
CSVSync - Framework
Schon viele Jahre gibt es das Skript MiniSync, mit welchem ich LDAP-Verzeichnisse miteinander abgeglichen habe. Und die Beschränkung auf LDAP und der "ONLINE-Verbindung" zu den beiden Systemen hat mich doch öfters beschränkt. Erst habe ich an ein MiniSync2 gedacht, welches komplett in .NET geschrieben sein sollte und über DLLs und Klassen modular erweitert werden könnte. Aber ich bin noch genug Programmierer und habe letztlich auch nicht die Zeit dazu, das Projekt fort zu führen.
Auf der anderen weiß ich aber auch, dass es einige kostenfreie (IILM, Quest Quick Connect) oder Programme im Bereich 100-1000€ gibt, die einen DirSync versprechen. Oft sind diese aber nicht ausreichend anpassbar oder eine Anpassung ist auch Zeitintensiv und ob ein kostenfreies oder billiges Produkt in ein paar Jahren noch pflegbar ist, sei auch dahin gestellt. Letztlich muss ein Administrator immer auch selbst wissen, was im Hintergrund passiert.
Statt dessen habe ich immer mehr mit PowerShell zu tun und auch hier kann man sehr umfangreich Änderungen durchführen. Zudem spart mit die Funktion der PowerShell "PIPE" in Verbindung mit Commandlets und der effektiven Verarbeitung von CSV-Dateien viel Programmieraufwand. CSV-Dateien sind einfach und von jedermann mit Excel oder anderen Tools zu verarbeiten, anzupassen, zu erstellen und selbst mit der PowerShell zu verändern. Also habe ich mich dazu entschlossen, einfach eine CSV-Datei als Metastore zu verwenden und mit entsprechenden Commandlets die Daten zu nutzen.
Auf die prinzipielle Funktion eines Verzeichnisabgleich möchte ich hier nicht weiter eingehen sondern auf MSXFAQ.DE - Verbinden von Organisationen und Verzeichnisabgleich verweisen. Hier sind die Klassen und deren Methoden beschrieben.
Achtung
CSVSync ist kein "Produkt", sondern ein Werkzeugkasten, um mit
einigen Anpassungen einen einfachen unidirektionalen Abgleich von
Kontakten und Benutzern zu erhalten, z.B. Um diese im Outlook
Adressbuch zu sehen oder Daten von Active Directory Benutzern anhand der
Personaldaten zu aktualisieren (z.B. Name, Straße, Telefon etc.).
CSV-Dateien
Nachdem ich einige Zeit mit MiniSync rein "online" gearbeitet habe und ich meinen Ansatz mit MiniSync und XML-Dateien nicht weiterführen wollte, habe ich mich auf die CSV-Dateien zurück besonnen, die einfach zu erstellen, einzulegen und zu modifizieren sind und von nahezu jedem System irgendwie auch erstellt werden können, z.B. auch von einer Buchhaltung oder einem anderen Mailsystem, deren Empfänger Sie importieren möchten. Folgende Module habe ich als Erstes auf meiner Agenda.

Verschiedene Tools erlauben den Extrakt von Daten aus den verschiedenen Quellen um daraus eine CSV-Datei abzulegen. Die kann man natürlich überverschiedene Wege (z.B. per FTP, WebDav, SMTP) auch an andere Stellen übertragen, um sie dann zu importieren. Damit ist im unterschied zu MiniSync keine "online-Verbindung" erforderlich, was speziell den Austausch von Kontakten zwischen Firmen ohne direkte Netzwerkkopplung erlaubt. Denkbare Einsatzszenarien sind dann:
- Outlook Public Folder Kontakte mit CRM-Adressen abgleichen
- Mailadressen von einer Tochter als Kontakte in anderen Forest übertragen
- Kundenkontakte im AD als Exchange Kontakte anlegen
- Rufnummern aus dem AD für die TK-Anlage aufbereiten
- Und sicher fallen ihnen auch noch ein paar Fälle ein.
Natürlich hätte ich auch XML-Dateien als universelleres Format nutzen können. Durch die erforderlichen Tags ist eine XML-Datei aber ungleich größer und aufwändiger zu handhaben. Wobei es kein Problem ist, aus einer XML-Datei mittels passendem XSLT-Formation eine CSV-Datei zu erzeugen und auch einer CSV-Datei kann man mit PowerShell recht einfach eine XML-Datei aufbauen.
Zudem kann man CSV-Dateien aus vielen Systemen einfach erzeugen, z.B. CSVDE:
REM Export von Exchange Postfächern csvde.exe ^ -f exchange.csv ^ -r "(&(mail=*)(HomeMDB=*))" ^ -l company,department,displayname,facsimiletelephonenumber,givenname,l,location,mail,streetaddress,postalcode,sn,telephonenumber ^ -u REM Export von Exchange Postfächern aus mehreren Domains csvde.exe ^ -f exchange.csv ^ -r "(&(mail=*)(HomeMDB=*))" ^ -s <name des GC> -t 3268 -p subtree -l company,department,displayname,facsimiletelephonenumber,givenname,l,location,mail,streetaddress,postalcode,sn,telephonenumber ^ -u REM Export der Postfächer eines Notes-Server csvde.exe ^ -f notes.csv ^ -r "(mail=*)" ^ -s notesservername ^ -l companyname,department,displayname,facsimiletelephonenumber,givenname,l,location,mail,streetaddress,postalcode,sn,telephonenumber ^ -a "Username" "password" ^ -u REM Export der Gruppen mit Mitgliedern aus einem AD csvde ^ -f group.txt ^ -r "(objectclass=group)" ^ -l dn,samaccountname,member ^ -u
CSVDE kann durch die Option "-a" auch Simple BIND und sogar "anonym" arbeiten, wenn dann der Benutzername und Kennwort leer sind. Auf jeden Fall sollte die CSV-Datei aber als UNICODE geschrieben werden, damit Sonderzeichen sicher erhalten bleiben.
Auch wenn man die Prozesse über eine PowerShell-Pipeline aneinander hängen kann, ziehe ich die Zwischenspeicherung von Dateien über Export-CSV und Import-CSV mit wechselnden Namen vor. So kann einfacher ein Schritt wiederholt und analysiert werden. Es erlaubt auch eine recht einfache Trennung auf verschiedenen Systemen. Allerdings muss dann da Zielsystem natürlich warten, bis die Datei komplett ist. Trick: Datei mit temporärem Namen speichern und erst am Ende umbenennen, damit das Zielsystem diese erst dann findet, wenn Sie komplett ist.
Exporter
Für die Verwendung von CSV-Dateien mit PowerShell spielt viel, da zwei wichtige Commandlets (Import-CSV, Export-CSV) schon vorhanden sind und über die PIPE eine direkte Weiterverarbeitung möglich wird. Allerdings ist das erst der Anfang von CSVSync. Viel Arbeit bleibt weiter, um die Daten entsprechend aus den Quellen zu extrahieren und in die Ziele zu importieren.
| Module | Programm | Einsatzbereich |
|---|---|---|
CSV2CSV |
PowerShell |
Generische Konvertierungsfunktion von CSV-Dateien eines Formats mit Überschriften in das gewünschte CSV-Format mit Feldern für das Ziel. Dieses Skript werden Sie häufiger anpassen müssen. |
LDAP2CSV |
CSVDE u.a. |
Dieses Modul exportiert Objekte aus einem LDAP-Server und ist ist Form von CSVDE für das Active Directory sogar schon vorhanden. Selbst alte Systeme wie Exchange 5.5 konnten auch per Skript mit "ADMIN:EXE" die Benutzer als CSV-Datei exportieren. |
CDO2CSV |
|
Export von Kontakten aus einem Outlook Kalender
|
SQL2CSV |
So ein Modul ist natürlich sehr interessant, wenn Kontakte z.B. Daten aus ERP/CRM sind, die auf anderen Plattformen bereit gestellt werden müssen. |
|
SPS2CSV |
|
Export von Kontakten aus Sharepoint |
-
CSVDE
Export von AD-Daten per CSVDE
Transfer
Die Stärke von CSVSync liegt darin, dass es keine "Online-Verbindung" zwischen Quelle und Ziel geben muss, da eine CSV-Datei genutzt werden kann. Natürlich muss die Datei schon irgendwie von der Quelle zum Ziel kommen. Dazu sind aber viele Wege möglich z.B.
- Netzwerklaufwerk/COPY
Natürlich kann man die CSV-Datei einfach im gleichen LAN von einem Netzwerklaufwerk direkt nutzen oder kopieren. - FTP/HTTP
Interessanter sind "internettaugliche" Verfahren, da Sie eigene Authentifizierungen, Verschlüsselungen und firewallfreundliche Ports verwenden. So könnte der Sender die Daten per FTP auf einen Server beim Ziel oder im Internet hochladen oder auf einem Webserver bereitstellen, so dass das Ziel diese z.B. einfach per FTP oder per HTTP (WGET) herunterladen kann. - SMTP
Natürlich kann die Quelle die Daten auch per Mail (z.B. BLAT mit SMTP) versenden und mit wenig Aufwand kann man im Ziel die Mails automatisiert aus einem Postfach extrahieren und verarbeiten.
Natürlich sind all diese Verfahren mit einer gewissen Zeitverzögerung zu betrachten, wenn keine direkte Verbindung zwischen Quelle und Ziel möglich ist.
Konverter
Die Daten der Quelle können in den wenigsten Fällen 1:1 im Ziel verwendet werden. Zum einen gibt es eventuell Datenschutzbedenken der Quelle, die bestimmte Daten ausfiltern möchte. Zum anderen ist es auch im Ziel nicht unüblich, wenn bestimmte Felder den dort geltenden Vorgaben entsprechen sollen. Folgende Felder kommen mir da in den Sinn:
- Telefonnummern normieren
z.B. aus 05251304613 eine +495251304613 zu machen, damit OCS und TAPI-Anwendungen "richtig" wählen - SMTP-Adressen entfernen
Wenn man mit CSVDE alle "ProxyAdresses" exportiert, kann es sein, dass die Quelle nicht alle Adressen zum Ziel senden will - SMTP-Adressen- anpassen'
Bei der Verbindung mehrerer Systeme kann es sein, dass die primäre Adresse der Quelle nicht die Zieladresse ist, die im anderen Mailsystem genutzt werden soll, z.B. User@firma.tld muss im anderen System als User@org2.firma.tld lauten. - Displayname anpassen
Der angezeigte Name der Quelle (z.B. Nachname, Vorname) soll im Ziel vielleicht als "Nachname, Vorname (Firma)" erscheinen. - Felder addieren
Vielleicht pflegt die Quelle nicht alle AD-Felder, wie dies im Ziel sein sollte. Wenn die Quelle z.B. das Feld "company" nicht pflegt, dann wäre es dennoch interessant, dies im Ziel einzutragen.
Also schon einige Dinge, die ein Konverter erledigen kann. Dazu dient CSV2CSV, welches per Pipe die Quelle annimmt und ebenfalls per Pipe wieder ausgibt. Dazwischen muss man das Skript entsprechend anpassen, damit man die gewünschten Quellfelder in die anderen Zielfelder überträgt und bestimmte Formate anpasst.
-
CSV2CSV
CSV-Dateien konvertieren
CSV-Dateien
Aber auch CSV-Dateien habe ihre Tücken, die im Code abgefangen werden müssen, z.B.
- Sonderzeichen, die im Ziel
nicht gültig sind
Verschiedene Systeme haben andere Einschränkungen. Zwar sind umlaute mittlerweile seltener das Problem aber besonders Zeichen wie ":", "\", ";", "%" und andere sind gegebenenfalls anders zu behandeln. Besonders wenn Sie Felder auswerten und schreien, die nicht nur von "Menschen" angesehen werden sondern z.B. Mail-Adressen oder die Bildung des CNs im Ziel. - Ungültige Feldinhalte
Gerade beim Import von Kontakten in Exchange mit dem Feld "Mail" habe ich schon faszinierende Daten in den Quellen gesehen. Leerzeichen an Anfang oder Ende sind noch die einfacheren Fehler. Einige Quellsysteme scheinen wirklich alles zu akzeptieren. Wobei das Feld "mail" im Active Directory auch alles enthalten kann aber die Exchange Commandlets natürlich eine Validierung durchführen. - UNICODE, ANSI, ASCII
Eine unicode-CSV-Datei kann PowerShell recht einfach erkennen aber auch andere Codierungsverfahren kommen zum Einsatz und daher sollte man beim Import und Export von Dateien immer die verwendete Codierung explizit angeben. - "X'"-Inhalte
Selbst mit unicode als Zeichensatz habe ich in CSV-Dateien Werte in Feldern gefunden, die HEX-Codiert waren. Das erkennen Sie daran, dass die Felder mit einem "X'" beginnen. Dabei gibt es auch Sonderfälle "X'00", die bei ADSI auch abgefangen werden müssen. - Mehrwertige Felder
Auch in CSV-Dateien können Felder mehrere Werte enthalten. Das bekannteste Feld ist hier sicher "ProxyAddresses". Aber auch andere Felder kommen vor. Dies muss natürlich beim Parsen (Trennzeichen) als auch beim Setzen der Werte im Ziel mit berücksichtigt werden. - Mehrfacheinträge
Erwarten Sie nicht, dass die Quelldaten eindeutige Datensätze erhalten. Es scheint schon zum "guten Ton" zu gehören, dass Einträge mehrfach vorhanden sind. Die Aufgabenstellung ist diese Dubletten klar zu erkennen, z.B: anhand eines E-Mail-Felds, aber selbst da kann es sein, dass das Feld Mail in der Quelle gar nicht produktiv genutzt wird und mehrere Personen ein gemeinsames Shared-Postfach nutzen und der Admin einfach im Feld "Mail" bei jedem die gleiche Adresse addiert hat. - Eigene Einträge
Speziell wenn Sie auch bidirektional Daten austauschen, dann kann es passieren, das Sie von der anderen Seite eine Liste zurück erhalten, in der neben den fremden Daten auch ihre eigenen Daten wieder enthalten sind, wenn beim Export diese nicht ausgeschlossen wurden. Überlegen Sie sich daher einen Weg um diese Daten zu erkennen und zu überspringen.
Letztlich unterliegen auch CSV-Dateien den gleichen Herausforderungen, die auch ein vollwertiger Verzeichnisabgleich zu lösen hat. Die heile Welt, in der alle Daten korrekt erfasst und eindeutig sind, gibt es nicht. Das merke ich insbesondere auch bei Migrationen, wenn verschiedene Mailsysteme abgeglichen werden. Das "initiale Matchen" ist manchmal zeitaufwändiger als die eigentliche Migration.
Importer
Auf der Zielseite müssen die CSV-Dateien natürlich wieder importiert werden. Dies muss natürlich "passend" zum Ziel erfolgen, so dass es hier nicht wirklich eine generische Lösung geben kann. Die Feldnamen und Inhalte können zwar über die Konverter schon ersetzt und umgeschrieben werden, aber wie letztlich Dubletten erkannt, Objekte angelegt, geändert und gelöscht und mehrwertige Felder behandelt werden, bleibt eine individuelle Aufgabenstellung. Zudem kann es ja durchaus sein, dass je nach Ziel noch weitere Funktionen erforderlich sein. Ein AD-Benutzer einer Quelle kann im Ziel ein Kontakt werden. Er kann aber auch zusätzlich für Exchange aktiviert werden und wenn im Ziel noch Lync ist, dann wäre es auch passend, das Objekt mit einem MSRTCSIPLine-Feld zu versehen, damit es auch im Lync-Adressbuch erscheint.
Alle Importer sind aktuell darauf ausgelegt, dass im Ziel einzelnde "Kontakte" angelegt werden. Es werden z.B. keine Kennworte oder SIDs übertragen und Gruppenmitgliedschaften gibt es nicht, da Verteiler einer Quelle auch nur als einzelner Kontakt erscheinen. Es ist kein vollwertiger DirSync oder Ersatz für ein Medadirectory
| Module | Programm | Einsatzbereich |
|---|---|---|
CSV2AD |
PowerShell |
Sollen die Konten im Ziel noch für Exchange oder Lync eingesetzt werden, dann habe ich mich dazu entschlossen, diese Funktionen nachgelagert als PowerShell im Skript zu hinterlegen aber das Konto selbst per LDAP anzulegen. Damit beschränke ich mich auf die notwendigen Felder. Einige Felder (z.B. PublicKey) können sowieso nicht über die Exchange Commandlets gefüllt werden. |
CSV2CDO |
Interessant ist natürlich auch das Importieren und Abgleichen von Kontakten in einen öffentlichen Ordner oder sogar in das Postfach eines Benutzers. Wobei hier eine Kennzeichung natürlich dafür sorgen muss, dass nur die eigenen Kontakte und aktualisiert gelöscht werden. |
|
CSV2SPS |
|
|
Die Logik des Import orientiert sich an folgendem Flussdiagramm.
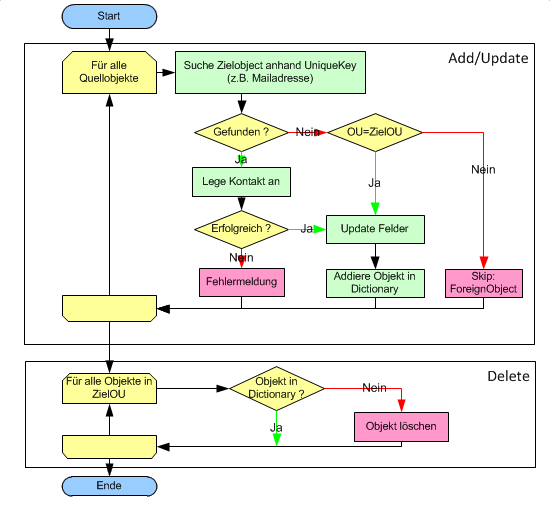
Das Flussdiagramm bezeichnet einen alten Code und hat das Problem, dass z.B. zu löschende Objekte noch Werte haben können, die durch andere neue Objekte benutzt werden sollten. Daher ist es ratsam erst die alten Objekte zu entfernen, auch wenn das aufwändiger ist. Siehe dazu CSV2EX
Einschränkungen
Nicht alles, kann mit einer CSV-Datei einfach umgesetzt werden. Daher sind einige Beschränkungen dieser Lösung zu können. Sie helfen auch dabei, die Abgrenzung zu "großen" Produkten wie einem Metadirectory und einem kompletten DirSync zu erkennen, die aber sowohl von Kosten als auch Aufwand deutlich höher sind.
Add, Update, Delete
Ich habe CSVSync so ausgelegt, dass er neue Objekte im Ziel anlegt, wenn diese keinen Konflikt darstellen und früher angelegte Objekte aktualisiert oder auch wieder gelöscht werden. Bei einigen Zielen kann das Skript einen "Marker" setzen, dass CSVSync die Quelle war und damit sicher nur eigene Löschen. Beim Active Directory kann dies ein freies LDAP-Feld sein oder das Ziel ist gleich eine eigene OU.
OneWay oder bedingt TwoWay
CSVSync ist aber nur mit Einschränkungen dazu geeignet, zwei Verzeichnisse gegenseitig abzugleichen. Sie müssen manuell verhindern, dass ein Objekt, was von Verzeichnis1 nach Verzeichnis2 repliziert wird, über den Rückweg nicht wieder in Verzeichnis2 ausgelesen wird. Das lässt sich über entsprechende Filter erreichen, die idealerweise schon beim Export zu berücksichtigen sind. Das gleiche gilt natürlich bei n:m abgleichen.
Keine atomare Feldänderungen
Eine echte bidirektionale Replikation auf Feldebene kann CSVSync nicht leisten, da es kein "Metaverzeichnis" hat und daher auch keine Änderungen auf Feldebene und entsprechend mögliche Konflikte erkennen kann. Das ist dann die Domäne echter Metadienste.
Gruppen
Wenn man Kontakte abgleicht, dann stellt sich auch die Frage, wie Gruppen abgeglichen werden. Natürlich könnte man die Gruppe einer Quelle auch im Ziel als Gruppe anlegen. Allerdings müsste man dann die Mitglieder auch komplett abgleichen. Nur was macht man, wenn man z.B. bei Mail nicht alle Mitglieder ebenfalls als Kontakte lokal vorhält. Dann wäre es eine unvollständige Gruppe. Daher werden Gruppen in der Quelle auch im Ziel einfach als Einzelobjekte (z.B. Kontakte) mit einer Weiterleitung in die Quelle, welche dann die Mails verteilt. Der Nachrichtenfluss ist dann vielleicht nicht optimal, aber zuverlässig.
Zertifikate
Wer mit S/MIME und Zertifikaten arbeitet, kann mittels des Active Directory diese "öffentlichen Schlüssel" auch im Directory hinterlegen. Dann ist es natürlich sehr interessant, wenn diese Daten auch bei einem Abgleich im fremden Verzeichnis bereit gestellt werden.
- Publish S/MIME certificates für external contacts to Active
Directory für use with Exchange Server 2007
http://blogs.technet.com/b/exchange/archive/2008/04/23/448761.aspx
Bilder
Auch AD-Photos können im Rahmen des Datenschutzes natürlich mit übertragen werden
- Using Contact photo's in EWS in Exchange 2010
http://gsexdev.blogspot.com/2009/09/getting-exchange-auditing-event-logs.html
Umfang des Abgleichs
Das Skript darauf ausgelegt, dass immer alle Daten komplett übertragen werden. Damit gibt es keine Abhängigkeit von vorherigen Versionen oder Ständen und es muss keine Reihenfolge eingehalten werden. Das Verfahren skaliert natürlich damit nur begrenzen. Das Active Directory bietet ja z.B. die Erkennung von Änderungen an (Siehe Get-USNChanges und GET-ADChanges) Aber wer sagt mir, dass jedes Quell-System dies unterstützt? Zudem würde es den Prozess komplexer machen. Solche Feinheiten bleiben die Domänen eines echten Metadirectory.
Mehrwertige Felder und Master/Slave
Felder wie z.B. ProxyAddresses können natürlich mehrere Werte enthalten. Das Skript basiert darauf, dass die Felder einfach "überschrieben" werden. Damit ist sicher, dass im Ziel aktuell Daten sind. Damit sind diese Skripte natürlich nicht für eine Umgebung geeignet, bei denen im Ziel andere Prozesse an den Objekten etwas ändern.
Konten und Authentifizierung
Felder wie z.B. die SIDHistory sind per LDAP nicht zu schreiben und das Kennwort kann per LDAP aus der Quelle nicht extrahiert werden. Per CSV-Datei könnte zwar ein Benutzerobjekt der Quelle auch im Ziel als Benutzer angelegt werden, aber als Anmeldekonto ist es nicht ohne weiteres nutzbar.
Denkbar sind aber schon Resource-Forest Modelle, bei denen über diesen Weg Platzhalterkonten entsprechend konfiguriert werden.
Automatik
Sobald so ein Abgleich automatisiert und nicht mehr interaktiv ausgeführt wird, sollten noch ein paar Funktionen nachgerüstet werden, z:B.
- "Sicherung" gegen
Fehlfunktion
Gerade das "Löschen" ist doch ein kritischer Moment. Eine einfacher Tippfehler könnte schon zum Löschen vieler gültiger Einträge führen. Hier wäre eine "Drossel" ratsam, dass bei allzu vielen Veränderungen das Skript innehält und einen überwachten Lauf anfordert. - Report an Admin oder
Eventlog
Generell sollte jeder automatische Prozess auch Hilfsmittel zur Überwachung bereit stellen. Dazu zählen nicht nur die Fehlermeldungen sondern auch OK-Meldungen, auf die SCOM oder andere Programme überwachen können. Das Fehlen einer "Fehlermeldung" sagt ja nichts darüber aus, wenn das Skript nicht gelaufen ist. - Sicherung gegen partielle
Daten
Werden CSV-Dateien "übertragen", dann muss sichergestellt sein, dass die Datei immer komplett und nicht nur partiell übertragen wird. Da CSV keine Prüfsummen kennt und anders als XML auch keine komplette Struktur ist, rate ich zum kopieren und umbenennen oder zum Komprimieren. Denkbar ist auch ein "Kontrolldatensatz" am Ende
Intervall
So ein einfacher CSV-Abgleich kann auch nicht alle Minute stattfinden. In der Regel erwarten meine Kunden, dass der Abgleich z.B. einmal in der Nacht erfolgt und rechtzeitig fertig ist, ehe Exchange oder Lync das nächte OAB erstellt. Sicher ist auch ein Abgleich im Stundentakt bis zu einer zu definierenden Menge an Datensätzen möglich aber dies ist immer noch lange im vergleich zu einer AD-Replikation oder dem Provisioning über ein Metadirectory.
Weitere Links
- Verbinden von Organisationen
- Verzeichnisabgleich
- MiniSync
- Ex552AD
- Weiterleitungen
- MIIS
-
CSV2CSV
CSV-Dateien konvertieren - Get-USNChanges
- GET-ADChanges
- CSV2Contact
- MSXFAQ.DE:CSVDE
- Import New Users with a CSV File
http://help.outlook.com/en-us/140/ms.exch.ecp.csvimportlearnmore.aspx
Anlegen von Kontakten in BPOS Umgebungen - Create and Configure Recipients with the CSV_Parser.ps1 script
http://help.outlook.com/en-us/140/cc713521.aspx - Identity Integration Feature Pack 1a für Microsoft Windows Server
Active Directory
http://www.microsoft.com/downloads/details.aspx?FamilyID=d9143610-c04d-41c4-b7ea-6f56819769d5&DisplayLang=en
Benötigt Windows 2003 Enterprise und mindestens eine MSDE (zum Test). für den produktiven Einsatz ist ein lizenzierter SQL-Server erforderlich. - Exchange API-spotting: Incremental Change Synchronization API
Definitions
http://blogs.msdn.com/exchangedev/archive/2008/03/27/incremental-change-synchronization-api-definitions.aspx - Creating a Contact with Exchange Web Services from PowerShell
http://gsexdev.blogspot.com/2008/05/creating-contact-with-exchange-web.html - GAL to Outlook Contacts Conversion Agent Script
http://www.cdolive.com/gal2contacts.htm - Importing and Synchronizing Contacts from a CSV (Outlook Express
Export) into Exchange 2007 (private Contacts Folder or Public
Contacts Folder) using
http://gsexdev.blogspot.com/2008/12/importing-and-synchronizing-contacts.html - Publish S/MIME certificates für external contacts to Active
Directory für use with Exchange Server 2007
http://blogs.technet.com/b/exchange/archive/2008/04/23/448761.aspx - General PKI Planning Considerations
http://technet.Microsoft.com/en-us/library/aa996408(EXCHG.65).aspx
Beschreibung des Feld "UserCertificate" zur Ablage von Zertifikaten im Active Directory - Importing and Synchronizing Contacts from a CSV (Outlook Express
Export) into Exchange 2007 (private Contacts Folder or Public
Contacts Folder) using
http://gsexdev.blogspot.com/2008/12/importing-and-synchronizing-contacts.html - Scripting Clinic - Create User Accounts from Information in an Excel Spreadsheet
http://msdn.Microsoft.com/en-us/library/ms974568.aspx - csvde zum Import und Export von AD-Daten nutzen
http://www.faq-o-matic.net/2003/10/25/csvde-zum-import-und-export-von-ad-daten-nutzen/ - Excel-Daten in echtes CSV exportieren
http://www.faq-o-matic.net/2003/02/17/excel-daten-in-echtes-csv-exportieren/ - Importdateien für CSVDE.exe einfach generieren
http://www.faq-o-matic.net/2006/04/12/importdateien-fuer-csvde-exe-einfach-generieren/ - Export-SPWeb
http://technet.Microsoft.com/en-us/library/ff607895.aspx - http://blog.netnerds.net/2011/09/sharepoint-2010-PowerShell-exportimport-calendar-items/
- Create random or demo
SharePoint Content with
PowerShell
http://sharepintblog.com/2011/06/24/create-random-or-demo-sharepoint-content-with-PowerShell/ - Creating a Contact with Exchange Web Services from PowerShell
http://gsexdev.blogspot.com/2008/05/creating-contact-with-exchange-web.html - Importing and Synchronizing Contacts from a CSV (Outlook Express
Export) into Exchange 2007 (private Contacts Folder or Public
Contacts Folder) using
http://gsexdev.blogspot.com/2008/12/importing-and-synchronizing-contacts.html - General PKI Planning Considerations
http://technet.Microsoft.com/en-us/library/aa996408(EXCHG.65).aspx
Beschreibung des Feld "UserCertificate" zur Ablage von Zertifikaten im Active Directory













