
IOPS - Input Output Operations per Seconds
Privatkunden interessiert bei Festplatten eigentlich immer nur der Preis pro Gigabyte und die Gesamtkapazität. Und immer wieder kommen fragen, warum 1 TB nicht 1.000 Gigabyte sind und daher ein 1 TB Disk nur 953 oder noch weniger Megabyte groß ist. für Server Administratoren sind das aber nur "Peanuts", da neben der Nettokapazität bei Servern ganz andere Faktoren zählen wie z.B.:
- Verfügbarkeit, Replikation und Rebuild-Rate
Daten sollten nicht verloren gehen und RAID gehört daher zur Pflicht aber auch gibt es feine unterschiede bezüglich der Performance und auch der Rebuild-Rate, wenn eine Disk ersetzt werden muss. Größere Storage Systeme können sogar Daten auf andere Systeme replizieren oder kopieren und erlauben damit auch eine Absicherung gegen Ausfälle eines kompletten Chassis oder Racks. - Flexibilität und Erweiterbarkeit
Moderne Storage-Systeme erlauben aber auch Dinge wie "Thin Provisioning", d.h. nur der tatsächlich belegte Platz wird auf den Disks allokiert wird, was gerade im SAN mit vielen Servern Kosten sparen kann. Auch können moderne Betriebssysteme problemlos damit umgehen, wenn LUNs plötzlich "größer" werden. Auch Windows kann den neuen Platz im laufenden Betrieb ohne Neustart verwenden. - Snapshot, Cloning Techniken
Wer schon die Daten etwas vom Server entfernt aufstellt, kann natürlich auch z.B. eine Sicherung ohne den Server durchführen, vor einem Update einen "Schnappschuss" anlegen um schnell wieder zurück zu können.
Aber bei all den sonstigen Funktionen zählt für die Betreiber von Servern ein Punkt, den man in Anlehnung an eine Aussage der Automobilbranche etwa so formulieren kann:
IOPS sind durch nichts zu ersetzen außer durch noch mehr IOPS.
Was sind (Random) IOPS ?
Es macht keinen Sinn, die IOPS eines Storage-Systems mit sequentiellen Zugriffen zu testen, denn solche linearen Zugriffe kommen höchstens beim Restore, Backup oder auf Desktops vor. Auf eine Exchange Datenbank wird in der Regel "Random" lesend und Schreibend zugegriffen. Schreiben in sogar noch "teurer" mit RAID, da hier bei ungeschickter Wahl der Stripe-Size der Block erst gelesen, verändert und dann komplett wieder geschrieben wird.
Die kleinstes Einheit, die eine Festplatte quasi "verarbeiten" kann, ist ein Datenblock. Dieser kann geschrieben oder gelesen werden. Intern sind die meisten Festplatten mit 512-byte-Sektoren ausgestattet. Erst modernere Festplatten arbeiten auch intern mit größeren Sektoren, z.B. 4kByte. Und dann gibt es natürlich auch noch die Leseköpfe und die Drehung der Festplatte. Während bei Durchsatz-Raten von Festplatten in MB/Sek gerechnet und oft die Obergrenze angegeben wird (also "bis so und so viel Megabyte), die aber nur beim sequentiellen optimierten Schreiben erreichen wird, ist die Formel bei IOPS einfacher. Damit ein IO ausgeführt wird, muss der Schreib/Lese-Kopf zu der entsprechenden Spur fahren und dann im Schnitt eine halbe Umdrehung warten, bis der Speicherplatz unter ihm angekommen ist. Erst dann wird gelesen oder geschrieben und der IO ist erfolgt.
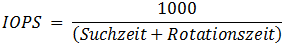
Und damit ist auch klar, welche Werte einer Festplatte maßgeblich sind:
- Suchzeit
Das ist mit mittlere Zugriffszeit der Köpfe und mechanisch vorgegeben. In der Regel sind kleine (2,5") Festplatten hier schneller da die Wege kürzer sind. Es gab sogar Festplatten mit mehreren "Armen" um die IOPS zu erhöhen. Mehr Festplatten oder Köpfe am gleichen Arm bringen hingegen wenig, da sie ja alle an der gleichen Stelle laufen.
Die Suchzeit ist allerdings abhängig von der aktuellen und Zielposition. Ein Wechsel zur nächsten Spur ist deutlich schneller als ein Sprung von einer Seite zu anderen. Zudem dauert die Zeit bis zum Schreiben etwas Länger als zum Lesen. Beim Lesen muss man nicht so "genau" an der Stelle stehen wie beim Schreiben.
Zeiten liegen hier meist zwischen 3,5ms bis zu 10ms für langsame Disks. - Drehzahl
Die Drehzahl ist der zweite Faktor und eine Verdopplung der Drehzahl halbiert die Latenzzeit. Es ist irrelevant, ob die Festplatte dabei groß oder klein ist. Bei größeren Festplatten ist nur die Geschwindigkeit am äußeren Rand sehr hoch, so dass meist die Drehzahl nicht endlos gesteigert werden kann. 2,5" Disks können also schneller drehen.
15k Disks haben ca. 2ms. 7200 U/Min etwas über 5ms
Die Werte für eine Festplatten wird speziell für Serverfestplatten veröffentlicht:
- Spezifikation Seagate
Cheetah
http://www.seagate.com/internal-hard-drives/enterprise-hard-drives/
http://www.seagate.com/internal-hard-drives/enterprise-hard-drives/3-5/cheetah-15k/ - http://en.wikipedia.org/wiki/Solid-state_drive
- IOPS
http://en.wikipedia.org/wiki/IOPS
Entsprechend kann man anhand der Umdrehung und der durchschnittlichen Positionierungszeit die IOPS aufzeigen. Nehmen wir mal 3,5-4ms als Positionierungszeit bei Serverfestplatten an, dann ergeben sich folgende errechnete IOPS. Allerdings sind diese Zahlen "optimale Zahlen" und da das Lesen selbst noch Zeit braucht und auch CPU und Storage Controller verzögernd wirken, sollten Sie eher mit den "realen" IOPS arbeiten, die durchaus deutlich unter den errechneten Werten liegen
| Drehzahl | Errechnete IOPS | Real 3,5 SATA | Real 2,5 SATA | Real 3,5 SAS | Real 2,5 SAS |
|---|---|---|---|---|---|
5400 |
55-75 |
45-55 |
50-60 |
47-57 |
52-63 |
7200 |
75-100 |
50-60 |
55-65 |
53-63 |
57-67 |
10000 |
125-150 |
keine Daten |
keine Daten |
125-135 |
160-170 |
15000 |
175-210 |
keine Daten |
keine Daten |
170-190 |
220-240 |
SSD |
2500-100.000 und mehr |
keine Daten |
keine Daten |
keine Daten |
keine Daten |
- Wikipedia: IOPS
http://en.wikipedia.org/wiki/IOPS - Significance of IOPS in
Exchange Server
http://msexchangeguru.com/2014/03/21/exchangeiops/
Anhand der Tabelle lassen sich einige Aussagen treffen:
- Die Anzahl der möglichen IOPS nimmt mit der
Drehzahl zu
Das ist auch verständlich, da der Bereich der Festplatte einfach schneller unter dem Kopf ankommt - 2,5" ist schneller aus 3,5"
Auch das ist erklärbar, da hier die Wege des Arms einfach kürzer sind und damit die Zielspur schneller erreicht wird. - SATA vs. SAS
Wer genau hinschaut, kann einen kleinen Vorteil von SAS gegenüber SATA sehen. Er ist aber eigentlich so gering, dass er vernachlässigt werden kann. Häufig sind SAS-Festplatten aber "Enterprise Disks" mit einer höheren Haltbarkeit, was sich durch eine höhere Werte bei der MTBF als auch der Garantiezeiten durch den Hersteller zeigt.
Wenn man als Anwendung (Exchange 2010 schreibt 64k), Dateisystem (NTFS hat 4k per Default), Stripe-Size des RAID-Controllers und Blocksize der Disk (512 Byte) gut aufeinander abstimmt, dann ist die Performance höher, als wenn man hier nicht drauf achtet.
Wenn Windows also NTFS mit 4k Blöcken nutzt, dann wäre es ja nur logisch, wenn die Disk auch diese Größe mit einem Zugriff statt 8 kleinen 512 Byte Zugriffen bedienen könnte. Wenn oben nun Exchange mit 64k Blöcken in der Datenbank arbeiten, dann bedeutet eine "Dirty Page" natürlich auch 16x4k-IOs, die in 128x512Bytes-Sektoroperationen (IOPS) aufgeteilt werden. Allerdings sind diese 128 Sektoren idealerweise "am Stück", d.h. eigentlich als ein etwas längerer IO zu zählen, der wenige Millisekunden länger dauert aber ohne mehrmalige Positionierung auskommt.
Insofern müssen andere Faktoren dennoch berücksichtig werden, um ein effektives Storage-System zu erhalten.
- Blockgröße und Ausrichtung (Alignment)
Neben der Blockgröße ist auch die Ausrichtung der Sektoren wichtig. Wenn eine Festplatte z.B. 128 Sektoren a 512byte auf einer Spur ablegt, dann sind das genau 64k. Schreibt Windows nun Daten, dann ist es aus Performancegründen ungeschickt, mitten im Schreiben oder Lesen eine Spurwechsel durchführen zu müssen. Siehe auch Diskpar. - Drehzahl der Disks und Positionierung
Viel Zeit geht auch beim Positionieren auf den Disks verloren. Hier stehen wir immer noch seit vielen Jahren im Beriech von Millisekunden für die Positionierung, was Welten gegenüber den Gigaherz darstellt. Auch bestimmt die Drehzahl, wie lange ein Kopf auf der Spur durchschnittlich warten muss, bis der geforderte Block zum Lesen oder Schreiben drunter durchfliegt. - Anbindung (SAS, SATA)
Auch wenn die Datenraten von SAS und SATA auf vergleichbar hohem Niveau liegen und theoretisch höher als die Nenngeschwindigkeit der Festplatten sind, gibt es doch unterschiede bei der Verarbeitung der Befehle. Viele Dinge sind in SATA wohl noch nicht enthalten oder günstiger ausgeführt. - Cache ist nur kurzfristig
Wer nun mit Ram zum Cache auf der Disk, dem Controller oder im Server die Situation entschärfen will, vergisst, dass IOs sich damit nicht vermeiden lassen. Transaktionslogs schreiben "Synchron" unter umgehung der Caches und meist ist der Speicher deutlich kleiner als die übertragenen Datenmengen. - RAID-Level
Niemand nutzt heute in Servern einfach eine Disk. Es ist auch vom RAID-Controller abhängig, wie effektiv er IOs verarbeitet und auch das RAID-Level hat maßgeblich Einfluss auf die IOPS eines Subsystems
Wir brauchen als eine Maßgabe für IOPS, die ein bestimmtes System bereit stellen kann.
Festplatten aus RAM oder SRAM
Solche Festplatten werden immer größer und sind relativ schnell, da sie
ohne Leseköpfe keine Zeit für die Positionierung verlieren. Allerdings
sind sie immer noch kleiner als echte Festplatten und lassen sich nicht
so oft überschreiben wie klassische Festplatten. Wer zudem nur eine
Teilinformation ändert, verursacht erst einen Lesezugriff auf den
Speicher, damit die Änderungen durchgeführt und der gesamte Block wieder
geschrieben wird.
Die folgenden Werte habe ich aus verschiedenen Quellen und aufgrund der schnellen technischen Entwicklung sollten Sie diese nicht als Basis für ein Sizing verwenden. Letztlich liegt es am Lieferanten des Storage-Systems ihnen diese Daten zu liefen oder gemäß ihrer IOPS-Anforderung ein passendes Storage-System zu konfigurieren
Einfluss der Festplattengröße
Auch wenn es auf den ersten Blick zu Erstaunen führt. Die Größe einer Festplatte in Gigabyte bzw. Terabyte ist für die IOPS nicht relevant. Es ist tatsächlich nur die Positionierungszeit und die Drehzahl. Aber die "Dichte" der Daten auf der Festplatte wirkt sich auf die Übertragungsleistung aus. Wenn auf einer Spur durch engeres Beschreiben quasi doppelt so viele "Bits/qm" abgelegt sind, dann kann die Festplatte beim Lesen und Schreiben die doppelte Datenmenge übertragen. Aber es ändert nichts an der IOPS Rate.
Einfluss von RAID
Die effektiv verfügbare IOPS-Leistung ist natürlich anhängig vom RAID-Level, bei dem mehrere Disks zusammen geschaltet werden. für eine IO-Operation werden mehrere Zugriffe auf Disks benötigt:
| Raid Level | Erforderliche Schreibvorgänge / Lesevorgänge | Formel: erforderliche DiskIOs abhängig von der Verwendung |
|---|---|---|
RAID0 |
1/1 |
Disk IOPS = Read IOPS + Write IOPS |
RAID5 (aus 3 Disks) |
3/3 |
Disk IOPS = Read IOPS + (3 * Write IOPS) |
RAID1 oder 10 |
2/1 |
Disk IOPS = Read IOPS + (2 * Write IOPS) |
Beachten Sie aber auch hier, dass diese Zahlen nur annähernd für die normale Hardware-RAIDs gelten. Storage-Systeme, SANs, iSCSI haben hier eventuell ganz andere Werte. An anderer Stelle habe ich folgende Formel gefunden, bei der aber keine Angaben zum "RAID Penalty Factor" standen
Total IOPS = #Disks x IOPS/Disk x RAID Penalty factor
Insofern ist diese Formel nicht weiter hilfreich. Zumal größere Server und Speichervirtualisierung hier ebenfalls einen Einfluss hat. Eine grobe Abschätzung kann folgende Tabelle liefern:
| RAID-Level | 0 |
1 |
5 |
6 |
10 |
|---|---|---|---|---|---|
| Penalty | 0 |
2 |
4 |
6 |
2 |
IOPS , RAID Penalty and Workload Characterization
https://sudrsn.wordpress.com/2010/12/25/iops-raid-penalty-and-workload-characterization/
Der Einzige, der ihnen genau die IO-Leistung eines Subsystems nennen, kann ist der Hersteller/Lieferant. Dieser wird aber immer mit "hängt von ... ab" antworten, so dass Sie vielleicht besser umgekehrt an die Sache rangehen und ihrerseits einfach den Bedarf ermitteln und damit dann an den Hersteller gehen
- Top 10 Exchange Storage Myths
https://blogs.technet.Microsoft.com/exchange/2010/03/29/top-10-exchange-storage-myths/
Fast interessanter sind die Antworten von Microsoft, speziell Ross Smith IV , auf Rückfragen in den Kommentaren - Optimieren von Speichersystemen für Microsoft
http://download.Microsoft.com/download/8/7/9/879964bc-457f-48c5-9845-af5c2d5001f4/StoragePerformance.doc - Tips für Designing a Well Performing Exchange Disk
Subsystem
http://technet.Microsoft.com/de-de/library/bb219049%28EXCHG.65%29.aspx - DISK RAID AND IOPS CALCULATOR
http://www.thecloudcalculator.com/calculators/disk-raid-and-iops.html
Exchange und IOPS Ermittlung
Die Bedarfsermittlung für ihren Server hängt natürlich auch wieder von mehreren Faktoren ab. Natürlich ist die eingesetzte Software ein Thema, wobei ich mich hier nun doch auf Exchange beschränke. für SQL, Dateiserver etc. gelten andere Werte. Und es ist auch ein unterschied, welche Zusatzdienste auf dem Server noch ausgeführt werden. Der von Microsoft bereit gestellte Mailbox Storage Calculator ist eine gute Ausgangssituation, um die IOPS für ein Exchange System zu ermitteln, wobei er sich nur auf die Mailboxrolle bezieht
Achtung:
Der gängigen Sizer von Microsoft beziehen sich nur auf die
Postfachrolle. IO-Bedarf, der sich durch Hub/Transport oder CAS-Rollen
ergibt, ist her nicht berücksichtigt !!
Für die Dimensionierung von Postfachspeichern werden mehrere Schritte durchlaufen:
Ermitteln der Postfachverwendung
Sie müssen möglichst zutreffend ermitteln, wie viele Mails die Anwender pro Tag senden und empfangen und wie groß diese Mails sind. Das ist gar nicht mal so einfach, da Termineinladungen und Quittungen sehr klein sind aber ein paar große Mails mit Anlagen die Durchschnittswerte stark anheben können. Gut, wenn jemand diese Daten von einem Bestehenden System ablegen kann. Dabei helfen :
- Messagetracking
Diese zeigen sie übertragenen Mailmengen und deren Größe. Allerdings werden hier Änderungen an Kontakten und eigenen Terminen nicht erfasst. Trotzdem ist dies der vermutlich beste Indikator für das aktuelle Belastungsniveau. Schade nur, dass es keine einfachen Auswertetools von Microsoft hierzu gibt. Also bleibt nur selbst skripten. (z.B.: MsgTrackSum) - Datenbank Transaktionsprotokolle
Ein zweiter Indikator, welcher sogar interne Änderungen (z.B. Kontakte, Termine, Notizen etc.) beinhaltet, sind die Transaktionsprotokolle der Datenbank. Sie zeigen das Volumen der Änderungen auf DB-Level an. Auch hier fehlen aber die Werkzeuge seitens Microsoft, So dass Sie entweder selbst Auswertetools schreiben müssen, z.B.: Get224Log oder24hlog oder mit DIR und EXCEL sich eine Momentaufnahme kurz vor dem Backup als Quelle zusammenbauen. - Netzwerkaktivität und Performancedaten des
Disk-System
Wenn beide ersten Daten nicht verfügbar sind, könnten sie über diese Werte nur grob schätzen, was ihr System so macht. Ein Stück weit gelingt dies über Performance Counter ihres aktuellen Systems
Weitere Hinweise zum Sizing finden Sie auch auf Sizingdaten ermitteln.
Ermitteln des IOP-Profil pro Mailbox
Diese Daten werden dann als Quelle heran gezogen, um die erforderlichen IOPS pro Mailbox zu ermitteln. Diese Formel ist von der Exchange Version abhängig, d.h. aufgrund der veränderten Datenbankstrukturen und Blockgrößen werden hier unterschiedliche Ansätze in Rechnung gestellt:
| Messagerate | Exchange 2007 StorageCalc 13.8 |
Exchange 2010 | Exchange 2013 Sizer 6.3 |
Exchange 2016 Sizer 7.8 |
|---|---|---|---|---|
50 a 75k |
0,17 IOPS/Mailbox |
0,03 IOPS/Mailbox |
0,03 IOPS/Mailbox |
0,03 IOPS/Mailbox |
100 a 75k |
0,32 IOPS/Mailbox |
0,12 IOPS/Mailbox |
0,07 IOPS/Mailbox |
0,07 IOPS/Mailbox |
Sie sehen auch, dass Exchange 2010 aufgrund interner Änderungen an der Datenbank mit weniger IOPS auskommt. Wer im Sizer mal mit der Nachrichtengröße spielt, sieht, dass diese Angabe in die IOPS gar nicht relevant ist. Was aber nicht heißt, dass es dann nicht bei der Datenmenge noch einen Engpass geben kann.
IOPS auf Disks aufteilen
Nun müssen Sie natürlich wissen, wie viele IOPS ihr geplantes Disk-Subsystem pro LUN "aushalten" kann. Diese Daten kann ihnen nur ihr Lieferant des Storage-Systems liefern. Mit der bekannten Größe der Mailboxen und der Zielgröße der Datenbanken, die sie noch sinnvoll betreiben können (Backup, Restore, Replikation) bestimmen Sie die Anzahl an Postfächern pro Datenbank und reduzieren die Zahl dann so lange, bis die IOPS (pro Mailbox mal Mailbox) von der LUN, auf der die Datenbank liegen wird, bedient werden kann.
Praktische Bedeutung
Wenn Sie nun denken, das dies alles nur "Zahlenspiele" sind, dann schauen wir uns doch einmal mal eine Umgebung mit 10.000 Benutzern, 5 GB Postfächern und 100 Mails/Tag a 150 Kilobyte an in einer DAG mit 4 Server und 4 Replikation.. Wenn diese Daten in den "Sizer 7.8" eingegeben werden, dann kommen folgende Eckwerte raus. Auch ohne Kalkulator kann man schon mal von 50 TB netto allein für Postfächer ausgehen. Da muss man noch ca. 10-20% Free Diskspace addieren und Transaktionsprotokolle und Transportqueue brauchen auch noch Platz. Also rein in den Sizer mit den Daten und die Ergebnisse sind:
- IOPS/Mailbox = 0.07
- IOPS/Server = 973
- Total Storage / Server (DB+LOG) = 71 TB
Natürlich basiert meine erste Planung auf JBOD mit günstigen 7,2k Disks mit 4 TB. Davon brauche ich pro Server 18 Stück. Wenn ich die mit 50 IOPS ansetze, dann habe ich 900 IOPS erreicht. Das reicht aber nicht. Also kann ich nur "mehr Disks" einsetzen oder schnellere Disks. Ich nehme hier einfach mal 20 Disks und mit 1000 IOPS wäre das ausreichend.
Wenn ich das ganze nun mit RAID5 machen will, dann brauche ich natürlich mehr Disks (Parity) und niemand wird ein RAID5 mit "20 +1" betreiben wollen., Die Rebuildraten wären schon lange, um 20*4 = 80 TB zu lesen, um daraus die eine ausgefallene Disk wieder herzustellen. Also wären eher 4 Raids mit 5+1 Disk, insgesamt also 24 Disks erforderlich. Leider reicht das aber nicht, denn mit der Penalty von "4" beträgt die IOPS-Leistung eines solchen Subsystems gerade mal (24*50)/4 = 300 IOPS. Um mit solch einem System auf 1000 IOPS zu kommen, müsste ich 1000*4/50 = 80 Disks verbauen.
Natürlich würde ich keine DAG mit vier Kopien noch mit RAID5 koppeln. Aber selbst wenn wir die Anzahl der Kopien auf eine DAG mit 2 Servern reduzieren, dann ändert sich folgendes.
- Ich habe nur zwei Kopien
Ein Reseeding passiert immer von der einzigen aktiven Kopie, der aktive Server kann nur auf 50% ausgelegt werden, da im Fehlerfall alle User des anderen Knoten umschwenken. - IOPS/Server = 981
Die erforderlichen IOPS gehen sogar noch etwas höher. - Halbierte Serverkosten = halbierte
Diskkosten
Es fallen ja zwei RAID5-Levels weg und durch die 80 Disks pro Server habe ich eh genug Kapazität
Dennoch habe ich nun "nur" zwei Server die aber weiterhin 2*80 Disks = 160 Disk brauchen. Die JBOD-Lösung kommt aber mit 4x24 Disks = 96 Disks in der DAG aus. Natürlich kosten auch die zwei weiteren Server etwas, aber sie können schwächer bei CPU/RAM ausgelegt sein und brauchen weniger externe Enclosures. Wenn Sie nun vielleicht 400€ für eine 4 TB Enterprise SATA-Disk ansetze, dann sind aber allein die 64 Disks ein Mehrpreis von 25600€. Dafür sollten zwei Server locker drin sein und die Einsparungen an Rackspace, Stromverbrauch, Enclosures sind noch gar nicht mitgerechnet.
Eine Option wäre hier natürlich auch der Betrieb von zwei Servern mit RAID1. Das wären dann 48 Disks * 2 Server. Also genauso viel Disks wie die 4er DAG und der Einsparung von zwei Server Chassis-Gehäusen. Allerdings müssen die beiden Server mehr RAM und mehr CPU haben, so dass die Einsparung geringer ist. Vermutlich wären auch noch zusätzliche Disk-Enclosures erforderlich, die die Differenz weiter schmelzen lassen, so dass am Ende noch die Exchange Lizenz mit gezählt werden muss.
Solche Vergleich und Berechnungen lohnen sich natürlich nicht für einen 100 User Exchange Server. Aber je größer die Server werden, desto genauer sollten Sie hier hinschauen. Das kann dann schnell mal in die tausende Euro gehen und viel schlimmer ist es, wenn der Wunsch eines in sich redundanten Diskspeichers (also RAID) ihnen die IOPS kaputt macht, so dass der Server nicht die Leistung erbringen kann.
Weitere Links
- JetStress
- Exchange Sizing - Wie dimensioniere ich die Hardware ?
-
Top 10 Exchange Storage Myths
https://blogs.technet.Microsoft.com/exchange/2010/03/29/top-10-exchange-storage-myths/
Fast interessanter sind die Antworten von Microsoft, speziell Ross Smith IV , auf Rückfragen in den Kommentaren -
Looking Into Exchange Server Disk I/O Latency Issues
https://techcommunity.Microsoft.com/t5/exchange-team-blog/looking-into-exchange-server-disk-i-o-latency-issues/ba-p/3612871 - The story of Exchange IOPS: How a crusade to make
Exchange less of a storage hog enabled a successful
cloud service
http://www.itprotoday.com/Microsoft-exchange/story-exchange-iops-how-crusade-make-exchange-less-storage-hog-enabled-successful - Exchange 2013 Reduction In IOPS Over Exchange 2010
http://www.exchangeitpro.com/2013/04/22/exchange-2013-reduction-in-iops-over-exchange-2010/ - How to Calculate Your Disk I/O Requirements
http://technet.Microsoft.com/en-us/library/bb125019(EXCHG.65).aspx - Storage Technologies
http://www.microsoft.com/whdc/device/storage/default.mspx - Optimieren von Speichersystemen für Microsoft
http://download.Microsoft.com/download/8/7/9/879964bc-457f-48c5-9845-af5c2d5001f4/StoragePerformance.doc - Understanding RAID Performance at Various Levels
http://www.storagecraft.com/blog/raid-performance/ - IOPS Berechnung
https://www.elasticsky.de/2012/06/iops-berechnung/ - DISK RAID AND IOPS CALCULATOR
http://www.thecloudcalculator.com/calculators/disk-raid-and-iops.html - Horde Hardware Requirements
http://wiki.horde.org/HardwareRequirements - Optimizing Storage für Microsoft Exchange Server
2003
http://www.microsoft.com/downloads/details.aspx?familyid=c6084d20-9730-4ffc-805d-b957327604c6&displaylang=en - IOPS
https://en.wikipedia.org/wiki/IOPS - Don’t do it: consumer-grade solid-state
drives (SSD) in Storage Spaces Direct
https://blogs.technet.Microsoft.com/filecab/2016/11/18/dont-do-it-consumer-ssd/
Sehr guter Artikel zu SSDs und deren Durchsatz für Storage Spaces und andere Server. - Storage Basics
Part I: Basics: http://vmtoday.com/2009/12/storage-basics-part-i-intro/
Part II: IOPS: http://vmtoday.com/2009/12/storage-basics-part-ii-iops/ - Calculate IOPS in a storage array
http://www.techrepublic.com/blog/the-enterprise-cloud/calculate-iops-in-a-storage-array/ - Calculating Disk IOPS
http://www.ryanfrantz.com/posts/calculating-disk-iops - Shouting in the Datacenter
https://www.youtube.com/watch?v=tDacjrSCeq4
Latenz steigt, wenn Festplatten angeschrien werden. - 10 Tips to Optimize Exchange 2003 Performance (Part
1)
http://www.msexchange.org/tutorials/Optimize-Exchange-2003-Performance-Part1.html














