
Regular Expressions - RegEx
Sobald Sie anfangen, Skripte und Programme zu schreiben, stellen sich immer wieder sehr ähnliche Aufgaben, die Sie mit klassischen Schleifen und InStr-Befehlen nur sehr aufwändig lösen können. Dazu gehört z.B.
- Extrahiere alle Mailadressen aus einem String
- Entferne alle nicht druckbaren Zeichen aus einer Zeichenkette
- Prüfe, ob eine Eingabe einer entsprechenden Vorgabe entspricht.
z.B.: ist es eine formal gültige Mailadresse, Kreditkartennummer, Bankleitzahl etc.
Das hört sich alles erst einmal nicht spektakulär an, aber bei der Umsetzung fällt es dann doch schwerer, alle Sonderfälle etc. zu berücksichtigen. Letztlich bauen Sie dann eine Konstruktion aus Schleifen und IF-Abfragen zusammen, die letztlich niemand mehr durchschaut.
Kurze Einführung in RegEx
Dabei geht es einfacher. Erinnern Sie sich doch einmal an ihre DOS-Zeiten in der Kommandozeile. Durch den Befehl "DIR" wurden alle Dateien eines Verzeichnisses aufgelistet. Wenn Sie aber nur die Word-Dokumente sehen wollten, konnten sie mit "DIR *.DOC" einen entsprechenden Filter anwenden. Wenn Sie alle Dateien mit genau 5 Zeichen sehen wollten, dann war "DIR ?????.*" ein geeigneter Ausdruck. In die gleiche Richtung gehen nun auch RegEx-Ausdrücke, die aber noch viel mehr Möglichkeiten bieten. Neben "*" und "?" gibt es sehr viel mehr Möglichkeiten. Hier eine kleine Auswahl:
| Zeichen | Bedeutung |
|---|---|
^ |
Entspricht dem Anfang einer Zeichenkette |
$ |
Entspricht dem Ende einer Zeichenfolge |
[a-z] |
Entspricht den Zeichen a bis z (nur Kleinbuchstaben !) |
* |
Null oder mehrfach |
+ |
Ein bis n mal |
? |
Null oder einmal |
{2,4} |
zwei bis 4 mal |
Entsprechend gibt es noch jede Menge weitere Schlüsselworte, die auch die Anzahl und Wiederholung von Zeichen festlegen. Mit regulären Ausdrücken können Sie programmatisch prüfen, ob das Element enthalten ist, Sie können die Werte ersetzen oder auch diese Teile extrahieren.
Entwicklung einer SMTP-Regel
Als Muster möchte ich hier langsam an die Bildung einer SMTP-Regel heranführen. Eine Mailadresse hat meist folgendes Format:
namensteil @ domainteil . domainteil
Dabei kann der Namensteil aus verschiedenen Zeichen bestehen, der zwingend durch ein "@" gefolgt wird, worauf ein Domainteil mit mindestens einem "." (Punkt) folgt. Ein erster RegEx Ausdruck könnte daher wie folgt aussehen:
[a-zA-Z]@[a-zA-Z].[a-zA-Z]
Nur ist hier natürlich bei weitem noch nicht alles berücksichtigt. Es gibt Sonderzeichen wie "?\/-" die im Namensteil erlaubt sind, aber nicht im Domain Teil. Zudem darf im Namensteil ein "." nicht das letzte Zeichen sein, d.h. frank.@msxfaq.de ist keine gültige Adresse. Auch eine Domäne mit zwei Punkten wäre mit dieser Regel noch nicht berücksichtigt. Genau genommen könnte man auch die Länge der einzelnen Teile auf Plausibilität prüfen. Der Länderanteil war lange Zeit immer 2. oder 3-stellig. Erst seit der Einführung von "info", "museum" und anderen neuen Top Level Domains ist so eine Einschränkung wie der folgende Ausdruck mit Vorsicht zu genießen.
^[\w-\.\{\}#\+\&\-]{1,}\@([\da-zA-Z-\{\}#]{1,}\.){1,}[\da-zA-Z-]{2,3}$
Auch dieser Ausdruck ist nicht 100% korrekt, da sehr viele Sonderzeichen und andere Dinge nicht geprüft werden. Aber es gibt sehr viele andere Webseiten im Internet, die hier ganze Arbeit geleistet haben. Besonders ist folgender Link zu nennen:
-
http://www.twilightsoul.com/Default.aspx?PageContentMode=1&tabid=134
RFC2822 Prüfung komplett - http://www.regular-expressions.info/email.html
Und das kann dann für die SMTP-Adresse bestehend aus dem lokale Teil (Localpart) und dem Domänenteil dann etwa so aussehen:
[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+
(?:[A-Z]{2}|com|org|net|gov|biz|info|name|aero|biz|info|jobs|museum)\b
Das ist aber ein sehr brauchbares RegEx-Pattern für die Prüfung von Mailadressen, der auch im folgenden Codebeispiel eingesetzt wird.
Aber man kann mit Regular Expressions auch Strings "teilen". Hie am Beispiel einer URI Aufteilung
"^(?:(?<protocol>[^:/\?#]+):)?(?://(?<authority>[^/\?#]*))?(?<path>[^\?#]*)(?:\?(?<query>[^#]*))?(?:\#(?<fragment>.*))?"
Die URI wird in ihre Bestandteile aufgelöst, welche dann als Match sogar direkt abrufbar sind
if ($uri -match "^(?:(?<protocol>[^:/\?#]+):)?(?://(?<authority>[^/\?#]*))?(?<path>[^\?#]*)(?:\?(?<query>[^#]*))?(?:\#(?<fragment>.*))?") {
write-host $matches[protocol]
write-host $matches[host]
write-host $matches[path]
write-host $matches[query]
write-host $matches[fragment]
}
Anwenden im Code
Nach so viel Theorie stellt sich natürlich die Frage, wie man einen RegEx Ausdruck z.B. in einem VBScript verwendet. Folgernde Funktion prüft, ob die übergebene Mailadresse gültig ist.
Funktion IsSMTPValid(strAdresse)
Dim regEx
Set regEx = New RegExp
regEx.Pattern = "^[\w-\.\{\}#\+\&\-]{1,}\@([\da-zA-Z-\{\}#]{1,}\.){1,}[\da-zA-Z-]{2,3}$"
regex.IgnoreCase = true ' ignore case
IsSMTPValid = regEx.Test(strAdresse)
end function
Aus Performancegründen sollten Sie bei der Überprüfung vieler Adressen jedoch die Funktion in eine Klasse verwandeln, damit nicht jedes Mal das RegEx Objekt neu erstellt und befüllt werden muss. Das könnte dann wie folgt aussehen. Die ersten sechs Zeilen zeigen gleich, wie die Klasse zu verwenden ist.
dim osmtptest
set osmtptest = new ValidSMTP
wscript.echo ("ValidSMTP 1:" & osmtptest.test("ValidSMTP@carius.de"))
wscript.echo ("ValidSMTP 0:" & osmtptest.test("ValidSMTP.@carius.de"))
msgbox ("Fertig")
wscript.quit(0)
Class ValidSMTP
' Generic Class to validate an given SMTP-Address against formal rules
dim SMTPRegEx
private Sub Class_Initialize
Set SMTPregEx = New RegExp
SMTPregEx.Pattern = "^[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*"_
&"@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+"_
&"(?:[A-Z]{2}|com|org|net|gov|biz|info|name|aero|biz|info|jobs|museum)\b"
SMTPregEx.IgnoreCase = true
end sub
private Sub Class_Terminate() : Set SMTPregEx = nothing : End Sub
function Test(wert)
test = SMTPregEx.test(wert) ' Test is true if Match is found
end function
end class
Sie müssen den hier verwendeten RegEx-Ausdruck nicht wirklich auf Anhieb verstehen. Ich tue es auch nicht. Mit entsprechenden Hilfsprogrammen ist es aber problemlos möglich, diese Ausdrücke auch grafisch auseinander zu nehmen und dann tatsächlich zu verstehen.
Reguläre Ausdrücke können aber nicht nur einen vorgegebenen String prüfen, sondern auch jedes Vorkommen davon ersetzen. Folgendes kurzes Codesegment ersetzt alle ungültigen Zeichen eines Dateinamens durch ein "-".
dim objRegex
set objRegex = new RegExp
objRegex.pattern = "[\\/:\*\?<\|""]{1,}"
objRegex.global = true
wscript.echo objRegEx.replace (dateiname,"-")
Ideal, wenn Sie z.B.: mit den Funktion Time() und Date() die aktuelle Zeit in einen Dateinamen einbauen. Je nach Ländereinstellung kommen dort auch diese Sonderzeichen vor, so dass die Funktion z.B.: in Deutschland funktionieren mag aber in Italien z.B. nicht mehr. Das gleiche Gilt übrigens auch für das Feld "DistinguishedName" im Active Directory, aber auch Texte, die sie in eine HTML oder XML-Datei schreiben wollen und viele anderen Felder, wo einige Zeichen eine besondere Behandlung benötigen.
RegEx Limit in VBScript
Leider unterstützt nicht jedes Objektmodell den kompletten Sprachumfang von Regular Expressions. Gerade das von VBScript genutzte Objekt kann einige Funktionen nicht.
Die wesentlichen Dinge, auf die ich selbst schon gestoßen bin:
- Keine "Names"-Tags.
Man kann also einen Treffer nicht mit (?<name>xxx) kennzeichnen um später mit sprechendem Code drauf zuzugreifen. - Kein unicode
Man kann einzelne Zeichen zwar mit \uFFFF verwenden aber generell ist UNICODE nicht möglich.
Weitere detaillierte Hinweise finden Sie z.B. auf:
- VBScript's Regular Expression Support
http://www.regular-expressions.info/vbscript.html
RegEx testen
Nun können Sie natürlich nicht erst immer ein Programme schreiben, um ihren eigenen RegEx-Ausdruck zu testen. Auch ist die Eingabe und Entwicklung dieser Ausdrücke alles andere einfach und überschaubar. daher gibt es entsprechende Hilfsprogramme, welche für die die Auswertung übernehmen oder sogar grafisch die Struktur analysieren und die Zusammenstellung erlauben.
So hilft z.B. das "Regular Expression Workbench" bei der Eingabe, Analyse und Test von regulären Ausdrücken.
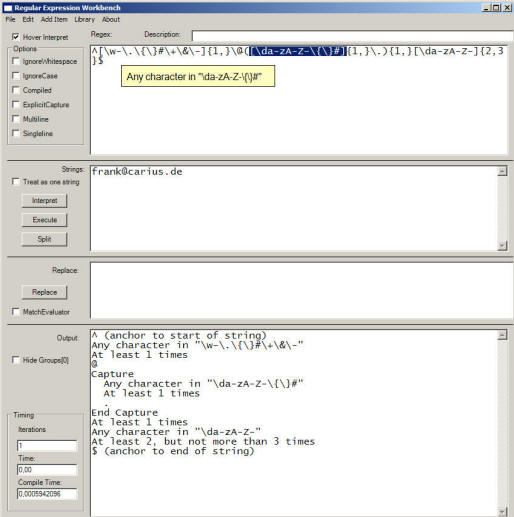
Auch "The Regulator" ist ein guter Einstieg in die Materie:
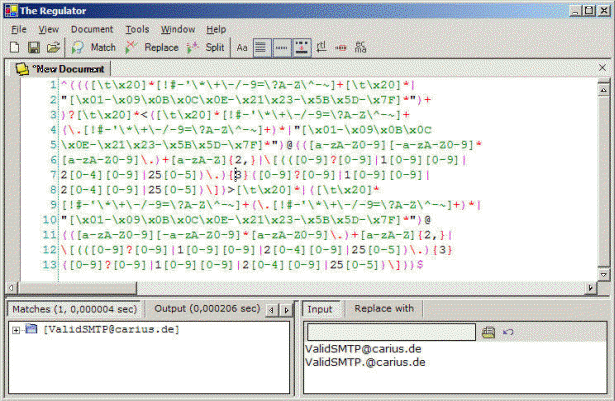
Mit solchen Hilfsmitteln ist es dann doch einfacher, einen RegEx Ausdruck zu entwickeln und zu testen.
- Regex Workbench
https://blogs.msdn.microsoft.com/ericgu/2003/07/07/regular-expression-workbench-v2-0/ - Regulator
https://osherove.com/tools
Regex und PowerShell
Auch mit der PowerShell kann man sehr einfach dank der .NET Anbindung mit Regular Expressions arbeiten, und damit sehr viele "Suchen und Ersetzen"-Funktionen überflüssig machen.
PS C:\msxfaq\ocs> [regex]$reg="w.*"
PS C:\msxfaq\ocs> $reg.Match("Wert")
Groups : {}
Success : False
Captures : {}
Index : 0
Length : 0
Value :
PS C:\msxfaq\ocs> $reg.Match("wert")
Groups : {wert}
Success : True
Captures : {wert}
Index : 0
Length : 4
Value : wert
Auch ein Aufteilen als auch Ersetzen ist recht einfach.
PS C:\msxfaq\ocs> [regex]$reg="0.*\((\d*)\)\D*(\d*)\D*(\d*)"
PS C:\msxfaq\ocs> $reg.Split("0(5251)304-600")
5251
304
600
PS C:\msxfaq\ocs> $reg.replace("0(5251)304-600",'+49$1$2$3')
+495251304600
Extrem pfiffig ist der Einsatz über eine Switch Bedingung, bei der man einen Wert gleich gegen mehrere reguläre Ausdrücke prüfen kann:
$var = "Wert"
switch -regex ($var) {
"Wert" {Write-Host "Genaue uebereinstimmung" $_
break
}
"Wert.*" {
Write-Host "Anfang passt " $_
break
}
"W.*" {
Write-Host "Erster Buchstabe passt" $_
break
}
default {
Write-Host "keine uebereinstimmung" $_
break
}
}
Es geht natürlich auch "direkter" ohne das RegEx-Objekt über "-match"
$line = 'Ip ist 10.1.1.2:123 gewesen'
if ($line -match '(.*\s(?<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):(?<port>\d{1,5}).*)') {
Write-Host "IP :" $matches.ip
Write-Host "Port:" $matches.port
}
Hinweis: Diese "-match"-Abfrage liefert das Ergebnis der Abfrage in der Variable "$matches"
Auch das direkte Suchen und ersetzen mit "-replace" macht vieles einfacher und dank den Named-Captures auch lesbar. Dieses Beispiel sucht eine IPv4-Adresse anhand der Schreibweise und
'Ip ist 10.1.1.2 gewesen' -replace '(.*\s(?<endpoint>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).*)', '${endpoint}'
Diese direkte Veränderung beeinflusst nicht die Variable "$matches"
- PowerShell regex crash course
Part 2 https://blogs.technet.microsoft.com/heyscriptingguy/2016/10/07/powershell-regex-crash-course-part-2-of-5/
HTML mit REGEX Parsen
Gleich vorneweg: per REGEX bekommen Sie nicht mit einem vertretbarem Aufwand einen Parser für HTML-Inhalte hin. HTML ist zwar strukturiert aber dennoch sehr variabel verschachtelbar. Aber REGEX kann man durchaus nutzen, um Informationen schnell aus HTML-Seiten zu extrahieren, wenn diese relativ statisch sind oder die Bereiche z.B. durch die Angabe einer "ID" identifizierbar sind.
Sie sollten zuerst aber prüfen, ob sie nicht einfach die HTML-Information ein DOM-Objekt des IE werfen und dann einfach und strukturiert darüber gehen können.
Bei der Entwicklung eines PRTG:Custom Sensor und dem Download einer Webseite mit dem PS HTTPClient konnte ich leider nicht auf den IE zurückgreifen, da das PowerShell-Script nicht als Benutzer, sondern als System läuft und nicht instanziert werden konnte. Aber selbst der Test mit dem geparsten HTML war sehr langsam, so dass ich einen alternativen Weg gesucht habe. Auf der Seite PRTG Kostal finden Sie weitergehende Informationen. Die HTML-Seite besteht überwiegend aus HTML-Tabellen und die gewünschten Werte stehen in Tabellenzellen, die per "<td> </td>" eingerahmt sind. Da liegt es nahe den String an diesen Stellen aufzuschneiden und dann einfach die Vorkommen zu nummerieren.
Mit PowerShell gibt es zwei mit bekannte Optionen, um String zu teilen
- Regex.Split Method
http://msdn.microsoft.com/de-de/library/system.text.regularexpressions.regex.split(v=vs.110).aspx -
StringSplitOptions-Enumeration
http://msdn.microsoft.com/de-de/library/system.stringsplitoptions(v=vs.80).aspx
Die einfache Split-Methode trennt per Default erst mal nur nach einzelnen Zeichen und muss schon quasi gezwungen werden, einen String als Trenner zu akzeptieren.
PS C:\> "11<a>22</a>33<a>44</a ll>55".split(@("<a>"), [System.StringSplitOptions]::None)
Schade nur, dass man damit erst mal nur ein Tag erwischt und auch noch einen "exakten" Match braucht. Wenn so ein "<td>" Feld noch einen Parameter hat, passt das schon nicht mehr und auch das "</td>" müsste ich getrennt behandeln.
Daher bin ich wieder bei Regular Expressions (RegEx) gelandet, die das doch flexibler zulassen. Zuerst habe ich mich mit "SPLIT" angenähert:
PS C:\> ("11<td>22</td>33<td>44</td 22>55" -split "<td>")
11
22</td>33
44</td 22>55
PS C:\> ("11<td>22</td>33<td>44</td 22>55" -split "<.*td>")
11
44</td 22>55
PS C:\> ("11<td>22</td>33<td>44</td 22>55" -split "<.*?td>")
11
22
33
44</td 22>55
PS C:\> ("11<td>22</td>33<td>44</td 22>55" -split "<.*?td.*?>")
11
22
33
44
55
PS C:\> ("11<td>22</td>33<td>44</td ll>55" -split "<.*?td.*?>")
11
22
33
44
55
So richtig habe ich es damit aber nicht geschafft nur die String zu erhalten, die in einem "<td> </td>"- Segment eingeschlossen sind. Daher hat doch das "Match" das Rennen gemacht, wobei ich hier noch eine Ehrenrunde drehen durfte. Der folgende Befehl hat nämlich immer nur das erste Elemente gematched:
"11<td>22</td>33<td c=""a"">44</td>55" -match "<\s*td[^>]*>([^<]*?)<\s*/td\s*>"
Erst ein Umstellen hat auch weitere Matches gefunden.
PS C:\> ([regex]"<\s*td[^>]*>([^<]*?)<\s*/td\s*>").matches("11<td>22</td>33<td c=""a"">44</td>55")
Groups : {<td>22</td>, 22}
Success : True
Captures : {<td>22</td>}
Index : 2
Length : 11
Value : <td>22</td>
Groups : {<td c="a">44</td>, 44}
Success : True
Captures : {<td c="a">44</td>}
Index : 15
Length : 17
Value : <td c="a">44</td>
Alternativ wäre wohl noch folgendes gegangen:
$string | Select-String "<\s*td[^>]*>([^<]*?)<\s*/td\s*>" -AllMatches | % matches
Natürlich muss man nun durch alle Matches gehen und von den Groups dann das Elemente [1] nehmen. Das ist zwar kein perfekter HTML-Parser aber es ist gut genug für das Parsen einer statischen HTML-Tabelle, bei der innerhalb der Tabelle keine weitere Formatierungen genutzt werden.
Weitere Links zu RegEx
- TechNet Webcast: String Theory für System Administrators: An
Introduction to Regular Expressions (Level 200)
http://msevents.microsoft.com/CUI/WebCastEventDetails.aspx?EventID=1032271679
http://go.microsoft.com/fwlink/?LinkId=44007 - Phone Number Normalization Rule Regular Expressions
http://office.microsoft.com/en-us/help/phone-number-normalization-rule-regular-expressions-HP010290159.aspx - Hey, Scripting Guy: How Can I Search a Text File für 9-Digit Numbers http://www.microsoft.com/technet/scriptcenter/resources/qanda/apr05/hey0415.mspx
- How to Find or Validate an Email Address
http://www.regular-expressions.info/email.html - Welcome to Regular-Expressions.info The Premier website about
Regular Expressions
http://www.regular-expressions.info/ - PowerShell Mini-Scripting Games 2014: Answer 1
http://blogs.technet.com/b/heyscriptingguy/archive/2014/08/18/PowerShell-mini-scripting-games-2014-answer-1.aspx - Common Applications of Regular Expressions, Part 1-4
Part 1 http://www.4guysfromrolla.com/webtech/120400-1.shtml
Part 2 http://www.4guysfromrolla.com/webtech/120400-1.2.shtml
Part 3: http://www.4guysfromrolla.com/webtech/120400-1.3.shtml
Part 4: http://www.4guysfromrolla.com/webtech/120400-1.4.shtml - RegEx
http://regexadvice.com/blogs/dneimke/archive/category/1010.aspx - Library
http://regexlib.com
Patterns für Mail: http://regexlib.com/DisplayPatterns.aspx?cattabindex=0&categoryId=1 - RegEx Tutorials
http://www.codeproject.com/KB/dotnet/regextutorial.aspx - TechNet Webcast: String Theory für System Administrators: An
Introduction to Regular Expressions (Level 200)
http://msevents.microsoft.com/CUI/WebCastEventDetails.aspx?EventID=1032271679
http://go.microsoft.com/fwlink/?LinkId=44007 - Expresso
http://www.codeproject.com/KB/dotnet/expresso.aspx
http://www.ultrapico.com/ExpressoDownload.htm - The 30 Minute Regex Tutorial
http://www.codeproject.com/KB/dotnet/regextutorial.aspx - RegEx Workbench
http://code.msdn.microsoft.com/RegexWorkbench - The Regulator
http://sourceforge.net/projects/regulator
http://www.gotdotnet.com/workspaces/workspace.aspx?id=24289454-7ec7-45b6-82ae-f6a636dc5fea - RegEx Designer
http://www.sellsbrothers.com/tools/#regexd
http://www.gotdotnet.com/workspaces/workspace.aspx?id=01e0dfb7-0182-45cd-94f7-2ed2df2504a9 - Kommerzielle Software für die Arbeit mit RegEx Ausdrücken
http://www.regexbuddy.com/ - An Introduction to Regular Expression with VBScript
http://www.4guysfromrolla.com/webtech/090199-1.shtml
http://www.4guysfromrolla.com/webtech/090199-1.2.shtml - Microsoft Beefs up VBScript with Regular Expressions
http://msdn.Microsoft.com/library/default.asp?URL=/library/en-us/dnclinic/html/scripting051099.asp - Expresso - A Tool für Building and Testing Regular Expressions
http://www.codeproject.com/dotnet/expresso.asp
http://www.ultrapico.com/Expresso.htm - The 30 Minute Regex Tutorial
http://www.codeproject.com/dotnet/regextutorial.asp - Visual Basic: Regular Expressions Sample
http://msdn2.Microsoft.com/en-us/library/akz90407.aspx
Samples zum Download
http://download.Microsoft.com/download/C/3/8/C3888A3E-52F8-4FE9-8E41-89150AB0302F/RegExpressions.zip.exe - http://www.regular-expressions.info/regexbuddy.html
- Parse a URL with C# Regex
http://www.cambiaresearch.com/c4/890160aa-bc4e-40fc-ac36-c1031858c048/Parsing-URLs-with-Regular-Expressions-and-the-Regex-Object.aspx
http://www.cambiaresearch.com/c4/890160aa-bc4e-40fc-ac36-c1031858c048/Parsing-URLs-with-Regular-Expressions-and-the-Regex-Object.aspx?page=1 - Chapter 13. Text and Regular Expressions
http://PowerShell.com/cs/blogs/ebook/archive/2009/03/30/chapter-13-text-and-regular-expressions.aspx













