
TCP Window Scaling, Latenz und Durchsatz, RWIN
Manchmal neigt man dazu, physikalische Gegebenheiten zu ignorieren und getreu dem Motto "Viel hilft viel" schon davon auszugehen, dass es "passen" wird. Es gibt aber Grenzen, die im normalen Tagesbetrieb gar nicht wirklich auffallen, es sei denn es kommt zu Problemen. Ein oft vernachlässigtes Problem ist die Super-schnelle WAN-Leitung, deren Latenz und die damit erzielbare Übertragungsrate.
Siehe dazu auch Latenzzeiten und 200ms
Diese Seite soll Sie auf die Thematik aufmerksam machen und weiterführende Links liefern. Sie bleibt aber etwas "einfacher" und geht nicht im Details auf die verschiedenen "Windows" ein wie "Receive Window" und "Congestion Window". Beachten Sie daher die weiteren Links.
Beispiel: Nur 5 MBit über 100 MBit Link?
Die Zeiten von 64kbit oder selbst wenigen Megabit an Übertragungsrate sind schon vorbei. Heute wird selbst im WAN mit Gigabit und Terabit gearbeitet und selbst Firmenstandorte lassen sich mit sehr schnellen breitbandigen Verbindungen koppeln. Das ist auch wichtig um z.B. Datensicherungen auszulagern, Exchange Datenbanken in eine Recovery-Site zu replizieren oder auch um Office 365 zu nutzen. Stellen Sie sich daher mal folgendes vor:
- Zwei Standorte
- "Sehr schneller" WAN Link
Die Bandbreite für die weitere Betrachtung gar nicht relevant. Es ist allein die Laufzeit und RoundTripTime, die interessiert. - Roundtrip-Time zwischen Endpunkten von 10ms
Es dauert also 10ms, bis ein Paket zur Gegenseite gesendet und die Quittung wieder bei mir angekommen ist. - Vereinfachung
Um die Rechnung nicht zu kompliziert zu machen, setzt ich alle andere Zeiten, z.B. zur Verarbeitung der Pakete etc. auf 0ms - XCOPY-Performance (SMB, aber auch HTTP-Download etc.)
Um zu verstehen, warum das so ist, müssen wir uns die Technik der WAN-Übertragung vor Augen führen. Tun wir erst mal so, als wäre es 1970 und die ersten Gehversuche von TCP/IP finden statt. Jedes Paket wird gesendet und quittiert. Ein klassisches Ping Pong-Spiel

Der Client sendet ein Paket, welches vielleicht 1514 Bytes groß ist und mit dem TCP-Header ca. 1460 Byte "Nutzlast" tragen kann. Eine solche Übertragung würde also 1460Bytes/10ms übertragen. Brüche kann man erweitern so dass 146kByte/Sekunde übertragen werden. Verdammt schnell für eine Übertragung im Jahr 1970 aber es war schon abzusehen, Dass dieses Verfahren so nicht funktionieren kann. Daher hat man natürlich mit größeren Puffern und Sammelquittungen gearbeitet.
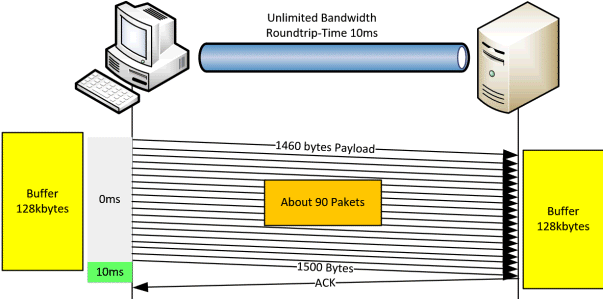
Server nutzt hier einen 128kByte Buffer, die er als Block versenden kann. Der Empfänger muss auch einen Puffer reservieren, denn die Reihenfolge der eingehenden Pakete oder Paketverluste müssen ja behandelt werden. Nehmen wir an, dass der Sender die 90 Pakete a 1514 Bytes in 0ms auf die Reise senden würde und die Gegenseite alle sehr schnell empfängt und die Quittung nach 10ms wieder beim Absender abkommt. Dann dann der Absender seinen Buffer räumen, da er ja kein Paket erneut senden muss.
Er schafft also 128kByte und 10ms oder entsprechend 12,8MByte/Sek was einer Rate von 128MBit entsprechen würde. Diese idealisierte Leistung ist aber eine Wunschvorstellung.
10ms im WAN nicht zu erreichen
Bei der Musterrechnung habe ich 10ms angenommen. Dieser Wert ist im LAN sicher zu unterbieten aber im WAN kaum zu erreichen. denn ein TCP-Paket wird von einem Endpunkt zum anderen Endpunkt über mehrere Stationen und Wege übertragen. Vernachlässigen wir mal den Computer und IP-Stack, PCI-Bus etc., dann gibt es weitere Störfaktoren:
- Ein Paket fehlt
Dann muss der Sender die fehlende Quittung auswerten, dann das Paket erneut senden und wieder die Quittung abwarten. Also noch mal 10ms. TCP muss aber nicht ganz warten aber es kostet etwas Zeit - 10ms im WAN?
Das ist eher eine Wunschvorstellung. Microsoft schreibt, dass bis 100ms noch OK sind. Mit einem 128k Buffer kommen wir dann aber nur noch auf 1/10 des Durchsatzes. Wenn andere Daten auch noch über die Leitung müssen, muss mein Paket etwas warten. Die Latenzzeit ist also eine direkte Kennzahl für die Auslastung der Verbindungsleitung. - Buffergröße
Die Größe des Buffers kann nicht endlos wachsen, da beide Seiten den Buffer im Speicher halten müssen, bis die Pakete quittiert wurden. Stellen Sie sich einen Webserver vor, der 1 Megabyte Puffer anbietet und ein böser Client macht 1000 Verbindungen und fordert eine 1MB-Datei an. Der WebServer hält die im Buffer, bis der Client den Empfang quittiert hat. Als 1 GB "Ram" einfach mal verbraucht. Das hat schon DoS-Potential. Fakt ist dass die Partner die Puffergröße anhand der Laufzeiten und Paketverluste dynamisch anpassen. - Switches/Router
Diese Systeme müssen zumindest einen Teil des Pakets empfangen haben, damit sie den "Next Hop" ermitteln und das Packet weiter senden können. Ein Switch braucht dazu also zumindest die ersten 12 Bytes der "Ziel-MAC-Adresse". Ein IP-Router muss noch etwas länger warten, bis er die Ziel-IP-Adresse erhalten hat. Dann hängt es noch davon ab, ob der Vermittlungsknoten auf dem Ziel gerade "Platz" hat und ob die Weiterleitung nicht doch erst wartet, bis das komplette Paket oder die ersten 64bytes empfangen wurden, ehe er vielleicht auf dem nächsten Teilstück ein Paket mit defekter Prüfsumme Platz belegt. Diese Komponenten haben also einen "Buffer" und speichern das Paket zum Teil oder gesamt zwischen. Damit erhöht sich die Latenzzeit. Jede Umschlagstation addiert etwas Zeit.
Kurze Rechnung: ein Router bedient 15MBit Anbindung und bekommt ein 1,500kByte-Paket. Es dauert schon 1ms, bis das Paket empfangen ist, ehe es an der anderen Seite weiter gesendet werden kann. - WAN-Link
Wer bei einer elektrischen Leitung nun an einen Schaltkreis in der Wohnung mit einer Leuchte und dem Lichtschalter denkt, bei dem überall auf der Leitung der gleiche Spannungspegel anliegt, muss sich erst einmal davon lösen. Auch Strom ist nicht "unendlich" schnell. Wie sprechen von ca. 1/3 Lichtgeschwindigkeit. Wenn ich nun aber eine Leitung mit 5ms "Laufzeit" habe und mit 100MBit/s sende, dann ist ein einzelnes Bit gerade mal 1/100M = 0,01µs (=10ns) lang. Auf eine Leitung, die aufgrund der Länge vielleicht 5ms Latenz aufweist, passen bis zu 500.000 "Bit" hintereinander auf die Leitung. Selbst mit 1.5Kbyte großen Paketen und unter Vernachlässigung von Codierverfahren und Pausen sind das 33 Pakete. Das ist Signaltechnik und nicht mehr Elektrotechnik.
Und das beschreibt nur den Hinweg und nicht den "Roundtrip". Nu ist es aber so, dass ein TCP-Client seine Pakete nicht einfach nur "los sendet", sondern natürlich ein Handshake auch die Zustellung absichert.
Nun wissen Sie übrigens auch, warum einige Dienste wie z.B. Audio/Video, nicht auf TCP sondern UDP setzen. Wenn Paketverluste unkritisch sind, dann kann man per UDP einfach drauf los senden und erreicht riesige Datenraten. Allerdings muss dann das höhere Protokoll dem Sender sagen, wenn eine Überlastung der Strecke zu viele Pakete verliert. Es macht ja keinen Sinn, wenn der Sender Pakete sendet, die unterwegs verworfen werden.
TCP Windows Size und Latenz
Sie haben nun verstanden, dass der ideal erreichbare Durchsatz von der Buffergröße und er Roundtripzeit abhängt. Diese Werte können wir mathematisch ausdrücken:
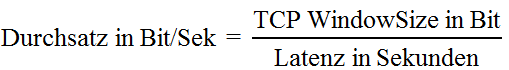
Ich nehme als Muster einfach mal 64kbyte, 128 Kbyte und 256kbyte als Buffergröße und variiere die Roundtripzeit:

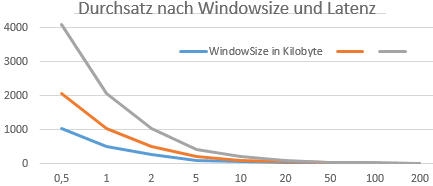
In einem LAN mit 0,5ms Latenzzeit kann eine einzelne TCP-Connection tatsächlich noch 1 GBit übertragen. Aber schon mit einer Verzögerung von 1ms halbiert sich der Durchsatz. Und mit 10ms bleiben gerade noch 51 Megabit technisch übrig. Erst die Veränderung der Windowsize z.B. auf 128kByte oder sogar 256 kByte hebt bei 10ms die maximal mögliche Übertragungsrate auf 102 bzw. 205 Megabit an. 10ms ist aber noch schnell, da über das Internet eher 20-200ms zu erwarten sind. Das ist insbesondere mit Office 365 und anderen Cloud Diensten eine Herausforderung.
Hinweis: Das "Problem" gibt es so nur mit TCP. Bei UDP obliegt es der Applikation, selbst die Bandbreite zu steuern und Rückmeldungen einzusammeln.
- Bandwidth-delay product
https://en.wikipedia.org/wiki/Bandwidth-delay_product
Luxusproblem?
Wenn sie sich nun fragen, warum das nicht breiter bekannt ist, dann würde ich schon sagen, dass es sich bei den meisten Firmen eher um ein "Luxus-Problem" handelt. In einem LAN ist die Latenzzeit in der Regel so kurz, dass diese Obergrenze der Geschwindigkeit eher nicht erreicht wird. Zudem arbeiten viele Firmen in der Breite noch mit "Gigabit" oder weniger, so dass ein Client eher nicht an die Grenze stößt. Auf der Server-Seite ist das Problem weniger sichtbar, da dieses Limit "pro TCP-Connection" gilt. Wenn ein Prozess also mehrere TCP-Connections benutzt, dann multipliziert sich die maximal mögliche Datenrate. Ein Server mit 10 Gigabit Karte kann also immer noch viele hundert Client "voll" bedienen, ohne an Grenzen stoßen zu sollen.
Das Problem kann aber einen individuellen Client oder Server erwischen, wenn er eine Datenmenge über eine "langsame Leitung" zu genau einem anderen System übertragen will und dazu genau eine TCP-Verbindung genutzt wird. Denken Sie man an zwei Exchange Server in einer DAG, die ihre Datenbank "seeden" oder die Replikation zwischen zwei DAG-Mitgliedern.
Auch Richtung Office 365 könnte es zukünftig immer mehr Probleme geben wenn die Bandbreiten immer höher werden. Die Latenzzeit wird damit zwar für das "Stück Kabel" auch kürzer aber bleibt doch noch höher. Eine Migration von Exchange Postfächern in die Cloud wird heute zwar noch nicht maßgeblich durch diese Grenzen beschränkt, aber wie lange gilt dies noch ?
Real wird das Problem immer dann, wenn die WAN-Leitungen immer schneller werden und wir als Anwender und Administratoren uns daraus auch eine schnellere Datenübertragung erwarten. Die , aber die Latenzzeit einfach anhand er Physik (1/3 Lichtgeschwindigkeit) trotzdem nicht geringer wird.
Lösungsansätze
Die physikalischen Eigenschaften lassen sich nicht ändern aber die Nutzung der Bandbreite durch Applikationen kann über verschiedene Wege "optimiert" werden
- Mehrere TCP-Streams
Der einfachste Weg den Datendurchsatz zu erhöhen ist die Aufteilung der Arbeit auf mehrere Streams. Für viele Anwendungen ist dies sehr einfach möglich, z.B. das Kopieren von Dateien muss ja nicht sequentiell erfolgen, sondern über Threads können mehrere Dateien nebeneinander übertragen werden. Auch eine Backup/Restore-Funktion kann mehrere Streams aufsetzen, um die Performance zu steigern. Allerdings muss der Client und der Server da natürlich mitspielen. - kürzere Latenz
Sie können auch im Bereich des Netzwerks versuchen, einfach "schneller" zu werden. Jeder Hop auf einer Verbindung kostet Zeit und je mehr Stationen involviert sind und diese vielleicht noch intensive Checks durchführen, desto langsamer wird der der Durchsatz. Allerdings ist das Potential hier eher darauf beschränkt, Engpässe zu ermitteln und zu beseitigen, die zusätzliche Verzögerungen noch draufsetzen. - Größere WindowSize
Wie Sie oben im Diagramm gesehen haben, können Sie natürlich auch mit einer höheren WindowSize arbeiten. Dann sendet der Client einfach mehr Pakete auf die Reise. Diese Einstellung ist in Windows möglich aber hat auch den Nachteil, dass der TCP-Stack sich mehr Pakete für eine eventuell erforderliche erneute Sendung merken muss. Der RAM-Speicherbedarf des TCP-Stack nimmt entsprechend zu. Das Risiko besteht aber, dass Router und das Zielsystem mit der "Überladung" nicht zurecht kommen. Wenn der Sender also statt 64kByte z.B. 256 KB sendet aber der Empfänger pro Verbindung eben nur 64kByte bereit stellt, führt dies im schlimmsten Fall zu einem Verbindungsabbruch. Denkbar sind aber auch einfach, dass die überzähligen Pakete verworfen werden, wodurch der Client diese selbst neu senden muss. - WAN Acceleratoren
Zuletzt gibt es natürlich noch Geräte von Cisco, RiverBed und anderen Herstellern, die eine "Beschleunigung" des WAN versprechen. Sie tun dies schon viele Jahre durch die "Optimierung" von Paketen durch Kompression und Caching. Aber sie können auch die ACK-Pakete "simulieren" und damit den Sender dazu bringen weiter zu senden. Die "Sicherung" der Übertragung übernehmen dann diese Optimierer. Technisch wirkt es sich aus wie eine größere WindowSize. Sie können dazu aber die WindowSize gezielt verkleinern, damit Sie bei Paketverlusten nicht die Pakete lange puffern müssen.
TCP Windows Scaling und TCP SACK
Am besten ist es natürlich, wenn niemand hier "manuell" Eingreifen muss, sondern die Systeme sich selbst entsprechen der Leitung verhalten und optimieren. Und natürlich haben auch die Entwickler von TCP schon viel früher das "Problem" erkannt und entsprechend nachgerüstet. So gibt es mit der RFC 1323 entsprechende Erweiterungen des TCP-Protokolls, mit dem Sender und Empfänger sich auf angepasste Werte abstimmen können.
- RFC 1323 - TCP Extensions for High
Performance
https://tools.ietf.org/html/rfc1323 - https://en.wikipedia.org/wiki/TCP_window_scale_option
-
RFC2018 TCP Selective Acknowledgment Options
https://tools.ietf.org/html/rfc2018 -
SACK
https://de.wikipedia.org/wiki/SACK
Allerdings hängt es vom Betriebssystem ab, ob diese Funktionen unterstützt werden und auch aktiviert sind:
| Betriebssystem | TCP Window Scaling | Bemerkungen und Links |
|---|---|---|
Vor Windows 2000 |
Nicht implementiert |
|
Windows 2000, XP, 2003 |
Implementiert aber per Default deaktiviert |
224829 Description of Windows 2000 and Windows Server 2003 TCP Features |
Vista, Server 2008 und neuer |
Default aktiv, kann manuell abgeschaltet werden |
Default Buffersize 64k. kann bis auf 16MB wachsen. |
Linux Kernel < 2.6.8 |
Nicht aktiv |
|
Linux Kernel >= 2.6.8 |
Per Default aktiv |
Seit ca. Aug 2004. |
FreeBSD, OpenBSD, NetBSD |
Per Default eingeschaltet |
|
MacOS |
Per Default eingeschaltet |
|
Wie sie sehen können, haben die Betriebssysteme schon seit mindestens 10 Jahren die Funktion "TCP Windows Scaling" nach RFC 1323 im Bauch und sogar aktiv. Insofern "sollten" die Endgeräte sich entsprechend der WAN-Leitung auf eine optimierte Bandbreite einstellen können. Allerdings kann es natürlich immer sein, dass in Router oder eine Firewall die RFC1323-Erweiterungen nicht durchlässt. Dann hängen die Clients auf 64kByte Windows fest und der Durchsatz ist gebremst. Die RFC beschreibt dazu:
2.2 Window Scale Option
The three-byte Window Scale option may be sent in a SYN
segment by a TCP. It has two purposes: (1) indicate that the
TCP is prepared to do both send and receive window scaling,
and (2) communicate a scale factor to be applied to its
receive window. Thus, a TCP that is prepared to scale
windows should send the option, even if its own scale factor
is 1. The scale factor is limited to a power of two and
encoded logarithmically, so it may be implemented by binary
shift operations.
Gängige WindowSize-Größen
Ich habe mir mal die Mühe gemacht, von meinem PC diverse Dienste in Office 365 mit großen Dateien anzufahren und mit Wireshark die letztlich ausgehandelten Werte ermittelt. Die Werte sind eine Momentaufnahme auf meinem Client mit einem DSL-Router und meinem Tenant-. Ihre Werte können abweichen. Passende dazu habe ich den theoretisch maximal erzielbaren Durchsatz anhand der Latenzzeit errechnet:
|
Application |
WindowSize |
1ms |
20ms |
50ms |
100ms |
200ms |
|---|---|---|---|---|---|---|
|
EWS |
1.048.560 |
na |
50MB/s |
20MB/s |
10MB/s |
5MB/s |
|
OneDrive 10MBUpload |
1.059.840 |
na |
50MB/s |
20MB/s |
10MB/s |
5MB/s |
|
SharePoint 12MB Download |
4.273.920 |
na |
208MB/s |
84MB/s |
42MB/s |
21MB/s |
|
End2end-http Outlook |
1.588.480 |
na |
75MB/s |
30MB/s |
15MB/s |
7,5MB/s |
|
Outlook Client |
525.568 |
na |
25MB/s |
10MB/s |
5MB/s |
2,5MB/s |
|
SFTP using SSH 1and1 |
131.584 |
na |
6MB/s |
2,4MB/s |
1,2MB/s |
660kB/s |
|
SMB in local LAN |
2.102272 |
GB+ |
na |
na |
na |
na |
Sie sehen hier schon, dass der maximal mögliche Durchsatz sehr stark von der Windowsize und der Latenzzeit abhängt.
Sonderfall SMB
Alle Protokolle, die auf Basis von TCP arbeiten, können von der dynamischen Windows Site profitieren, wenn Sie denn ihre Daten auch "lossenden". Es gibt aber durchaus Protokolle, die ihre Daten nicht einfach "Streamen", sondern noch selbst in Blöcken organisieren oder einen eigenen Handshake mit aufbauen. Bei SMTP sind die ersten Pakete ja auch Befehle wie "Mail From", "RCPT TO" etc., die von der Gegenseite beantwortet werden müssen. Erst nach dem "DATA" kann der Sender ohne weitete Bestätigung des Empfängers die Daten auf die Reise senden.
Eine Ausnahme ist aber SMB, das Protokoll zum Datei-Sharing unter Windows. SMB 1.0 hat alle Dateizugriffe in 4k Blöcke aufgeteilt und diese einzeln geschrieben. Der Client hat sich quasi so verhalten, als hätte er einen blockorientierte Festplatte im Zugriff. Nebenbei konnte so der Server mit weniger Aufwand die Blöcke einfach entgegennehmen und abspeichern. Nur "schnell" ist das natürlich nicht, wenn der Client nach dem Senden von 4k erst al auf die Antwort des Servers wartet. Das hat Microsoft angeblich mit SMB 2.0 verbessert. Dennoch kann es sein, dass sie hier noch etwas nachsteuern müssen:
... Microsoft has
explained that performance issues come about primarily
because SMB 1.0 is a block-level rather than a
streaming protocol, that was originally designed for
small
LANs; it has a block size that is limited to 64K, SMB
signing creates an additional overhead and the TCP
window size is not optimized for WAN links.
Solutions to this problem include the Updated SMB 2.0
protocol,
Offline Files,
TCP window scaling and
WAN
acceleration devices from various network vendors that
cache and optimize SMB 1.0 and 2.0.
Quelle:
Server Message Block (https://en.wikipedia.org/wiki/Server_Message_Block)
Es gibt nun verschiedene Ansätze im Internet, über Werte in der Registrierung auch SMB zu "beschleunigen". Ich bin da allerdings vorsichtig, da SMB nicht mehr nur ein "Windows Only"-Protokoll ist, sondern mittlerweile auch auf Unix (SAMBA) aber auch verschiedenen anderen NAS und Storage Systemen genutzt wird. Selbst meine Fritz!Box kann per USB einen Speicher per SMB bereit stellen und eine Webcam kann per SMB Bilder auf einen Server ablegen. Hier sind also sicher einige Tests mehr erforderlich. Der erste Schritt ist meiner Meinung nach erst einmal die Analyse woran es denn liegt, ehe man an den Einstellungen etwas verstellt. Vielleicht lässt sich der Zugriff schon allein dadurch beschleunigen, dass SMB 1.0 verhindert wird. Gerne genommen werden auch falsche Einstellungen im Bereich "TCPChimney und RSS".
- TCP Optimization for Windows
http://www.powercram.com/2009/07/tcp-optimization-for-windows.html
Wireshark zur Analyse
Also ist ein Blick mit Wireshark und Co in den TCP-Handshake interessant. Zuerst interessiert mich, ob der Client beim Verbindungsaufbau die Option mit sendet. Bei meinem Windows 7 Client sieht das so aus:
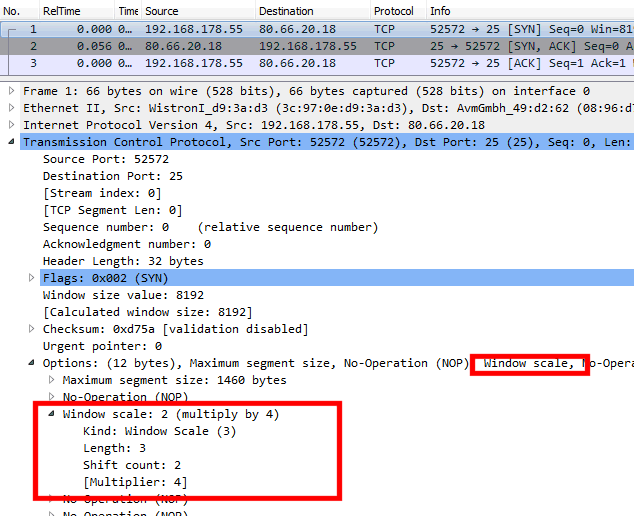
Als nächstes muss man das SYN-Paket der Gegenseite abwarten und hier kontrollieren. Die Antwort auf dieses Paket enthält auch ein Angebot für "Windows Scale":
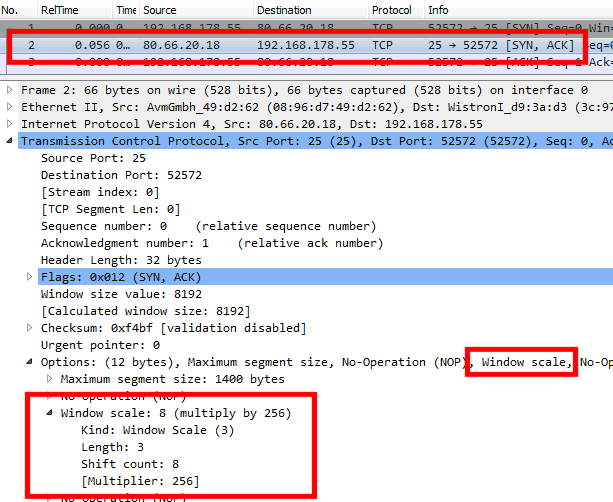
Das bedeutet natürlich noch nicht, dass und in welcher Weise die Endpunkte auch davon gebrauch machen. Aber mit jedem weiteren Paket kann dann die aktuelle Window-Size ausgelesen werden. Hier sind wir schon mal bei 132kByte:

Hier scheint also die Anpassung der Fenster zu funktionieren. Dankenswerterweise hat Wireshark sogar eine Statistik-Funktion für diese Windows Size:
Leider zeigt die Statistik dann immer nur einen Stream an. Sie können zwar rechts unten dann in den Streams durchlaufen und auch auf die Gegenrichtung umschalten.

Eine Übersicht über alle verwendeten Windows-Größen habe ich aber noch nicht gefunden. Allerdings kann Wireshark die errechnete Paketgröße auch als Filter verwenden. Ich habe dann einfach mal einen Filter eingesetzt. um Pakete mit 75k Windowsize zu finden, was auf jeden Fall mehr als 64k sind. Dazu habe den Filter auf " tcp.window_size >75000" gesetzt und mit dann die gefundenen Pakete angeschaut

Eine Analyse der Window_Size für diese Verbindung ergibt dann folgende Bild:
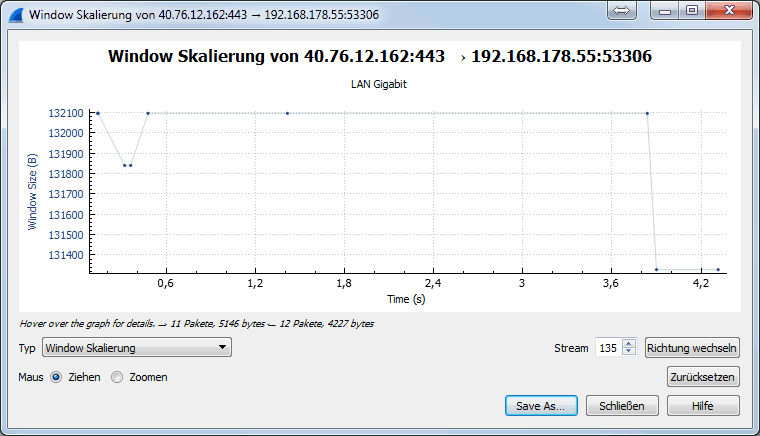
Hier ist gut zu sehen, dass diese Verbindung auch mit einer Windowsize von 132100 Bytes arbeitet. Hier haben sich Sender und Empfänger entsprechend geeinigt, um eine größere Datenmenge zu übertragen. So kann zumindest als Stichprobe geprüft werden, ob abweichende Werte für die Windowsize genutzt werden können. Sollten Sie so was gar nicht sehen, dann könnte es daran liegen, dass ein Router oder eine Firewall die Erweiterungen blockiert.
Einfluss von MTU
Die Windowssize ist natürlich nur ein Parameter des TCP-Stack. Auch eine Ebene tiefe auf der Netzwerkschicht gibt es Paketgrößen. Die MTU bestimmt, wie groß das größte Paket auf dem Übertragungskanal ist. Bei Ethernet ist dies meist 1500 Bytes brutto. Davon werden natürlich noch Ethernet-Header, IP-Header abgezogen, so dass bei TCP vielleicht nur 1450-1480 Bytes übrig bleiben. Wenn die Pakete dann noch über DSL mit PPoE verpackt werden oder sie einen VPN-Tunnel nutzen, dann wird es noch kleiner.
Weitere Links
-
TCP Retransmit und SACK
Netzwerkgrundlagen für Cloud und LAN - Latenzzeiten und 200ms
- QoS mit Flowcontrol
- Netzwerk und QoS
- MTU - Maximum Transmission Unit
-
End2End:Bandbreite und Performance
Richtig Messen am Beispiel von Bandbreite und Latenz - TCP window scale option
https://en.wikipedia.org/wiki/TCP_window_scale_option - TCPWindowSize
https://technet.Microsoft.com/en-us/library/cc938219.aspx - TCP Receive Window
https://de.wikipedia.org/wiki/TCP_Receive_Window - TCP window scale option
https://en.wikipedia.org/wiki/TCP_window_scale_option - Bandwidth-delay product
https://en.wikipedia.org/wiki/Bandwidth-delay_product - How To Calculate Optimal TCP Window Size
For Long Distance WAN Link
http://darrylcauldwell.com/how-to-calculate-optimal-tcp-window-size-for-long-distance-wan-link/ - Understanding TCP Window Size / Window
Scaling
http://ithitman.blogspot.de/2013/02/understanding-tcp-window-window-scaling.html - Heise: TCP Netze: Stellschrauben
http://www.heise.de/netze/artikel/Stellschrauben-224314.html - Netzwerkanalyse Typische
Problemsituationen Teil 2 - eLeFaNts - Long
Fat Networks
http://www.nwlab.net/guide2na/netzwerkanalyse-probleme-2.html#lfn - Long Fat Pipes: TCP WSCALE, TCP SACK and
Time Stamp Options
http://mccltd.net/blog/?p=1864
http://mccltd.net/blog/?tag=wan-optimization - SMB 3 is Going to be Huge, in both Scope
and Impact
http://blog.fosketts.net/2012/05/06/smb-3-huge-scope-impact/ - What’s new in SMB 3.1.1 in the Windows
Server 2016 Technical Preview 2
https://blogs.technet.Microsoft.com/josebda/2015/05/05/whats-new-in-smb-3-1-1-in-the-windows-server-2016-technical-preview-2/ - SMB 2.2 is now SMB 3.0
https://blogs.technet.Microsoft.com/windowsserver/2012/04/19/smb-2-2-is-now-smb-3-0/ - Server Message Block
https://en.wikipedia.org/wiki/Server_Message_Block -
RFC2018 TCP Selective Acknowledgment Options
https://tools.ietf.org/html/rfc2018 -
SACK
https://de.wikipedia.org/wiki/SACK -
Was verbirgt sich hinter den Begriffen MTU
und RWIN?
https://www.3cx.de/voip-sip/mtu-rwin/ -
Network Lab: Typische Problemsituationen
Teil 1: http://www.nwlab.net/guide2na/netzwerkanalyse-probleme-1.html
Teil 2: http://www.nwlab.net/guide2na/netzwerkanalyse-probleme-2.html













