
TCP Session Timeout / TCP Idle Timeout
Diese Seite beschreibt die Funktion und Besonderheiten von TCP-Sessions hinsichtlich Outlook, Exchange und Office 365.
Beachten Sie dazu auch HTTP Chunked und HTTP Keep-alive und Test-TCPTimeout
TCP kennen wir doch schon, oder?
Sicher kennen heute die meisten Administratoren die grundlegende Funktion von TCP und wissen auch um die Unterschiede zu UDP und ICMP.
TCP ist ein verbindungsorientiertes Protokoll, bei dem der TCP-Stack eigenständig dafür sorgt, dass Pakete ohne Verluste und in der richtigen Reihenfolge bei der Gegenseite ankommen. Eine Applikation kann ihre Daten einfach an den TCP-Stack übergeben und muss sich nicht um Fehlerbehandlung kümmern.
Die dazu erforderliche Flusssteuerung kann der TCP-Stack teilweise schon auf
Netzwerkkarten auslagern (Offloading).
Dabei muss der TCP-Stack sich mit verschiedenen Anforderungen herumschlagen.
- Verbindungen müssen sauber auf und wieder abgebaut werden
- Sowohl Sender als auch Empfänger müssen Buffer vorhalten, um verlorene Pakete noch mal zu senden bzw. die Reihenfolge beim Empfang wieder herzustellen.
- Die Buffer sind begrenzt so dass der Durchsatz auch mit der Laufzeit der Pakete zusammenhängt.
- Pakete müssen ggfls. aufgeteilt werden, wenn eine Teilstrecke nur kleinere Pakete unterstützt
- Zudem muss der Stack mit inaktiven Verbindungen umgehen können, wenn es grade nichts zu übertragen gibt aber der Kanal offen bleiben soll oder ein Endpunkt nicht mehr erreichbar ist ohne sich abzumelden.
Das sind durchaus einige Herausforderungen, auf die ich aber auf eine Komponente auf dieser Seite eingehen möchten:
Was hat das mit Exchange, Skype, Teams, Office 365 zu tun?
Sowohl Outlook als auch Mobilgeräte unterscheiden in einem Aspekt sehr stark von klassischen TCP-Verbindungen wie diese von einem SMB-Client, Webbrowser, IMAP4/SMTP-System o.ä. verwendet werden. Diese Systeme bauen Verbindungen auf und übertragen Daten mit der maximalen Geschwindigkeit. Danach wird die Verbindung in der Regel schnell wieder freigegeben.
Outlook, Skype, Mobilgeräte u.a. hingegen bauen eine Verbindung zu einem Service auf und diese bleibt bestehen. Wie sonst sollte Outlook oder ein Smartphone mitbekommen, dass es neue Nachrichten gibt. Was landläufig als "Push" bezeichnet wird, ist in Realität doch ein Abholen. Allerdings stellt der Client eine Anfrage und der Servier lässt sich mit der Antwort sehr lange Zeit. Der Server baut also keine Verbindung zum Client auf. Das kann er auch gar nicht, wenn der Client hinter einem NAT-Router, oder über einen http-Proxy-Server kommuniziert oder häufiger die IP-Adresse wechselt. Ein zu kurzer Timeout führt zu:
- Häufigen "Hängern" beim Zugriff nach
einiger Zeit
Die TCP-Connection muss ja erst wieder aufgebaut werden und ggfls. sogar eine neue Anmeldung am Proxy erfolgen - Verzögerte Zustellung von Mails
Wenn Exchange nicht an den Client antworten kann, zeigt der Client neue Mails erst wieder an, wenn er eine neue Anfrage stellt. - Mehr Netzwerk-Verkehr
Wenn der Client erkennt, dass der TCP-Timeout kurz ist, dann muss er eben häufiger ein "Keep-Alive" senden. Das macht dann jeder Client mit jeder Verbindung. Das kann sich schon aufaddieren. - Skype SIP-Traffic Probleme
SIP-Verbindungen haben auch einen Timeout und sind in der Regel beständig. Wenn die NAT-Zuordnung zu früh abgebaut wird, kommen Rückantworten nicht mehr an. Bei UDP würde eine Firewall dann einen neuen Source-Port nutzen. Da sind einige andere Firewalls auf der anderen Seite dann wieder zornig und blocken das Paket schnell mal. Das passiert meist bei längeren Konferenzen oder Verbindungen, bei denen "nur" Audio sattfindet und es daher keine SIP-Pakete für Statusupdates gibt. Meetings brechen dann gerne einfach ab, wenn eine Seite mangels SIP-"UPDATE"-Paket die Verbindung beendet.
Die Fehler sind also nicht immer klar zu benennen und schwammig.
TCP-Session behalten ist (nicht) einfach
Daher muss der Client die Verbindung nicht nur initiieren (3-Wege Handshake, Siehe auch TCP SYN ACK RES) sondern auch halten. Solange ja Daten übertragen werden, wird auch der TCP-Stack Pakete senden und empfangen. Beide Endpunkte haben was zu tun und alle Stationen dazwischen sind auch involviert, dass es hier eine aktive Übertragung gibt. Interessant sind nun die Abschnitte, in denen keine Daten zur Übertragung anstehen. Dann ist erst einmal "Ruhe" auf dem Kabel. Ein Client und Server senden nur dann ein Paket, wenn es wirklich notwendig ist.
Auf der anderen Seite kann das aber bedeuten, dass ein Client aber auch ein Server ohne Vorwarnung nicht mehr erreichbar sind. Dafür gibt es viele Gründe z.B.
- Ihr Client geht schlafen
Suspend und Resume sind bei Notebooks aber noch mehr bei beim Smartphone Stand der Technik. Um Strom zu sparen, werden bestimmte Komponenten ausgeschaltet - Zonen-Wechsel
Dur eine Ortsveränderung kann die Verbindung abbrechen. Passiert gerne beim Herumlaufen im Büro und dem Wechsel des Netzwerkanschlusses von Kabelgebunden (Dockingunit) auf WLAN. - "Public WLAN-Wackler"
Wer im Hotels, Zügen etc. unterwegs ist, kennt das Problem, dass WLANs nicht immer verfügbar sind. Bewegliche WLANs in öffentlichen Verkehrsmitteln sind auch mal kurze Zeit weg, Bei anderen WLANs ist oft die Reichweite eingeschränkt, so dass Sie einfach eine schlechte wackelige Versorgung haben. - Server Ausfall
Eher selten ist natürlich der Fall, dass ein Service ungeplant beendet wird und der Client sich daher neu verbinden muss.
Wenn in diesen Fällen kein "Aufräumprozess" vorgesehen wäre, dann würde die andere Seite für Immer eine Sitzung offenhalten, was natürlich Ports und Speicher belegt. Daher gibt es Timeout-Werte, nach denen ein Statuspaket übertragen wird und wenn die Antwort darauf mehrfach ausbleibt, dann wird die Session geschlossen.
Es gibt natürlich das "freundlichen Bye". Gerade wenn ein Server heruntergefahren oder ein Dienst beendet wird, dann sollte dieser Dienst den TCP-Socket wieder schließen. Das bringt dann den TCP-Stack dazu, der Gegenseite ein RESET zu senden (Siehe auch TCP SYN ACK RES), so dass auch dort die Sitzung aufgeräumt und der Kommunikationsprozess informiert wird.
HTTP Keep-Alive und Chunked
Office 365 Diensten nutzen natürlich HTTPS-Verbindungen über TCP und damit ist nicht allein der TCP- Session Timeout relevant. Auch bei HTTP gibt es im Protokoll entsprechenden Techniken, um Verbindungen zu halten. Diese sind ebenfalls wichtig, da gerade die "Push"-Funktion vieler Produkte, um den Client möglichst schnell zu aktualisieren, über HTTP erfolgen. Hier gibt es ebenfalls Keep-alive und Chunking-Ansätze. Zu beiden gibt es extra Seiten:
Wer zerschneidet das Seil?
Solange sich die beiden Endpunkte im gleichen gerouteten Netzwerk befinden und quasi nur Router dazwischen die Pakete weiterleiten, sind kaum Probleme zu erwarten. Client und Server kommunizieren miteinander und können jederzeit auch Statuspakete und "KeepAlive"-Meldungen übertragen. Niemand greift ein oder muss sich etwas merken:

Das ist aber nur eine idealisierte Darstellung und mittlerweile gibt es innerhalb von Firmen schon voneinander abgetrennte Netzwerkzonen und beim Zugriff auf Cloud-Dienste kommen weitere Komponenten ins Spiel. Hier ein exemplarisches Bild:

In der Realität gibt es von links nach rechts:
- NAT-Router
Das ist insbesondere im Home-Office der Fall, dass die Fritz!Box o.ä. die interne private IP-Adresse auf die eine externe Adresse umsetzt. Damit Rückantworten ankommen, muss sich dieses Gerät natürlich merken, dass es hier eine Verbindung gibt und welche Public-IP-Port-Kombination auf welche interne IP-Port-Kombination weiter zu leiten sind. Dieses "Session-Table" ist gerade auf kleinen Routern für den SOHO-Bereich nicht endlos groß. Wenn Sie z.B. 100 Clients mit bis zu 10 Verbindungen pro Client planen, dann sind das 1000 Paarungen mit je 4-bytes für die IP-Adressen und je 2-bytes für den Port, was eine ca. 12kByte große Speichermenge bedeuten. - Router
Einfache Router halten normalerweise keine "Sitzungstabelle", da sie nur von Paket zu Paket entscheiden. - Firewall
Anders sieht es bei Firewalls aus, die Verbindungen schützen, Einige schauen nur von der Seite zu, analysieren die TCP-Ströme und unterbinden Pakete, die nicht in die "Reihe" passen. Dazu müssen Sie sich aber den Status der Verbindungen merken. Andere sind aktiv in einem Umsetzungsprozess wie NAT involviert und merken sich entsprechend mehr - Loadbalancer
Hochverfügbare Services werden meist durch eine Lastverteilung bedient, die Abhängig von der Verfügbarkeit und Performance des eigentlichen Service die Zugriffe der Clients dort hin leitet. Auch das erfolgt über eine Umsetzung der Adressen und Protokolle. Der Loadbalancer muss sich dazu auch merken, wohin er Pakete einer bestehenden Verbindung senden muss, damit der Client immer beim gleichen Backend landet. - HTTP-Proxy
Neben der Umsetzung auf Layer-4 (TCP-Ports und Adressen) gibt es natürlich auch noch die "höheren" Ebenen wie z.B. HTTP/HTTPS. Ein Proxy (Ausgehend) oder Reverse Proxy (Veröffentlichung) ist auch eine aktive Komponente im Kommunikationskanal mit entsprechenden Statusinformationen einer Verbindung. Insbesondere wenn es beständige HTTP-Sessions sind, wie bei MAPI/HTTP und ActiveSync.
Jede dieser Komponenten muss sich für ihren Anwendungsfall merken, welche beiden Endpunkte miteinander verbunden sind, um auch nachfolgende Pakete korrekt weiter zu verarbeiten. Die Herausforderung hierbei ist, ein gesundes Mittelmaß zwischen Aktualität und Speicherbedarf zu finden. Speicher ist nu mal begrenzt und wenn eine Sitzung nicht ordentlich abgebaut werden kann, dann müssen die beteiligten Systeme entsprechende Strategien ermitteln, um ihren Speicher wieder frei zu geben.
- TCP/IP Settings Check
https://microsoft.github.io/CSS-Exchange/Diagnostics/HealthChecker/TCPIPSettingsCheck/
Client -> Firewall (1 hour) -> NLB (40 minutes) -> Exchange Servers (20 Minutes)
Der Session Timeout
Spätestens jetzt sollen Sie verstanden haben, wo das Problem liegt: Die beiden Endpunkte haben jeder für sich einen eigenen Session Timeout. Der Endpunkt mit dem niedrigsten Timeout ist für die weitere Betrachtung relevant. Sobald der Timeout wegen Inaktivität abläuft, sendet dieser Client ein "Keep-Alive" an die Gegenstelle. Damit prüft er die Verbindung aber vor allem wird die Verbindung damit aufrecht erhalten. Die andere Seite bemerkt dieses Paket und quittiert es. Damit ist die Session weiter am Leben und der Counter beginnt von Vorne. Der Counter wird natürlich auch zurückgesetzt, wenn Nutzdaten übertragen werden
Wenn aber nun ein System auf dem Transportweg die Zuordnung für diese Session schon gelöscht hat ohne an die Parteien ein RESET zu senden, dann gibt es keinen Kanal mehr, den die Endpunkte nutzen können. Wenn nun der Exchange Server die Information über eine neue Mail an den Outlook Client senden will, dann wird das Paket von der Zwischenstation verworfen. Outlook kann nicht melden, dass eine neue Mal da ist. Das gleiche gilt für OneDrive und insbesondere natürlich auch Teams und Skype for Business. Wobei hier der Timeout einfach aufgrund des "gesprächigeren Protokolls" seltener zuschlagen dürfte.
Besonders gefährdet sind Clients und Protokolle, die über eine bestehende Verbindung längere Zeit keine Daten übertragen. So sind auch Mobilgeräte mit ActiveSync natürlich als Opfer prädestiniert, zumindest wenn mehrere Minuten keine neuen Mails ankommen. Das war früher sogar ein richtiges Problem, wenn ActiveSync bis zu 28 Minuten ohne Nutzdaten eine Verbindung beibehalten hat und anhand der Fehler dieses Intervall immer weiter verkleinert hat, was deutlich auf die Batterielaufzeit der ersten Smartphones gegangen ist.
Es ist also wichtig, dass die Zwischenstationen die Session auf jeden Fall so lange beibehalten, wie der Client mit der kleinsten Session Timeout Einstellung. Da ist es natürlich interessant zu wissen, welche Timeout-Einstellungen die verschiedenen Clients und Relay-Systeme so haben. Es gibt mehrere Timeouts, z.B. wie lange beim Verbindungsauf mit einem SYNC auf das SYNC ACK gewartet wird, wie lange eine beendete Verbindung noch inaktiv bleibt, ehe Sie final gelöscht wird. Diese beziehen sich aber alle auf die Endpunkte. Interessant ist nur die Zeit, ab wann ein Zwischensystem Pakete einfach nicht mehr weitergibt. Wenn der Endpunkt ein Windows System ist, dann ist folgender Blog-Artikel
TCP keep-alives can be sent once every KeepAliveTime (defaults
to 7,200,000 milliseconds or two hours) if no other data or higher-level
keep-alives have been carried over the TCP connection. If there is no response
to a keep-alive, it is repeated once every KeepAliveInterval seconds.
KeepAliveInterval defaults to 1 second.
Quelle: Things that you may want to know about TCP Keepalives
https://blogs.technet.microsoft.com/nettracer/2010/06/03/things-that-you-may-want-to-know-about-tcp-keepalives/
Rein auf TCP bezogen gibt es hier also einen Timeout von 2 Stunden. Allerdings kommt der natürlich nur zum tragen, wenn die Applikation nicht selbst eine Update anfordert. ActiveSync sendet nach 28 Minuten einen neuen Request um zu verhindern, dass es was verpasst. Outlook über MAPI/RPC (Outlook Anywhere) sind ggfls. auch betroffen. Seit MAPI/HTTP ist das Problem entspannt, da der HTTP-Stack selbst einen kürzeren Timeout hat
A minimum of 120 seconds would be a good idle timeout on
egress equipment used for Office 365 as MAPI/HTTP has application level keep
alives set which will ensure the connection is not prematurely terminated with
this timeout value or above.
Quelle: Network Perimeters & TCP Idle session settings for Outlook on Office 365
https://blogs.technet.microsoft.com/onthewire/2014/03/04/network-perimeters-tcp-idle-session-settings-for-outlook-on-office-365/
Früher ging es sogar ohne und es war sogar gefordert, dass man Keep-Alive-Pakete abschalten konnte, um Bandbreite zu sparen.
A "keep-alive" mechanism periodically probes the other end
of a connection when the connection is otherwise idle, even when there is no
data to be sent. The TCP specification does not include a keep-alive mechanism
because it could:
(1) cause perfectly good connections to break during transient Internet failures;
(2) consume unnecessary bandwidth ("if no one is using the connection, who cares
if it is still good?");
(3) cost money for an Internet path that charges for packets.
Quelle: Requirements for Internet Hosts -- Communication Layers 4.2.3.6 TCP
Keepalives
https://tools.ietf.org/html/rfc1122#page-101
In den Zeiten von 300 Baud-Verbindungen waren das schon wichtige Überlegungen. Aber auch heute bleibt es ein Problem, wenn die Endpunkte glauben verbunden zu sein aber das nächste Paket vom Server zum Client nicht ankommt. Dann muss der Server drauf warten, dass der Client dies bemerkt und sich neu meldet. Der Client wartet in der Zeit vergebens auf eingehende Nachrichten.
Solche Zwischensysteme könnten das Problem reduzieren, indem Sie ein RESET an die beiden Endstellen schicken. Das machen die meisten Systeme aber nicht, da sie sich dann auch die Sequence-Nummer merken müssten und zudem das Paket mit der From-Adresse der anderen Seite absenden. Da ist es einfacher den Eintrag in der Sitzungstabelle zu löschen.
Diese Liste hier enthält nur exemplarisch einige Systeme um die unterschiedlichsten Einstellungen aufzuzeigen. Bitte prüfen Sie tagesaktuell die Einstellungen ihre Systeme.
Die Werte sind schön unterschiedlich aber alle größer als die 120 Sekunden, die Microsoft als Minimaleinstellung vorschlägt. Einige Produkte können sogar selbst die Keep-Alive-Pakete senden um so zu prüfen, ob die Endstellen noch erreichbar sind (Cisco ASA: Dead-Connection-Detection (DCD)
Wer sind die Endpunkte?
Im vorigen Kapitel bin ich immer davon ausgegangen, dass die beiden Endpunkte der Client und der Exchange Server sind und alle anderen System transparent dazwischen die Pakete routen und umsetzen. Das ist aber dann doch nicht immer der Fall, denn auch Systeme dazwischen können hinsichtlich TCP aktiv. Das ist gar nicht mal so selten. So terminieren Clients ihre IP-Verbindung nicht auf dem Exchange Server, wenn Sie über einen HTTP-Proxy nach extern gehen oder Exchange selbst über einen Loadbalancer veröffentlicht. Hier ein paar Szenarien:
- Intern -> Fw -> Loadbalacer -> Exchange
In größeren Firmen sind Server und Clients auch per Firewall getrennt und der Loadbalancer vor Exchange steht natürlich mit im Datacenter. Wenn Der Loadbalancer hier ein einfaches Layer-4 Balancing macht, dann baut der Client schon eine Verbindung bis zum Exchange Server auf und die Timeout-Werte des Loadbalancers und der internen Firewall sind hier relevant
Wenn der Loadbalancer aber auf Layer-7 arbeitet und den HTTP-Verkehr terminiert, dann haben wir zwei unabhängige TCP-Verbindungen. Einmal den Client zum Loadbalancer, die von den Timeouts der Firewall gestört werden können als auch die Verbindung von Loadbalancer zu Exchange. Die ist meist unkritisch - Extern -> Fw - Rev-Proxy -> HLB -> Exchange
Clients aus dem Internet müssen meist zuerst durch eine Firewall, die sich die Sessions genau anschaut und per Timeout eine Session entfernt, so dass nachfolgende Pakete verworfen werden. Meist landen diese Zugriffe dann auf einem Reverse Proxy, der eine Preauthentication macht. Hier terminiert der Client dann. Der Proxy baut dann eine eigene Verbindung zum Exchange auf, die oft aber auch noch mal durch eine interne Firewall geleitet wird. Auch hier gibt es die Timeout-Problematik - Intern -> Proxy - Fw/Nat - Office 365
Wen ich von einem Firmen-Client auf mein Office 365 Postfach gehen möchte, dann wäre ein direkter Weg per Routing und NAT ideal. In den meisten Firmen gibt es aber immer noch HTTP-Proxy-Server, um ausgehende Zugriffe nach URL und angemeldeten Benutzern zu filtern, auszuwerten und auf Malware zu prüfen. Dann ist aus Sicht des Clients der Proxy-Server das entfernte Ende und ggfls. eine Firewall dazwischen. Vom Proxy nach Extern könnte dann weiterhin die externe Firewall eine Langlauf-Verbindung stören. Beim Proxy-Server gibt es aber auch noch den Timeout des HTTP-Proxy selbst, der eine Sitzung unterbrechen kann. - Extern -> Fw/Nat - Office 365
Selbst im Homeoffice lauert der Session-Timeout in Form des DSL-Routers. Gerade diese Geräte halten Sessions eher kurz, da Sie Millionenfach und günstig gebaut werden und damit mit wenige Speicher auskommen müssen. 900 Sekunden (15Min) hört sich viel an aber kann durchaus "Idle-Connections" zu früh erwischen. Beim YouTube-Streaming, beim Surfen im Web und selbst ein POP3-Abrufen merken dieses Problem natürlich nicht. Eine SSH-Shell ist aber schon öfter Opfer des Session-Timers geworden.
Session Timeout herausfinden?
Vielleicht sind ja "nur" Exchange Admin und müssen darauf vertrauen, dass ihre Netzwerk-, Proxy-, Firewall- Administratoren alles richtig machen. Da wäre es doch ganz brauchbar, wenn man selbst schon einmal prüfen könnte, wann so ein Timeout passiert. Eine 100% zuverlässige Methode gibt es nicht und es hat auch etwas mit "versuchen" zu tun. Letztlich benötigen Sie
- Einen einfachsten Client,
der TCP-Connection zu einer Gegenstelle aufbaut und dann keinerlei Daten sendet, SSH, Putty oder auch das einfache "TELNET:EXE" sind hier dankbare Clients, mit denen Sie eine Verbindung zu einer Gegenstelle aufbauen können. - Eine Gegenstelle
Ideal ist es, wenn sie direkt die Gegenstelle erreichen können, mit der Sie das Verhalten untersuchen wollen. - Wireshark oder NetMon
Wir müssen dann mit einem Netzwerk-Schnüffler die gleich gestartete Verbindung aufzeichnen. NetMon kann z.B. auf den Prozess-Namen filtern. Ansonsten tut es auch ein Filter auf die Zieladresse/Port mit nachfolgendem Filter auf die Connection. Sie sollten auf dem Test-Client in der Zeit natürlich etwas Datensparsam sein - Connection Start und Warten
Die verbinden sich dann mit der Gegenstelle und betrachten im Netzwerksniffer den TCP-Handshake (3 Pakete). - Warten
Nun müssen sie warten, was passiert. Drei Dinge sind möglich- Die Verbindung wird von der Gegenstelle
beendet.
Die meisten Dienste mögen es nämlich nicht, wenn eine Verbindung aufgebaut wird und dann keine Nutzdaten kommen. Hier kommt dann ein Applicatoin-Timeout zum tragen und die Gegenstellt ist nicht weiter als Testsystem nutzbar - Die Verbindung wird mit einem RESET beendet
Dann könnte es eine aktive Firewall, Reverse-Proxy oder Loadbalancer sein, der die Inaktivität erkennt und als DoS-Schutz die Verbindung wieder freiräumt. Es könnte aber auch sei, dass der Administrator der anderen Seite den TCP Session Timeout von 2h deutlich reduziert hat. Auch diese Gegenstelle ist dann eigentlich nicht geeignet. - Es passiert nicht
Dann müssen sie nach einer gewählten Seit (z.B. 15Min) wieder eine Information senden, z.B. bei Telnet einfach eine Taste drücken und sehen, was passiert. Ihr Client geht davon aus, dass die Verbindung steht und sendet direkt das Paket. Dann gibt es wieder zwei Reaktionen der Gegenseite- Keine Reaktion und ihr
Client sendet das gleiche Paket
mehrfach
Die Gegenseite könnte "down" sein, aber das nehmen wir mal als unwahrscheinlich an. Dann ist dies ein Beleg, dass etwas auf dem Weg die Verbindung beendet hat. - Die Gegenstelle sendet ein
RESET
Das dürfte in 99% der Fälle dann doch eine Firewall sein, die dankenswerterweise nun Bescheid gibt, dass es keine passende Session gibt. Hätte die Gegenstelle die Sitzung abgebaut, dann hätten wir schon vorher einen eigenenden RESET gesehen. - Die Gegenstelle antwortet
mit einem ACK
Die Session ist immer noch aktiv. Dann müssen wir nun wieder noch länger warten und den Test widerholen, bis 1 oder 2 passiert.
- Keine Reaktion und ihr
Client sendet das gleiche Paket
mehrfach
- Die Verbindung wird von der Gegenstelle
beendet.
Sie sehen schon, dass es keinen zuverlässigen Test gibt, einen Session Timeout einfach zu ermitteln. Die Gegenstelle muss mitspielen und sie benötigen Geduld. Anstatt nu einen TELNET auf Gegenstellen zu machen, habe ich einfach HTTP-Requests mit der PowerShell gemacht. Diese behält die Session nämlich bei uns nutzt die gleiche Verbindung. Die Tests habe ich über meine Fritz!Box laufen lassen, die nach 900 Sekunden die TCP-Session kappt. Wenn ich also nach 901 Sekunden den Request wiederhole, sollte die Fritz!Box sehr wahrscheinlich mit einer neuen SourceIP:Port-Kombination am Ziel aufschlagen und keine bestehende Verbindung finden. Als Gegenstelle dient wieder mein kleines PHP-Script auf der MSXFAQ, welches einfach nur die Client-IP-Adresse samt Port ausgibt.
<?php
$ip = getenv('REMOTE_ADDR');
$port = getenv('REMOTE_port');
echo $ip, ":", $port;
?>
Sie können das Skript einfach auf ihren eigenen WebServer im Internet bereitstellen und dann per PowerShell ansprechen.
invoke-webrequest https://<ihr-server>/getip.php
Der Mitschnitt liest sich dann in etwas so:
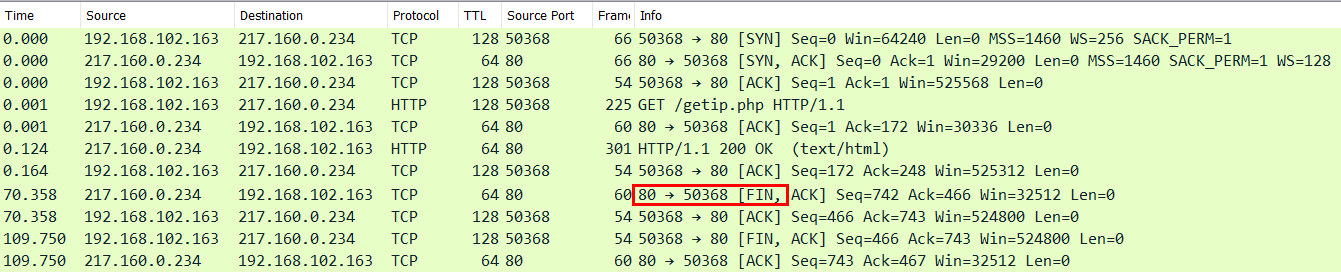
Die ersten drei Pakete sind der Handshake (TCP SYN ACK RES) ehe im Paket 4 dann der "GET" gesendet und die Daten empfangen werden. nach ca. 70 Sekunden gibt es dann ein eingehendes "RESET" durch den Webserver. Die Gegenseite baut die Verbindung ab und die Tastsache, dass das Paket noch ankommt Kann als belegt gewertet werden. dass kein System dazwischen die Verbindung "vergessen" hat.
- PowerShell als HTTP-Client
- HTTP persistent connection
https://en.wikipedia.org/wiki/HTTP_persistent_connection
Inaktive Messung mit Perfmon
Sie haben sicher nun verstanden, dass es gar nicht einfach ist, den kleinsten Timeout auf einem Verbindungsweg zu ermitteln. Das kann Windows selbst natürlich auch nicht besser und in einem idealen Netzwerk gibt es ja keine Paketverluste, die durch den TCP-Stack über den Handshake "gerettet" werden müssen. Im LAN sprechen wir heute von geswitchten Verbindungen, die meiste genug Bandbreite haben, um alle Pakete zu übertragen. Selbst im WAN sollte es eigentlich problemlos möglich sein, Pakete verlustfrei zu übertragen und ggfls. Spitzen durch Warteschlangen in Routern zu mildern.
Denken Sie einfach daran, dass jedes per TCP gesendete und nicht zugestellte Paket noch einmal übertragen wird und zusätzlich auch der Handshake weitere Pakete verursacht. Packet-Loss und die damit verbundene erneute Übertragung ist etwas, was sie auf keinen Fall wollen. Es lässt sich aber nicht immer vermeiden. Hier ein paar Beispiele:
- Paketverlust im LAN
Sollte innerhalb eines guten geswitchten Netzwerks nicht passieren. Anders als bei 10 Megabit BNC sind Kollisionen quasi vernachlässigbar. Paketverluste sind hier ein Zeichen einer unterdimensionierten oder temporär überlasteten Teilstrecke. - Paketverlust über Funk (WLAN, WWAN)
Hier ist das schon häufiger möglich. Funk ist ein "Shared Medium" und Überlastsituationen oder schlechter Empfang durchaus reale und stören die verlustfreie Übertragung von Paketen. Hier "rettet" dann der TCP-Handshake die Verbindung. - Client gestorben
Wann immer ein Prozess mit aktiver Verbindung auf einem Client beendet wird, dann meldet er sich in der Regel per "RESET" ab und schließt die Verbindung. Das ist nicht der Fall, wenn der Prozess einfach terminiert wird oder der Client "offline" geht, d.h. Netzwerk verliert oder einen Schlafmode nutzt. - Server-Prozess endet
Server und darauf laufende Prozesse sollten noch viel Seltener einfach "abbrechen" und Verbindungen damit nicht mehr abgebaut werden. Aber da Clients ihre Verbindung verlieren, werden auch auf dem Server die "Retransmits" gezählt werden. - Firewall vergisst Verbindung
Diese letzte Option ist für Office 365 natürlich interessant. Wenn eine Zwischensystem die Statusinformation über eine "lang anstehende Verbindung" entfernt, kommt das nächste Paket nicht mehr an. Für den Sender bleibt die Quittung aus und er sendet das Paket erneut. Ein sicheres Zeichen, dass die Gegenseite nicht mehr erreichbar ist. Wobei so noch nicht klar ist, warum das Paket nicht zugestellt wurde.
Insofern gibt es immer ein paar erneut übertragene Pakete, insbesondere, wenn Sie diese Daten auf dem Server erfassen, an den viele Clients verbunden sind. Auf Client kann es die Situation auch geben, insbesondere im WLAN oder mit Suspend/Resume. Windows liefert ihnen die Daten quasi kostenfrei als Perfmon-Counter. Leider ist dies nur ein globaler Wert, der nicht nach Prozess oder Ziel-IP unterschieden wird. Es gibt aber Drittprodukte, die solche Daten erfassen und melden.
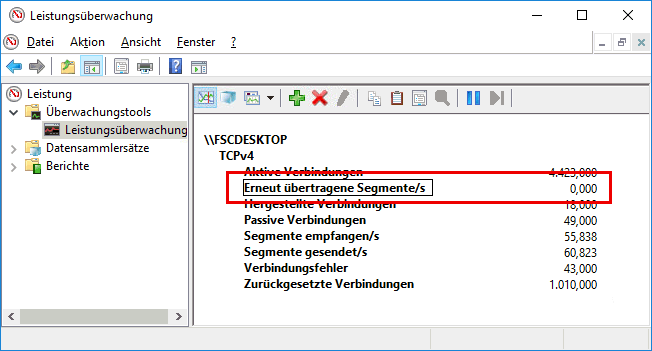
Dennoch sind die Counter auf Clients in der Regel "niedrig" und wenn Sie doch signifikant höher sind, dann können Sie ja mal genauer hinschauen, ob es am Switch, am Standort oder der Nutzung liegt. Dazu müssen Sie diese Daten natürlich erst einmal einsammeln.
Vielleicht liefert ihnen ja auch die Firewall zusätzliche Daten. Sie "sieht" ja alle TCP-Verbindungen und führt Buch über deren Status. Sie sollte entsprechende "Retransmits" sicher erkennen können.
- TCP Retransmit Monitoring
- Performance Best Practice: Monitor TCP
Retransmits
https://www.ibm.com/developerworks/community/blogs/kevgrig/entry/Best_Practice_Monitor_TCP_Retransmits?lang=en - 5 Key TCP Metrics for Performance
Monitoring
https://www.linkedin.com/pulse/5-key-tcp-metrics-performance-monitoring-daniel-shanahan
Endpunkt Konfiguration
Der Session Timeout ist nicht nur eine Einstellung auf den Übertragungskomponenten sondern kann auch auf dem Endpunkt, d.h. dem Client oder Server angepasst werden.
Ehe Sie an der Konfiguration von Windows etwas per REGEDIT ändern, sollten Sie sich der Auswirkungen bewusst sein, Microsoft und andere Firmen haben schon viele Jahrzehnte Erfahrung mit TC/IP und die Standardeinstellungen sind in den meisten Fällen absolut passend. Eine Veränderung kann sich nicht nur auf die Performance auswirken sondern ihre Konfiguration weicht dann von Millionen anderer Windows Systeme ab.
Technisch ist es Windows "nur" ein Registry-Key. Er steuert in Millisekunden die Zeitspanne, nach der ein "KeepAlive" gesendet wird. Wenn der Wert nicht vorhanden ist, ist der Default von 7200000 = 2 Sunden aktiv. Folgender Eintrag stellt den Wert auf 30 Minuten. (Microsoft Exchange Empfehlung https://microsoft.github.io/CSS-Exchange/Diagnostics/HealthChecker/TCPIPSettingsCheck/ )
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters] "KeepAliveTime"=dword:001800000
So kann ein Client oder Server die Verbindung weiter aktiv halten aber auch inaktive Clients schneller entfernen.
- Microsoft CSS Exchange -
TCP/IP Settings Check
https://microsoft.github.io/CSS-Exchange/Diagnostics/HealthChecker/TCPIPSettingsCheck/ - Einstellungen zur Minimierung des regelmäßigen WAN-Datenverkehrs -
Standardwerte für Pakettypen
https://docs.microsoft.com/de-de/troubleshoot/windows-client/networking/settings-for-minimizing-periodic-wan-traffic#default-values-for-packet-types - TCP/IP- und NBT-Konfigurationsparameter für Windows XP - KeepAliveTime
https://docs.microsoft.com/de-de/troubleshoot/windows-client/networking/tcpip-and-nbt-configuration-parameters#optional-tcpip-parameters-that-you-can-configure-by-using-registry-editor - MSS: (KeepAliveTime) How often keep-alive packets are sent in milliseconds
https://admx.help/?Category=SecurityBaseline&Policy=Microsoft.Policies.MSS::Pol_MSS_KeepAliveTime - Einstellung der TCP-Keepalive-Zeit für Windows-Server
https://www.consic.de/de/einstellung-der-tcp-keepalive-zeit-fuer-windows-server
Aber sie sollten sich sehr sicher sein, dass auch andere Komponenten damit klar kommen. Denken Sie mal an:
- Offloading-Funktionen
Seit dem Einzug von Gigabit können viele Netzwerkkarten dem IP-Stack die Arbeit abnehmen, indem die unteren Protokolle, insbesondere das TCP-Handling, auf der Hardware statt der Host-CPU abgewickelt wird - Gigabit-Karten mit Jumbo-Pakets
Für bestimmte Fälle dürfen IP-Pakete auch mal größer als 1514 Bytes sein. - Virtuelle Karten
Sind sie sicher, dass diese Anpassungen auch auf virtuellen Maschinen sauber funktionieren? - Besondere Protokolle
IP ist nicht mehr nur etwas "Websurfen". Über IP werden Datenbanken repliziert und per iSCSI sogar Massenspeicher angebunden. Auch IP over Fiberchannel, Infiniband u.a. fordern den TCP/IP auf ihre eigene Weise
Der Standard Timeout für TCP-Sessions ist bei Windows auf zwei Stunden (7.200.000ms) gestellt und die meisten Applikationen nutzt eigene Timeouts, um ausstehende Request zu erneuern, so dass der TCP-Timeout gar nicht erst zum Tragen kommt. Jeder Applikation ist es zudem freigestellt, selbst den Keep-Alive Timer über Socket-Optionen anzupassen, wenn Sie selbst keinen Keep-Alive unterstützt. NetBIOS hat z.B.: selbst einen Keep-Alive, der viel kürzer als der TCP-Keep-Alive ist.
Sie können auch erst einmal damit anfangen, die aktuellen Einstellungen ihrer Server zu überprüfen.
TCP Keep Alive Time Report Script
https://gallery.technet.microsoft.com/office/TCP-Keep-Alive-Time-Report-c9a240d0
Auch NETSH liefert die aktuellen Einstellungen:
C:\>netsh interface tcp show global Der aktive Status wird abgefragt... Globale TCP-Parameter ---------------------------------------------- Zustand der empfangsseitigen Skalierung : enabled Autom. Abstimmungsgrad Empfangsfenster : normal Add-On "Überlastungssteuerungsanbieter" : default ECN-Funktion : disabled RFC 1323-Zeitstempel : disabled RTO (anfänglich) : 3000 Zustand der Empfangssegmentzusammenfügung : enabled Nicht-SACK-RTT-Widerstandsfähigkeit : disabled Maximale SYN-Neuübertragungen : 2 Fast Open : enabled Fast Open-Fallback : enabled Geschwindigkeitsprofil : off
Allerdings ist der Session Timeout hier nicht aufgelistet.
Sinnvolle Timeout-Werte
Anstatt eine Anpassung an den Endgeräten sollten wie überlegen, welche Timeout-Werte auf den Systemen praktikabel sind, die bislang die Sitzung unterbrechen. Die Werte sollen so groß sein, dass die Clients in dem Intervall auf jeden Fall noch mal Daten übertragen. Sie sollten die Werte nicht auf die 2h ausdehnen, nach denen ein Windows TCP/IP-Stack ein KeepAlive sendet. Der Werte sollte aber klein genug sein, damit wirklich von Clients beendete Verbindungen nicht über Gebühr die Firewalls, Proxy-Server etc. belasten.
Microsoft empfiehlt mindestens 120 Sekunden für die Nutzung mit Office 365.
A minimum of 120 seconds would be a good
idle timeout on egress equipment used for Office 365 as
MAPI/HTTP has application level keep alives set which will
ensure the connection is not prematurely terminated with
this timeout value or above.
Quelle Network Perimeters & TCP Idle session settings for
Outlook on Office 365
https://blogs.technet.microsoft.com/onthewire/2014/03/04/network-perimeters-tcp-idle-session-settings-for-outlook-on-office-365/
Das ist ein ein recht kleiner Wert. Andere Quellen bewegen sich im Bereich von 10-20 Minuten als Timeout für TCP-Sessions. Allerdings haben Sie zumindest von meinen Messungen am Anfang auch gesehen, dass MIcrosoft seinerseits auch nach 100 Sekunden die Verbindung ggfls. abbaut.
- Network Perimeters & TCP Idle session
settings for Outlook on Office 365
https://blogs.technet.microsoft.com/onthewire/2014/03/04/network-perimeters-tcp-idle-session-settings-for-outlook-on-office-365/ - Server Timeouts Property
https://docs.microsoft.com/en-us/windows/desktop/Http/server-timeouts-property
Diverse Seiten empfehlen sogar eine abgestufte Länge. Die Firewall sollte einen längeren Timeout habe als der Router und der Loadbalancer noch weniger, d.h. vom Client zum Backend sinkt der Timeout.
Ich finde das eher verwirrend und wenn Sie wissen, dass von den beiden Endpunkten der TCP-Verbindung der mit dem geringsten Timeout maßgeblich ist, dann müssen die Stationen einfach etwas darüber liegen.
Interessant ist in dem Umfeld natürlich, welche TCP Session Timeout die Office 365 Service haben. Dier Servicebetreiber kann ja durch einen eher kurzen Timeout selbst dafür sorgen, dass auf Kosten zusätzlicher Keep-Alive-Pakete keine Session auf dem Transportweg wegen Inaktivität gelöscht wird.
Sonderfall NAT
Als ich diesen Artikel geschrieben habe, war ich Zug unterwegs und per UMTS-Karte im Vodafone-Netzwerk online. Ich habe auch hier mein Tests mit Invoke-Webrequest gemacht, da hierbei ja die TCP-Session beibehalten wird. Das ist mit Netmon auch sehr schön zu sehen. Mein Client mit der 100.82.38.21 sendet mit Port 56138 die Pakete an meinen WebServer.

Interessanterweise liefert mit die Rückantwort eine andere IP-Adresse, die aber zumindest gleich bleibt und mit jedem Request einen anderen Source-Port

Zuerst bin ich davon ausgegangen, dass Vodafone hier etwas umsetzt. Zumal meine UMTS-IP-Adresse 100.82.38.21 gar nicht auf dem WebServer angekommen ist. Da ist auf jeden Fall ein NAT mit drin.
Ich habe dann den Test "zuhause" noch mal wiederholt. Hier hatte ich aber den gleichen Effekt. Der per PHP ermittelte Source-Port war mit jedem Request anders. Über die Trace-Funktion der Fritz!Box (http://fritz.box/html/capture.html) habe ich dann die auf der WAN-Seite ausgehenden Pakete mitgeschnitten. Wie erwartet war hier der Source-Port immer gleich:

Mein PHP-Script hat hier zumindest die gleichen Source-IP-Adresse (46.85.246.65) des DSL-Routers geliefert. Der DSL-Provider (Telekom) macht hier also kein NAT der IP-Adressen. Allerdings waren die Source Ports auch jedes mal was Eigenes. Da ich aber hier im Mitschnitt keine RESET oder neue Aushandlung gesehen habe, suche ich noch nach der Ursache. Vielleicht ist auch die PHP-Abfrage so gar nicht richtig. Ich muss mir mal einen Windows /Linux-Host im Internet suchen, auf dem ich dann per Netzwerk-Sniffer genauer anschauen kann, was real ankommt.
Ich werde mal eine VM in Azure mit öffentlicher IP starten und dort per Netmon und PHP schauen, welche Daten ich bekomme.
Das Problem betrifft PHP bei 1und1 genauso wie bei OVH. Ich denke es liegt daher eher an der falschen Abfrage.
- Fritz!Box 7490 Service: Paketmitschnitt (Internet) + Support-Daten erstellen
https://avm.de/service/fritzbox/fritzbox-7490/wissensdatenbank/publication/show/1387_Paketmitschnitt-Internet-Support-Daten-erstellen/
Weitere Links
- HTTP Chunked
- HTTP Keep-alive
- TCP SYN ACK RES
- TCP Retransmit Monitoring
- Test-TCPTimeout - Timeout zwischen IP-Endpunkten austesten
- Packet Loss
- Outlook TCP-Connections
- TCP Retransmit Monitoring
- Cloud Verbindung
- Network Perimeters & TCP Idle session settings for Outlook on Office 365
https://blogs.technet.microsoft.com/onthewire/2014/03/04/network-perimeters-tcp-idle-session-settings-for-outlook-on-office-365/ - For Exchange 2010, 2013, and 2016 do this before calling
Microsoft
https://blogs.technet.microsoft.com/david231/2015/03/30/for-exchange-2010-and-2013-do-this-before-calling-microsoft/ - Things that you may want to know about TCP Keepalives
https://blogs.technet.microsoft.com/nettracer/2010/06/03/things-that-you-may-want-to-know-about-tcp-keepalives/ - How to troubleshoot non-browser apps that can’t sign in to
Office 365, Azure, or Intune
https://support.microsoft.com/en-us/help/2637629/how-to-troubleshoot-non-browser-apps-that-can-t-sign-in-to-office-365 - Requirements for Internet Hosts -- Communication Layers
4.2.3.6 TCP Keepalives
https://tools.ietf.org/html/rfc1122#page-101 - Appendix A: TCP/IP Configuration Parameters
https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2003/cc739819 - Keepalive - Wikipedia
https://en.wikipedia.org/wiki/Keepalive - Ryte WIki Keep-Alive
https://de.ryte.com/wiki/Keep-Alive













