
S.M.A.R.T
System Monitoring kann auch Disks umfassen und manchmal hat man Glück und eine Disk geht auch mal defekt. Ich halte mir solche Disks aber auch mal zurück um zu prüfen, ob ein Monitoring reagiert. Windows 2012 überwacht selbst auch die S.M.A.R.T-Parameter, wie ich im August 2017 selbst erleben durfte.
Es handelt sich um einen Spiel und Test-Server, in dem ich einige alte Desktop-Festplatten (Uptime > 4 Jahre) betreibe.
Anzeige auf dem Desktop
Wenn Sie auf dem Server arbeiten und ihr System auf eine Stelle zugreift, die ein Problem hat, dann kann ihnen Windows 2012 z.B. folgende Meldung anzeigen:
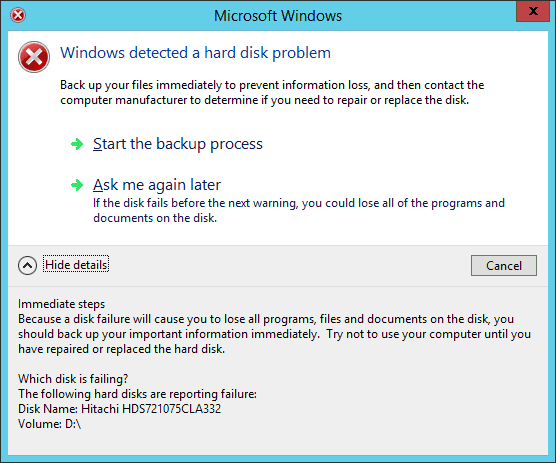
Ich denke der Hinweis ist "deutlich" genug: Es wird zeit für ein Backup, wenn es nicht sogar schon zu spät dazu ist.
Anzeige im Eventlog
Eine GUI lässt sich nicht gut überwachen. "Ricihtige Server" haben natürlich ein eingebautes Management, womit sich solche Fehler aber auch Betriebsdaten, z.B. Lüfterstatus, Temperaturen etc., zentral erfassen lassen und auch solche Fehler erkennen.
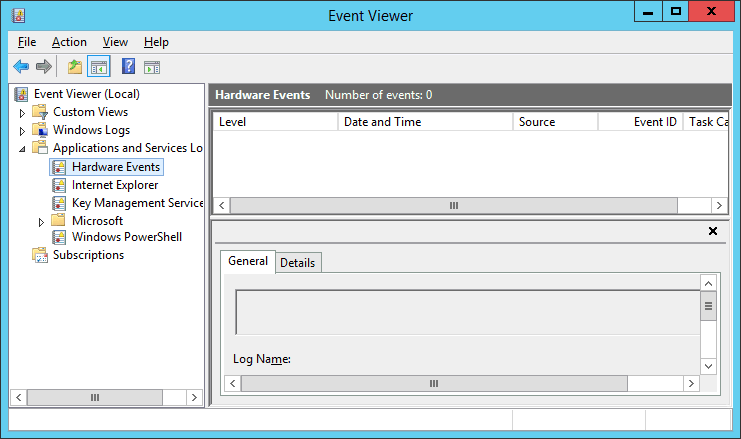
Aber auch das Windows Eventlog berichtet das Problem. Sie können also sehr einfach darauf einen Alert konfigurieren:
Log Name: System
Source: Microsoft-Windows-DiskDiagnostic
Date: 07.08.2017 13:39:41
Event ID: 1
Task Category: None
Level: Critical
Keywords: User: SYSTEM
Computer: Hyper-V
Description:
Windows Disk Diagnostic detected a S.M.A.R.T. fault on disk Hitachi HDS721075CLA332 (volumes D:\).
This disk might fail; back up your computer now. All data on the hard disk, including files,
documents, pictures, programs, and settings might be lost if your hard disk fails.
To determine if the hard disk needs to be repaired or replaced, contact the manufacturer of your computer.
If you can't back up (for example, you have no CDs or other backup media), you should shut down
your computer and restart when you have backup media available.
In the meantime, do not save any critical files to this disk.
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="Microsoft-Windows-DiskDiagnostic" Guid="{E670A5A2-CE74-4AB4-9347-61B815319F4C}" />
<EventID>1</EventID>
<Version>0</Version>
<Level>1</Level>
<Task>0</Task>
<Opcode>0</Opcode>
<Keywords>0x8000000000000000</Keywords>
<TimeCreated SystemTime="2017-08-07T11:39:41.031400300Z" />
<EventRecordID>5022648</EventRecordID>
<Correlation ActivityID="{FC2D45E3-4B8E-4DA7-9CB0-17508FB3322C}" />
<Execution ProcessID="1180" ThreadID="3768" />
<Channel>System</Channel>
<Computer>Hyper-V</Computer>
<Security UserID="S-1-5-18" />
</System>
<EventData>
<Data Name="DiskFriendlyName">Hitachi HDS721075CLA332</Data>
<Data Name="VolumeNames">D:\</Data>
<Data Name="HardwareID">SCSI\DiskHitachi__HDS721075CLA332JP3O</Data>
</EventData>
</Event>
Ein zweiter Event kommt mit der Source "disk", die den baldigen Ausfall der Festplatte ankündigt.
Log Name: System
Source: disk
Date: 10.08.2017 09:27:33
Event ID: 52
Task Category: None
Level: Warning
Keywords: Classic User: N/A
Computer: Hyper-V
Description:
The driver has detected that device \Device\Harddisk2\DR2 has predicted that it will fail.
Immediately back up your data and replace your hard disk drive. A failure may be imminent.
Event Xml:
<Event xmlns="http://schemas.microsoft.com/win/2004/08/events/event">
<System>
<Provider Name="disk" />
<EventID Qualifiers="32772">52</EventID>
<Level>3</Level>
<Task>0</Task>
<Keywords>0x80000000000000</Keywords>
<TimeCreated SystemTime="2017-08-10T07:27:33.377858100Z" />
<EventRecordID>5023112</EventRecordID>
<Channel>System</Channel>
<Computer>Hyper-V</Computer>
<Security />
</System>
<EventData>
<Data>\Device\Harddisk2\DR2</Data>
<Binary>0E00030001000000000000003400048002000000000000000000000000112D000000000000000000030000</Binary>
</EventData>
</Event>
Interessanterweise bleibt das "Hardware Eventlog" leer:
S.M.A.R.T mit Defraggler
Wenn Sie nun etwas mehr über die Festplatte erfahren wollen, habe ich noch keine netten Tool gefunden, die in Windows enthalten wären, Es gibt aber einige Werkzeuge, die auch unter Windows die S.M.A.R.T-Parameter auslesen und anzeigen.
- Comparison of S.M.A.R.T. tools
https://en.wikipedia.org/wiki/Comparison_of_S.M.A.R.T._tools
Ich habe mit dem Piriform Defraggler die Details der betroffenen Disk genauer angeschaut. Beim ersten Fehler war es noch ein "WARNING"

So richtig die Ursache für das "Warning" ist aber nicht zu erkennen. Ich vermute, das der "Reallocated Sector Count" ist. Es geht natürlich noch etwas dramatischer, denn einige Minuten später kam die Meldung noch einmal und nun ist der S.M.A.R.T-Status schon Rot:

Diesmal zeigt mir das S.M.A.R.T-Tool aber auch farblich die relevanten Einträge an. Die "Read Errir Rate" ist nun unter dem Threshold, den Sie nicht unterscheiten darf. Die beiden anderen Werte steigen weiter an
Reaktion
Was machen Sie nun, wenn so ein Fehler erscheint?. Das hängt schon etwas vom S.M.A.R.T-Fehler ab. Eine Disk die einfach nur länger zum "Anlaufen" gebraucht hat, wird zwar auch bald ausfallen aber dürfte noch keine Daten zerstört haben oder nicht mehr lesen können. Eine Disks, die aber schon Lese-Fehler meldet, könnte bestimmte Daten nicht mehr liefern. Dann bleibt die Frage, ob Sie die Daten von der Disk dennoch weiter nutzen, um diese auf eine neue Disk zu kopieren oder ob sie doch lieber die Daten des letzten kompletten Backups heranziehen und nur die Änderungen seit der Zeit zusammenführen.
Das Problem wird bei Lese-Fehlern sein, dass sie nie genau wissen, welcher Block und damit welche Dateien durch den Fehler betroffen sind. Beim "Kopieren" auf ein andere Ziel sollte der Kopierprozess die betroffenen Dateien als "fehlerhaft" melden. Das muss aber nicht der Fall sein und da weder NTFS noch FAT eine Prüfsumme ermitteln, können Sie logische Defekte auch nicht erkennen. Exchange macht das mit der CRC-Prüfung auf die EDB-Datenbanken sehr viel besser.
Insofern kann ich nur sagen:
- Festplatten sind mechanische Geräte mit Verschleiß
- Festplatten fallen aus und Daten gehen dabei verloren
- Eine Replikation auf weitere Disks (RAID, DAG) sind Teil der Lösung
- Eine Datensicherung bleibt wichtig für größere Defekte (Löschen, RAID-Controller, Softwarefehler)
- Überwachen der Disks ist erforderlich.
Schon die "Vorwarnung" ist wichtig.
Insofern denken Sie mal über ihre Server nach, über die Relevanz ihrer Daten und die erforderliche Verfügbarkeit. Ein RAID oder Replikation kann die Verfügbarkeit bei einem Single-Disk-Fehler sicherstellen während ein Backup auch verschiedene Versionen vorhalten und "rückgängi" machen kann. Und ein Backup kann an einem anderen Ort sein.
Weitere Links
- Monitoring
- Überwachung von Servern und Exchange
- Comparison of S.M.A.R.T. tools
https://en.wikipedia.org/wiki/Comparison_of_S.M.A.R.T._tools














