
MSExchangeTransport, MSExchangeTransportLogSearch, W3Svc, WinRM}
ServicesNotRunning : {}
Auch "Test-MRSHealth" testet nicht nur ob der Replication Service läuft, sondern auch dessen Reaktionszeit auf Anfragen und seine Queue;
[PS] C:\>Test-MRSHealth
RunspaceId : 3a7723d2-c609-41ad-b785-b4dea4ea6b7c
Check : ServiceCheck
Passed : True
Message : The Mailbox Replication Service is running.
Identity : ex2013
IsValid : True
ObjectState : New
RunspaceId : 3a7723d2-c609-41ad-b785-b4dea4ea6b7c
Check : RPCPingCheck
Passed : True
Message : The Microsoft Exchange Mailbox Replication service is responding to
a RPC ping. Server version: 15.0.620.24 caps:3F.
Identity : ex2013
IsValid : True
ObjectState : New
RunspaceId : 3a7723d2-c609-41ad-b785-b4dea4ea6b7c
Check : QueueScanCheck
Passed : True
Message : The Microsoft Exchange Mailbox Replication service is scanning mailbox
database queues für jobs. Last scan age: 00:09:05.4650000.
Identity : ex2013
IsValid : True
ObjectState : New
Der große Oberbegriff ist aber hinter "Get-HealthReport" verborgen. Hier sehen Sie die verschiedenen "Healthsets", die verschiedene Tests zusammenfassen und deren Status sie so sehr schnell sehen können.
[PS] C:\Windows\system32>Get-HealthReport -Identity ex2013 Server State HealthSet AlertValue LastTransitionTime MonitorCount ------ ----- --------- ---------- ------------------ ------------ ex2013 NotApplicable ActiveSync Healthy 5/7/2013 1:34:04 PM 3 ex2013 NotApplicable ActiveSync.Protocol Healthy 6/7/2013 4:50:32 PM 7 ex2013 NotApplicable Autodiscover.Pro... Unhealthy 6/7/2013 10:02:5... 4 ex2013 NotApplicable Autodiscover unhealthy 6/7/2013 10:28:2... 1 ex2013 NotApplicable DataProtection unhealthy 6/9/2013 9:06:02 AM 17 ex2013 NotApplicable Antimalware Degraded 6/9/2013 11:16:4... 8 ex2013 NotApplicable ECP Healthy 6/7/2013 4:50:09 PM 3 ex2013 NotApplicable AD Healthy 5/7/2013 1:35:44 PM 10 ex2013 Online Autodiscover.Proxy Healthy 6/7/2013 9:38:45 AM 1 ex2013 Online ActiveSync.Proxy Healthy 6/7/2013 9:38:34 AM 1 ex2013 Online ECP.Proxy Healthy 6/7/2013 4:28:35 PM 4 ex2013 Online EWS.Proxy Healthy 4/24/2013 2:49:0... 1 ex2013 Online OAB.Proxy Healthy 4/24/2013 2:49:0... 1 ex2013 Online OWA.Proxy Healthy 6/7/2013 4:33:09 PM 2 ex2013 NotApplicable Ediscovery.Protocol Healthy 6/7/2013 12:47:1... 1 ex2013 Online RPS.Proxy Healthy 5/7/2013 1:35:48 PM 13 ex2013 Online RWS.Proxy Healthy 6/7/2013 9:35:04 AM 10 ex2013 Online Outlook.Proxy Healthy 4/24/2013 2:49:0... 1 ex2013 NotApplicable EDS Healthy 6/7/2013 9:35:11 AM 13 ex2013 NotApplicable EventAssistants Healthy 6/7/2013 9:54:38 AM 5 ex2013 NotApplicable EWS.Protocol Healthy 5/7/2013 1:34:42 PM 5 ex2013 NotApplicable FIPS Degraded 6/9/2013 11:01:4... 18 ex2013 NotApplicable HDPhoto Healthy 5/7/2013 1:43:52 PM 1 ex2013 NotApplicable Monitoring unhealthy 6/7/2013 9:48:12 AM 9 ex2013 NotApplicable EWS Healthy 4/24/2013 2:49:0... 1 ex2013 Online FrontendTransport Healthy 6/7/2013 9:47:30 AM 11 ex2013 Online HubTransport unhealthy 6/9/2013 9:56:39 AM 138 ex2013 NotApplicable Clustering Healthy 5/7/2013 1:33:16 PM 4 ex2013 NotApplicable DiskController Healthy 5/7/2013 1:39:32 PM 1 ex2013 NotApplicable AntiSpam Healthy 6/7/2013 9:35:06 AM 4 ex2013 NotApplicable OWA.Protocol.Dep Healthy 6/7/2013 9:35:10 AM 1 ex2013 NotApplicable FfoQuarantine Healthy 4/24/2013 2:49:5... 1 ex2013 NotApplicable MailboxTransport unhealthy 6/9/2013 4:26:28 AM 57 ex2013 NotApplicable MSExchangeCertif... Disabled 1/1/0001 1:00:00 AM 2 ex2013 NotApplicable MailboxSpace Healthy 6/7/2013 9:52:22 AM 4 ex2013 NotApplicable MailboxMigration Healthy 5/7/2013 1:33:00 PM 4 ex2013 NotApplicable MRS Healthy 5/7/2013 1:34:40 PM 9 ex2013 NotApplicable Network Healthy 6/7/2013 9:45:20 AM 1 ex2013 NotApplicable OWA.Protocol Healthy 6/7/2013 4:50:25 PM 5 ex2013 NotApplicable OWA Healthy 6/7/2013 4:30:04 PM 1 ex2013 NotApplicable PublicFolders Healthy 6/7/2013 9:42:41 AM 4 ex2013 NotApplicable RPS Healthy 5/5/2013 8:44:42 AM 1 ex2013 NotApplicable Outlook.Protocol Healthy 6/7/2013 4:55:51 PM 3 ex2013 Online Transport Healthy 6/7/2013 9:35:11 AM 9 ex2013 NotApplicable SiteMailbox Healthy 5/7/2013 1:30:39 PM 3 ex2013 NotApplicable Store Healthy 6/7/2013 9:41:54 AM 18 ex2013 Online UM.CallRouter Healthy 6/7/2013 9:35:17 AM 7 ex2013 NotApplicable UM.Protocol Healthy 6/7/2013 4:17:41 PM 17 ex2013 NotApplicable UserThrottling Healthy 6/7/2013 10:01:0... 7 ex2013 NotApplicable DAL Healthy 4/24/2013 2:50:1... 16 ex2013 NotApplicable Outlook Healthy 6/4/2013 3:57:31 PM 5 ex2013 NotApplicable Search Healthy 6/7/2013 12:36:5... 39 ex2013 NotApplicable Security Healthy 5/7/2013 1:35:08 PM 3 ex2013 NotApplicable IMAP.Protocol Healthy 5/7/2013 1:35:06 PM 3 ex2013 NotApplicable Datamining Healthy 4/24/2013 2:52:4... 3 ex2013 NotApplicable Provisioning Healthy 5/7/2013 1:31:49 PM 3 ex2013 NotApplicable POP.Protocol Healthy 5/7/2013 1:35:13 PM 3 ex2013 NotApplicable ProcessIsolation Healthy 5/7/2013 1:35:50 PM 12 ex2013 NotApplicable TransportSync Healthy 5/7/2013 1:32:47 PM 3 ex2013 NotApplicable MessageTracing Healthy 5/7/2013 1:36:07 PM 3 ex2013 NotApplicable CentralAdmin Healthy 5/7/2013 1:32:28 PM 3 ex2013 NotApplicable OAB Healthy 5/7/2013 1:31:58 PM 3 ex2013 NotApplicable Calendaring Healthy 5/7/2013 1:34:37 PM 3 ex2013 NotApplicable PushNotification... Healthy 5/7/2013 1:33:08 PM 3 ex2013 NotApplicable RemoteMonitoring Healthy 4/24/2013 2:54:4... 1 ex2013 NotApplicable FEP Healthy 5/7/2013 10:48:2... 1
Nicht alles was "unhealthy" ist, ist auch kritisch. Der State darf dabei natürlich nicht auf "NotApplicable" stehen.
Wenn Sie mehr über jeden einzelnen Test erfahren wollen, dann ist "Get-ServerHealth" das Mittel der Wahl. Allerdings liefert dieses Commandelt noch viel mehr Daten zurück. Bei mir sind es 559 Checks. Hier sollte bei der Ausgabe dann doch gefiltert werden:
[PS] C:\>(Get-ServerHealth ex2013).count
559
[PS] C:\>Get-ServerHealth ex2013 | ? {$_.alertvalue -ne "Healthy"}
Server State Name TargetResource HealthSetName AlertValue ServerComp
onent
------ ----- ---- -------------- ------------- ---------- ----------
ex2013 NotApplicable AutodiscoverSelfT... MSExchangeAutoDis... Autodiscover... Unhealthy None
ex2013 NotApplicable AutodiscoverCtpMo... ex2013.msxfaq.de Autodiscover unhealthy None
ex2013 NotApplicable ScanTimeMonitor Antimalware Degraded None
ex2013 NotApplicable ScanTimeMeanMonitor FIPS Degraded None
ex2013 NotApplicable MaintenanceFailur... Monitoring unhealthy None
ex2013 NotApplicable DatabaseHealthLog... Mailbox Database ... DataProtection unhealthy None
ex2013 Online Messages.failed.t... HubTransport unhealthy HubTran...
ex2013 Online Transport.NDRForU... HubTransport HubTransport Disabled HubTran...
ex2013 Online TransportLogGener... HubTransport Disabled HubTran...
ex2013 Online TransportCategori... HubTransport Disabled HubTran...
ex2013 Online FederatedDecrypti... HubTransport Disabled HubTran...
ex2013 Online TransportDelivery... HubTransport Disabled HubTran...
ex2013 Online TransportDelivery... HubTransport Disabled HubTran...
ex2013 NotApplicable TransportDelivery... MailboxTrans... Disabled None
ex2013 Online IsMemberOfResolve... HubTransport Disabled HubTran...
ex2013 Online IsMemberOfResolve... HubTransport Disabled HubTran...
ex2013 Online Transport.DomainS... HubTransport HubTransport Disabled HubTran...
ex2013 Online Transport.DomainS... HubTransport HubTransport Disabled HubTran...
ex2013 Online TlsDomainClientCe... HubTransport HubTransport Disabled HubTran...
ex2013 Online Transport.DomainS... HubTransport HubTransport Disabled HubTran...
ex2013 Online Transport.DomainS... HubTransport HubTransport Disabled HubTran...
ex2013 NotApplicable TransportFedCertM... MSExchangeCertifi... MSExchangeCe... Disabled None
ex2013 NotApplicable TransportFedCertE... MSExchangeCertifi... MSExchangeCe... Disabled None
ex2013 NotApplicable MSExchangeAssista... MailboxTrans... Unhealthy None
ex2013 NotApplicable MSExchangeAssista... MailboxTrans... Unhealthy None
ex2013 NotApplicable Mapi.Submit.Monitor MailboxTransport MailboxTrans... Unhealthy None
ex2013 Online MessageCountMonitor Transport Transport Disabled HubTran...
ex2013 Online DeferredMessageCo... Transport Transport Disabled HubTran...
ex2013 Online AverageMessageCou... Transport Transport Disabled HubTran...
ex2013 Online TotalMessageCount... Transport Transport Disabled HubTran...
ex2013 Online MessageCountExcee... Transport Transport Disabled HubTran...
ex2013 Online MessageCountExcee... Transport Transport Disabled HubTran...
ex2013 Online AggregatedQueueMo... Transport Disabled HubTran...
Sie sehen hier auch die Spalte "HealthSet", so dass Sie erkennen zu welchem Set der individuelle Test gehört. Die Fehler hier sind überwiegend durch meine Muster-VM verursacht, die mit recht wenige Hauptspeicher und Festplattenplatz auskommen muss.
Eventlog
Wie für jede gute Windows Software üblich, sollten Fehler dort hin geschrieben werden, wo ein Administrator oder eine Monitoring-Lösung am einfachsten nachschauen kann. So protokolliert Exchange auch die meisten Fehler direkt im Eventlog. Hier z.B. ein Exchange 2010 CAS-Server der vom Exchange 2013 Anfragen erhalten soll.
Wenn ich es recht gesehen habe, dann führt das Exchange 2013 Managementpack für System Center selbst gar keine aktiven Tests mehr aus, sondern vertraut auf die Exchange 2013 Überwachung und beschränkt sich auf das Auslesen der Eventlogeinträge.
Log Name: Application Source: MSExchange Front End HTTP Proxy Event ID: 3005 Task Category: Core Level: Warning Keywords: Classic User: N/A Computer: EX13.msxfaq.de Description: [Oab] Marking ClientAccess 2010 server ex2010.msxfaq.de (https://ex2010.msxfaq.de/OAB) as unhealthy due to exception: System.Net.WebException: The remote server returned an error: (503) Server unavailable. at System.Net.HttpWebRequest.GetResponse() at Microsoft.Exchange.HttpProxy.ProtocolPingStrategyBase.Ping(Uri URL)
Log Name: Application Source: MSExchange Front End HTTP Proxy Event ID: 3005 Task Category: Core Level: Warning Keywords: Classic User: N/A Computer: ex2013.msxfaq.de Description: [Ews] Marking ClientAccess 2010 server ex2010.msxfaq.de (https://ex2010.msxfaq.de/EWS) as unhealthy due to exception: System.Net.WebException: The operation has timed out at System.Net.HttpWebRequest.GetResponse() at Microsoft.Exchange.HttpProxy.ProtocolPingStrategyBase.Ping(Uri URL)
Hier landen auch noch die meisten Events, wenn Sie mit "Set-EventlogLevel" den Protokollierungslevel anheben. Aber mittlerweile gibt es noch andere Eventlogs, die durchaus interessant sind:
Interessant ist hier auf jeden Fall das "Monitoring" Log und darin enthaltene Fehler. Gerade am Anfang können das schon einige Meldungen sind.
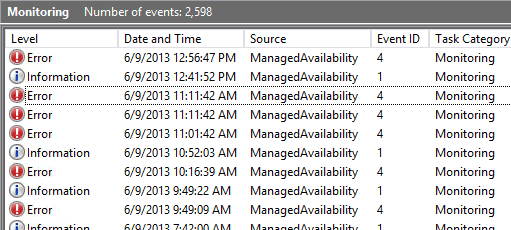
Hier mal ein paar Meldungen als Auszug:
Mean Scan Time has been greater than 60 seconds für the last 15 mins. Please investigate.
The MailboxTransport Health Set has detected a problem with NAWEX13 at 07.06.2013 15:10:08. Attempts to auto-recover from this condition have failed and requires Administrator attention.
Malware filtering is taking too long (90th percentile)
Maintenance workitem "Process.Isolation.Maintenance.Workitem" (ID: 61) has failed. Health Manager has detected it is either set to run once and failed, or has been failing consistently. Maintenance workitem failure could cause monitoring gap and should be investigated. The error message from the last result is: workitem completed with result: TimedOut
Retry Mailbox Delivery Queue Length is more than 750 over the last 15 minutes
Internal aggregate delivery queue length für normal priority messages is more than 3000 over the last 15 minutes
Und dann gibt es natürlich noch eine große umfassende Meldung:
Log Name: Microsoft-Exchange-ManagedAvailability/Monitoring Source: Microsoft-Exchange-ManagedAvailability Date: 6/9/2013 12:56:47 PM Event ID: 4 Task Category: Monitoring Level: Error Keywords: User: SYSTEM Computer: NAWEX13.netatwork.de Description: Mean Scan Time has been greater than 60 seconds für the last 15 mins. Please investigate. ------------------------------------------------------------------------------- States of all monitors within the health set: Note: Data may be stale. To get current data, run: Get-ServerHealth -Identity 'NAWEX13' -HealthSet 'FIPS' State Name TargetResource HealthSet AlertValue ServerComponent ----- ---- -------------- --------- ---------- --------------- NotApplicable ScanProcessesRunningMonitor FIPS Healthy None NotApplicable ScanProcessBelowMinimumMonitor FIPS Healthy None NotApplicable ScanRequestsTimedOutMonitor FIPS Healthy None NotApplicable ScanRequestsTimedOutUrgentMonitor FIPS Healthy None NotApplicable ScanTimeMeanMonitor FIPS Healthy None NotApplicable ScanRequestErrorsMonitor FIPS Healthy None NotApplicable ObsoleteEngineInUseEventMonitor FIPS FIPS Healthy None NotApplicable EngineNotEnabledForUpdatesEventMonitor FIPS FIPS Healthy None NotApplicable EUSTerminationEventMonitor FIPS FIPS Healthy None NotApplicable EUSUnableToStartEventMonitor FIPS FIPS Healthy None NotApplicable ScanningProcessRepeatedlyCrashingMon... FIPS FIPS Healthy None NotApplicable FilteringManagementServiceDownMonitor FIPS Healthy None NotApplicable PrivateWorkingSetWarningThresholdExc... fms FIPS Healthy None NotApplicable ProcessProcessorTimeErrorThresholdEx... fms FIPS Healthy None NotApplicable MicrosoftFailedUpdatesMonitor FIPS Healthy None NotApplicable MicrosoftEngineErrorsMonitor FIPS Healthy None NotApplicable MSClassificationEngineErrorsMonitor FIPS Healthy None NotApplicable ExchangeCrashEventErrorThresholdExce... fms FIPS Healthy None States of all health sets: Note: Data may be stale. To get current data, run: Get-HealthReport -Identity 'NAWEX13' State HealthSet AlertValue LastTransitionTime MonitorCount ----- --------- ---------- ------------------ ------------ NotApplicable ActiveSync Healthy 07.05.2013 13:34:04 3 NotApplicable ActiveSync.Protocol Healthy 07.06.2013 16:50:32 7 NotApplicable Autodiscover.Protocol unhealthy 07.06.2013 10:02:58 4 NotApplicable Autodiscover unhealthy 07.06.2013 10:28:26 1 NotApplicable DataProtection unhealthy 09.06.2013 09:06:02 17 NotApplicable Antimalware Degraded 09.06.2013 11:16:42 8 NotApplicable ECP Healthy 07.06.2013 16:50:09 3 NotApplicable AD Healthy 07.05.2013 13:35:44 10 Online Autodiscover.Proxy Healthy 07.06.2013 09:38:45 1 Online ActiveSync.Proxy Healthy 07.06.2013 09:38:34 1 Online ECP.Proxy Healthy 07.06.2013 16:28:35 4 Online EWS.Proxy Healthy 24.04.2013 14:49:07 1 Online OAB.Proxy Healthy 24.04.2013 14:49:07 1 Online OWA.Proxy Healthy 07.06.2013 16:33:09 2 NotApplicable Ediscovery.Protocol Healthy 07.06.2013 12:47:11 1 Online RPS.Proxy Healthy 07.05.2013 13:35:48 13 Online RWS.Proxy Healthy 07.06.2013 09:35:04 10 Online Outlook.Proxy Healthy 24.04.2013 14:49:07 1 NotApplicable EDS Healthy 07.06.2013 09:35:11 13 NotApplicable EventAssistants Healthy 07.06.2013 09:54:38 5 NotApplicable EWS.Protocol Healthy 07.05.2013 13:34:42 5 NotApplicable FIPS Healthy 09.06.2013 12:41:46 18 NotApplicable HDPhoto Healthy 07.05.2013 13:43:52 1 NotApplicable Monitoring unhealthy 07.06.2013 09:48:12 9 NotApplicable EWS Healthy 24.04.2013 14:49:08 1 Online FrontendTransport Healthy 07.06.2013 09:47:30 11 Online HubTransport unhealthy 09.06.2013 09:56:39 13 NotApplicable Clustering Healthy 07.05.2013 13:33:16 4 NotApplicable DiskController Healthy 07.05.2013 13:39:32 1 NotApplicable AntiSpam Healthy 07.06.2013 09:35:06 4 NotApplicable OWA.Protocol.Dep Healthy 07.06.2013 09:35:10 1 NotApplicable FfoQuarantine Healthy 24.04.2013 14:49:53 1 NotApplicable MailboxTransport unhealthy 09.06.2013 04:26:28 57 NotApplicable MSExchangeCertificat... Disabled 01.01.0001 01:00:00 2 NotApplicable MailboxSpace Healthy 07.06.2013 09:52:22 4 NotApplicable MailboxMigration Healthy 07.05.2013 13:33:00 4 NotApplicable MRS Healthy 07.05.2013 13:34:40 9 NotApplicable Network Healthy 07.06.2013 09:45:20 1 NotApplicable OWA.Protocol Healthy 07.06.2013 16:50:25 5 NotApplicable OWA Healthy 07.06.2013 16:30:04 1 NotApplicable PublicFolders Healthy 07.06.2013 09:42:41 4 NotApplicable RPS Healthy 05.05.2013 08:44:42 1 NotApplicable Outlook.Protocol Healthy 07.06.2013 16:55:51 3 Online Transport Healthy 07.06.2013 09:35:11 9 NotApplicable SiteMailbox Healthy 07.05.2013 13:30:39 3 NotApplicable Store Healthy 07.06.2013 09:41:54 18 Online UM.CallRouter Healthy 07.06.2013 09:35:17 7 NotApplicable UM.Protocol Healthy 07.06.2013 16:17:41 17 NotApplicable UserThrottling Healthy 07.06.2013 10:01:06 7 NotApplicable DAL Healthy 24.04.2013 14:50:10 16 NotApplicable Outlook Healthy 04.06.2013 15:57:31 5 NotApplicable Search Healthy 07.06.2013 12:36:54 39 NotApplicable Security Healthy 07.05.2013 13:35:08 3 NotApplicable IMAP.Protocol Healthy 07.05.2013 13:35:06 3 NotApplicable Datamining Healthy 24.04.2013 14:52:47 3 NotApplicable Provisioning Healthy 07.05.2013 13:31:49 3 NotApplicable POP.Protocol Healthy 07.05.2013 13:35:13 3 NotApplicable ProcessIsolation Healthy 07.05.2013 13:35:50 12 NotApplicable TransportSync Healthy 07.05.2013 13:32:47 3 NotApplicable MessageTracing Healthy 07.05.2013 13:36:07 3 NotApplicable CentralAdmin Healthy 07.05.2013 13:32:28 3 NotApplicable OAB Healthy 07.05.2013 13:31:58 3 NotApplicable Calendaring Healthy 07.05.2013 13:34:37 3 NotApplicable PushNotifications.Pr... Healthy 07.05.2013 13:33:08 3 NotApplicable RemoteMonitoring Healthy 24.04.2013 14:54:40 1 NotApplicable FEP Healthy 07.05.2013 10:48:20 1 Note: Subsequent detected alerts are suppressed until the health set is healthy again.
Aber auch für einzelne Events gibt es eigenständige Eventlogeinträge
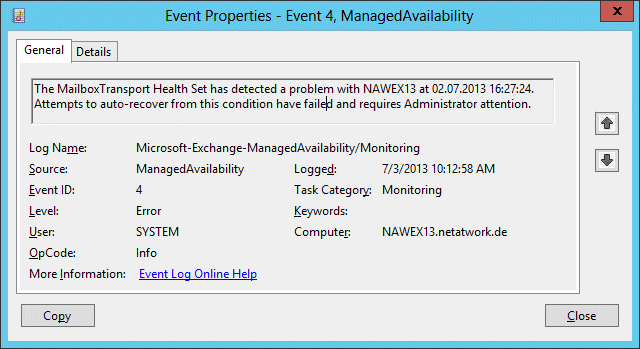
Bluescreen durch Managed Availibility
Ja, Exchange überwacht sich selbst und im schlimmsten Falle initiiert Exchange einen Bluescreen !!. Das ist aber nicht neu bei Exchange 2013, sondern diese Funktion wurde schon in Exchange 2010 SP1 eingebaut. Immer wenn Exchange bemerkt, dass Disk-IOs zu lange dauern, dann meldet er das und im schlimmsten Fall "hilft" er sich durch einen Reboot, indem er den WININIT-Prozess abschießt. (0x000000ef)
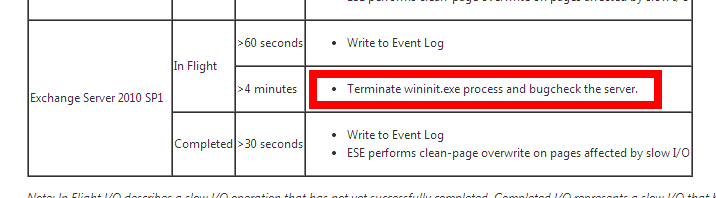
Das macht Exchange 2013 natürlich auch, wobei hier auch andere Probleme zum Bugcheck ((0x000000ef)) führen können:
CRITICAL_OBJECT_TERMINATION (f4) A process or thread crucial to system operation has unexpectedly exited or been terminated. Several processes and threads are necessary für the operation of the system; when they are terminated (for any reason), the system can no longer function.
Wenn Sie den Fehler noch diagnostizieren, kann es hilfreich sein diese Überwachung temporär zu deaktivieren:
Add-GlobalMonitoringOverride ` -Identity exchange\ActiveDirectoryConnectivityConfigDCServerReboot ` -ItemType Responder ` -PropertyName Enabled ` -PropertyValue 0 -Duration 30.00:00:00
Dieser Befehl setzt diese Überwachung für 30 Tage auf "deaktiviert". Die Einstellungen sind "Global", d.h. werden im AD hinterlegt und vom Exchange Server dann auf die lokalen Server übernommen. Dies können Sie im Eventlog mit folgendem Befehl auslesen.
(Get-WinEvent `
-LogName Microsoft-Exchange-ActiveMonitoring/responderdefinition `
| % {`
[XML]$_.toXml()}).event.UserData.eventXml `
| ?{ `
$_.Name -like "ActiveDirectoryConnectivityConfigDCServerReboot" `
} `
| ft name,enabled
Der Befehl liest das Eventlog aus und sucht gezielt nach der Bestätigung, dass die Einstellungen übernommen wurden.
- Bug Check 0xEF: CRITICAL_PROCESS_DIED
http://msdn.Microsoft.com/en-us/library/windows/hardware/ff560358(v=vs.85).aspx - Exchange 2013 and Bugcheck 0x000000ef
http://itsalwaysmyproblem.com/2013/08/27/exchange-2013-and-bugcheck-0x000000ef/ - BSOD after creating DAG
http://social.technet.Microsoft.com/Forums/forefront/en-US/44d1cd98-cba1-4ed0-b0e7-8aa76ee3eabc/bsod-after-creating-dag - Windows Disk Timeouts and Exchange Server 2010
http://blogs.technet.com/b/exchange/archive/2011/11/17/windows-disk-timeouts-and-exchange-server-2010.aspx - Add-GlobalMonitoringOverride
http://technet.Microsoft.com/de-de/library/jj218683(v=exchg.150).aspx - Blue Screen of Death on DAGs
http://www.blankmanblog.com/general-news/tips-tricks/blue-screen-of-death-on-dags/ - KB2870270 – A Hotfix Bundle für WS2012 Hyper-V Failover
Clusters
http://www.aidanfinn.com/?p=15203 - New High Availability and Site Resilience Functionality in
Exchange 2010 SP1
http://technet.Microsoft.com/en-us/library/ff625233.aspx
Weitere Links
- Managed Availability
http://technet.Microsoft.com/en-us/library/dn482056(v=exchg.150).aspx - New Managed Availability
Documentation Available
http://blogs.technet.com/b/scottschnoll/archive/2013/11/25/new-managed-availability-documentation-available.aspx - New High Availability and
Site Resilience Functionality in
Exchange 2010 SP1
http://technet.Microsoft.com/en-us/library/ff625233(v=exchg.141).aspx - Customizing Managed
Availability
https://blogs.technet.Microsoft.com/exchange/2013/08/13/customizing-managed-availability/ - Lessons from the Datacenter:
Managed Availability
http://blogs.technet.com/b/exchange/archive/2012/09/21/lessons-from-the-datacenter-managed-availability.aspx - What Did Managed
Availability Just Do To This
Service?
http://blogs.technet.com/b/exchange/archive/2013/06/13/what-did-managed-availability-just-do-to-this-service.aspx - Storage, High Availability
and Site Resilience in Exchange
Server 2013
Part 1:http://blogs.technet.com/b/scottschnoll/archive/2012/09/19/storage-high-availability-and-site-resilience-in-exchange-server-2013-part-1.aspx
Part 2:http://blogs.technet.com/b/scottschnoll/archive/2012/10/01/storage-high-availability-and-site-resilience-in-exchange-server-2013-part-2.aspx - A quick look at Exchange
2013 Managed Availability
http://clintboessen.blogspot.de/2013/01/a-quick-look-at-exchange-2013-managed.html - Suppressing Exchange 2013
Managed Availability synthetic
messages für journaling
http://windowsitpro.com/blog/suppressing-exchange-2013-managed-availability-synthetic-messages-journaling - Exchange 2013 Health and
Server Reports (PS)
Part 1: http://justaucguy.wordpress.com/2013/06/06/exchange-2013-health-and-server-reports-ps-part-1/
Part 2: http://justaucguy.wordpress.com/2013/06/13/exchange-2013-health-and-server-reports-ps-part-2/ - Get-HealthReport
http://technet.Microsoft.com/en-us/library/jj218724(v=exchg.150).aspx - Exchange and Shell
Infrastructure Permissions
http://technet.Microsoft.com/en-us/library/dd638114(v=exchg.150).aspx - What Did Managed
Availability Just Do To This
Service?
http://blogs.technet.com/b/exchange/archive/2013/06/13/what-did-managed-availability-just-do-to-this-service.aspx - Installing Cumulative Updates für Exchange Server 2013
http://exchangeserverpro.com/exchange-2013-installing-cumulative-Updates/ - [updated] Script: putting
Exchange Server 2013 into
Maintenance Mode
http://michaelvh.wordpress.com/2013/04/08/script-putting-exchange-server-2013-into-maintenance-mode/ - Placing Exchange 2013 Into
Maintenance Mode
http://blog.c7solutions.com/2012/10/placing-exchange-2013-into-maintenance.html - Exchange 2013 Maintenance
Mode
http://letsexchange.blogspot.de/2013/03/exchange-2013-maintenance-mode.html - UM Call Router
troubleshooting adventure
http://paulrobichaux.wordpress.com/2013/06/16/um-call-router-troubleshooting-adventure/ - Exchange 2013: SMTP 421
4.3.2 Service not active
http://www.frankysweb.de/exchange-2013-smtp-421-4-3-2-service-not-active/ - Server Component States in
Exchange 2013
http://blogs.technet.com/b/exchange/archive/2013/09/26/server-component-states-in-exchange-2013.aspx - http://blog.enowsoftware.com/solutions-engine/bid/185987/Introduction-to-Managed-Availability-An-Exchange-Administrator-s-task-Part-I
- http://blog.enowsoftware.com/solutions-engine/bid/186014/Introduction-to-Managed-Availability-How-to-check-Recover-and-Maintain-your-Exchange-Organization-Part-II
- http://blog.enowsoftware.com/solutions-engine/bid/186036/introduction-to-managed-availability-local-monitoring-files-and-overrides-part-iii














