
Netzwerk SLA
"Service Level Agreements" sind in aller Munde und 99,9xx% Uptime für Mailserver, Datenbanken o.ä. werden oft diskutiert. Bei Netzwerken geht es primär um die "Uptime" einer Verbindung aber auf dieser Seite möchte die die Qualität des Netzwerks etwas weiter treiben.
Auslöser
Mein Kampf mit "Realtime-Traffic" in Netzwerken ist schon sehr alt. um 1992 habe ich im Finanzbereich/Börsenhandel schon um jede Millisekunde im WAN (Datex-P) und LAN (4/16 Megabit-Token-Ring/10 Megabit BNC) gekämpft und der Exchange 2000 Konferenz Server, auch bekannt als On-Premises-Version von Livemeeting, hat per UDP Multicast seine Bilder übertragen. Mit OCS2007R2 konnte ich mit dem PC telefonieren und heute nutzen Millionen Menschen die Cloud-Dienste von Microsoft Teams, Google Classroom, Zoom oder andere Lösungen. Und natürlich gibt es immer wieder Beschwerden über die Qualität der Sprachverbindung.
Und immer ist das Netzwerk "nie schuld", denn ein einfacher PING geht ja und die MRTG-Grafiken über die belegte Bandbreite zeigt keine Überlastung. Also muss es ja irgendwie "das Windows" oder "die Cloud" sein. Allerdings haben viele Firmen auch die Herausforderung, dass die "Server Administratoren" auf der einen Seite und die "Netzwerker/Teleföner" nicht immer die gleiche Sprache sprechen. Wer sich mit Windows, SQL, Exchange, Dateiserver auseinandersetzt, kennt meist nicht mehr die Netzwerktechnik. Umgekehrt erlebe ich bei meinen "Office 365 für Netzwerkadministratoren" immer wieder, wie wenig ausgeprägt deren Verständnis für die Anwendungsanforderungen ist.
Über meine "Netzwerk Assessment"-Vorträge und Workshops bei Kunden versuche ich diese Lücken auf beiden Seiten zu schließen und meist ist schon direkt danach klar, was am aktuellen Netzwerk verändert werden muss, damit die virtuelle Handbreme gelöst wird. Aber das reicht nicht immer und die Probleme stecken tiefer oder man möchte gegen zukünftige Probleme besser gewappnet sein.
Latenz statt Bandbreite
Das erste Missverständnis ist die Sichtweise auf das Monitoring. Ich unterscheide da drei Aspekte.
- Erreichbarkeitsmonitoring
d.h. ich sende einen PING oder HTTP-Request einmal pro Minute an den Server und stelle so sicher, dass er "da" ist. Diese Checks können intensiver sein, z.B. durch synthetische SQL-Abfragen, den Versand von Testmails, die Überwachung von Diensten - Grenzwertüberwachung
Der zweite Baustein ist die Erfassung numerischer Wert wie z.B. die auf dem WAN-Link übertragenen Pakete und Bytes, der Füllgrad von Festplatten, die CPU/RAM-Last u.a. Im Netzwerk gibt es dann die bekannten MRTG-Bilder zur Bandbreitennutzung - Engmaschige Überwachung
Im Gegensatz zu den ersten beiden Punkten geht es hier darum, die Bereitschaft in Sekunden oder sogar Millisekunden zu überwachen. Wenn ein WAN-Link eine 1 Sekunden Überlast-Situation hat, dann ist das bei Teams-Meetings nicht zu übersehen aber durch das normale Monitoring nicht zu erkennen.
Speziell für "Echtzeit-Daten" eignet sich das klassische Bandbreiten-Monitoring der Netzwerkschnittstellen nicht.
Mich interessiert die Bandbreite nicht mehr sondern nur noch die Latenzzeit. Wenn die Laufzeit ansteigt, dann ist irgendwo auf dem Weg ein Bandbreitenengpass vorhanden. Eine höhere Auslastung einer Leitung bedeutet aber nicht automatisch, dass die Laufzeit zu lange wird. Microsoft fordert für Teams ja auch keine Mindestbandbreite sondern eine Mindestlaufzeit.
Lassen sie mich es erklären:
- Fahrzeit
Wenn ich zum Flughafen muss, dann ist es mir egal, wer noch vor mir, hinter mir oder neben mir auf der Autobahn fährt, solange ich innerhalb der Zeit bleibe um meinen Flug nicht zu verlassen. Insofern kann eine WAN-Leitung auch gerne zu 90% ausgelastet sein. Dann dauert es etwas länger, bis ich auffahren kann aber es darf einfach nicht zu lange dauern. - Torkontrolle
Es hilft mir auch nicht weiter, wenn der Wachschutz am Werkstor alle ein- und ausfahrenden LKW zählt und wiegt. Dann weiß ich zwar, wie ausgelastet meine Werkszufahrt ist aber ich habe keine Information, ob es am nächsten Kreisverkehr eine Baustelle gibt oder eine Teilstecke überlastet ist. Das klassische SNMP-Monitoring macht aber genau das. Es zählt Pakete und deren Größe - Pizzabote im Hauptverkehr
Wenn 20% von 100 Mitarbeitern in einem Teams-Meeting (1MBit mit 150 Pkt/sec) sind und damit 20 Megabit und 3000 Pakete/Sek anliegen, dann sollte es doch kein Problem sein, 10-50 kleine Pakete zur Überwachung mit zu senden.
Damit stellt sich die Frage, wie ich Laufzeit sinnvoll messen kann. Und genau das ist mein Ansatz. Ich habe mir Werkzeuge gebaut, mit denen ich kontinuierlich die Verbindungsqualität zwischen zwei Punkten messen kann. Sowohl zwischen einem Client und einem Cloud Dienst als auch zwischen zwei Client oder einem Client und einem internen Server. Das kann ein einfacher "PING", "TCP-Connect" oder "HTTPGET" sein, der z.B. jede Sekunde abgefeuert wird. Es kann aber auch ein sehr engmaschiger UDP-Datenstrom sein, der eine Audio/Video-Verbindung simuliert oder sogar einen Stresstest erlaubt, um noch kleinere Aussetzer zu erkennen oder auch Änderungen an einer Konfiguration bzw. den Erfolg von Korrekturen zu bestätigen.
SLA-Vorgaben
Wir agieren da gar nicht im freien Raum. Gerade Cloud-Anbieter wie Microsoft schreiben für gewisse Dienste sogar Latenzzeiten vor:
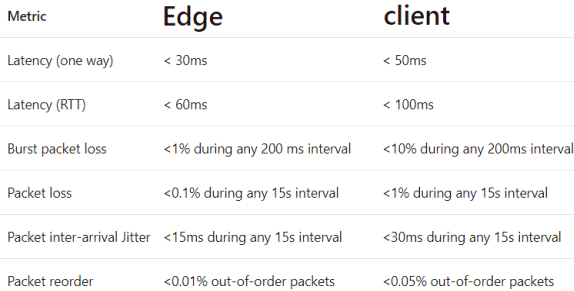
Das ist natürlich verständlich, da Audio und Video sehr empfindlich auf längere Laufzeiten reagieren. In einer Konferenz steigt das Risiko sich ins Wort zu fallen. Verzögerungen bei Audio und Video und insbesondere stark variierende Laufzeiten (Jitter) führen zu Unzufriedenheit bei den Nutzern.
- Network Performance requirements from a Skype for Business client to
Microsoft network Edge
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance#network-performance-requirements-from-a-skype-for-business-client-to-microsoft-network-edge - Network performance requirements from your network Edge to Microsoft network
Edge
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance#network-performance-requirements-from-your-network-edge-to-microsoft-network-edge - Media Quality and Network Connectivity Performance in Skype for Business
Online
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance - Prepare your organization's network for Microsoft Teams
https://docs.microsoft.com/de-de/microsoftteams/prepare-network - Microsoft 365 network connectivity principles
https://docs.microsoft.com/en-us/microsoft-365/enterprise/microsoft-365-network-connectivity-principles?view=o365-worldwide
Die gleichen Überlegungen sollten Sie aber für jede Verbindung anstelle, auch wenn es nicht um Ton und Bild geht. TCP hat im Prinzip kein Problem mit Laufzeiten von Sekunden aber Anwender werden sich beschweren, wenn Tastatureingaben bei Terminaldiensten langsam sind, jeder Webseitenaufbau lange dauert u.a.
Wo und wie messen?
Sie können gerne weiter die übertragenen Bytes und Pakete zählen aber für die Messung der Laufzeiten müssen Sie sich ihr Netzwerk anschauen und anhand der Komponenten und Wege die passenden Endstellen und Gegenstellen festlegen.
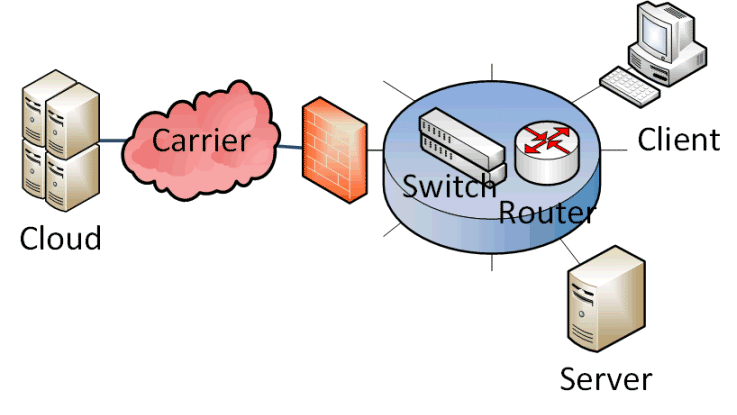
Natürlich ist ihr Netzwerk etwas komplexer, aber das Bild reicht, um sich die Wege der Pakete deutlich zu machen und entsprechende Messpunkte einzusetzen. Es reicht nämlich nicht, auf einem System etwas zu messen. Sie müssen schon überlegen, welche Teilstrecken sie isolieren können und wie über geeignete parallele Messungen indirekt das Problem eingekreist werden kann.
Für Microsoft Teams schlägt Microsoft z.B. Messungen über mindestens 7 Tage gegen eine bekannte Multicast-Adresse vor

Allerdings lässt man sie natürlich etwas alleine bei der Wahl der Hilfsmittel.
Firewall als Probe?
Rein technologisch könnte eine "Stateful Firewall" aus den fließenden Paketen die Laufzeit ermitteln. Wireshark kann das z.B. für mitgeschnittene Pakete.
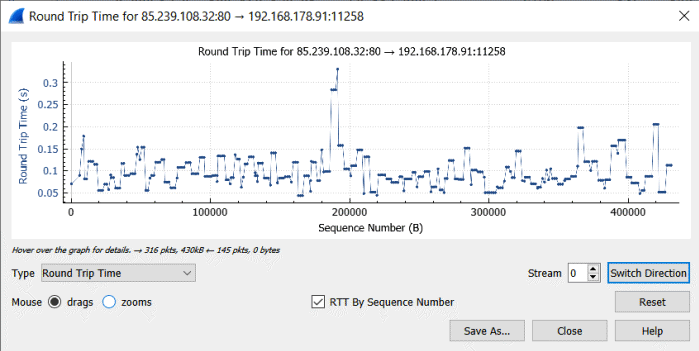
Ich kenne leider keine Firewall, die diese Daten nach Zielen aufbereitet. Ein Nachteil hat dieses passive Auswerten: Wenn keine Daten übertragen werden, haben sie eine Lücke in der Überwachung und wenn viel Verkehr zu übertragen ist, sind die Laufzeiten naturgemäß etwas höher.
End2End-Tests per PowerShell
Um die Latenzzeit zu messen, bleiben nur aktiven Komponenten, die kontinuierlich entsprechende Daten übertragen und ihnen eine Rückmeldung geben. Aus meinem Werkzeugkasten nutze ich gerne meine PowerShell-Skripte, mit denen ich direkt die Cloud-Dienste aber auch lokale Dienste ansprechen kann:
| Skripte | Funktion | Gegenstellen |
|---|---|---|
| End2End-UDP3478 | Sende 50 Pakete pro Sekunden an einen TURN-Server |
Skype for Business und Teams TURN-Server. Lokale SfB Edge-Server oder UDP-Turn-Server anderer Konferenzdienste, z.B. Google |
| End2End-Ping | Sendet einen Ping jede Sekunde und summiert die Ergebnisse alle 60 Sekunden |
Alles, was auf PING reagiert. ICMP wird aber oft anders bedient als TCP/UDP. Daher sind die Messungen mit Vorsicht zu geniessen |
| End2End-HTTP | Fordert jede Sekunde eine URL an und summiert die Ergebnisse alle 60 Sekunden. Selbst ein "404 Not Found" ist eine gültige "Laufzeitmessung" |
OWA, SharePoint, OneDrive, interne Webserver, teilweise Router, Drucker etc. |
End2End-TCP |
Baut jede Sekunde eine TCP-Verbindung auf, Optional mit TLS-Handshake |
Jeder TCP-Service, auch TURN/TCP |
Alle Skripte kennen einen "Dauerbetrieb und können über lange Zeit eine Grundlast erzeugen und die Daten in eine CSV-Datei schreiben oder z.B. an einen PRTG - HTTP Push-Sensoren senden. So können Sie dann auch historisch wunderbar die Laufzeiten zu bestimmten Diensten ermitteln. Über die TLS-Prüfung kann auch eine "Inspecting Firewall" oder ein Proxy erkannt werden.
Für härtere Fälle habe ich noch ein Skript, welches sehr viele UDP-Pakete zwischen zwei Punkten überträgt. Auch ein PowerShell-Script kommt da problemlos auf mehrere tausend Pakete/Sekunde. Das Ziel ist hier aber weniger die Laufzeitmessung sondern eher auf Packetloss oder nach ultrakurzen Störungen zu suchen. Der Code meldet sich nur, wenn Pakete ausbleiben. Damit kommt man aber "wackeligen Uplinks" u.a. auf die Schlichte.
End2End-Tests der Router
Aber vielleicht müssen Sie gar keine Skripte einsetzen. Die meisten Router haben schon ähnliche Funktionen eingebaut. Sie können damit Teilstecken kontinuierlich überwachen und müssen nur die Ergebnisse z.B. per SNMP einsammeln. Hier ein paar Beispiele:
| Gerät | Typ | Anleitung |
|---|---|---|
Cisco IOS11 Router |
Router |
Ein Bild aus der Cisco Beschreibung zeigt die Funktionsweise sehr deutlich: Die Router machen die Arbeit und die Überwachung liest per SNMP einfach die Ergebnisse: |
HP/Aruba |
Router |
|
Juniper |
Router/Switch |
Die Juniper-Geräte können sowohl UDP-Gegenstelle sein als auch direkt eigene Dauertests durchführen.
|
Alcatel |
Router |
Two-way active measurement protocol (TWAMP)
The Two-way
active
measurement
protocol (TWAMP)
provides a
standards-based
method to
measure the
round-trip
performance (including
the packet loss,
delay, and
jitter) of IP
packets that are
transmitted
between two
devices.TWAMP,
which is
described in RFC
5357, uses the
methodology and
architecture of
the One-way
active mea
|
Palo Alto |
Firewall |
|
|
|
Ich bin sicher, dass noch andere Router ähnliche Funktionen haben. Wenn Sie entprechende Links kennen oder sogar Erfahrung damit haben dann freue ich mich über Links |
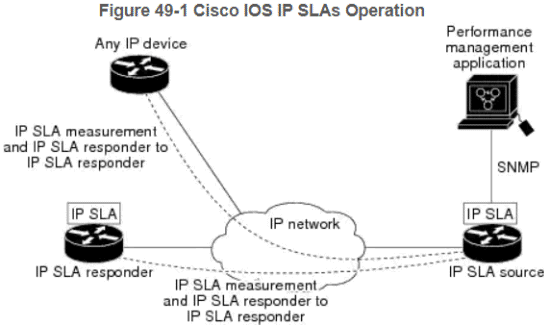
Solche System eigenen sich zumindest für die interne Überwachung von Verbindungen, wenn Sie die Kontrolle über die beiden Gegenstellen haben. Eventuell hat aber auch ihre vorhandene Monitoring-Lösung schon entsprechende Sensoren und Tools. So kann auch PRTG zwischen zwei Probes eine Latenzprüfung durchführen.
Aktionsplan
Wenn ich sie nun davon überzeugt habe, dass eine Bandbreitenmessung nur zweite Wahl ist und sie eigentlich eine Laufzeitmessung ihres Netzwerk umsetzen sollten, dann hat diese Seite ihren Zweck erfüllt. Nun müssen Sie natürlich den Wunsch auch in eine Realität umsetzen. Vielleicht haben Sie schon die passenden Produkte und Werkzeuge. Eventuell reichen ihnen sogar meine Skripte für eine erste Analyse.
Allerdings kann Software nicht eine fundierte Analyse und Auseinandersetzung mit dem Thema ersetzen. Wer mit einem Geigerzähler eine Strahlungsbelastung messen möchte, sollte zumindest grundlegend wissen, was Radioaktivität ist. Mit einem Oszilloskop kann man auch Netzspannung messen, aber es gibt besser geeignetere und sicherer Möglichkeiten.
Gerade die kontinuierlichen Messungen können einen negativen Einfluss auf ihren laufenden Betrieb haben, wenn Sie auf 10 Clients per HTTP die Outlook-Erreichbarkeit messen, dann könnte Microsoft dies als "Angriff" erkennen und letztlich die Messung wertlos machen. Wenn Sie so regelmäßig die Homepage von Google aufrufen, sehen ihre Anwender irgendwann eine Meldung, dass die Client-IP eventuell einen Virus hat.
Weitere Links
-
End2End Bandbreite und Performance
Richtig Messen am Beispiel von Bandbreite und Latenz - End2End-UDP3478
- End2End-Ping
- End2End-HTTP
- PRTG - HTTP Push-Sensoren
- PRTG QoS mit UDP-Mirror
- PRTG QoS Sensor
- PRTG - Custom Sensor
- PRTG QoS mit UDP-Mirror
- Network Performance requirements from a Skype for Business client to
Microsoft network Edge
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance#network-performance-requirements-from-a-skype-for-business-client-to-microsoft-network-edge - Network performance requirements from your network Edge to Microsoft network
Edge
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance#network-performance-requirements-from-your-network-edge-to-microsoft-network-edge - Media Quality and Network Connectivity Performance in Skype for Business
Online
https://docs.microsoft.com/de-de/skypeforbusiness/optimizing-your-network/media-quality-and-network-connectivity-performance - Prepare your organization's network for Microsoft Teams
https://docs.microsoft.com/de-de/microsoftteams/prepare-network - Microsoft 365 network connectivity principles
https://docs.microsoft.com/en-us/microsoft-365/enterprise/microsoft-365-network-connectivity-principles?view=o365-worldwide













