
Dreimal 401 mit Negotiate
Eigentlich war es nur ein Kennwortdialog, der in Outlook immer mal wieder aufgetaucht ist. Auf der Seite Kennwortbox habe ich schon die häufigsten Ursachen beschrieben. Hier beschreibe ich ein Verhalten, welches sehr suspekt ist und vielleicht hilft ihnen die Analyse bei der eigenen Fehlersuche. Der Fehler tritt meines Wissen nur bei einer Anmeldung per NTLM auf und Fiddler ist manchmal sogar störend bei der Analyse.
HTTP Anmeldung, Negotiate und "HTTP/1.1 401 Unauthorized"
Wenn ein HTTP-Client sich mit einem Server verbindet, dann weiß er anfangs ja noch gar nicht, welche Authentifizierungsverfahren der Server unterstützt und ob eine Anmeldung überhaupt erforderlich ist. Viele Webseiten im Internet sind ja anonym erreichbar, auch wenn anonym für die Werbewelt natürlich zu relativieren ist. Wenn eine Ressource aber nicht anonym erreichbar ist, dann weist der Webserver die erste Anfrage erst mal mit einem 401-Fehler ab.
Verwechseln Sie das nicht mit einem "HTTP/1.1 403 Forbidden" oder "HTTP/1.1 404 Not Found", bei denen keine weitere Verarbeitung erfolgt.
Der 401-Fehler enthält aber die erforderlichen Informationen, damit der Client die nächste Anfrage besser stellen kann. Maßgeblich ist hier der "Authentication"-Header in der Antwort. Hier ein Beispiel von Office 365 EWS mit einem Invoke-Webrequest. Office 365 erkennt, dass dieser Client kein "ModernAuth" kann und bietet nur "BasicAuth" an

Ein anderes Beispiel ist eine Autodiscover-Anfrage in einem internen Netzwerk mit:
Invoke-WebRequest ` -Method POST ` -URI https://autodiscover.netatwork.de/Autodiscover/autodiscover.xml
Hier ist dann gut zu sehen, dass neben Basic auch NTLM und Negotiate angeboten wird. Das Angebot machen einige Server durchaus davon abhängig, aus welchem Subnetz und mit welchem User-Agent der Client die Anfrage stellt. So unterscheidet Exchange Online sehr wohl zwischen Clients, die ModernAuth/OAUTH2 beherrschen und "rückständigen" Clients.

Es liegt nun am Client zu entscheiden, welches Verfahren er nimmt. Das hängt von verschiedenen Kriterien ab:
- Was kann der Client
"Basic" sollte jeder Client können. Aber NTLM ist vielleicht schon seltener und Negotiate benötigt weitere Nachfragen, was nun genau die Gegenseite darunter versteht - Internet-Zonen
Clients beachten ggfls. Zoneneinstellungen, z.B. dass Sie nur in der "Intranet-Zone" automatisch sich anmelden, d.h. ihr Kennwort oder NTLM-Hashwerte senden. Im Internet ist meist nicht gewollt. Ansonsten könnte eine Webseite ja eine URL, z.B. Zählpixel, nur nach Anmeldung erreichbar machen und so den Anmeldeversuch samt Benutzername einfangen.. - Kerberos-Abhängigkeiten
Wenn ein Client sich entscheidet per Kerberos eine Anmeldung durchzuführen, dann muss er natürlich ein Ticket erhalten. Ansonsten wird er ein anderes Verfahren nutzen.
Der Schwerpunkt liegt bei uns nun aber beim Thema Negotiate/NTLM.
Browser und Negotiate/NTLM
Ich habe hier mal eine Anmeldung an einem Dienste per Negotiate/NTLM aufgezeichnet. Sie sehen, dass der Client drei Anfragen braucht, bis er ein "200 OK" erreicht.
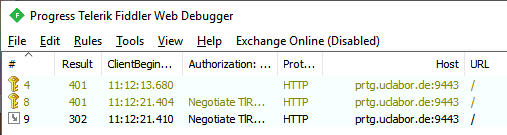
Das ist eine Besonderheit bei der Nutzung von NTLM, welche ich kurz erkläre:
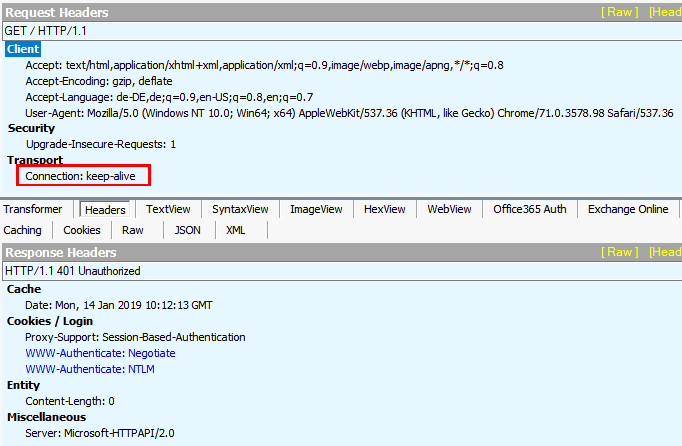
- Request 1: Anonyme Anfrage
Zuerst sendet der Client eine anonyme Anfrage. Er weiss ja noch nichts vom Server und den Anforderungen. Der Server lehnt unter Angabe der möglichen Anmeldeoptionen ab:
- Request2: Negotiate/NTLM Handshake
Es sieht erst mal nach einer Anmeldung per NTLM aus, der auch mit einem 401 abgelehnt wird.
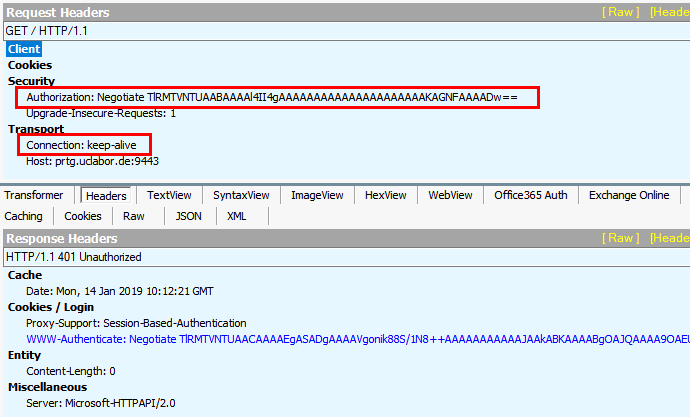
Schauen Sie sich aber den AuthHeader genauer an. Sie sehen, dass da noch nichts "drin". Es ist der "Handshake" im Rahmen des Negotiate-Protokolls mit den Möglichkeiten des Clients,
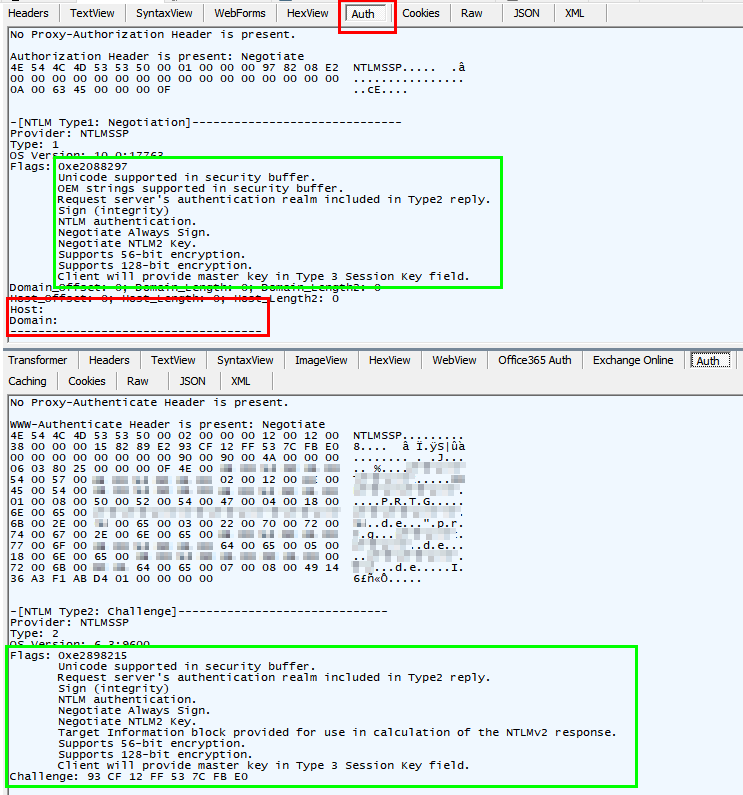
Der Server antwortet darauf wieder mit einem 401 aber liefert dem Client die Information, welche Negotiate-Optionen er akzeptiert. Zudem bekommt der Client für NTLM den notwendigen Challenge. - Request 3: Die Anmeldung
Erst jetzt kann der Client die Anmeldung korrekt ausführen und bekommt auch ein 200 OK, wenn es die angefragte Ressource gibt und er darauf berechtigt ist. Der Auth-Header ist auch deutlich länger.

Ich habe den Auth-teil des Requests etwas gekürzt aber sie können auch so sehen, dass hier kein Kerberos sondern NTLMv2 zum Einsatz gekommen ist und die "lm_resp" am Ende "00" ist

Das bedeutet aber auch, dass nach zwei 401-Einträgen im IISLog ein 200OK kommen sollte. Ansonsten bekommt der Anwender eine Rückfrage zur Eingabe der korrekten Anmeldedaten.
403 mit Loadbalancer
Nun scheibe ich so eine Seite nicht aus Langeweile, sondern weil mir etwas bei meinem Teste und Skripten aufgefallen ist. Ich habe per EWS ein Postfach im Rahmen eines Monitoring immer geöffnet und geschlossen. Dazu habe ich meinen Code aus End2End EWS genutzt und es gab immer mal wieder 401 Anmeldefehler. Also habe ich Fiddler angeworfen und mir die Fehler genauer angeschaut.

Ich sehe hier also drei Anfragen aber die letzte hat auch noch einen 401. Also stelle ich die Requests mal nebeneinander auf. Man sieht schön den ersten anonymen Kontakt mit den unterstützten Authentifizierungsverfahren. Der zweite Request ist dann die Negotiate-Aushandlung aber die dritte Anfrage mit den Anmeldedaten funktioniert nicht!
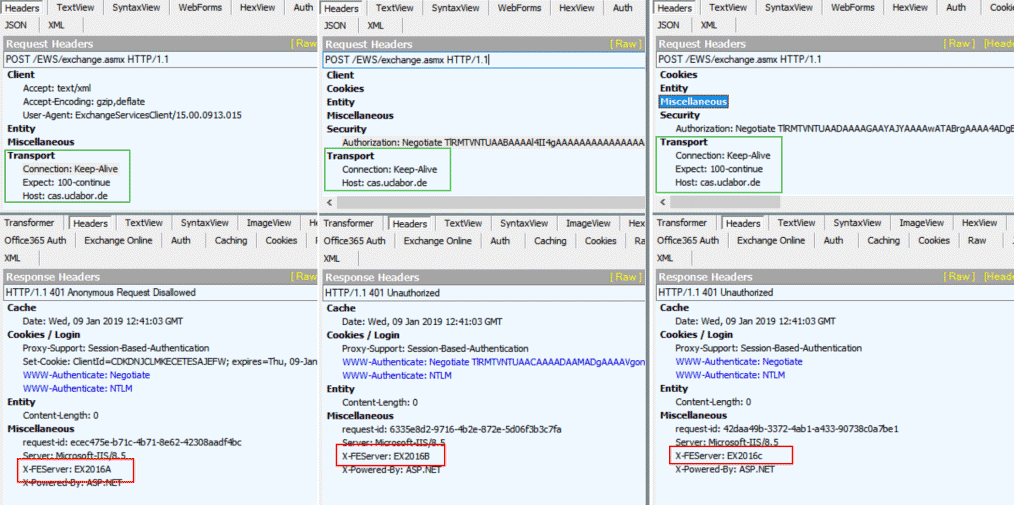
Ale drei Requests haben den Header "Connection: Keep-Alive", womit der Client mitteilt, dass die Verbindung bestehen bleibt. Irritierend ist dann aber, dass der "X-FEServer" zwischen den Requests wechselt. Insbesondere der Wechsel von Request 2 zu Request 3 ist für NTLM natürlich tödlich. Denn der zweite Server übermittelt einen NTLM-Challenge, den der Client als Basis für die Credentials nutzt. Diese Information hat kein anderer Server und wenn der Server hier wechselt, dann sendet der Client einen NTLM-Request an einen Server, der diesen nicht versteht. Damit ist der 401 auch verständlich.
Loadbalancer oder Client ?
Wer den Request genau betrachtet, sieht den Hostnamen "cas.uclabor.de" als Zieladresse für den Request während im Hintergrund drei unterschiedliche Frontend Server antworten. Also muss eine Verteilung durch einen Loadbalancer, DNS Round Robin, Network Load Balancing (NLB) o.ä., erfolgen. In dem Fall war nun ein Loadblancer im Boot, der die Verbindungen weiter gereicht hat.
So lag erst mal der Verdacht nahe, dass dieser keinerlei Persistenz nutzt. Microsoft sagt zwar, dass Exchange 2013 keine Persistenz mehr benötigt und jeder "Request" an einen beliebigen Frontend Server gehen kann. Das stimmt aber nur, wenn der Request z.B.: per Bearer-Token, SAML-Token o.ä. enthält und damit vom Server direkt ausgewertet werden kann.
Beim Prozess der Anmeldung hingegen, der hier aus drei Requests besteht, muss der Client immer beim gleichen Backend-Server bleiben. Nun sind Loadbalancer durchaus knifflig aber dass eine bestehende TCP-Session auf dem Backend nach "Round Robin" verteilt wird, wäre schon ungewöhnlich. Daher habe ich auf dem Client mit Wireshark mit die TCP-Verbindungen angeschaut. Erwartet habe ich einen TCP-Handshake mit einem TLS-Aufbau und dann drei Gruppen von Paketen. Gefunden habe ich aber folgendes:
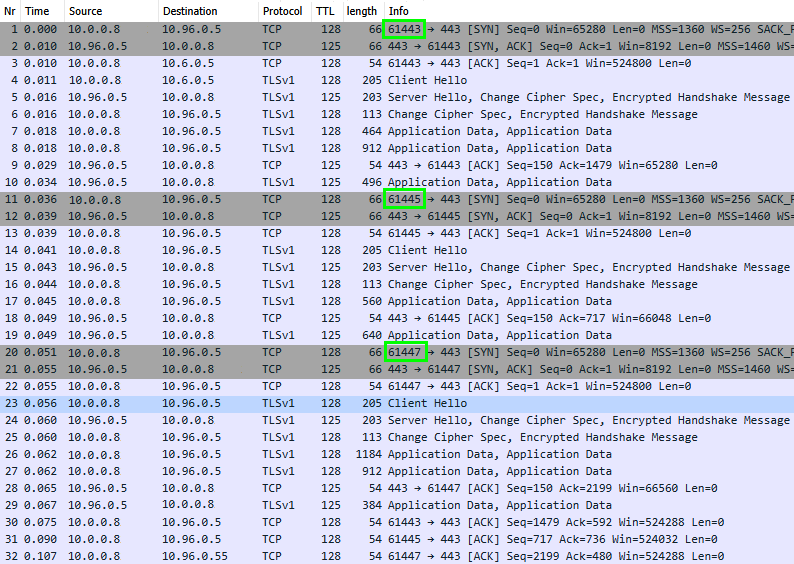
Ich finde hier drei eigenständige TCP-Verbindungen, die neu aufgebaut werden. Damit ist für den Loadbalancer es natürlich knifflig die Pakete immer zum gleichen Frontend Server zu senden, wenn nicht mindestens eine "Source-IP"-Persistence konfiguriert werden.
Leider habe ich keinen schnellen Weg gefunden um in Fiddler die "ClientIP:Port" mit anzuzeigen.
Das ist aber ungeschickt, wenn viele Clients über die gleiche Source-IP auf dem Loadbalancer ankommen. Terminal Server sind ein Fall aber auch Reverse-Proxy Server oder VPN-Server als Brücke aus dem Internet. Mein Test erfolgte mit der EWS-DLL unter Nutzung meines Skripts End2End EWS. Ich habe meine Analysen noch nicht abgeschlossen aber das Verhalten der EWS.DLL 2.1 auf diesem Client würde ich als Fehler bezeichnen. Es macht keinen Sinn selbst während der Anmeldung jedes mal eine neue TCP-Connection samt TLS-Handshake aufzubauen.
Es scheint auch kein generelles Problem zu sein, wenn der Großteil der Anwender arbeitet problemlos und nur wenige wechselnde Clients sind betroffen, wenn Sie sich über NTLM anmelden.
Basic, Kerberos, Bearer?
In dem Zuge stellt sich natürlich die Frage, warum das Problem nur bestimmte Clients erwischt, die über den Loadbalancer die Umgebung erreichen. Wenn Sie sich aber den Anmeldeprozess in Erinnerung rufen, dann verstehen sie die Beschränkung des Problems auf NTLM.
- Basic Authentication
Hier gibt es ja kein Challenge o.ä. Der Client sendet nach dem ersten 401 direkt einen Request mit Benutzername und Kennwort. Der Server kann damit die Anmeldung komplett mit einem Paket durchführen. - Kerberos
Auch wenn hier ebenfalls Negotiate als Container eingesetzt wird, so enthält ein Kerberos-Ticket alle Informationen über den Benutzer in signierter und verschlüsselter Form, welche von jedem Frontend Server decodiert werden kann. Auch hier gibt es keinen Challenge sondern das zweite Paket nach dem ersten 401 "passt" - Bearer/Tickets/Cookies
Heute ist es üblich, dass man nur einmal anfangs eine Authentifizierung durchführt und der Service dann ein Applikationsticket ausstellt und während der Laufzeit der Session auch immer wieder erneuert. Auch hier gibt es dann keinen Challenge mehr und die Thematik entfällt.
Es dürfte also wirklich nur NTLM betreffen, bei dem der Server erst einen Challenge sendet, der vom Client in die Authentifizierung eingebaut wird. So stellt Microsoft sicher, dass eben nicht das Kennwort selbst in Klartext oder verschlüsselt übertragen wird sondern nur das Ergebnis einer einmal gültigen Rechenoperation. Genau dieses Challenge-Response-Verfahren führt hier zu den Problemen wenn die Antwort auf den Challenge nicht wieder beim gleichen Server landet.
Betroffene Clients ermitteln?
Die Analyse von Wireshark, Fiddler und Loadbalancer ist nichts, was sie permanent machen. Zudem sind hier mehrere Team (Client, Netzwerk, Exchange) involviert, die Sie nicht immer an einen Tisch bekommen. Aber alle Requests kommen letztlich bei den Exchange Servern an. Ganz so einfach ist es aber nicht, denn...
- Viele Server
Wenn das Problem bei ihnen vorhanden ist, dann haben Sie mehrere Server und die Zugriffe laufen auf unterschiedlichen Servern auf. Sie müssen also mehrere Logs zusammenführen - Anonym statt Username
In den IISLogs landen zwar die Zugriffe aber der Benutzername ist nur dann enthalten, wenn die Authentifizierung erfolgreich war. Bei einem 401 ist das aber nicht der Fall. Im Log steht an der Stelle Username also nur ein "-" - Source-IP und
X-Forwarded-For
Bei einer Gruppierung nach der Client-IP ist darauf zu achten, dass je nach Loadbalancing die IP-Adresse des Loadbalancers geloggt wird. In Verbindungen mit Layer-7 Loadbalancing sollte der HLB einen "X-Forwarded-For" Header addieren und dieser im IIS mit in das Log geschrieben werden. - Parallele Requests und "Request-ID"
Es kann durchaus sein, dass ein Client zur gleichen Zeit mehrere HTTP-Verbindungen startet und jede 2x einen 401 liefert. Eventuell lässt sich dies durch ein Loggen von zusätzlichen Header-Feldern, z.B. dem Feld "Request-ID" lösen. Allerdings haben Sie in meinem Trace oben auch gesehen, dass hier unterschiedliche Requests erscheinen.
Mit dem Wissen können Sie aber schon versuchen z.B. die Request von der gleichen Client-IP innerhalb eines Zeitfensters von vielleicht 1-2 Sekunden zusammenfassen und einen 200OK zu erwarten. Programme wie LogParser oder PowerShell helfen natürlich auch bei der Auswertung von IISLogs.
Je nach Loadbalancer können Sie natürlich auch auf diesem System ein Logging aktivieren, mit dem Sie bei einem 401 Fehler die Client-IP samt Port und den ZielServer protokollieren. Hier sollten Sie dann auch schnell erkennen, ob Anfragen eines Clients bei unterschiedlichen Servern landen oder vermehrt 401-Fehler hintereinander auftreten, die nicht umgehend von einem 200 OK abgeschlossen werden.
Zusammenfassung
Das hier beschrieben Thema ist für mich wieder ein gutes Beispiele, dass manchmal ein Problem sehr vielfältige Themen berührt und unterschiedlichste Punkte zu bearbeiten sind. Das Problem ist real aber sehr selten, denn ursächlich ist hier das Fehlverhalten des Clients, welcher bei einer HTTP-Anmeldung per "Negotiate mit NTLM" neue TCP-Verbindungen aufmachen und dann bei unterschiedlichen Frontend Servern landet.
Bei den meisten Firmen funktioniert selbst diese Anmeldung, da ein Loadbalancer mit "Least Connection" den Client in den meisten Fällen ja zum gleichen Real-Servern sendet und vor allem weil eine bestehende Verbindung auch beim gleichen Backend Real-Server
Das macht die Suche nach dem Fehler auch so knifflig und ich war quasi froh, dass mein EWS-Client so vorhersehbar und reproduzierbar falsch gefragt hat. Das half aber erst einmal nicht weiter, denn auf der anderen Seite scheint sich der Großteil der Client auch richtig zu verhalten und die bestehende TCP-Connection zu nutzen und damit vom Loadbalancer nicht verteilt zu werden.
Ich muss also überlegen, warum sich meine EWS.DLL in Verbindung mit NTLM so seltsam verhält und überflüssigerweise und mit einem HLB inkompatible neue Verbindungen startet und ob dies in der Fehlerumgebung tatsächlich der Grund ist.
Weitere Links
- Kennwortbox
- End2End EWS
- Fiddler
- Wireshark
- X-Forwarded-For
- Loadbalancer
- DNS Round Robin
- Network Load Balancing (NLB)
-
Wikipedia: SPNEGO
https://en.wikipedia.org/wiki/SPNEGO -
Single Sign-on für HTTP-Anforderungen mit
SPNEGO-Webauthentifizierung
https://www.ibm.com/support/knowledgecenter/de/SSEQTP_liberty/com.ibm.websphere.wlp.doc/ae/cwlp_spnego.html













