
PowerShell und parallele Verarbeitung
Die meisten PowerShell-Skripte laufen einfach seriell ab. Das ist einfach, überschaubar aber nicht unbedingt sehr schnell. Viele Anfragen, z.B. an Exchange benötigen doch etwas länger und in der Zwischenzeit wartet der Prozess. Auch der Vergleich von zwei LDAP-Verzeichnissen kann schneller erfolgen, wenn der Export parallelisiert wird und die Daten am Ende zusammengeführt werden. Windows selbst ist schon lange ein "Multitasking"-System, auch wenn viele Unix-Administratoren gerne daran rummäkeln. In den Anfangszeiten hat die Instanziierung eines Prozesse manchmal schon etwas länger gedauert.
Die PowerShell selbst bietet mehrere Optionen Prozesse ein Stück weit parallel ablaufen zu lassen. Um die Funktion und Leistung an einem Beispiel zu zeigen, habe ich mir zwei Prozesse ausgedacht, die einfach "langsam" sind.
{start-sleep 1 ; write-host "Modul1:"$_; $_}
{start-sleep 5; write-host "Modul2:"$_}
Beide machen also nichts anderes, als die Information, die Sie per Pipeline erhalten haben, nach einiger Verzögerung weiter zu geben. Diese beiden Prozessen werden einfach miteinander auf die verschiedenen Weisen verbunden. Als Eingabe dient einfach eine Zahlenreihe von 1 bis 9. Die kann in PowerShell auch einfach generiert werden.
1..9
Für die verschiedenen Alternativen gibt es schon mal eine kurze Vergleichstabelle:
| Funktion | Sequentiell | Pipeline | Job | Process | System. Management. Automation. PowerShell |
|---|---|---|---|---|---|
|
Schwierigkeit |
Leicht |
Leicht |
Mittel |
Mittel |
Mittel |
|
Geschwindigkeit |
Sehr Langsam |
Langsam |
Schnell |
nicht gemessen |
schnell |
Abhängigkeit vom Vater |
entfällt |
Ja |
Ja, Jobs werden beendet, wenn Vater endet |
Nein |
Ja |
|
Parameterübergabe |
Variable |
Pipeline |
Beim Aufruf per Parameter |
Beim Aufruf per Parameter |
? |
|
ErgebnisRückgabe |
Variable oder Pipeline |
Pipeline |
Abruf der Pipeline über Receive-Job. Auch während der Laufzeit möglich |
|
? |
Jobkontrolle |
Entfällt |
Entfällt |
|
|
Job-Objekt |
|
Write-Host Support |
|
|
|
|
|
Start-Transcript-Support |
|
|
|
|
|
|
LaufzeitUmgebung, d.h. Zugriff auf im Vater definierte Variablen und geladene Snapins und Add-ons |
Entfällt |
Vererbt |
"Privater Raum". Module etc. müssen selbst nachgeladen werden. |
komplett eigenständig zu verwalten |
"Privater Raum". Module etc. müssen selbst nachgeladen werden. |
Berechtigung |
Gleich |
Gleich |
Credentials optional |
Credentials optional |
Credentials optional |
|
Synchronisation |
Entfällt |
Pipeline Oneway |
Selbst zu entwickeln |
Selbst zu entwickeln |
Selbst zu entwickeln |
Throtting |
Entfällt nur 1 aktiver Teil |
Entfällt, nur 1 aktiver Teil |
|
|
|
 Get-Job
Get-Job Ja,
aber nur global
Ja,
aber nur globalSchauen wir uns die einzelnen Optionen der Verarbeitung an.
Sequentielle Verarbeitung
Fangen wir einfach mit der einfachsten Verarbeitung in Bausteinen ab.
# Liste von Eingabeobjekten erstellen
$liste1 = 1..10
# Eingabeobjekte im ersten Modul verarbeiten und in Liste2 speichern
$liste2 = foreach ($item in $liste1){
start-sleep 1 ; write-host "Modul1:"$item; $item}
# Liste2 als Eingabe in Modul2 verarbeiten
foreach ($item in $liste2){
start-sleep 5 ; write-host "Modul2:"$item}
# Ausgabe erfolgt an der Console
Die erste Verarbeitung benötigt 10 Sekunden um dann in Modul2 mit 50 Sekunden zu schlafen.

Insgesamt kommen also knapp 60 Sekunden Laufzeit zusammen. Man sieht auch bei der Bildschirmausgabe, dass der das Modul1 natürlich alles verarbeitet haben muss, ehe das langsamere Modul2 überhaupt erst anfangen kann.
Verketten mit der Pipeline
Der erste und sicher den meisten Personen bekannte Weg ist die Nutzung einer Pipeline, bei der die Ausgaben eines Prozesses an einen anderen Prozess übergeben werden. Auch wenn die Abarbeitung sequentiell erfolgt, da der nachgeschaltete Prozess auf die Daten des Vorgängers warten muss, ist die Verarbeitung schon etwas effektiver.
1..5 | `
%{start-sleep 1 ; write-host "Modul1:"$_; $_} | `
%{start-sleep 3; write-host "Modul2:"$_; $_} | `
%{start-sleep 5; write-host "Modul3:"$_}
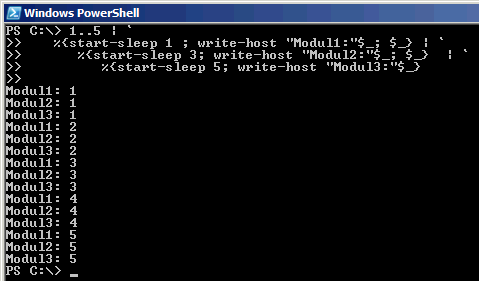
Einen Geschwindigkeitsrekord erreichen wir damit natürlich auch nicht, aber Modul2 kann zumindest schon nach einer Sekunden anfangen, zu verarbeiten. Leider wartet Modul2 und Modul 3 so lange.

Die Bildschirmausgabe zeigt auch, dass die Queue an sich sequentiell bleibt und das nächste Modul erst weiter machen kann, wenn das vorige Modul seine Teilaufgabe erledigt hat. Es ist also nicht so, dass Modul1 seine Ergebnisse nach 10 Sekunden in eine Pipeline geworfen hat und dann pausiert, sondern jedes Element wandert bei dem Beispiel durch die Pipeline durch. Die Verkettung von Prozessen per Pipeline bringt im Bezug auf die Laufzeit keine Vorteile, wohl aber im Bereich der Speicherbelastung, da eine Zwischenspeicherung nicht mehr erforderlich ist.
Foreach-Object - parallel
Eine For-Schleife ist ja eine oft genutzte Lösung um den gleichen Code für verschiedene Elemente zu wiederholen. Erstmalig mit PowerShell 7 Preview 3 hat Microsoft einen Parameter "-parallel" ergänzt, mit dem der Inhalt parallel abgearbeitet werden kann. Sie sollten dabei natürlich drauf achten, dass ihr Code das auch abkann. Eine Variable in der Schleife hochzuzählen und im Code zu verwenden funktioniert dann z.B. nicht mehr gut. Auch parallele Zugriffe auf Dateien z.B. per "Out-file" sollten Sie sich genau überlegen.
Zudem müssen Sie schon "Foreach-Objekt" nutzen, denn Microsoft schreibt dazu
Don’t confuse ForEach-Object cmdlet with PowerShell’s foreach keyword. The foreach keyword does not handle piped input but instead iterates over an enumerable object. There is currently no parallel support for the foreach keyword
- PowerShell ForEach-Object Parallel
Feature
https://devblogs.microsoft.com/powershell/powershell-foreach-object-parallel-feature/
Start-Job
Wenn Sie nun aber auf der einen Seite Daten relativ schnell ermitteln und die langsamere Nachverarbeitung parallel erfolgen kann, dann ist Start-Job ein mittel der Wahl. Über das "Start-Job"-Commandlet kann einfach ein Skriptblock in den "Hintergrund" gesendet werden. Über GET-Job lässt sich der Status des Jobs abfrage und über "Receive-Job" kann das Ergebnis des Jobs (Pipelineausgabe) einfach wieder abgerufen werden.
# Start einer Ausgabe
PS C:\> start-job {write-host "test";"pipetest"}
Id Name State HasMoreData Location
-- ---- ----- ----------- --------
11 Job11 Running True localhost
PS C:\> Get-Job
Id Name State HasMoreData Location
-- ---- ----- ----------- --------
11 Job11 Completed True localhost
PS C:\>$a= receive-Job 11
test
PS C:\>$a
pipetest
PS C:\> Remove-Job 11
Ausgaben der Jobs mit "Write-Host" oder der Pipeline landen aber nicht im Fenster des aufrufenden Programms, sondern müssen mit "Receive-Job" abgeholt werden.
Achtung:
Sowohl Ausgaben mit "Write-Host" als auch direkt
als STDOUT erscheinen bei einem einfachen "Receive-Job"
vermengt. Bei einer Zuweisung an eine Variable
werden aber nur die Daten von STDOUT kopiert.
Der Anruf leert dann aber die bis dahin angefallene Warteschlange, wenn Sie dies nicht mit "-keep" unterbinden. Interessant bei Start-Job ist die Option, alternative Credentials anzugeben. Im Taskmanager sehen Sie die Jobs als eigene Prozesse unter dem aufrufenden Prozess.
zurück zu unserem Performance Beispiel als "Job"
# Modul2 als Job parallel starten
1..10 | `
%{start-sleep 1 ; write-host "Modul1:"$_; $_} | `
%{$object = $_ ;
write-host "StartJob: $object"
start-job `
-scriptblock {
start-sleep 5;
$data = $input;
write-host "Modul2:$data";
$data
} `
-Inputobject $object
}
wait-job -state running
get-job | receive-job
Hier dauert es zwar nun wieder simulierte 10 Sekunden aber die Jobs laufen parallel mit ab und da der letzte Job bei Sekunde 10 startet und 5 Sekunden läuft, ist das ganze System nach 15 Sekunden "durch".
Ein Start-Job kann direkt einen Skript-Block enthalten oder ein eigenständige PowerShell-Skript starten. Es ist nicht möglich, als Bestandteil eines Jobs auf eine Funktion im gleichen Skript zu verweisen. Der Job hat also keine "Kopie" der LaufzeitUmgebung.
Wird der Vaterprozess geschlossen, dann werden damit auch alle Jobs entfernt. Da Jobs nach dem Start nicht mehr direkt gesteuert werden können, eignen Sie sich für klar umrissene Aufgaben, die auch ein Ende haben und weniger für Langläufer. Übrigens können Sie keine "PowerShell Events" nutzen, um zwischen Jobs der gleichen Instanz zu kommunizieren. Events können selbst aber Jobs starten. Auf der anderen Seite können Sie in einem Job aber kein "Start-Transcript" nutzen, um die Ausgaben zu protokollieren.
Ich nutze Jobs aber dennoch gerne, um länger Tasks asynchron schon mal auszuführen. Dabei darf man es aber nicht übertreiben. Ich würde z.B. die Aufgabe 100 DNS-Namen zu IP-Adressen aufzulösen sicher nicht auf 100 Jobs verteilen. Aber ein Job, der im Hintergrund die Arbeit schon mal macht, während das Programm gerade andere Daten sammelt und später dann darauf zurückgreift, ist durchaus sinnvoll nutzbar. Insbesondere wenn das Hauptprogramm "blockende" Befehle verwenden, wie z.B. einen HTTP-Listener.GetContext. (Siehe auf PRTG Pause) Hier ein Beispiel, wie man eine Liste von Namen später als "IP zu Name"-Liste als Jobs auslesen kann:
# IP2DNS
#
# PS Script to resolve Names to IPs in the Background
[string[]]$hosts=@()
$hosts+="www.microsoft.com"
$hosts+="www.netatwork.de"
$hosts+="www.msxfaq.de"
$hosts+="www.msxfaq.com"
start-job -ScriptBlock {
param($hostlist)
write-host "IP2DNSNAME:Start"
[hashtable]$ip2name=@{}
foreach ($hostname in $hostlist) {
write-host "Hostname:" $hostname -nonewline
foreach ($dnsanswer in ([System.Net.Dns]::GetHostAddresses($hostname))){
write-host (" -> Resolved to IP-Address:" + $dnsanswer.IPAddressToString) -nonewline
if ($ip2name.containskey($dnsanswer.IPAddressToString)) {
write-host " Duplicate - SKIP"
}
else {
$result = "" | select ipaddress,hostname
$result.ipaddress = $dnsanswer.IPAddressToString
$result.hostname = $hostname
$ip2name.add($dnsanswer.IPAddressToString,$result)
write-host " Added"
}
}
}
$ip2name.values
write-host "IP2DNSNAME:End"
} `
-ArgumentList (,$hosts) # required to send array as one arument instead of individual args
Als Besonderheit muss man hier sehen, dass die Liste der Hosts in Klammern mit einem führenden Komma angegeben werden muss. So versteht Powershell diese Liste als einen Parameter und nicht als Parameterliste, die dann mit $ARGS ausgelesen werden müsste.
- Start-Job
http://technet.microsoft.com/de-de/library/dd347692.aspx - about_Jobs
http://technet.microsoft.com/de-de/library/dd315273.aspx - Hey, Scripting Guy! How Can
I Start, Receive, and Manage
Jobs in Windows PowerShell 2.0?
http://blogs.technet.com/b/heyscriptingguy/archive/2010/03/15/hey-scripting-guy-march-15-2010.aspx - Can -PowerShell run
commands in parallel
http://stackoverflow.com/questions/4016451/can-PowerShell-run-commands-in-parallel - $input gotchas
http://dmitrysotnikov.wordpress.com/2008/11/26/input-gotchas/ - Parallel "For Each"
http://snipplr.com/view/47915/parallel-for-each/ - Video: Dmitry Sotnikov -
PowerShell Jobs in v2 and v3
http://dmitrysotnikov.wordpress.com/2012/03/28/video-dmitry-sotnikov-PowerShell-jobs-in-v2-and-v3/ - A better Start-Job cmdlet
http://blog.brianhartsock.com/2010/05/22/a-better-start-job-cmdlet/ - How to pass an array or
multidimensional array as
arguments to a scriptblock
http://www.alexwinner.com/articles/powershell/69-posh-array-arglist.html - Calling a PowerShell
function in a Start-Job script
block when it’s defined in the
same script
https://stuart-moore.com/calling-a-powershell-function-in-a-start-job-script-block-when-its-defined-in-the-same-script/ - Using Background Runspaces
Instead of PSJobs For Better
Performance
https://learn-powershell.net/2012/05/13/using-background-runspaces-instead-of-psjobs-for-better-performance/
Parameter -AsJob
Eine Sonderform von Jobs verbirgt sich hinter der Option "-AsJob", den verschiedene Commandlets zulassen. Damit ist es möglich, diesen Befehl per PowerShell Remoting auf einem anderen Computer (oder natürlich auch wieder lokal) zu starten und damit zu parallelisieren.
Prozess
Bei einem Prozess wird nicht ein Job innerhalb bzw. genauer unterhalb der startenden Umgebung aufgemacht, sondern eine ganz eigene Instanz eines Prozesses gestartet. Das muss kein PowerShell-Script sein. Das kann ein beliebiger ausführbarer Code sein, also auch eine EXE oder BAT-Datei. Es kann sogar ein Dokument sein, zu dem es eine Programmverknüpfung gibt. So kann durch den Aufruf einer DOC-Datei z.B. Word gestartet werden und über den Parameter "-verb" kann sogar z.B. "Print" ausgewählt werden.
Diese Prozesse laufen eigenständig ab. Sie müssen sich also auch eine entsprechende "Umgebung" für ihre Aktionen schaffen. Sie können keine Module oder Variablen des aufrufenden Programme nutzen. Auch gibt es nicht wirklich eine einfache Schnittstelle zur Übergabe und Rückerhalt von Daten.
Ein Prozess kann Natürlich über Kommandozeilen Informationen erhalten, aber strukturierte Daten muss man notfalls über Dateien oder andere Wege der Kommunikation zwischen Prozessen austauschen. Es ist aber möglich, zumindest STDIN, STDOUT und STDERR über Dateien umzuleiten. Das ist aber Natürlich ein Rückschritt zur objektorientierten Übergabe in einer reinen PowerShell-Umgebung. Import-CliXML und Export-CliXML können helfen, strukturierte Daten bis zu bestimmten Größen bereitzustellen.
Diese Unabhängigkeit bietet aber auch den Weg, alternative Anmeldedaten zu verwenden. Zudem ist der gestartete Prozess nicht vom Vater abhängig, d.h. läuft auch weiter, wenn der startende Prozess nicht mehr aktiv ist. Es gibt mehrere Wege einen Prozess zu starten:
- Invoke-Command
Hierbei wird über PSRemote der Prozess auf dem lokalen oder entfernten Computer mit umfangreichen Optionen gestartet. Erst mit der Option "-AsJob" wird das aufrufenden Skript nicht angehalten. Technisch wird lokal ein "Job" als Verwaltungsobjekt erstellt, auch wenn das Programm remote ausgeführt wird. Damit ist eine Verteilung auch auf mehrere Computer (Scale-Out) möglich, wenn diese die entsprechenden Code-Teile vorhalten
invoke-command -scriptblock {write-host "hallo"}
- Start-Process
Diese Commandlet startet lokal einen neuen Prozess. Leider gibt es außer dem Programmnamen, Parametern und der Option einer Ein/Ausgabe-Umleitung keine weitere Möglichkeiten. Über einen "Get-Process" können Sie (alle) Prozesse sehen.
start-process notepad.exe
- [system.diagnostics.process]::Start
Interessanter ist dabei vielleicht der Start über die reine .NET-Funktion. Hierbei erhält der aufrufende Prozess ein Objekt zurück, mit dem es den laufen Prozess weiter abfragen kann, selbst wenn der Prozess schon beendet ist. So entspricht diese Funktion besser dem lokalen "Start-Job"
$child = [system.diagnostics.process]::Start("PowerShell", "-file c:\temp\test.ps1 -param1 value1")
Get-process -id $child.id
Für diese Funktion habe ich keine Last/Performance-Tests gemacht, da die Anforderungen hierzu doch eher individuell sind und eine 10fach durchlaufende Schleife den PC nicht wirklich stresst. Das instanziieren von 10 weiteren Prozessen aber schon eher, so dass die gemessenen Zeiten nicht gültig wären.
Eigene Prozesse sind eher etwas, wenn es um die Verteilung auf verschiedene Systeme oder direkt die entfernte Ausführung geht oder ein Nachgeschalteter Prozess gestartet werden soll, ohne das der Vaterprozess lange aktiv bleiben muss.
Ein Einsatzfeld könnte die Aktivierung von PowerShell-Skripten per Taskplaner sein, welcher eiben geplanten Prozess immer nur einmal startet. Hier könnte ein kleiner "Starter" das eigentliche Modul als Prozess starten und sich selbst wieder beenden, damit der Taskplaner ihn erneut aufwecken kann. Dies kann aber auch ganz schnell zu Überlastsituationen führen.
- Start-Process
http://technet.microsoft.com/de-de/library/dd347667 - Invoke-Comand
http://technet.microsoft.com/de-de/library/dd347578
Powershell Workflows
Seit PowerShell 3 gibt es so genannte "Workflows". Sie können mehrere Befehle einfach parallel ausführen. Auch wenn es wie PowerShell aussieht, werden dabei aber im Hintergrund die Windows Workflow Foundation genutzt. Ähnlich dem Schlüsselwort "Function" wird nun ein Workflow definiert. Siehe dazu PowerShell Workflows.
Aus meiner Sicht ist das ein ganz interessanter Ansatz mit wenig Aufwand eine überschaubare Anzahl von Aktionen zu parallelisieren.
Jobs mit Runspace / Invoke
Die Aufrufe von Routinen mit "Start-Job" oder dem Parameter "-asJob" startet immer eine neue PowerShell-Session, in der Sie alle Verbindungen neu aufbauen müssen. Sie vererben nichts und zudem kostet die zusätzliche PowerShell-Laufzeitumgebung kostbaren Speicher und dauert wenige Sekunden bis Sie "aktiv" ist.
Mit PowerShell Runspaces wird nur ein weiterer Thread gestartet, was weniger Speicher und weniger Zeit als eine Job-Einrichtung dauert. Siehe dazu die Seite PS Runspace.
MultiThreading mit Sockets
Es muss nicht immer ein kompletter Job sein, wenn man einfach etwas im Hintergrund laufen lassen will. Neben kompletten Jobs mit eigener Laufzeitumgebung gibt es ja noch die Option zusätzlicher Threads. Das geht einmal bei diversen-NET-Klassen, die einen asynchronen Start erlauben. Ich nutzte das z.B. bei dem Aufbau von TCP-Verbindungen. Der klassische Weg ist dabei:
$Socket = New-Object System.Net.Sockets.TCPClient
$Connection = $Socket.Connect("www.msxfaq.de",443)
if ($Socket.connected ) {
write-host "Connected"
}
else {
write-host "Timeout on connection - port not open"
}
Dieses Skript "wartet" beim $socket.connect() bis die Verbindung steht. Viel störender ist es, wenn die Verbindung nicht zustande kommt. Da der TCP-Stack das mehrfach versucht, kann das auch mal 21 Sekunden dauern, bis das Skript weiter läuft. Eleganter ist es daher den Socket asynchron zu öffnen und später zurück zu kommen und zu prüfen.
$Socket = New-Object System.Net.Sockets.TCPClient
$Connection = $Socket.BeginConnect("www.msxfaq.de",443,$null,$null)
## hier kann ich dann was anderes tun
if ($Socket.connected ) {
write-host "Connected"
}
else {
write-host "Timeout on connection - port not open"
}
- TcpClient.BeginConnect Method
https://docs.microsoft.com/de-de/dotnet/api/system.net.sockets.tcpclient.beginconnect?view=netframework-4.7.2 - Socket.BeginConnect Method
https://docs.microsoft.com/de-de/dotnet/api/system.net.sockets.socket.beginconnect - PowerShell und Callback-Funktionen
- Use Asynchronous Event Handling in
PowerShell
https://blogs.technet.microsoft.com/heyscriptingguy/2011/06/16/use-asynchronous-event-handling-in-powershell/ - Multithreading with Jobs in PowerShell
http://www.get-blog.com/?p=22 - True Multithreading in PowerShell
http://www.get-blog.com/?p=189 - Using Background Runspaces Instead of
PSJobs For Better Performance
https://learn-powershell.net/2012/05/13/using-background-runspaces-instead-of-psjobs-for-better-performance/
Throtting und Synchronisation
Wer parallel mehrere Aufgaben abarbeiten lässt, muss ich um mindestens zwei Dinge sorgen.
- Throttling
Parallelisieren kann Geschwindigkeit bringen. Wenn Sie aber 10.000 Empfänger einlesen und 10.000 Jobs starten, um eine Eigenschaft der Empfänger zu ändern, dann wird das vermutlich gar nicht mehr schnell ablaufen. Zum einen sind das sehr viele Prozesse die ihre CPU, Speicher und LAN belasten und zudem kennt auch Exchange Schutzmechanismen (Siehe EWS, Outlook 2003 mit Exchange 2010 und Daten werden abgerufen), um eine Überlastung zu verhindern.
Insofern sollten Sie ihr Skript entsprechend zügeln, dass es sich nicht selbst blockiert, z.B. indem sie die Anzahl der aktiven Jobs zählen ehe sie neue Jobs anlegen und die Daten beendeter Jobs zeitnah abholen und die Jobs entfernen. - Synchronisation
Sie können in die Situation kommen, dass Sie mehrere parallele Jobs aufeinander abstimmen müssen, z.B.: weil ein Job erst loslegen kann, wenn die Vorarbeiten durch einen anderen Job erledigt sind (und das Active Directory sich repliziert hat). Dies ist insbesondere der Fall, wenn Sie verkettete Aktionen in sich parallelisieren. Aber auch die Zusammenfassung von Ergebnissen verschiedener Jobs kann eine Aufgabe am Ende der Verarbeitung sein. So muss das Hauptprogramm auf das Ende der Jobs warten und die Ergebnisse einsammeln. Wenn es dabei noch auf die Reihenfolge ankommt, dann müssen sie beim Anlegen der Jobs die Job-Daten nutzen.
Ganz allgemein sollten sie schon überlegen, wo eine parallele Verarbeitung heute wirklich sinnvoll ist. Erst mit den Jobs oder Prozessen ist eine merkliche Verbesserung möglich.
Weitere Links
- PowerShell Beispiele
- PS Runspace
- PS Performance
-
PS
Distributed
Verteile Jobs mit Powershell - Start-Job
http://technet.microsoft.com/de-de/library/dd347692.aspx - Can -PowerShell run
commands in parallel
http://stackoverflow.com/questions/4016451/can-PowerShell-run-commands-in-parallel - Parallel "For Each"
http://snipplr.com/view/47915/parallel-for-each/ -
Video: Richard Siddaway -
PowerShell Events
http://dmitrysotnikov.wordpress.com/2012/04/02/video-richard-siddaway-PowerShell-events/ - Multithreading with Jobs in
PowerShell
http://www.get-blog.com/?p=22 - True Multithreading in
PowerShell
http://www.get-blog.com/?p=189 - Using Background Runspaces
Instead of PSJobs For Better
Performance
https://learn-powershell.net/2012/05/13/using-background-runspaces-instead-of-psjobs-for-better-performance/ - Producer Consumer
Parallelism in PowerShell
https://www.leeholmes.com/producer-consumer-parallelism-in-powershell/













